
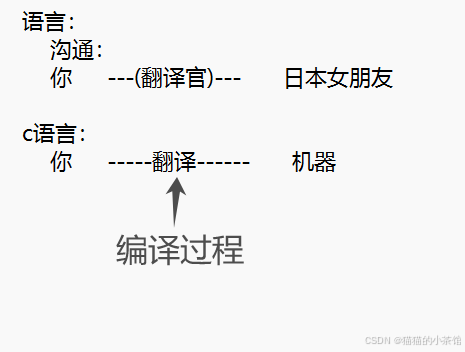
这篇文章介绍了c语言的编译过程。
在计算机底层,CPU只能做一些小事情,例如从内存中获取指令,执行所需的任务,并将输出发送回内存,做数学运算,随着时代的发展,人工智能 (AI) 和图形密集型任务对CPU的要求也在逐步提高,但基本上也还是这几件事。
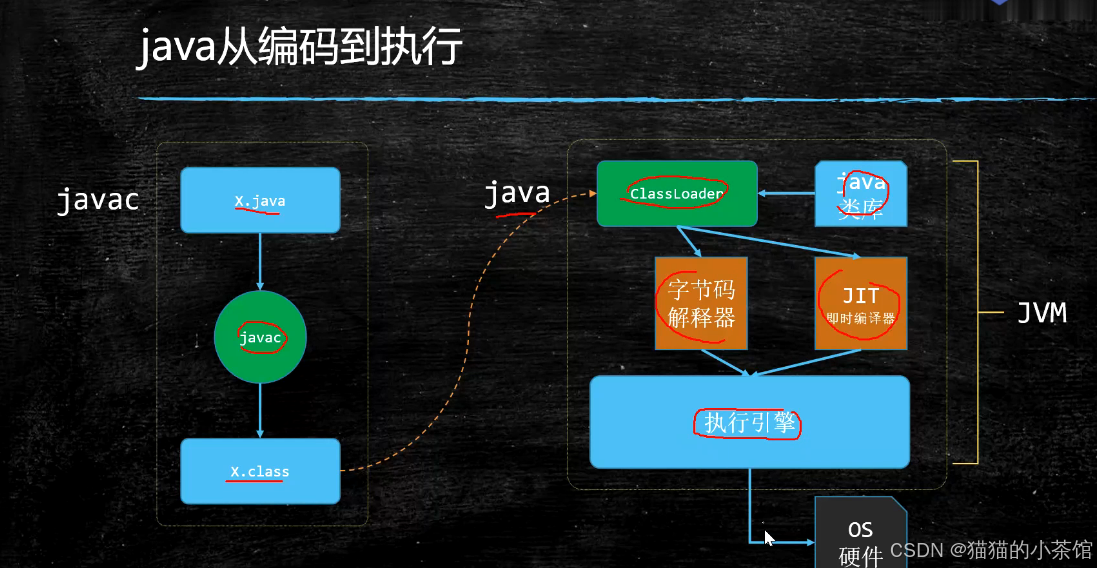
在编译器中所产生的可执行程序为机器码,才是计算机最终所识别的内容。它是一连串二进制数组成的程序(如下图),被称为机器码。机器码是实际执行的程序。
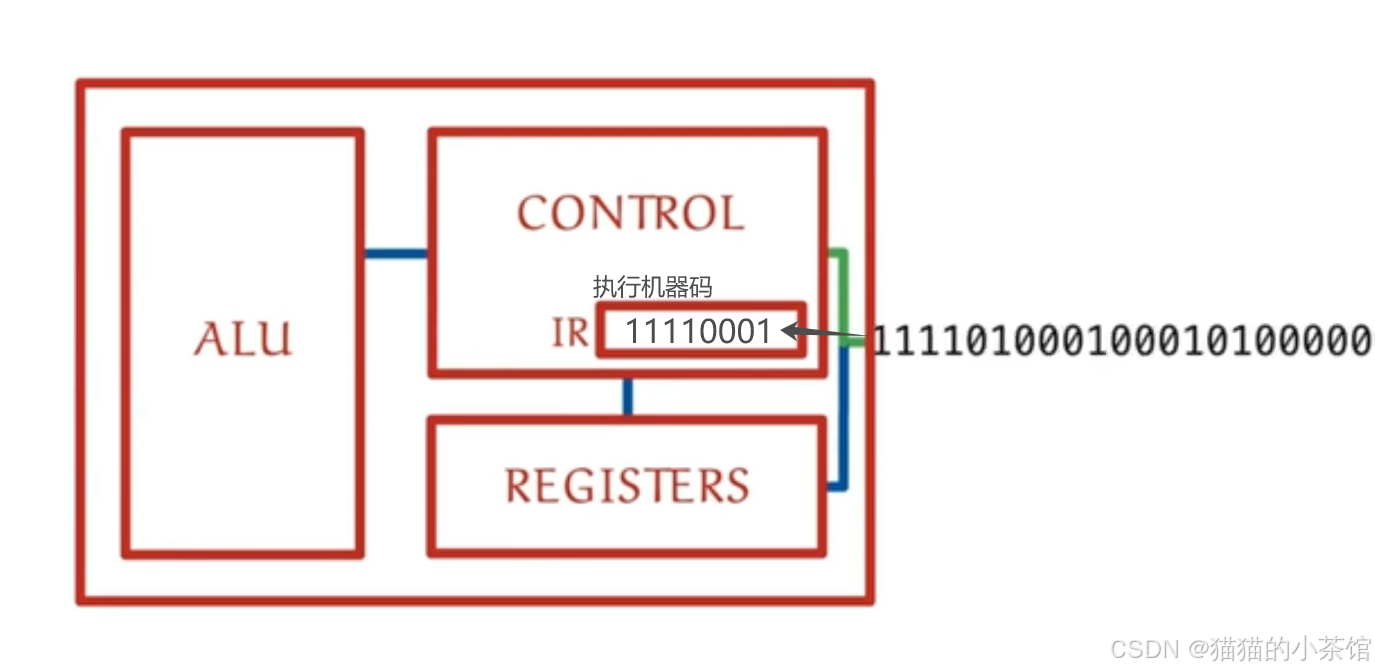
处理器已经包含了执行机器码指令的电路,但只有当相应的指令被输入时,正确的电路才会相链接,机器码指令中的1和0使得某些晶体管打开或关闭,最终正确执行输入指令的程序。
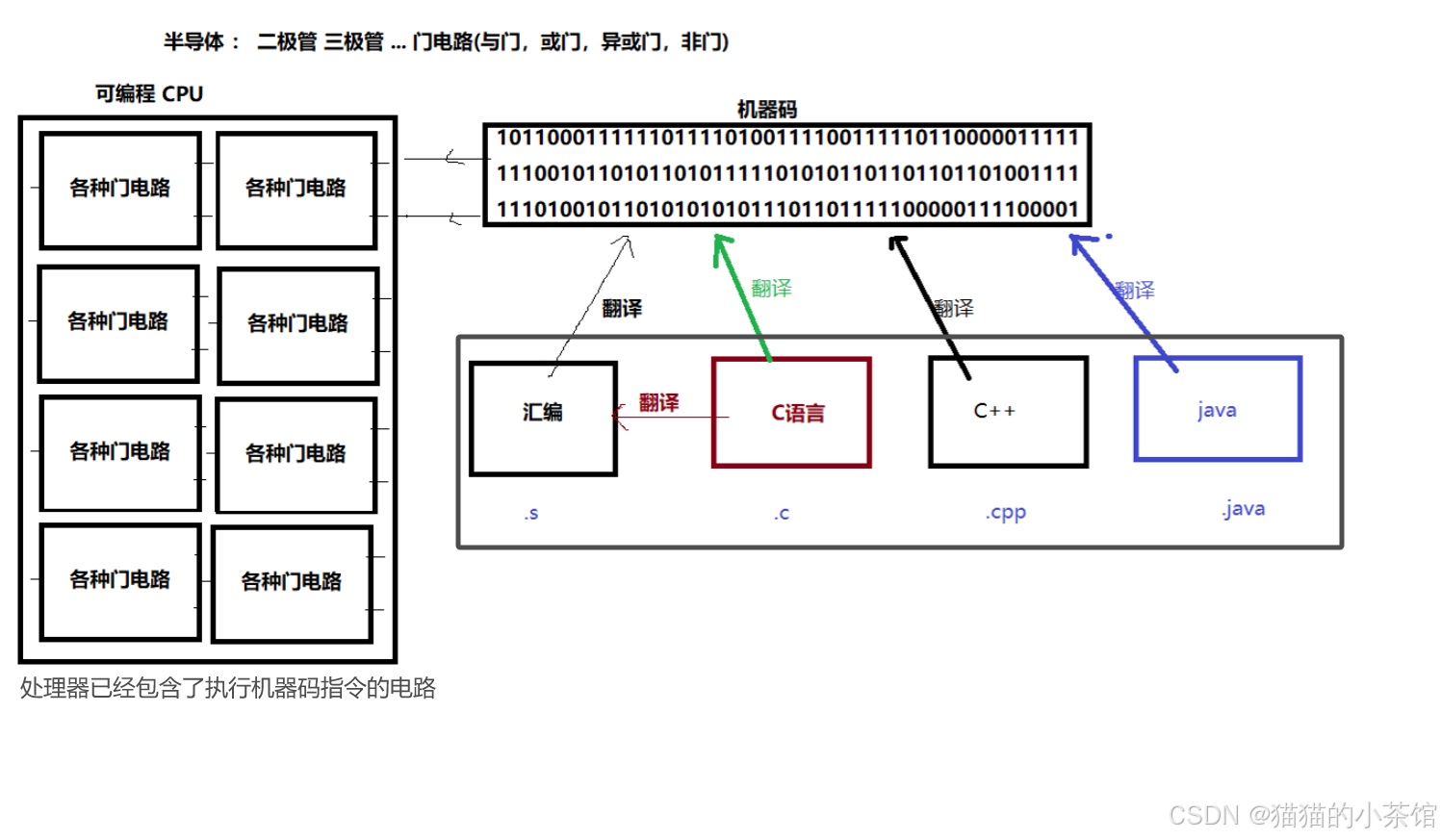
