
一、Tesseract:
1.下载windows版: tesseract
2. 安装并记下路径,等会要填
3.保存.py文件
import pytesseract
from PIL import Image
def ocr_local_image(image_path):try:pytesseract.pytesseract.tesseract_cmd = r'D:\Programs\Tesseract-OCR\tesseract.exe'img = Image.open(image_path)text = pytesseract.image_to_string(img, lang='eng')return text.strip()except Exception as e:return "error" if __name__ == "__main__":result = ocr_local_image('1.jpg') # 只使用英语模型,简化测试print(result)4.运行代码,搞定

二、PaddleOCR
tesseract中文支持不好,我们再玩下PaddleOCR,据说中文牛P:
安装CPU版环境:
python -m uv pip install paddlepaddle==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/安装GPU版环境:
python -m uv pip install paddlepaddle-gpu==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/安装依赖:
uv pip install paddleocr终端中输入指令回车,搞定:
paddleocr --image_dir 1.jpg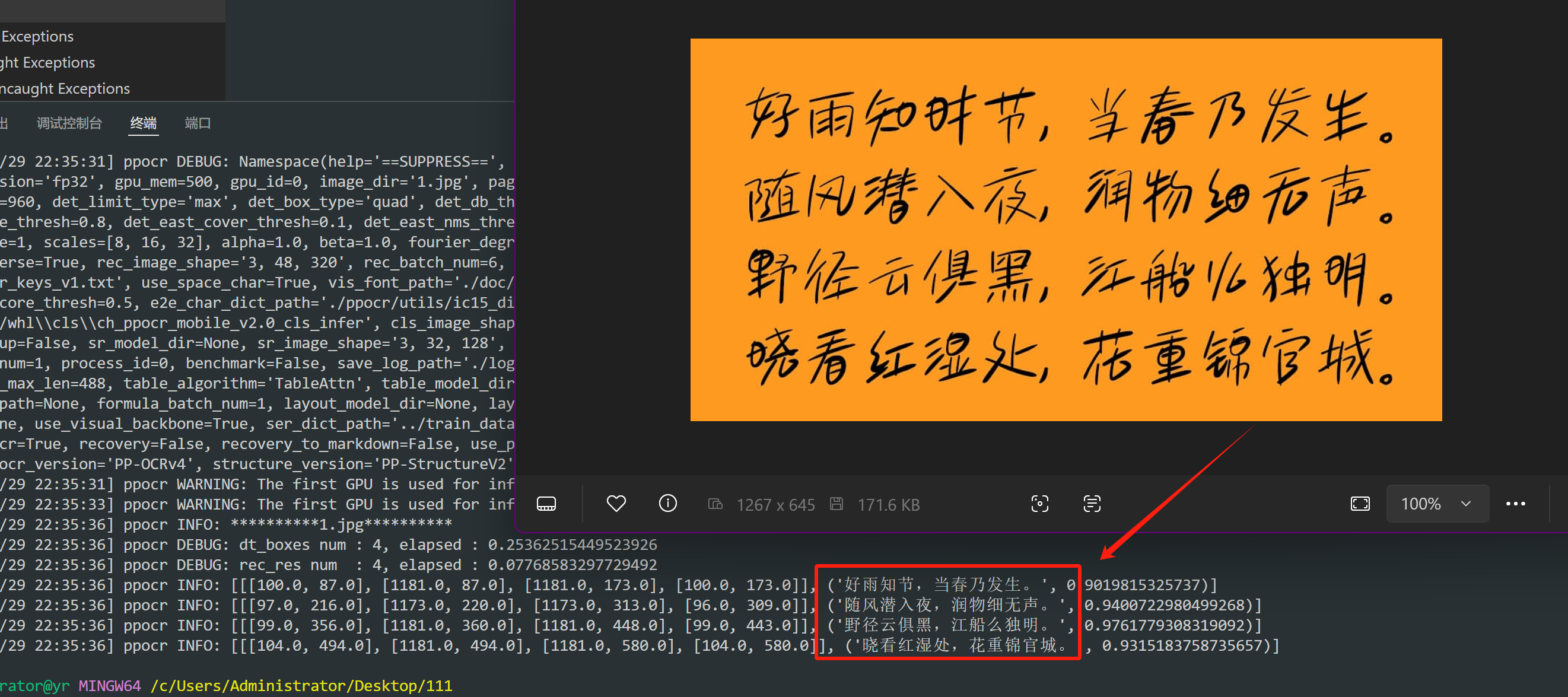
如果嫌结果太乱,代码中提取一下:
from paddleocr import PaddleOCR
ocr = PaddleOCR(lang='ch') # ch,en
img_path = '3.jpg'
result = ocr.ocr(img_path)
for idx in range(len(result)):res = result[idx]for line in res:# 只输出文本内容(通常在line[1][0]位置)而不是整个lineprint(line[1][0])
GTX1660Ti-6G,识别时间:0.6s










 "OpenCV中的轮廓检测cv2.findContours()")

