
人工智能咨询培训老师叶梓 转载标明出处
传统的Transformer网络设计用于处理完全连接的图,这在NLP中是可行的,因为句子中的每个词都可以与序列中的其他词相关联。然而,这种架构没有利用图的连接性,当图拓扑结构重要且未编码到节点特征中时,性能可能会很差。由南洋理工大学的研究者们提出了一种新的图Transformer网络架构,旨在解决传统Transformer在图数据上的应用问题。
新的图Transformer架构,具有以下四个新特性:
- 邻域连接性:注意力机制是基于图中每个节点的邻域连接性的函数。
- 拉普拉斯特征向量:位置编码由拉普拉斯特征向量表示,这自然地推广了NLP中常用的正弦位置编码。
- 批量归一化:用批量归一化层替代层归一化,这有助于加快训练速度并提高泛化性能。
- 边缘特征表示:架构扩展到边缘特征表示,这对于化学(键类型)或链接预测(知识图谱中的实体关系)等任务至关重要。
方法
图Transformer架构主要考虑了两个关键方面:稀疏性和位置编码,以期在图数据集上实现最佳的学习效果。
图的稀疏性
在自然语言处理(NLP)中,Transformer网络将句子视为一个完全连接的图。这种设计选择有两个原因:
-
词间交互的稀疏性:在句子中,单词之间的交互难以找到有意义的稀疏连接。例如,句子中一个词对另一个词的依赖性会随着上下文、用户视角和特定应用而变化。因此文本数据集中的句子通常没有明确的单词交互信息,这使得每个词都有必要关注句子中的其他词。
-
计算可行性:在NLP Transformer中考虑的图通常节点数量较少(少于数十或数百个节点),这使得计算上可行,并且可以训练大型的Transformer模型。
然而,在实际的图数据集中,图具有任意的连接结构,节点数量可能达到数百万甚至数十亿。这种结构为我们提供了丰富的信息,可以作为神经网络中的归纳偏置。鉴于节点数量的庞大,对于这类数据集来说,构建一个完全连接的图是不现实的。因此理想的Graph Transformer应该让每个节点只关注其局部邻居,类似于图神经网络(GNNs)。
