
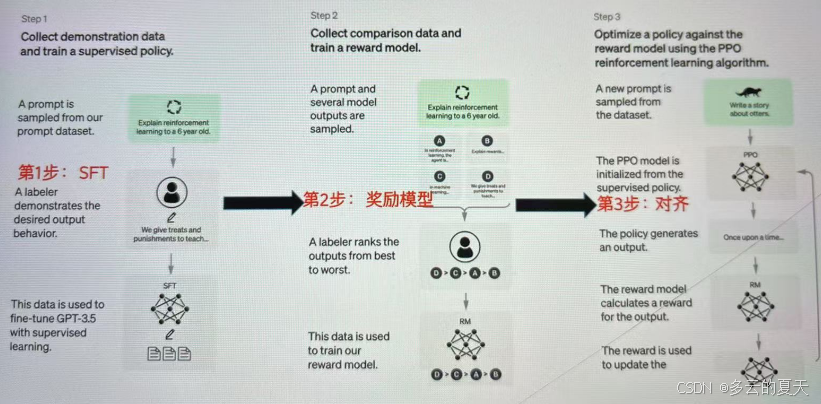
本篇中的信息大部分来自互联网,我也是不太懂的,供大家参考。
1.模型架构
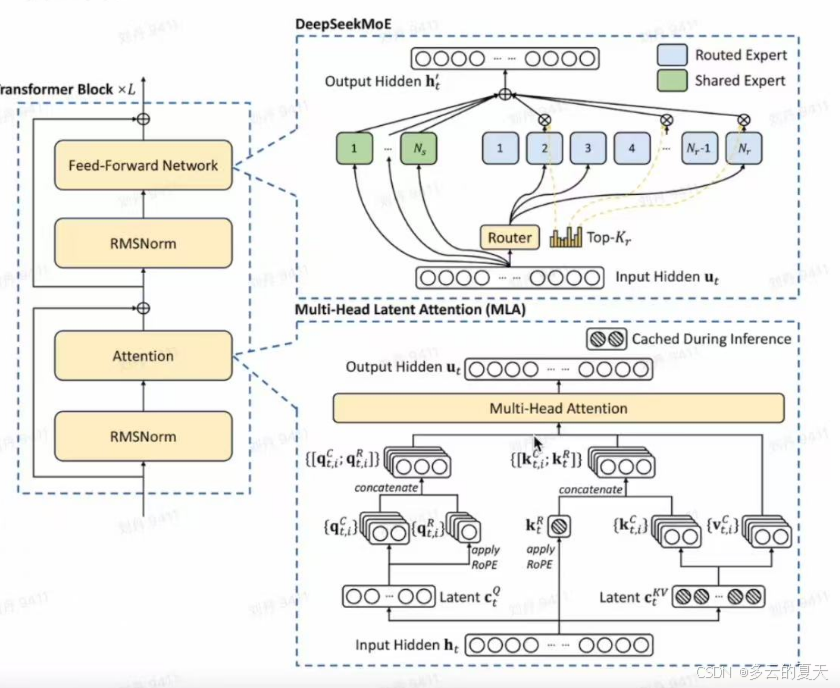
1.1config
routed Expert
Shared Expert
| 内容项 | 详情 |
|---|---|
| 专家头包含 | 包括 share router 专家头 |
| share 专家状态 | 一直激活,输入 token 都会经 share 专家头计算 |
| router 专家头操作 | 先和图中 ut 计算亲和度(代码中用 Linear 层投影),选 topk 个专家推理 |
流程:
1.share expert+input
2.router export+input
input+router expert =指心向量
input+指心向量=亲和度(相似度)
亲和度topkrouter expert :解决问题
3. top router exprt
每个input+share expert=output
被选出的topk router expert+input =output
4.前2种router 权重相加
manager 确保了一种router 其余都运行的方法。
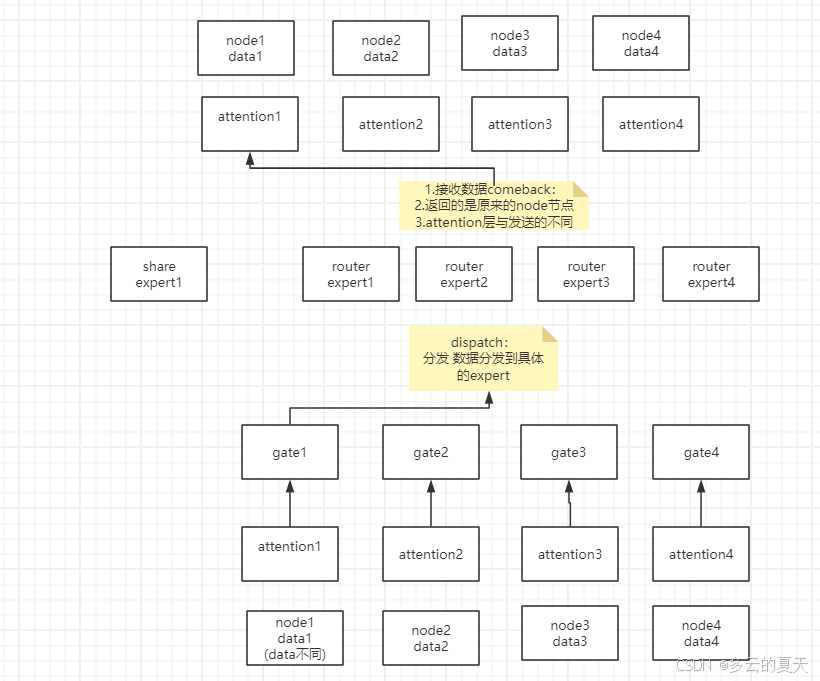
代码:node 分组节点 减少机器个数
分组:routed expert
group route expert (10,topk(5))
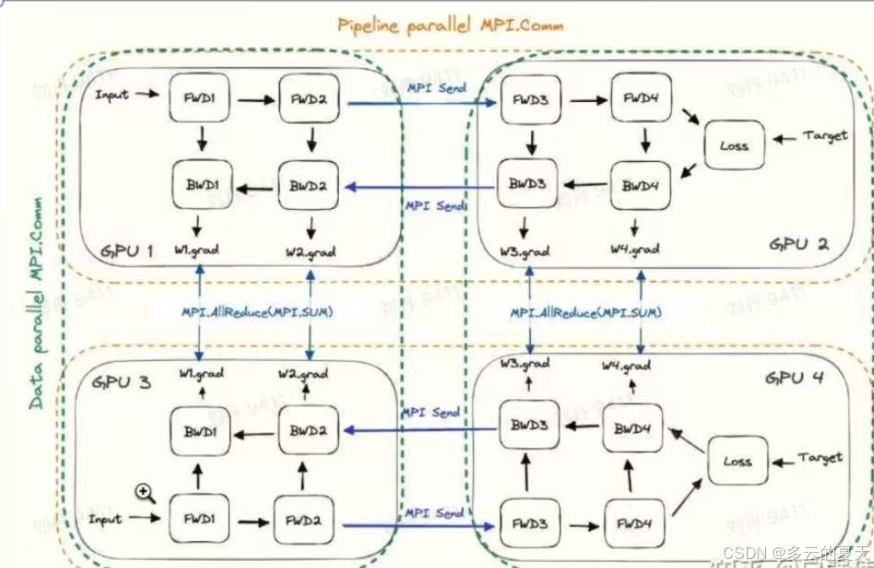
1.2 数据并行dp和模型并行pp
{
"aux_loss_alpha": 0.001, // 辅助损失权重
"ep_size": 1, // 具体含义需结合模型场景确定
"hidden_act": "silu", // 激活函数
"hidden_size": 7168, // 隐藏层大小
"initializer_range": 0.02, // 模型中间层初始化大小
"intermediate_size": 14336, // 中间层大小
"kv_layer_rank_size": 512, //k,v 的低秩维度
"max_position_embeddings": 163840, // 最大长度
"moe_intermediate_size": 2048, // MoE 中间层维度
"n_group": 8, // 分组数
"n_routed_experts": 256, // 非共享专家数
"n_shared_experts": 1, // 共享专家数
"num_attention_heads": 128, // 注意力头数
"num_expert_per_tok": 8, // 每个 token 激活的专家数