c语言的编译过程大致为:1. 创建 .c 结尾的文件2. 在文件中根据编译器的规则编写代码3. 编译器对该文件进行翻译,得到机器码4. 将机器码放入CPU中,执行程序指令


在CPU中执行:
1. 创建 .c 结尾的文件:
1. touch first.c
2. vi second.c // 在 second.c 中做保存操作,便会自动创建 second.c 文件 /vim(空格)文件名 --->这里以c语言为例
2. 在文件中根据编译器的规则编写代码:
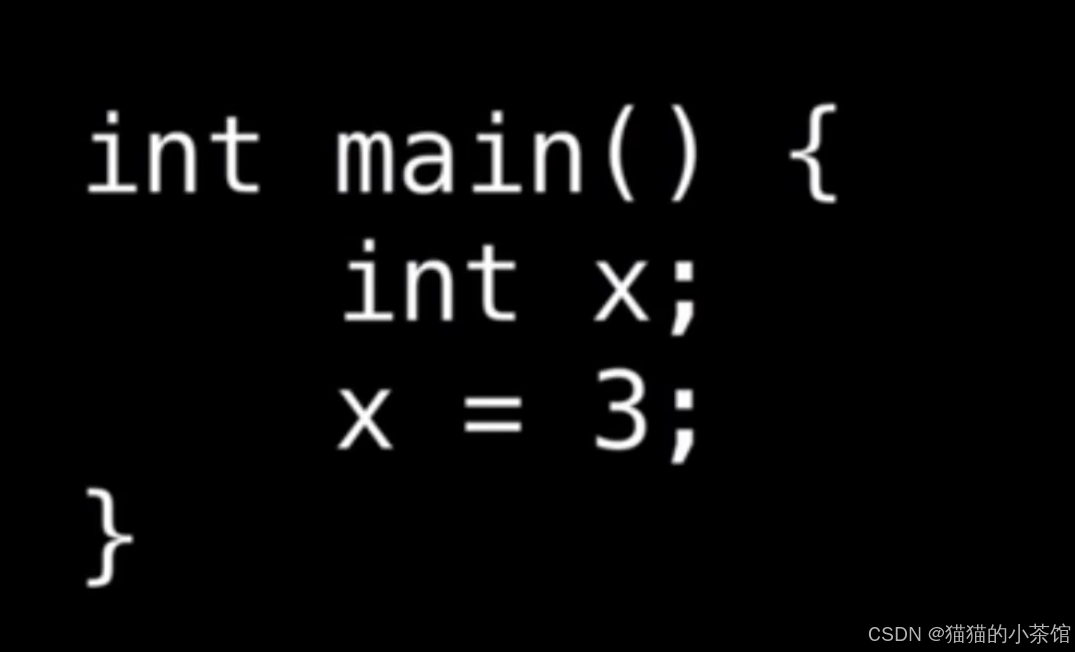
#include <stdio.h> // 引入头文件int main(void) // main函数,是程序的入口{int x = 3; // 初始化操作printf("hello girls\n"); // 在屏幕打印 双引号 里面的东西 \n 是换行的意思 return 0; // 返回值 }
以上,便是程序的源代码(人类识别),也许你认为这段代码片具有某种“结构” —— 但对于计算机而言,这仅仅只是一串毫无意义的字符,接下来,我们把这个源代码输送进编译器进行处理,看看编译器到底做了什么。
3. 编译器对该文件进行翻译,得到机器码
写法:
3.1. 编译器 gcc:
判断是否有网络: ping www.baidu.com (ctrl + c 可以使其停止)安装gcc :sudo apt-get updatesudo apt-get install gcc
3.2. 编译操作:
第一种: gcc first.c // 默认在当前路径下生成 a.out 机器码文件(可执行文件)第二种:gcc first.c -o first // 都可以指定路径// 生成 机器码文件(可执行文件) first gcc的别名用法:有时候,我们需要测试多个可执行文件,如果使用gcc直接编译,所有的文件都会叫a.out而导致被覆盖 解决:在编译的过程中,对可执行文件进行别名 使用:gcc编译器的选项:-o 用法: gcc C程序名 -o 别名
那么,gcc是如何将 一个C程序 转化为可执行文件的呢? 在编译过程中,到底发生了什么呢?
