
目录
1.单例模式
饿汉模式
懒汉模式
2.阻塞队列
生产者消费者模型的意义:
1,解耦合
2,削峰填谷
代码实现
3.定时器
实现步骤:
4.线程池
构造方法
拒绝策略
线程池数目设置
模拟实现线程池
1.单例模式
单例 => 单个实例(对象)
对于单例这个事情看起来是很简单的,只要保证写代码的时候,只给一个类new一次对象,不去new多次就可以,但是事实上在开发中并不能保证每个人都能完全做好这件事,所以让编译器来帮我门做监督,确保这个对象不会出现多个(如果出现直接报错),这样会更靠谱。
单例模式根据创建对象的时间分为两种实现形式,饿汉模式,懒汉模式
饿汉模式:比较急切,尽早创建实例化对象
懒汉模式:比较从容,在第一次使用的时候,再去创建实例化对象
饿汉模式
代码实现:
class SingleTon{private static SingleTon instance = new SingleTon();public static SingleTon getInstance(){return instance;}private SingleTon(){}
}要特别注意:
-
instance 用static修饰,确保instance是属于类的不属于某个方法,确保一个类只会有一个对象。
-
构造方法用private修饰,此时类外面的其他代码,就无法new出这个类的对象了
-
饿汉模式创建的时间比较早,是在类加载的时候就创建
懒汉模式
代码实现:
class SingleTonLazy{//4号位置private static volatile SingleTonLazy instance = null;public static SingleTonLazy getInstance(){if(instance == null){ //3号位置synchronized (SingleTonLazy.class){ //2号位置if (instance == null){ //1号位置instance = new SingleTonLazy();}}}return instance;}private SingleTonLazy(){}
}使用懒汉模式的时候需要特别关注线程安全。对比饿汉模式,此处添加了很多线程安全的条件。
在饿汉模式中,获取实例对象调用的方法只需读取,不用修改。
在懒汉模式中,获取实例对象调用的方法既有读取,又有修改,就可能存在问题。
分析上面懒汉中的关键条件: 1号位置:这里是在线程首次调用该方法时进行非空判断创建对象
2号位置:在多个线程都获取实例时,为保证new对象的时候只有一个线程能进行一次new对象操作从而进行上锁保护,其他线程如果也正在获取实例时,会出现锁竞争,进行阻塞等待,等正在创建对象的线程结束。
3号位置:在instance已经被new出来过后,还有很多地方需要获取实例对象,做一个非空判读,避免后续每一次都要进行上锁释放锁,上锁和释放锁也会消cpu耗资源,这样可以提高程序执行效率。
4号位置:主要是防止编译器的错误优化,禁止指令重排序。详细可以参考上一节博客volatile关键字的保证有序性线程入门4-CSDN博客
2.阻塞队列
阻塞队列是多线程代码比较常用的一种数据结构
阻塞队列是种特殊的队列
1.线程安全
2.带有阻塞的特性
a)如果队列为空,继续出队列,就会发生阻塞,阻塞到其他线程往队列里添加元素为止
b)如果队列为满,继续入队列,也会发生阻塞,阻塞到其他线程从队列中取走线程为止
阻塞队列最大的意义,就是可以用来实现”生产者消费者模型“
生产者消费者模型的意义:
1,解耦合
两个模块,联系越紧密,耦合度越高,尤其是对于分布式系统来说,是更加有意义的。
在一个简单的分布式系统中
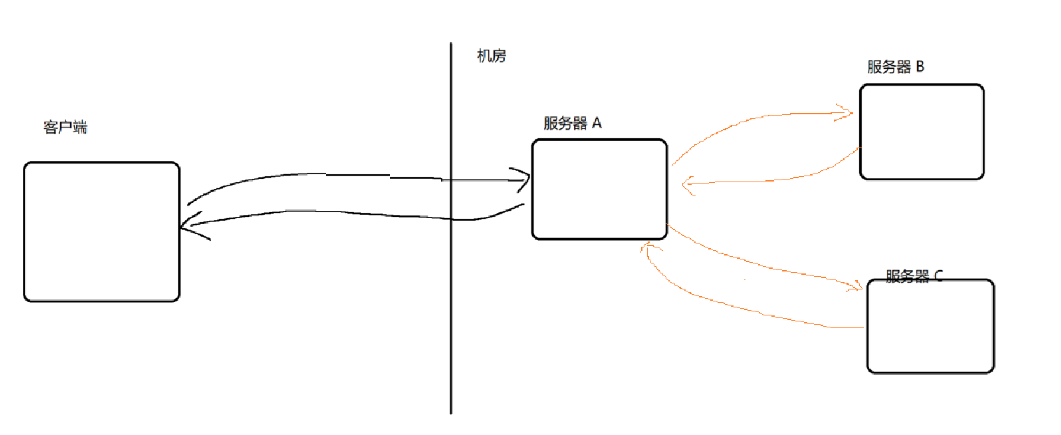
如果A 和 B 直接交互 (A把请求发给B,B把响应返回给A),彼此之间的耦合度是比较高的
a)如果B出现问题,很可能就把A影响到了
b)如果再添加一个C,就需要对A这把代码做出一些改动
相比之下,使用生产者消费者模型,就可以有效解决刚才的耦合问题
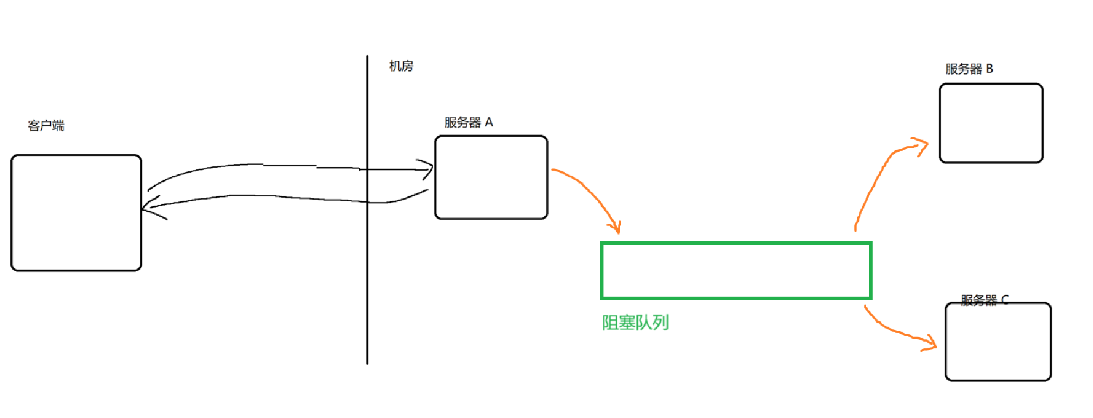