位置编码
在NLP中,基于Transformer的模型通常会为每个词提供一个位置编码,这对于确保每个词的唯一表示并保留距离信息至关重要。然而,在图数据中设计独特的节点位置是具有挑战性的,因为存在对称性,这阻碍了规范的节点位置信息。
大多数在图数据集上训练的GNNs学习的结构化节点信息与节点位置无关。这也是为什么一些简单的基于注意力的模型(如GAT),其注意力机制是基于局部邻域连接性而非全图连接性,在图数据集上似乎无法取得有竞争力的性能。
为了解决位置嵌入的问题,Dwivedi等人(2020)利用可用的图结构预计算拉普拉斯特征向量,并将其用作节点位置信息。由于拉普拉斯特征向量是对原始Transformer中使用的位置编码的泛化,并且更好地帮助编码距离感知信息(即,靠近的节点具有相似的位置特征,而较远的节点具有不同的特征),因此在Graph Transformer中使用拉普拉斯特征向量作为位置编码。
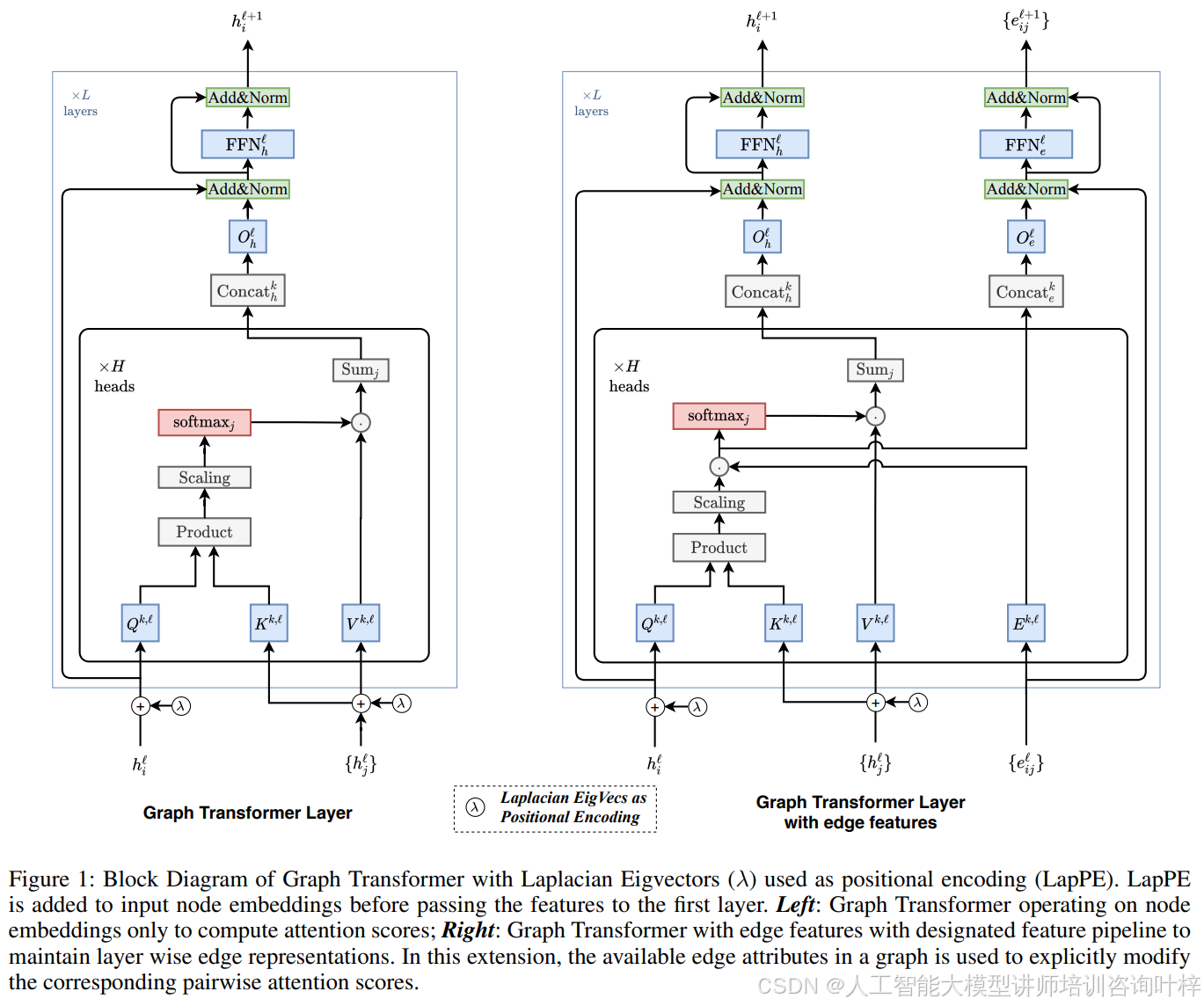
如图1所示,该图展示了带有拉普拉斯特征向量(λ)的位置编码作为输入节点嵌入的Graph Transformer的块图。左侧部分展示了图Transformer仅操作节点嵌入来计算注意力分数;右侧部分展示了具有边特征的图Transformer,具有指定的特征流水线,用于在每一层维护边的表示。
论文中介绍了两种Graph Transformer Layer:一种是为没有显式边缘属性的图设计的,另一种是为了更好地利用丰富的边缘特征信息而设计的。
输入:首先准备输入节点和边缘嵌入,以便传递给Graph Transformer Layer。对于具有节点特征αi和边缘特征βij的图G,输入节点特征αi和边缘特征βij通过线性投影传递到d维隐藏特征h0i和e0ij。
Graph Transformer Layer:Graph Transformer与最初提出的Transformer架构非常接近。定义了节点更新方程,注意力输出hˆ`+1i然后通过前馈网络(FFN)传递,该网络前面和后面都有残差连接和归一化层。