前提简要:AST(抽象语法树) 的解析和转换整个流程可以概括为:源代码→ 词法分析→ 语法分析→ AST 转换→ 生成代码→ 最终代码。
编译器的第一步是词法分析(Lexical Analysis),它从源代码中识别出一个个有意义的单元,也就是将一份源代码文本转换成抽象语法树(Abstract syntax tree,Aka AST)的过程,AST是一个token序列,token是语法中的原子单元,称为“词法单元”或“标记”(Token)。 这些词法单元通常是关键字、标识符、常量、运算符等。编译器首先将文本分割成一个个“tokens”,这有点类似于编译器在解读代码里的词汇和字符。
- 要将源代码转换为AST,可以分为三个步骤:
* 预处理
* 生成token序列
* 根据token序列生成AST

然后,“tokens”被组织进一种层次结构,这就是编译原理中常见的解析树(parse tree),第二步语法分析(Syntactic Analysis) 语法分析器大体上可以分为三种类型:通用的、 自顶向下的和自底向上的。自顶向下的方法从语法分析树的顶部(根节点)开始向底部(叶子节点)构造语法分析树,自底向上则相反。自顶向下处理文法典型为LL(1)文法,自下而上处理文法典型为LR文法。其中LR文法包括SLR、LR(1)、LALR(1)文法。语法分析器的输入总是按照从左向右的方式被扫描,每次扫描一个符号。
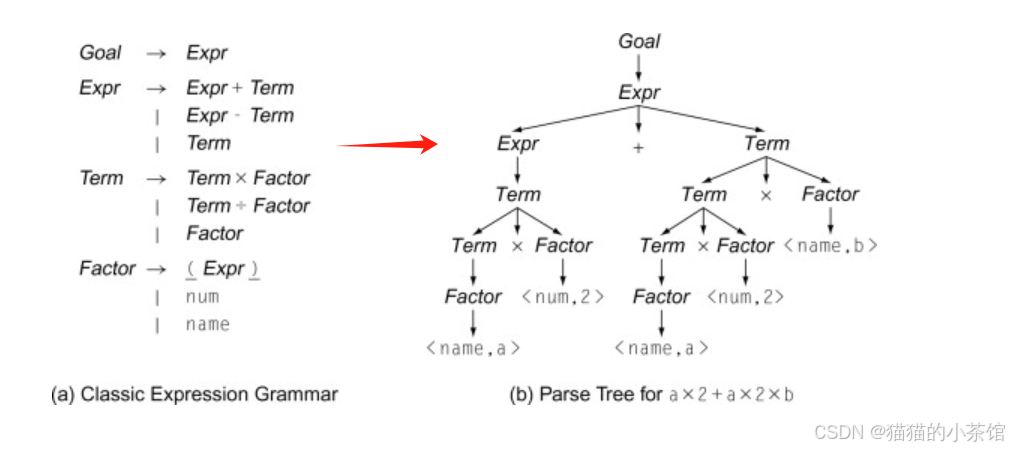
编译器通过这样的方式来搞清楚程序的语法和结构,
然后,编译器记录有关程序的上下文,进入 第三步 语义分析(Semantic Analysis)阶段。 这是编译器设计中的一个关键阶段,位于词法分析和语法分析之后。 语义分析的主要任务是确保源代码不仅在语法上是正确的,而且在语义上也是合理和有意义的。 这一阶段会检查和处理程序中的各种语义问题,包括但不限于类型检查、作用域解析、变量声明和使用的一致性、表达式的正确性等。上下文中的内容是计算机在程序的不同部分需要跟踪的东西,例如,我们的上述代码中的变量:x