"num_hidden_layers": 61, // Transformer 层数
"num_key_value_heads": 128, //k ,v 头数
"pretraining_tp": 1, // 预训练张量并行度
"lora_rank": 1536, // 微调训练的 lora 维度
"qk_nope_head_dim": 64, //qk 的 nope 维度
"quantization_config": {
"activation_scheme": "dynamic", // 激活动态量化
"fmt": "e4m3", // 指数 4 位尾数三位
"quant_method": "fp8", // 量化数据结构
"weight_block_size": [
128 // 量化分组指数,即一个 128*128 的矩阵共享一组 scaling 和 bias
]
},
"rms_norm_eps": 1e-6, //rms 的参数
"rope_scaling": {
"beta_fast": 32, //yarn 的上下文长度拓展参数
"beta_slow": 1,
"factor": 40,
"mscale": 1.0,
"mscale_all_dim": 1.0,
"original_max_position_embeddings": 4096,
"type": "yarn"
},
"rope_theta": 10000, //theta 的大小
"routed_scaling_factor": 2.5, //router 的放大系数
"scoring_func": "sigmoid", // 评分函数
"seq_aux": true,
"tie_word_embeddings": false, //ln_head 和 embedding 不共享
"topk_group": 4, // 激活 node
"v_head_dim": 128, //v 头维度
"vocab_size": 129280 // 词表数
}
注意力演进
1.2分调
1.3MLA
1.4 share MOE
2.训练方法创新
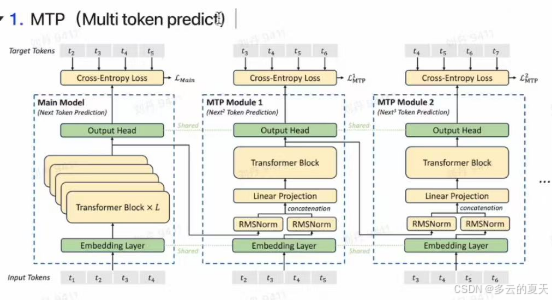
2.1MTP
词向量训练:
skip gram(所有 **的**都是共享的) 中心词预测左右的词:比如 “的”预测前后
cbow(所有 绿色*模块都是共享的) 旁边词预测中间的词:比如“”去预测*
现在:multi token predict 预测多个token
原来:next token predict 预测下一个token
第一个token 预测第二个token的表征
第二个是右移了一位 B 2H的向量 2H向量降维 linear preaction 降维操作
流程1 用1 去预测2
流程2 用1 去预测3
