
“Enhancing Financial Market Predictions: Causality-Driven Feature Selection”
论文地址:https://arxiv.org/pdf/2408.01005

摘要
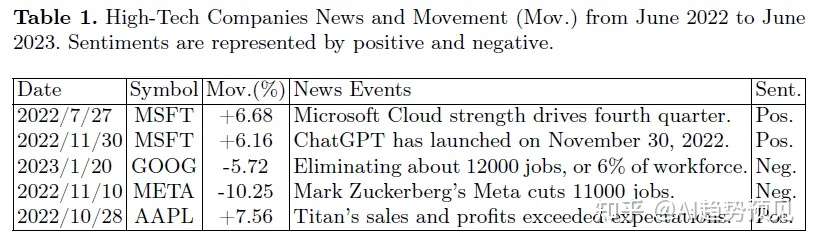
本文阐述了FinSen数据集的特色,它整合了来自197个不同国家的经济和金融新闻报道与相应的股市数据,涵盖了15年的历史,包含160,000篇金融市场新闻,提供了一个广阔的全球视角。
基于这个数据集,作者引入了一种新颖的Focal Calibration Loss方法,该方法能够紧密地将预测的概率分布与实际发生的结果相匹配,从而增强了金融预测的准确度和可信度。通过结合情感分析与精准校准技术,作者提出的方法为金融预测领域提供了一种可靠的新途径。
简介
在金融行业中,预测股市的变动是一个关键性的难题。由于市场的复杂非线性特征及其固有的不稳定性,要精确地预估市场走向颇具挑战。传统的分析模型多依赖于过往的数值资料,但这类方法难以全面反映市场动态的各个方面。同时,公开可用的数据集通常不具备详尽的时间戳信息,这进一步增加了探索那些未知因素如何影响金融市场稳定性的难度。尽管投资者情绪在市场研究中越来越受到重视,然而它对市场波动的具体影响及其可靠性依然是一个需要深入研究的话题。
本文中,作者介绍了一种结合神经网络与情感分析技术来预测金融市场波动的新方法。为此,他们构建了一个名为FinSen的新型金融数据集,并通过该数据集确立了情感评分与S&P 500指数波动之间的因果关联。此外,作者还设计了一种名为Focal Calibration Loss的损失函数,以增强模型预测的可靠性和精确度。研究结果表明,这一模型在预测金融市场波动方面不仅表现优异,而且具有良好的解释力。
01 相关工作
股市预测的相关情绪数据集
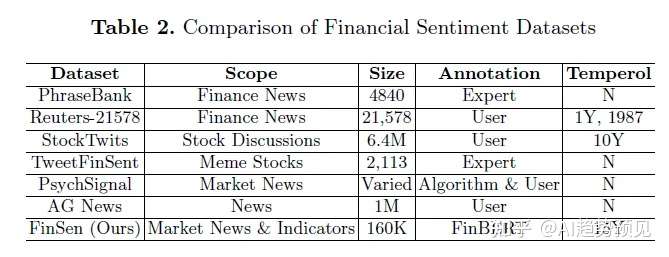
用于预测股票价格的常用情感数据集包括Financial PhraseBank、Reuters-21578新闻数据集、StockTwits数据集、TweetFinSent、PsychSignal数据集以及AG News。这些数据集中的情感信息有助于揭示市场情绪对股价波动的潜在影响。作者指出,除了情感数据外,金融指标和新闻报道也是预测股票价格的重要因素。
股票市场相关预测方法
情感分析与机器学习技术的结合在股市预测中展现出了巨大的潜力。尽管LSTM模型在提升预测准确性上表现出色,但在提供可靠置信度评估方面有所不足。以往的研究往往忽视了模型的可解释性和可信度,这可能导致实际市场应用中的投资决策失误。虽然某些现有技术在金融预测中证明了其有效性,但它们同样未充分考虑模型的透明性和可靠性。
神经网络模型校准技术
模型校准领域的工作,例如Platt Scaling和Isotonic Regression,主要聚焦于调整已训练模型的输出概率。后续提出的方法,如Focal Loss,虽然提供了更大的灵活性,但也可能表现出过度自信或过于保守的问题。不同的网络校准技术可以通过多种复杂的指标来评估其校准效果,其中包括预期校准误差(ECE)和Brier得分等。
02 数据和方法
本文以标准普尔500指数(S&P 500)的每日百分比变动作为目标变量,旨在探究其与情绪评分之间的因果关联。在确立了因果关系之后,这些情绪评分特征被整合到LSTM模型中,用于进行预测和模型校准的实验。


