
使用QuartzNet和Pytorch实现语音文字转换(speech-to-text)
QuartzNet介绍
QuartzNet是Nvidia推出的一个轻量级的端到端语音识别模型,即使在5x15版本上仅包含18.9M个参数,在LibriSpeech-dev其他数据集上也能有超过95%的准确率。因此,凭借高吞吐量和高精度,QuartzNet可以提供帧级语音到文本推理,相比于大多数GB级别的ASR模型,QuartzNet适用于存储和计算能力有限的边缘设备上使用。
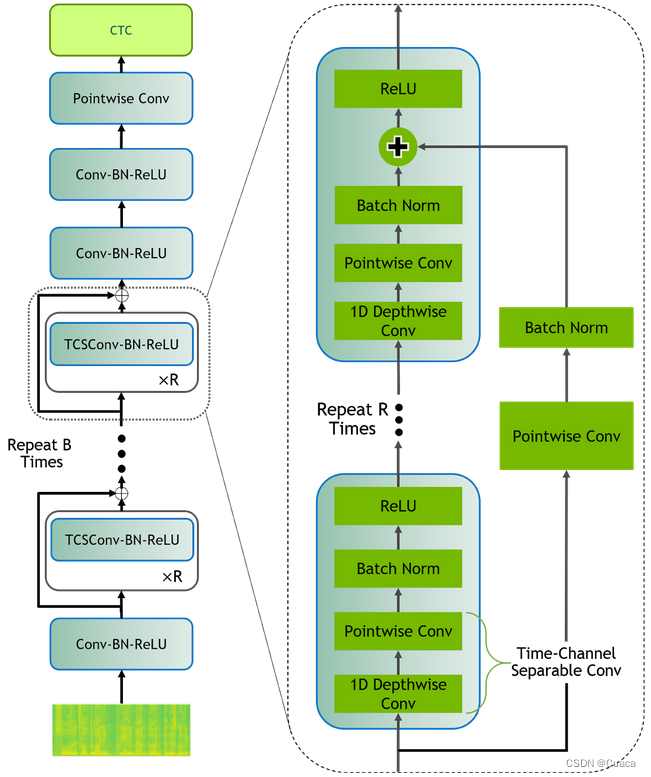
QuratzNet预训练模型
Nvidia提供了QuartzNet15x5的预训练NeMo模型,在 8xV100 GPU上以Apex/Amp O1优化级别进行训练。训练使用了LibriSpeech和Mozilla的EN Common Voice进行训练。在不使用其它语言模型的情况下,仅使用贪婪解码器,该模型在LibriSpeech 测试的WER(word error rate)为4.19%,在其他测试中的WER为 10.98%。
预训练模型使用
为了更好的将QuartzNet15x5模型应用在多种类、跨平台的应用上,我们将模型迁移到了Pytorch上,并将原来的代码尽可能解耦,以方便不同领域简单能够复用。以下为Demo的使用教程:
-
将代码克隆至本地:
git clone https://github.com/youjunl/Quartznet-pytorch.git -
进入到代码文件夹:
cd Quartznet-pytorch -
安装Python依赖:
pip install -r requirements.txt -
运行Demo,这里我们将audio文件夹下的一段demo音频转化为文本:
python try_model.py -
输出结果:
as i approached the city i heard bells ringing and a little later i found the street a stir with throngs of well dressed people in family groups winding their way thither and thither