流程3 用1 去预测4
所以实现了用token1 预测 token2 token3 token4
所有绿色模块都是共享的
共享权重
# MTP 代码
# MLA和MOE代码省略,其他基本完善
import torch
import torch.nn as nnclass RMSNorm(nn.Module):def __init__(self, dim: int, eps: float = 1e-8):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(dim)) # 可学习的缩放参数def _norm(self, x: torch.Tensor):return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x: torch.Tensor):return self.weight * self._norm(x.float()).type_as(x)class share_embedding(nn.Module, config):def __init__(self, config: DeepseekV3Config):super().__init__()class MTP(nn.Module, config):def __init__(self, config: DeepseekV3Config):super().__init__()self.RMSNorm_right = RMSNorm(config)self.RMSNorm_left = RMSNorm(config)self.transformer = transformer_block(config)self.proj = nn.Linear(2*config.hidden_size,config.hidden_size)def forward(self, last_block_out, input_ids_truncated, share_embedding, st):last_norm_out = self.RMSNorm_right(last_block_out)embedding_trunc = share_embedding(input_ids_truncated)concat_input = torch.cat((last_norm_out, embedding_trunc), dim=-1)proj_out = self.proj(concat_input)trans_out_logits = self.transformer(proj_out)return trans_out_logitsclass MTP_and_deepseek(nn.Module, config):def __init__(self, config: DeepseekV3Config):super().