此时耦合度就被降低了,如果B出现问题了,就不会对A产生影响 (A只和队列交互,不知道B的存在)
如果后续新增一个C,此时A也不必进行任何修改,只需要让C从队列中获取数据即可
2,削峰填谷
在第一个结构中,一旦客户端这把发送的请求多了,每个A收到的请求,都会立即发给B,A抗多少访问量,B就和A完全一样,不同的服务器跑的业务不一样,虽然访问量一样,但是单个访问消耗的硬件资源是不一样的,可能A能承担这些并发量,但是B就不行然后就之间挂了(比如B操作数据库,数据库本身就是分布式系统中相对脆弱的环节)
当我们引入生产者消费者模型,上述问题也就能得到一些改善
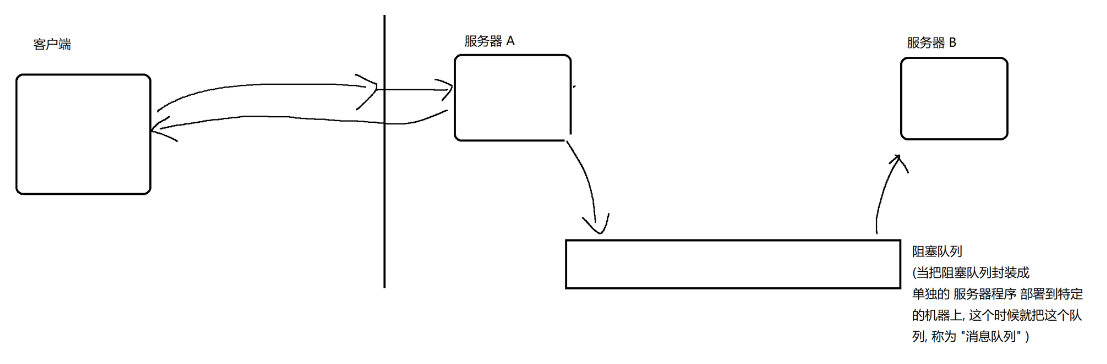
A这边收到了较大的请求量,A会把对应的请求写入到队列中,B任然可以按照之前的节奏,来处理请求。
有了这样的机制之后,就可以保证在突发情况来临的时候,整个服务器任然可以正确执行。
代码实现
基于数组实现的环形阻塞队列
//模拟实现一个阻塞队列 元素用字符串代替
class MyBlockingQueue{private String[] queue = new String[1000]; //默认数组大小为1000
//为避免内存可见性问题加上volatile关键字private volatile int size = 0; //队列中当前存在的元素的个数private volatile int head = 0; //指向队头,表示出队列的位置private volatile int tail = 0; //指向队尾,表示入队列的位置
public void put(String num) throws InterruptedException {synchronized(this){ //下面代码涉及到对数据的修改,多线程环境下可能会不安全,需要进行上锁while (size == queue.length){ //队列已经满了,无法插入this.wait(); //阻塞等待take操作结束后唤醒}//队列没满正常插入queue[tail] = num;tail++;if(tail == queue.length){ //tail已经超出最后一个位置了,需要进行修正tail = 0;}size++; //个数增加this.notify();}
}public String take() throws InterruptedException {synchronized (this){while (size == 0){//队列为空无法拿出数据this.wait(); //阻塞等待调用put方法,添加完元素,来唤醒take操作}String num = queue[head];head++;if(head == queue.length){ //超出范围,进行修正head = 0;}size--;this.notify(); //队列已经出了一个元素,有空位了,就可以唤醒put操作进行添加元素了return num;}}
}put方法阻塞式入队列,take方法阻塞式出队列
注意代码中的等待唤醒方法
一个队列,要么是空,要么是满,take喝put只有一边能阻塞。
如果put阻塞了,其他线程继续调用put也都会阻塞,只有靠take唤醒
如果take阻塞了,其他线程继续调用take还是会阻塞,只有考put唤醒
关键要点:
判断是否需要阻塞等待有两种不同的实现判断方式:

考虑wait唤醒是通过notify 还剩 Interrupt 唤醒
notify唤醒:说明其他线程调用take此时队列已经不满了,可以继续添加元素
Interrupt唤醒:此时队列其实还是满的,继续添肯定会出问题
上面两段代码的区别主要是if 和 while
当while返回的时候,需要进一步确认一下,看当前队列是不是满着的。
而当if被唤醒返回的时候,不管何种唤醒方式,如果是Interrupt唤醒,也都不会再判断是否队列是满的,这样很有可能会出问题。
建议:使用wait等待的时候,往往都是用while作为条件判定的方式,目的就是为了让wait唤醒之后还能再确认一次,是否条件任然满足。
3.定时器
定时器作为一个日常开发常见的组件,他的作用是约定一个时间,时间到达之后,执行某个代码逻辑,定时器非常常见,尤其是在进行网络通信的时候。
实现步骤:
1.需要创建一个类,通过这类的对象来描述一个任务
代码实现:
class MyTimerTask implements Comparable<MyTimerTask> {private Runnable runnable;private long time;
public MyTimerTask(Runnable r , long delay){this.runnable = r;this.time = System.currentTimeMillis()+delay;}
public Runnable getRunnable(){return runnable;}
public long getTime(){return time;}
@Overridepublic int compareTo(MyTimerTask o) {return (int)(this.time-o.time); //按照时间进行比较小根堆的方式}
}2.需要一个数据结构能够将所有的任务都保存起来
这里我们选择使用优先级队列来保存数据,根据每个任务的执行时间建立小根堆。
这样每次堆顶元素一定是需要最早执行的,每次获取最顶元素就能完成按照时间先后顺序来执行任务。
并且注意:在使用优先级队列时需要实现一个比较每个任务时间的方法
我们在任务类中实现了Comparable接口,实现了compareTo方法。
3.Timer中需要有一个线程,循环扫描任务是都到达时间,时间到了就执行任务
代码实现
class MyTimer{private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();
public void schedule(Runnable runnable,long delay){synchronized (this){queue.offer(new MyTimerTask(runnable,delay));this.notify();}
}//构造扫描线程public MyTimer(){Thread t = new Thread(()->{while (true){try {synchronized (this){while (queue.isEmpty()) {this.wait(); //队列为空就一直等待}//队列不为空,取出堆顶元素MyTimerTask task = queue.peek();long curTime = System.currentTimeMillis();if (curTime >= task.getTime()) {task.getRunnable().run(); //执行任务queue.poll(); //释放堆顶元素} else {this.wait(task.getTime() - curTime);}}}catch (InterruptedException e){e.printStackTrace();}}});t.start();}
}对于上面代码需要注意:
1.任务类,可比较问题 (实现指定比较方式)
2.线程安全问题 (加锁,阻塞等待被唤醒后需要的进一步判断再执行下一步)
3.忙等问题 (如果当前时间还没到要执行任务的时间,可以先释放锁进行指定时间的的等待)
4.线程池
线程池诞生的意义,是因为进程的创建/销毁。太重量了(比较慢)
虽然线程和进程相比,线程的创建和销毁比进程的创建销毁快不少,但是如果进一步提高创建销毁线程的频率,线程的开销也不能忽视。
提高线程创建/销毁效率的办法:
1.协程(轻量级线程)
相比于线程,把系统调度的过程给省略了,在当下是一种比较流行的并发编程手段,但是在Java圈子里,协程还不够流行。
Java的标准库中没有协程,但是有一些第三方库实现了协程。Java中实际开发也不怎么会使用这个方式更多的还是线程池。
2.线程池
这个虽然可能没协程好多少,但也不至于很慢。线程池主要是通过提前先把线程创建好,放在池子里,后续使用的时候之间从池子里取出来。
从线程池里取比创建新的线程效率高的原是:
从线程池里取:属于用户态操作
创建新的线程:需要用户态 + 内核态 相互配合完成。
(对于一段程序,如果是在系统内核中执行,此时就称为”内核态“,如果不是,则称为”用户态“)
构造方法
Java标准库中的线程池创建构造方法分析

corePoolSize 和 maximumPoolSize 分别别表示 ” 核心线程数 “ 和 ” 最大线程数 “,这个线程池里的线程数目是可以动态变化的。变化范围为[corePoolSize, maximumPoolSize]
keepAlive 和 unit 分别表示 ” 多余 空闲线程结束前最多存货的时间 “ 和 ”单位表示(ms,s,min...)“
workQueue 表示 阻塞队列,用来存放线程池中的任务
threadFactory 表示 工厂模式的体现
handler 表示 线程池的拒绝策略,当往线程池里添加的任务达到上限了,继续添可能会出现什么效果。
拒绝策略
下面是不同的拒绝策略表示不同的含义:
1.直接抛出异常

2.新添加的任务,由添加任务的线程负责执行

3.丢弃任务队列中最老的任务

4.丢弃当前新加的任务
![]()
线程池数目设置
对于一个cpu的逻辑核心数是N,此时线程池需要设置线程的数目是多少合适?
答案是不确定的,没有准确的一个数,只要说出一个具体的数都是错的!
一个线程,执行的代码主要有两类: 1.cpu密集型:代码里主要的逻辑都是在进行 算术运算 / 逻辑判断
2.IO密集型:代码里主要进行的操作都是IO操作
假设一个线程的所有代码都是cpu密集型,这个时候,线程池的数量不应该超过N (设置N就是极限了),设置比N更大,这个时候,也没法提高效率了,cpu已经吃满了,此时更多的线程反而会增加调度的开销。
假设一个线程所有的代码都是IO密集型,这个时候不吃cpu,此时设置的核心数,就是可以超过N,一个核心可以通过调度的方式来并发执行。
结论:代码不同,线程池的线程数目设置就不同,无法知道一个代码,具体多少内容是cpu密集,多少是IO密集,因此只能通过实验的方式,对程序进行测试,找到最符合需求的线程数目。
模拟实现线程池
class MyThreadPool{private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(1000);
public void submit(Runnable runnable) throws InterruptedException{queue.put(runnable); //此处策略是拒绝等待策略}
public MyThreadPool(int n){//创建n个线程,负责执行上述队列中的任务for(int i = 0; i < n; i++){Thread t = new Thread(()->{//让这个线程去队列中获取任务,并进行执行try {Runnable runnable = queue.take();runnable.run();} catch (InterruptedException e) {throw new RuntimeException(e);}});t.start();}}
}测试方法:
public static void main(String[] args) throws InterruptedException {MyThreadPool myThreadPool = new MyThreadPool(4);for(int i =0; i < 1000; i++){int id = i;myThreadPool.submit(()->{System.out.println("正在执行"+id);});}
}注意循环中我们定义了一个id,因为此处涉及到变量捕获,在匿名内部类中,变量捕获只能捕获final 或者 事实final 的变量,如果直接传i此时i一直在被修改,并不是事实final的变量。通过创建id,此处id并没有被修改,就被看作是一个事实final的变量,这样程序就不会报错。