FinSen数据收集和预处理
本文使用了标准普尔500指数的OHLCV数据,即开盘价、最高价、最低价、收盘价和成交量,以分析价格动量和波动性特征。这些数据是从雅虎财经API获取的,覆盖了从2020年1月至2023年6月的时间段。我们的研究专注于预测标准普尔500指数的动量、波动率以及对数波动率作为监督学习的目标。
为了收集相关数据,我们采用了先进的网络爬取技术,从多个知名财经新闻网站、Trading Economics平台以及其他经济指标来源中提取新闻标题和内容。Trading Economics提供了来自196个国家超过2000万个经济指标的数据,包括汇率、股票、指数、债券及大宗商品的价格历史和实时信息。FinSen数据集整合了超过16万条记录,涵盖了15年的数据,确保了全球金融状况和时间信息的广泛代表性。

我们采用专门为财经文本优化的FinBERT模型对预处理后的财经新闻进行情感分析和标注。通过这一步骤,我们将定性的新闻内容转化为定量的情绪分数,以便更好地整合情绪数据。从FinBERT获取的情绪评分具体如下:
- 新闻的情感评分:编码的文本被输入到FinBERT中,FinBERT输出表示情感分类的逻辑。这个分数用s1表示,它的可能性范围为-1(消极)、0(中性)和+1(积极),代表了第i条新闻的情绪。
- 每日情绪汇总:为了获得每日情绪得分,我们汇总了每天所有新闻的情绪得分。第d天的每日情绪得分SAgg d = n1 d PN i=1 d((- 1∗P负)+(0∗P新)+(1∗P pos))),计算为当天所有新闻情绪得分的平均值,其中N d是第d天新闻的总数。
方法
为了评估市场情绪作为标准普尔500指数波动预测因素的潜力,我们采用了基于因果验证的情感评分方法,并结合LSTM模型进行波动率预测。具体来说,我们使用了格兰杰因果检验,将每日综合情绪得分SAgg_d作为自变量X。这一统计方法用于确定一个时间序列是否能够有效预测另一个时间序列,从而检验两个变量之间的潜在因果关系。
通过这种方法,我们考察了从金融新闻中提取的情绪得分(X)是否能够预测标准普尔500指数的波动性(y)。格兰杰因果检验帮助我们确认情绪数据与市场波动之间是否存在显著的预测关系。

在确认了市场情绪得分(X)与标准普尔500指数波动率(y)之间存在格兰杰因果关系后,我们将情绪分析融入LSTM模型以进行波动率预测。该LSTM模型不仅使用了传统输入特征,还加入了情绪得分作为额外的预测变量。这样,通过结合情感数据,我们旨在提升模型对市场波动的预测能力。
将因果验证特征嵌入DAN 3进行文本分类
我们采用DAN 3模型来进行文本分类,该模型通过以下步骤处理文本数据:首先,将标记索引转换为向量;然后,对这些向量求平均值,以生成每个文本实例的固定大小的向量表示。接下来,这个向量表示会通过一系列密集层进行处理,其间穿插批处理规范化,最终由一个映射到输出类别的数量的输出层完成分类任务。
焦点校准损失(Focal Calibration Loss)
焦点校准损失旨在应对文本分类器训练过程中的两大挑战:类别不平衡和模型预测概率的校准问题。其设计目的是在提升模型性能的同时,确保预测的概率分布与实际结果紧密一致。该损失函数结合了Focal Loss和Calibration Error两个要素,并引入了一个正则化参数λ,用于在强调难分类样本和保持模型预测适当校准之间取得平衡:

使用MAE评估校准误差
MAE(Mean Absolute Error)作为校准误差的评估方法,其理论基础源于预期校准误差(ECE)的概念。ECE是一种常用的校准度量,它通过将预测分组到不同的区间中,并比较各区间内平均预测概率与实际结果频率来评估模型的校准情况。虽然ECE提供了一种分类层面的校准估计,但MAE则提供了更为连续的、实例级别的校准测量,能够更精细地反映模型预测与真实结果之间的差异。
03 实验
建立因果关系:市场波动的情绪得分
我们的分析首先评估了标准普尔500指数波动率和新闻情绪得分的百分比变化是否平稳。通过使用增广Dickey-Fuller (ADF)检验,我们验证了这两个序列是平稳的,这使得它们适合进行格兰杰因果检验。为了探究两者之间的因果关系,我们构建了一个回归模型,用于预测标准普尔500指数的百分比变化(记为∆SP500),该模型基于金融新闻文章的情绪得分。
在这个模型中,我们考虑了过去30天的情绪得分作为预测变量,表示为X t-i,其中i的取值范围是从1到30,代表从最近一天到第30天前的情绪数据。这样的结构允许我们考察较长时间范围内的情绪变化对市场波动的影响。

我们使用方程(6)对限制性模型(不包含情绪得分)和非限制性模型(包含情绪得分)的残差进行了F检验。如果在选定的显著性水平(0.05)下,F值大于临界值,我们将拒绝原假设,这意味着情绪得分对标准普尔500指数波动具有“格兰杰因果效应”。每个F检验的原假设是:自变量的滞后值在回归中不具有显著影响。
根据这些测试的结果,我们确定了四种可能的情形,用以描述情绪得分与标准普尔500指数百分比变化(∆SP500)之间的潜在因果关系。这帮助我们更深入地理解市场情绪对股票市场波动的影响。

我们分别检验了标准普尔500指数的百分比变化(∆SP500)是否能预测情绪得分,以及情绪得分是否能预测∆SP500。对于每一个滞后长度k(从1到30天),我们都进行了单独的回归分析。F统计量在1%、5%和10%的显著性水平上,分别在滞后1天、3天、7天、14天和30天时表现出显著性。这表明情绪得分对∆SP500存在“格兰杰因果效应”。
然而,没有任何F统计量能够达到拒绝原假设的程度,这意味着∆SP500并不能“格兰杰因果”地预测情绪得分。因此,我们的结果支持了以下结论:情绪得分确实对市场波动(即∆SP500)具有“格兰杰因果效应”,而市场波动本身则未能显著预测情绪得分。
基于因果验证情感评分的LSTM增强
首先,我们利用FinBERT预训练模型对新闻文章进行句子级别的情感标注,随后将这些情感得分汇总为每日的整体情感得分。接下来,我们将市场波动率与整体情感得分一起输入到LSTM模型中,进行训练和预测。实验结果显示,加入情感得分的模型显著提升了预测效果,尤其是在14天滞后(Lag 14)的情况下,R²值达到了94.84%。这表明,基于金融新闻的情感分析能够有效辅助股市波动率的预测。

校准:嵌入增强DAN 3模型
我们使用多个数据集,包括20 Newsgroups、Financial PhraseBank、AG News和FinSen,来训练全局池化CNN网络和DAN 3模型。训练过程中采用了GloVe嵌入,并结合了交叉熵、AdaFocal、DualFocal以及Focal Calibration Loss等多种损失函数。特别地,在FinSen数据集上,使用DAN 3模型与Focal Calibration Loss的组合展现了优秀的可靠性图表和较低的ECE(预期校准误差)值。实验结果表明,FinSen数据集在ECE方面表现优异,同时分类错误率也显著降低。


04 总结
通过确立情感分数与市场波动之间的因果关系,并将这些因果验证的特征整合到LSTM模型中,我们的模型能够提供更加细致和可靠的市场预测。在文本分类任务中,FinSen数据集展现了相对更优的校准性能。特别是在使用Focal Calibration Loss训练的DAN 3模型上,ECE(预期校准误差)显著降低至3.34%,这不仅表明模型达到了高精度,还意味着其概率预测与实际结果高度一致,从而增强了模型在决策支持中的可靠性。






_web前端开发设计_荆州百度推广_百度一下首页手机版)