__init__()self.share_embedding = share_embedding(config)self.share_lm_head = share_output_head(config)self.loss = nn.CrossEntropyLoss(ignore_index = config.pad_token_id)self.Model_trans_blocks = nn.ModuleList([transformer_block(config, layer_idx)for layer_idx in range(config.num_hidden_layers)])self.MTP_trans_blocks = nn.ModuleList([transformer_block(config, layer_idx)for layer_idx in range(config.num_MTP_layers)])self.config = configself.alpha_list = config.alpha_list # 对于每一个MTPloss的加权列表def forward(self, input_ids):# input_ids :###[bos,tok1,tok2......last_tok]###labels_origin:###[tok1,tok2,....,last_tok,eos/pad]###labels_MTP1###[tok2,....last_tok,eos,pad]###labels_MTP2###[tok3,....last_tok,eos,pad]embedding_logits = self.share_embedding(input_ids)deepseek_hidden = embedding_logitsfor index,trans_block in enumerate(self.Model_trans_blocks):deepseek_hidden = trans_block(deepseek_hidden)deepseek_logits = self.share_lm_head(deepseek_hidden)labels = torch.cat([input_ids[:, 1:], torch.full((input_ids.size(0), 1), self.config.pad_token_id, dtype=input_ids.dtype)], dim=1)Main_loss = self.loss(deepseek_logits, labels)last_mtp_out = deepseek_hiddenfor ind, MTP in enumerate(self.MTP_trans_blocks):input_ids_trunc = torch.cat([input_ids[:, ind + 1:], torch.full((input_ids.size(0), ind + 1), self.config.pad_token_id, dtype=input_ids.dtype)], dim=1)mtp_out = MTP(last_mtp_out,input_ids_trunc,self.share_embedding)mtp_logits = self.share_lm_head(mtp_out)last_mtp_out = mtp_outlabels_trunc = torch.cat([input_ids_trunc[:, 1:], torch.full((input_ids_trunc.size(0), 1), self.config.pad_token_id, dtype=input_ids_trunc.dtype)], dim=1)mtp_loss = self.loss(mtp_logits, labels_trunc)alpha = self.alpha_list[ind]Main_loss += alpha*mtp_lossreturn Main_loss
2.2专家负载均衡

2.2.1辅助函数
亲和度影响因子:
如果topk=2
原始亲和度,人为偏移量, 专家值
a: 0.4-0.1 100;
b:0.35+0 50;
c: 0.25+0.1 120;
output =50+0.35+0.25+120 ?
2.3训练成本
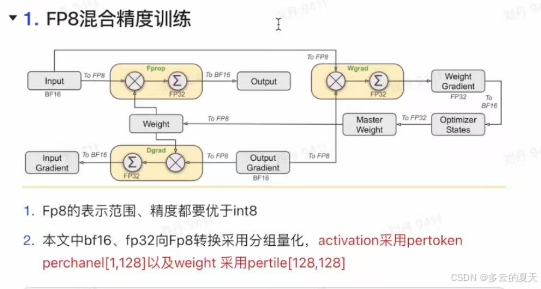
2.3.1混合精度
2.3.2moe层计算与通信量下降
2.3.2.1原始层MLP的计算量
2.3.2.2MOE的计算量
2.3.2.3MOE与MLP的计算对比
2.3.2.4分布式训练的通信量
2.3.2.5 总结
3.强化学习
3.1 过程

强逻辑:数学题
作文:主观题 没有输出
3.2 实现



Ai优势函数,在特定场景下的动作 不一定会赢,赢面大
b:原来的优势是b 未来每次奖励求和
状态价值
A : r :同一个输入值,不同采样下得到G个输出 奖励值
当前的优势
为什么要除以均值
![]()
4.分布式混合精度训练
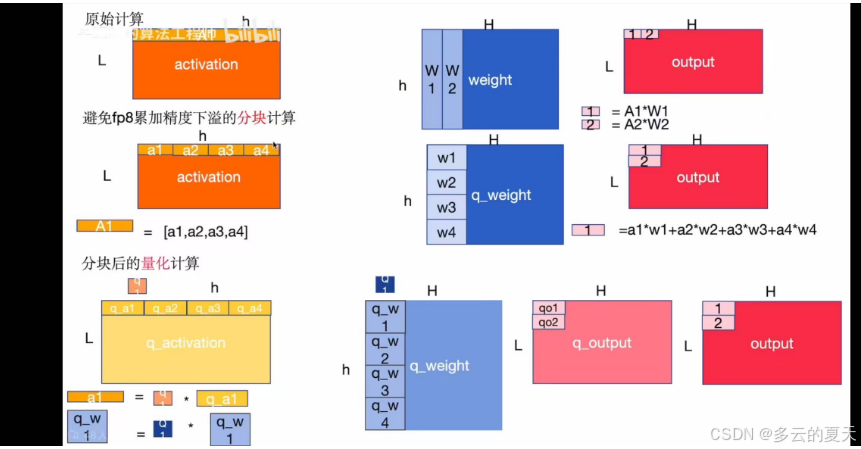
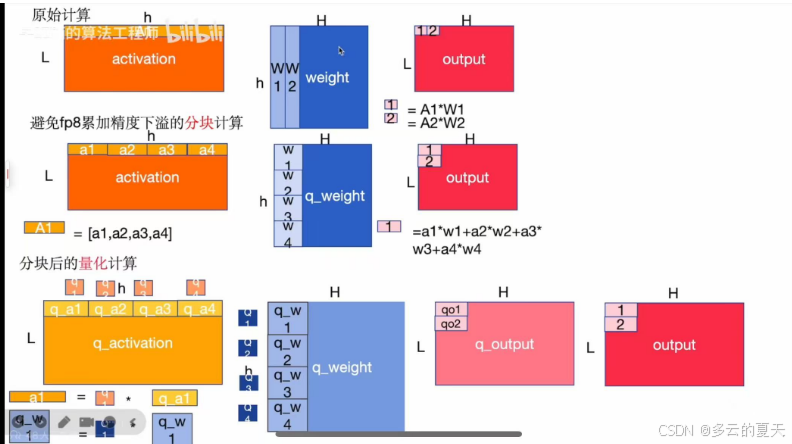
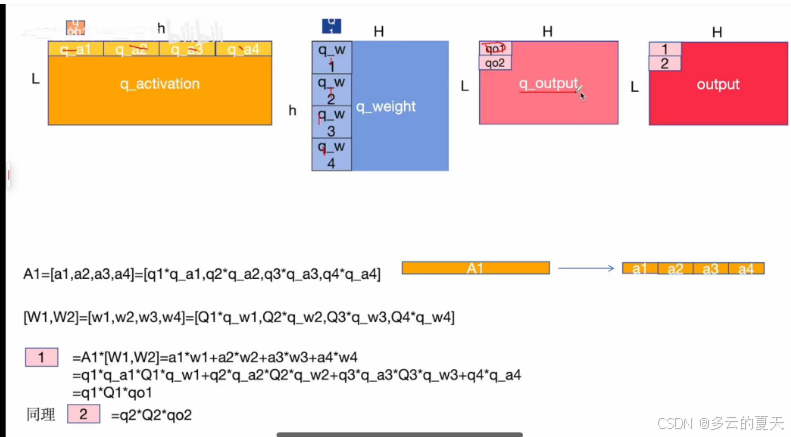
5.数据准备

sft-rl data model
6.适配推理引擎

7.GROUP算法








dpo: 每个answer标注出来,离线强化学习
长链条的 标注数据,难收敛
ppo:当前优势



















