
一、概念
1.原理看图,非常简单:
(1)蓝的是节点,白的是分支(条件,或者说是特征,属性,也可以直接写线上,看题目有没有要求),
(2)适用于离散的数据,分分分,就完了!
(3)训练阶段就是构造一个树,测试阶段就是沿着构造的树走一遍,但是选择哪个特征作为分支节点很难。
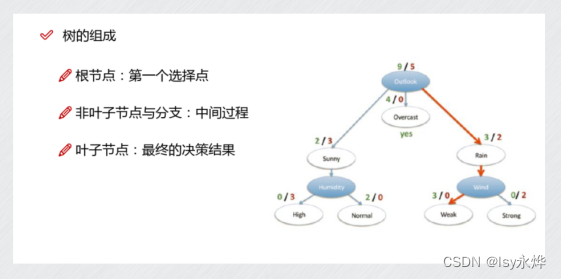
2.既可以用于分类,也可以用于回归(区别线性模型可以在坐标轴画出来):
(1)分类问题:根据输入特征的取值,通过一系列的决策节点(节点上的条件判断)来对样本进行分类。最终每个叶节点对应一个类别标签。
(2)回归问题:通过一系列的决策节点,来预测数值型的目标变量。每个叶节点对应的数值是该节点上所有训练样本目标变量的 均值 或 加权平均值 。
3.构建决策树的三个方法:
顺序 基于信息增益的ID3,在此基础上改编出基于信息增益率的C4.5,然后是升级版的基于基尼指数的CART
4.信息熵(超级无敌重点):
(熵的概念在第一章,但基础就是越混乱,熵越大)
(1)信息熵公式:
(2)例题:
假如有一个普通般子A,仍出1-6的概率都是1/6
有一个散子B,扔出6的概率是50%,扔出1-5的概率都是10%
有一个般子C,扔出6的概率是100%。
解:
(PS:不算一下,不知道问题出在哪!)
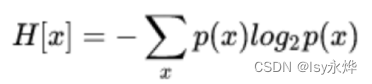
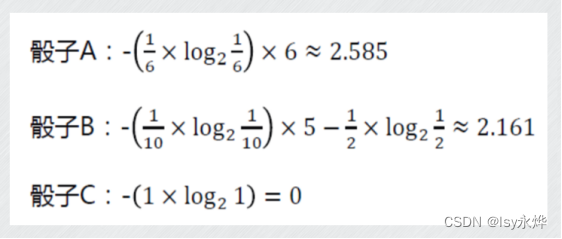
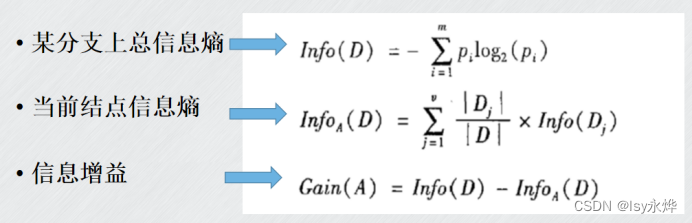
5.信息增益gain:
与此关联的是ID3,选信息增益最大的作为下一个节点
(1)计算公式:
(2)性质:
a. gain与属性的值域大小成正比,属性取值种类越多,越有可能成为分裂属性(即ID3算法对可取数值多的属性有偏好)。
b. 不能处理连续分布的数据特征。
(3)习题:
有下列数据集:
解:
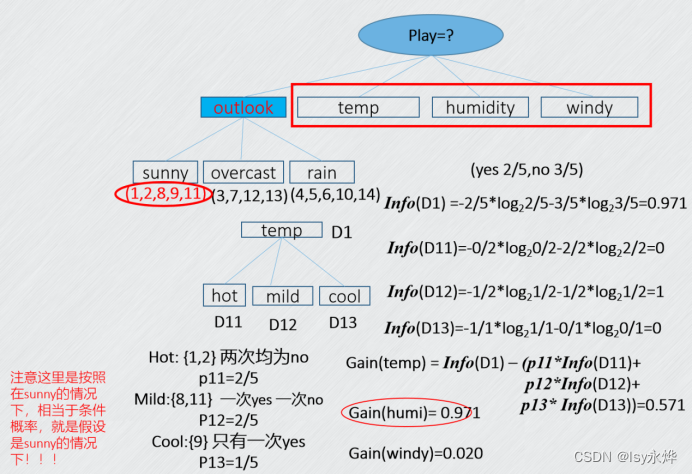
步骤1:如何确定根节点
总的信息熵:
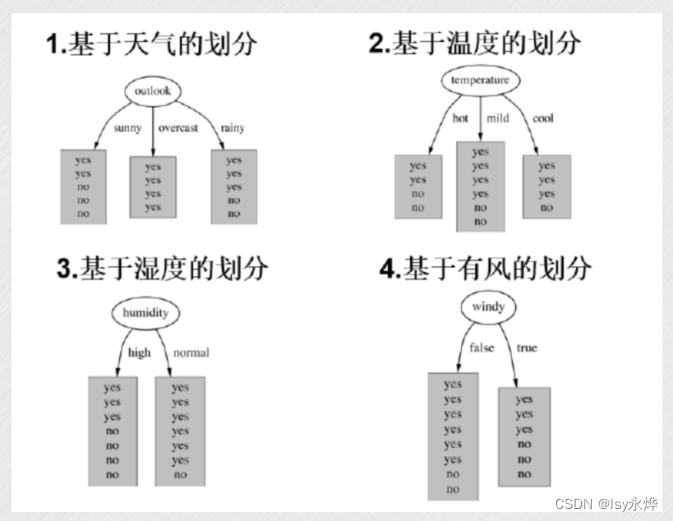
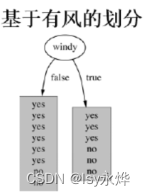
以下主要计算了基于天气的,但是最后剩下三种的都给了。
由于outlook的信息增益最大,根据ID3规则,选Outlook,接下来算一次子节点:
也是可以得出下一次就是humidity作为sunny的子节点了,毕竟它最大。


6.信息增益率(计算太麻烦了,应该不考计算):
与此关联的是C4.5,选信息增益率最大的作为下一个节点,使用该方法最大的优点就是避免了因为种类太多导致gain值过于大的情况(分母越大,值越小)。
(1)公式及例子:
(2)其具体算法步骤与ID3类似;
(3)优缺点
优点:
C4.5能够完成对连续属性的离散化处理;
能够对不完整数据进行处理;
分类规则易于理解、准确率较高;