带边缘特征的Graph Transformer Layer:设计了带边缘特征的Graph Transformer,以便更好地利用图数据集中以边缘属性形式存在的丰富特征信息。这种架构将可用的边缘特征与通过成对注意力计算的隐式边缘分数结合起来。
任务型MLP层:Graph Transformer的最后一层节点表示被传递到基于任务的MLP网络,以计算任务依赖的输出,然后输入到损失函数中以训练模型的参数。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
评论留言“参加”或扫描微信备注“参加”,即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory。关注享粉丝福利,限时免费录播讲解。
实验
图Transformer在三个基准图数据集上进行了性能评估:ZINC、PATTERN和CLUSTER。
-
ZINC:这是一个分子数据集,任务是图属性回归,针对受限的溶解度。每个ZINC分子被表示为一个图,原子作为节点,键作为边。由于此数据集在键作为边属性方面有丰富的特征信息,因此使用了带有边缘特征的“图Transformer”。使用的是Dwivedi等人(2020)中的12K子集。
-
PATTERN:这是一个节点分类数据集,使用随机块模型(SBM)生成。任务是对节点进行2个社区的分类。PATTERN图没有显式的边特征,因此使用了简单的“图Transformer”。该数据集包含14K个图。
-
CLUSTER:这也是一个使用SBM模型合成生成的数据集。任务是给每个节点分配一个聚类标签,共有6个聚类标签。与PATTERN类似,CLUSTER图没有显式的边特征,因此使用了简单的“图Transformer”。该数据集包含12K个图。
模型配置遵循Dwivedi等人(2020)中引入的基准测试协议,基于PyTorch和DGL。使用了10层Graph Transformer层,每层有8个注意力头和任意隐藏维度,以使可训练参数总数在500k范围内。使用学习率衰减策略训练模型,当学习率降至1×10^-6时训练停止。每个实验使用4个不同的种子运行,并报告4次运行的平均性能。
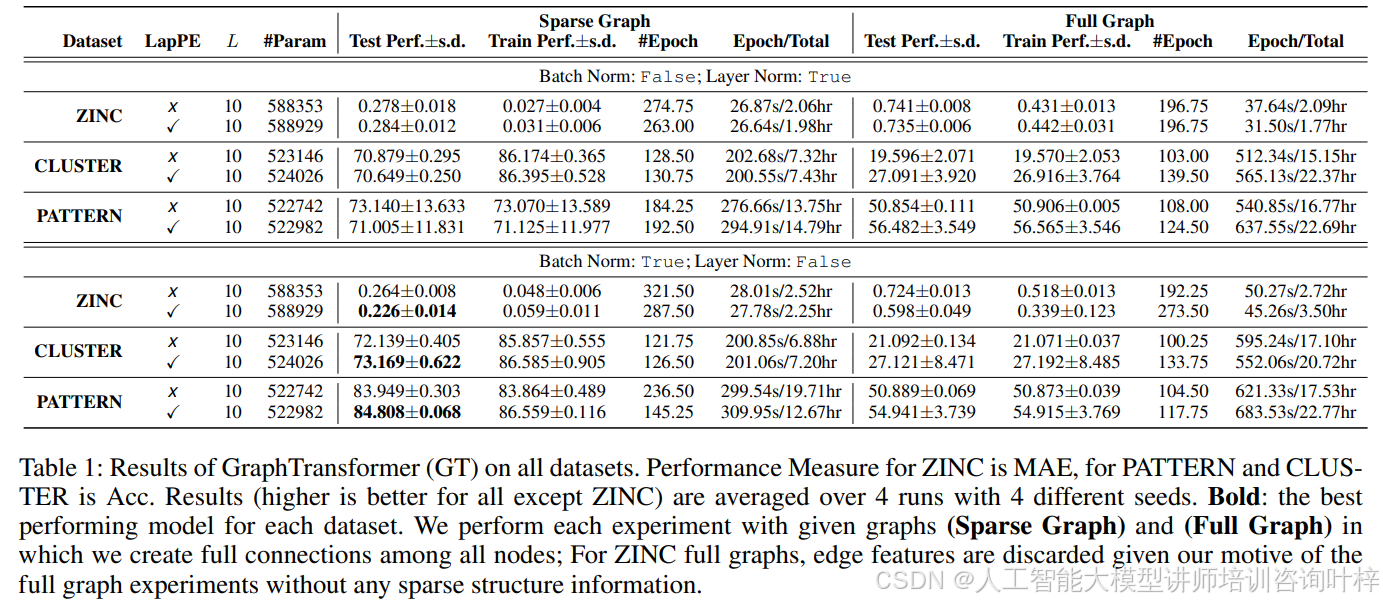
表1展示了在所有数据集上Graph Transformer(GT)的结果。ZINC的性能度量为平均绝对误差(MAE),而PATTERN和CLUSTER为准确度(Acc)。这些结果是4次运行的平均值,每次运行使用4个不同的种子,以确保结果的可靠性和一致性。在这些实验中,使用稀疏图结构的模型表现优于在完全连接的图上训练的模型,这表明稀疏性是图数据的一个关键特性。值得注意的是,对于ZINC数据集的完整图实验,边缘特征被丢弃,以探究没有稀疏结构信息时模型的性能。
表2比较了GT和基线GNN模型的性能。GT在所有数据集上都显示出比GCN、GAT和GatedGCN更好的性能,这进一步证明了GT在处理图数据方面的优越性。
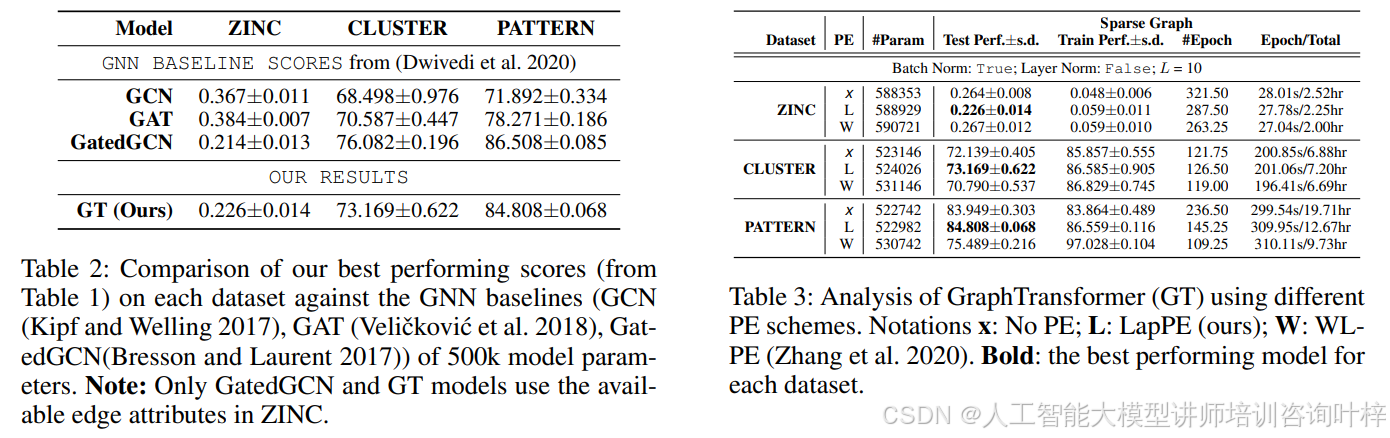
表3分析了Graph Transformer使用不同位置编码方案的结果。实验中比较了无位置编码(x)、拉普拉斯位置编码(L)、以及Weisfeiler-Lehman位置编码(W)。结果显示,拉普拉斯位置编码(L)在所有数据集上均表现最佳,这证实了拉普拉斯特征向量作为位置编码在图Transformer中的有效性。
实验结果表明,该模型在所有实验中都显示出了优越的性能,特别是在使用拉普拉斯特征向量作为节点位置编码和批量归一化时。
论文链接:https://arxiv.org/pdf/2012.09699v2
项目链接: https://arxiv.org/pdf/2012.09699v2











的连接、识别和跟踪(五)-无人机跟踪 "【学习笔记】无人机系统(UAS)的连接、识别和跟踪(五)-无人机跟踪")