PS:符号表(Symbol Table)是编程和编译器设计中的一个重要概念,它用于存储程序中定义和引用的各种符号信息,是编译器为存储变量名、函数名、对象、类、接口等各种实体的出现情况而创建和维护的一种重要的数据结构。符号表可能不会默认创建——编译器必须被要求创建一个“调试”版本,它有一个符号表(GCC编译器的- g”选项”。)一个没有符号表的程序被称为“retail”构建,而且对反向工程师更困难——因为它没有信息将二进制程序映射到原始源代码。
符号表不包括源代码,但可以通过引用实际的变量和函数名提供有关源代码的线索。在编译的二进制程序中没有变量名——所有的操作都是使用编号的寄存器完成的。在计算机科学中,符号表是语言转换器(如:编译器或解释器)使用的一种数据结构,其中程序源码中的每个标识符(或符号)、常数、过程和函数都与其在源码中的声明或appearance相关的信息相关联。换句话说,符号表的条目存储了与该条目对应的符号相关的信息。
最后,第四步遍历整个树,使得它们可以有效地执行与此特定源代码相同的操作,程序指令在树结构上有序运行程序指令。
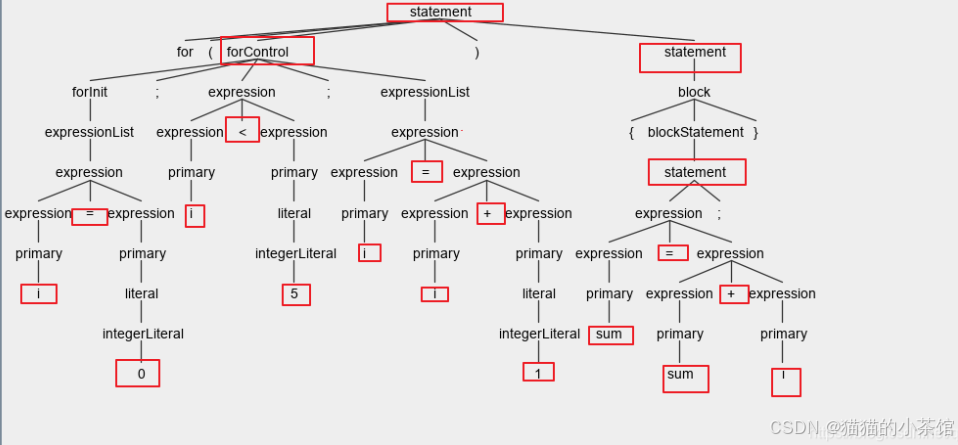
编译器通常不会直接从解析树转换到机器码,还需经过以下步骤:
中间代码生成(Intermediate Code Generation)——> 中间代码优化 ——> 目标代码生成 ——> 目标代码优化 ——> 汇编和链接(生成可执行文件)
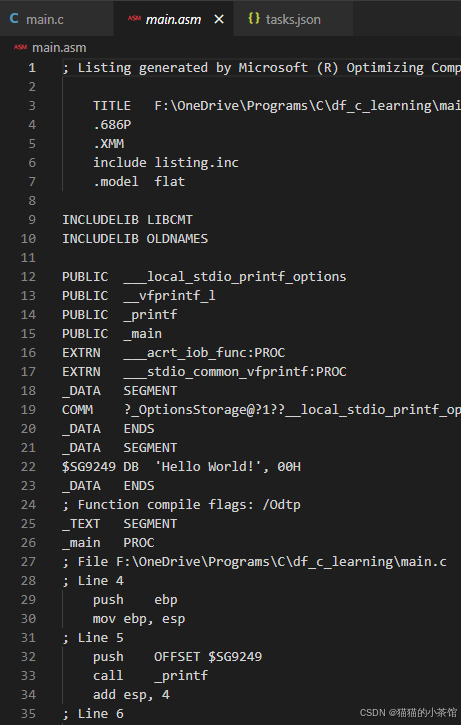
最后,经过编译后,这是机器码用二进制表示的样子↓
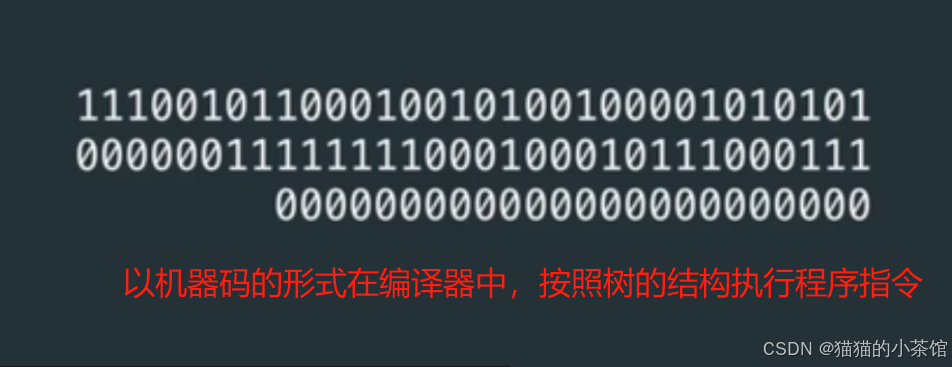
我们把它转成十六进制数:

然后,我们把它写成汇编代码,这是早期给人类阅读的机器代码版本:
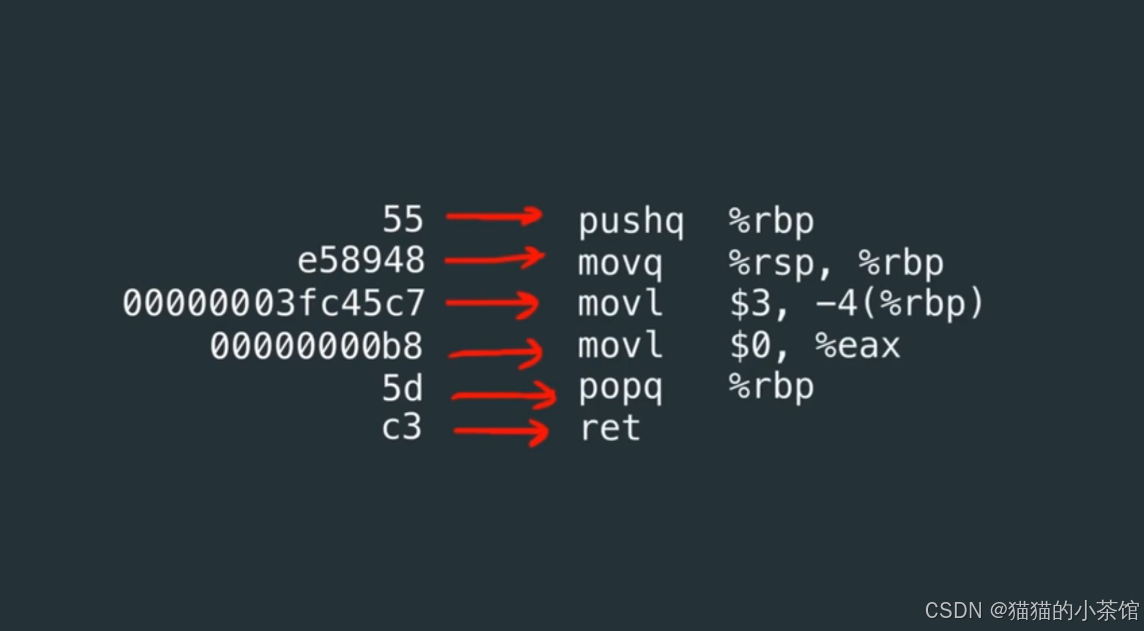
这部分汇编语言对应着源代码:
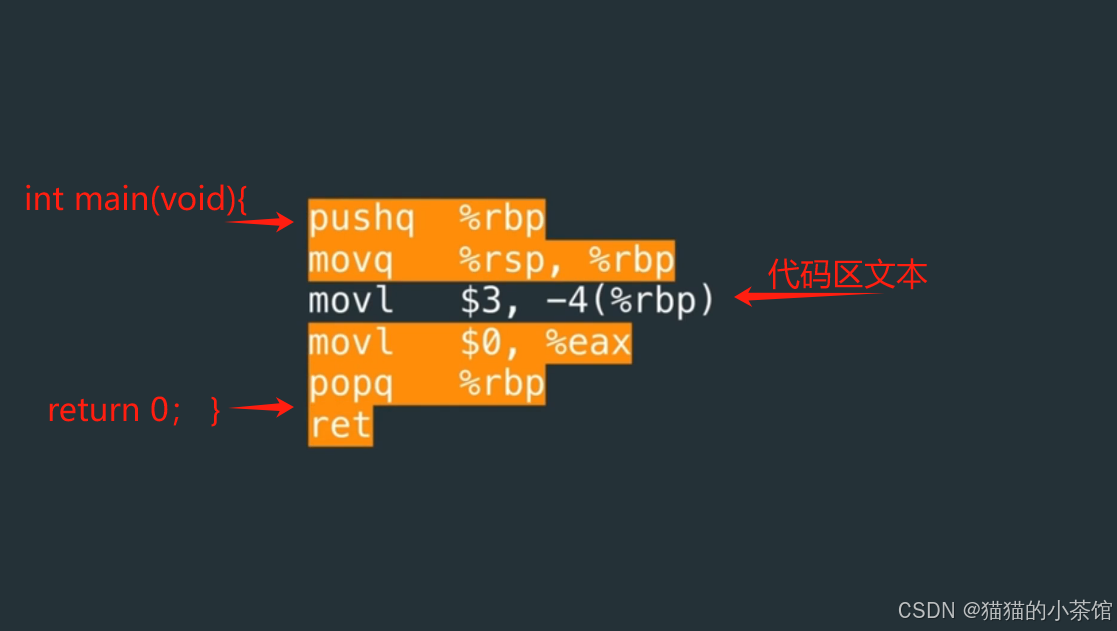
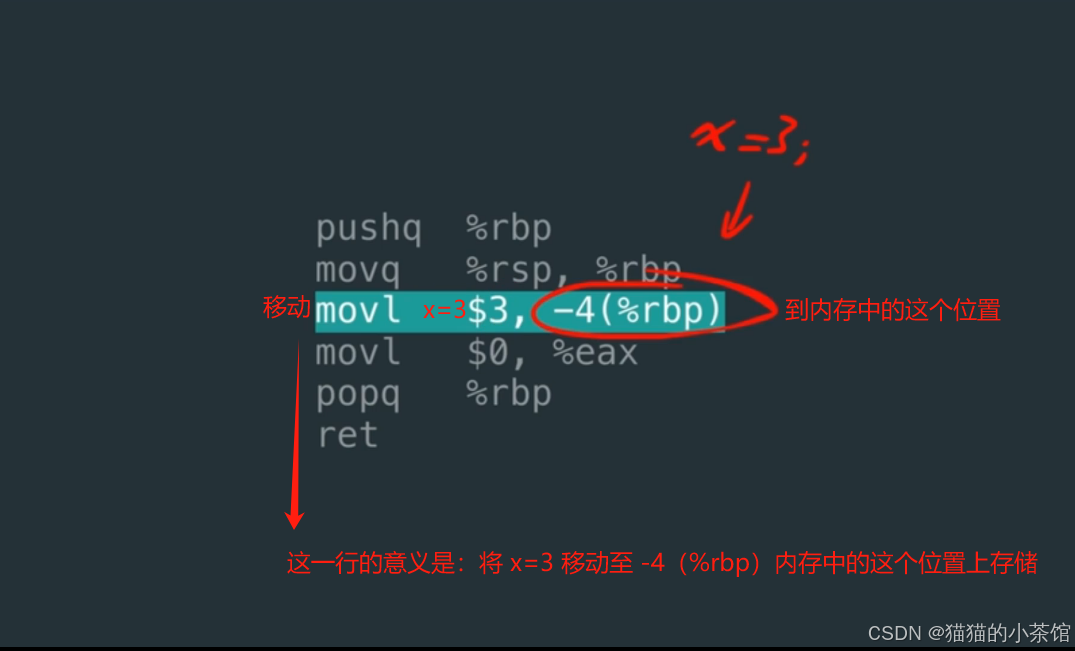
开始执行这个指令,00000003 常量被放到了对应的内存位置上。

编译器根据源代码 声明变量 int x,并给它数值 3,经历一系列过程将其翻译成机器码,并根据指令将 数值3 放入内存中的某个位置存储。

在有了上述知识储备的前提下,我们来使用 gcc 生成文件,看看每个阶段所生成的文件和代码是什么样子。
C语言的编译过程:预处理 - 编译 - 汇编 - 链接
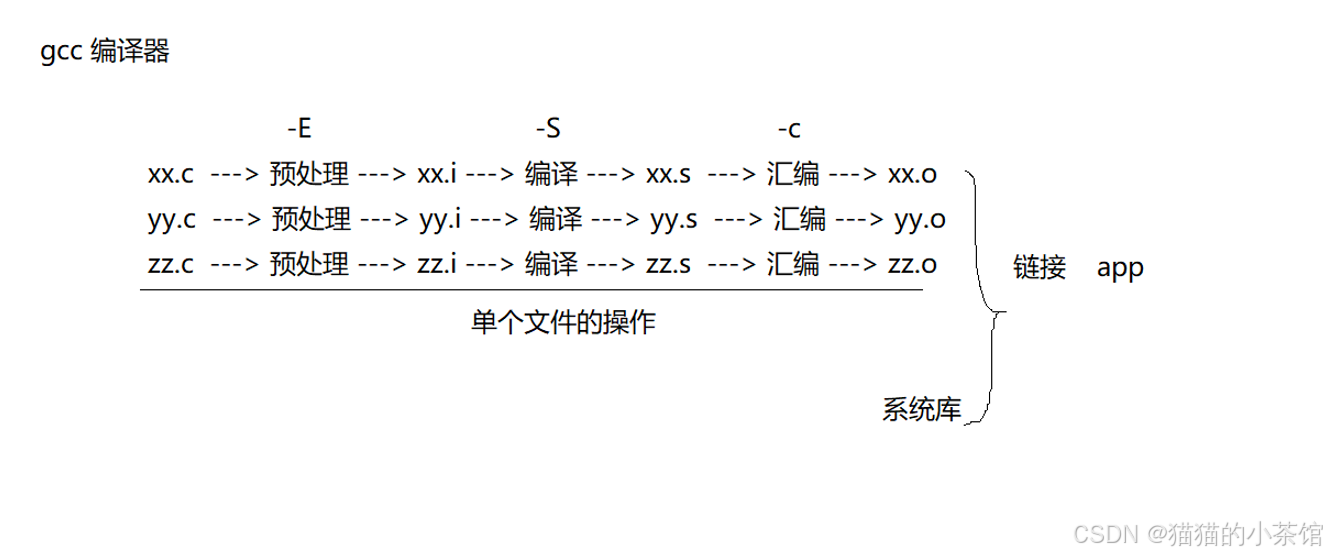
---预处理:(-E)* 加载了头文件 (将头文件的中内容拷到过来)* 处理了宏(宏展开)* 处理了注释(将所有注释全部删除)* 处理了条件编译 (#if #endif #ifndef #ifdef )gcc -E xx.c -o xx.i ---编译: (-S)* 将文件 编译成为 汇编代码(.s) gcc -S xx.i -o xx.s或: gcc -S xx.c -o xx.s ---汇编: -c* 将文件 汇编成为 目标文件(二进制文件.o) // 机器可以识别,人类无法识别 gcc -c xx.s -o xx.o 或: gcc -c xx.c -o xx.o ---链接:* 将所有的.o文件 链接 成为 可执行文件 gcc xx.o yy.o zz.o -o app // ./app 或者: gcc xx.c yy.c zz.c -o app 另外:-On : n是一个数字,优化程度 -O0 不优化-O1 数字越大,优化程度越高,编译的时间越长,运行时间越短-Wall : Warning all : 警告所有 -g : 运行进行 GDB调试例子: gcc xx.c -o app -Wall -O0 -g
生成文件可自行查看:

4. 将机器码放入CPU中,执行程序指令:
./a.out 或 ./first
对了,聊点有趣的计算机历史吧,也算是关于编译器的。
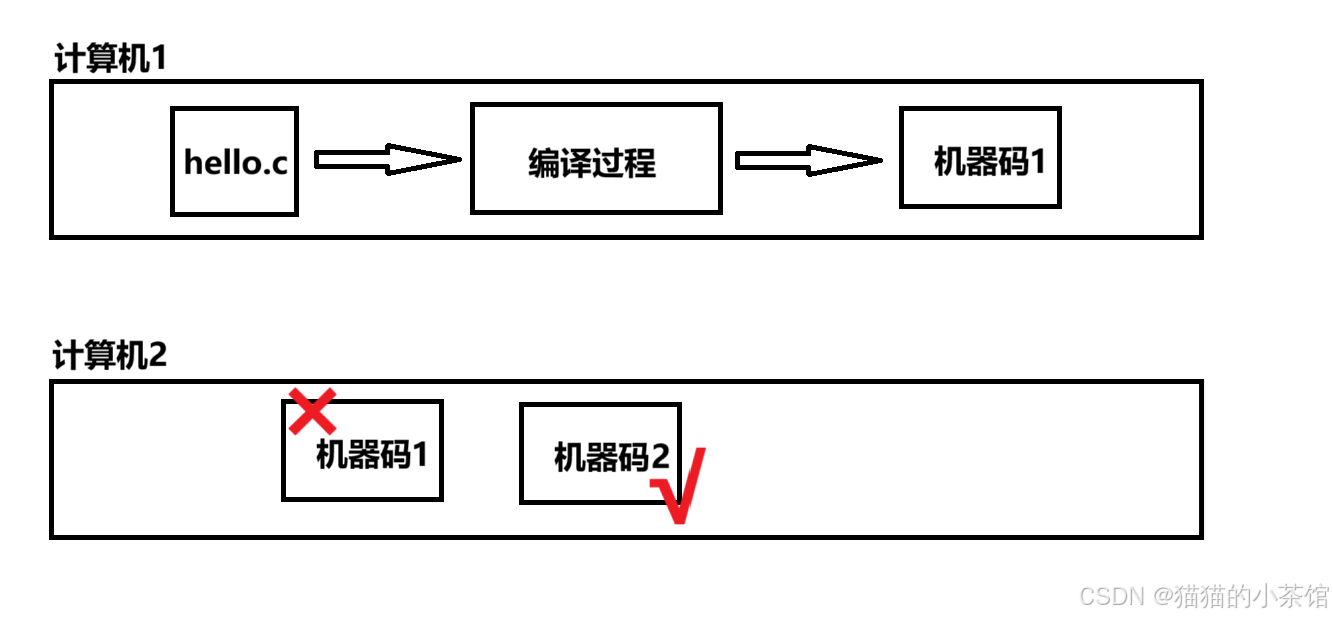
如果你编译计算机上的程序生成了机器码,然后将这段机器码复制到另一台计算机上运行。它很有可能无法运行,因为如果另一台计算机使用不同系统或者配置了不同的处理器,它可能使用不同的机器指令。所以,要想使得同一段程序在不同的计算机中运行的话,需要将这段程序编译成适合这台计算机的机器码;另外,如果使用你写的软件的用户们运行在不同的系统平台上(IOS/安卓/Windows/Linux…),也会出现这个问题,当然,有些项目是开源的↓,你可以获取它的源码自己去编译,否则,你会需要有可执行程序在你想运行的任何一个平台…(但很显然,这不太可能),所以,一些编程语言解决了这个问题,例如 .java,取代编译成机器码,javac编译器会将Java源代码编译成称为字节码的中介码,并将字节码保存到与源代码文件名相同的.class文件中。

某项目源码:↑在不同处理器和操作系统
然后,当字节码被发送至其他计算机中时,它在那边被转换成特定计算机的机器码,经由解释器的解译便可以使用。以 .class 字节码作为媒介的折中的解决方案,使得代码拥有更为良好的便携性,但它的效率较低。然而,至这样之后,咱们写的代码便可以兼容各种不同的处理器和操作系统了。
所以,你能想象以前的研究者是如何操作计算机的吗???
编程意味着将汇编语言或机器码写到打孔卡,要弄清楚每个指令该填入的正确位置,每一步都必须确保精准无误,也不可以将你的程序用在不同的计算机上,只可以在特定的计算机上运行。因为它们的指令设计各有不同。但即便如此,计算机技术也不断的发展和突飞猛进,早期科学家们的精神令人深感敬佩!!
打孔卡和计算机:




所以,在今天成为一名程序员是非常幸福的事情,你只需要写一个程序,编译它,测试输入和输出就行了,如上述4个步骤所示,甚至不需要自己动手经历编译的过程,人们能够体验到编程的乐趣,并按照自己的想法创造出各种各样的软件和工具。更有意思的是,编译器(例如 gcc)本身也是一个程序,这是一个“特别的程序”,也就是说,我们曾经有人用机器码以二进制的格式用纸片打孔机创造了编译器,(想想就强的可怕…),就像人工智能自我优化自己编程一样,创造自动化的过程就是自动化的一部分,这个过程十分神奇,当然,程序语言的发展历史非常复杂,而后,经历了几十年才达到今天我们看见的样子。↓
所以,每一次写代码的时候,都觉得十分感动,我们所使用的一切,哪怕是编译环境中微小的语法高亮显示、静态分析、面向对象编程 (OOP) 、面向过程编程(OPP)、面向切面编程(AOP)、函数式编程、函式库、链接工具、构建工具和除错工具,多种多样的类目任你挑选,甚至,编程问题看似逻辑纷繁复杂,仅仅只用顺序、分支和循环这三种流程结构就够用了。(详细了解可以去看下论文:Bohm C., Jacopini G. “Flow diagrams, Turing machines and languages with only two formation rules.” Communications of the Association for Computing Machinery, Vol.9, pp. 366–371. 1966.)(在我的资源中上传了这篇论文,感兴趣的朋友可以自行下载。)
编程并没有很难,反而,这是由一群世界上最聪明的脑子创造出来的物品。程序的世界妙趣横生。
以上。仅供学习与分享交流,请勿用于商业用途!
我是一个十分热爱技术的程序员,希望这篇文章能够对您有帮助,也希望认识更多热爱程序开发的小伙伴。
感谢!