缺点:
效率低,只适合于能够驻留于内存的数据集。

7.CART算法(应该也不考计算)
采用的是一种二分循环分割的方法,每次都把当前样本集划分为两个子样本集,使生成的决策树的结点均有两个分支,显然,这样就构造了一个二叉树。如果分支属性有多于两个取值,在分裂时会对属性值进行组合,选择最佳的两个组合分支。
(1)采用的是基尼(gini)指数。
(2)公式:
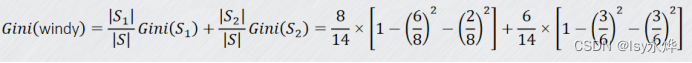
8.过拟合问题
一方面要注意选取具有代表性样本,这样数据集质量高。
另一方面要限制树的深度来减少数据中的噪声对于决策树构建的影响,一般采取剪枝:
剪枝是用来缩小决策树的规模,从而降低最终算法的复杂度并提高预测准确度,包括预剪枝和后剪枝两类。
(1)预剪枝的思路是提前终止决策树的增长,在形成完全拟合训练样本集的决策树之前就停止树的增长,避免决策树规模过大而产生过拟合。
条件可以报考深度,最大叶子数等
(2)后剪枝策略先让决策树完全生长,之后针对子树进行判断,用叶子结点或者子树中最常用的分支替换子树,以此方式不断改进决策树,直至无法改进为止。
一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。
但训练时间比预剪枝要大得多。
二、习题
单选题
2.( B)是最早用于决策树模型的特征选择指标,也是ID3算法的核心。
A、信息增益率 B、信息增益 C、基尼指数 D、信息增益比
10. 下列关于ID3算法说法错误的是(D)
A、ID3算法中根据信息论的信息增益 评估和选择 特征
B、ID3不能处理连续分布的数据特征
C、ID3算法对可取数值多的属性有偏好
D、每次选择信息增益最小的候选特征,作为判断模块
多选题
9. 以下关于决策树的说法正确的是(ABC )。
A、既可用于分类,又可以用于回归
B、通过贪心策略挑选最优属性
C、具有很强的数据拟合能力,容易产生过拟合
D、一定能找到全局最优解
(贪心算法,即每一步都采取局部最优的选择来构建树。)
判断题
5. 决策树属于典型的生成模型。( F)
10. 决策树是一种常用的机器学习算法,既可用于分类,也可用于回归( T)。
11. 如果对决策树进行剪枝可以减小决策树的复杂度,提高决策树的专一性能力。(F)
本题老师给的答案是错误,但是我查的是正确的。。。
12. 决策树本身是一种贪心的策略,一定能够得到全局的最优解。(F)
计算题
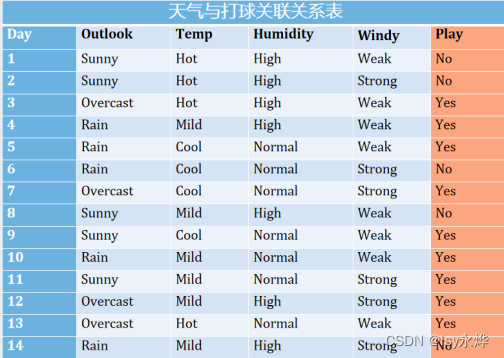
2.根据提供的打球和天气表格构造决策树,要求计算每个特征的信息熵(4分),并依据信息增益确定每个根节点的特征(3分),画出决策树(3分)。
Day
Outlook
Windy
Play
1
Rain
Weak
no
2
Sunny
Weak
yes
3
Rain
Strong
no
4
Sunny
Weak
yes
5
overcast
Strong
no
答案:













