
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
在访问一个网页时,如果该网页长时间未响应,系统就会判断该网页超时,所以无法打开网页。下面通过代码来模拟一个网络超时的现象,代码如下:
import requests
# 循环发送请求50次
for a in range(0, 50):
try: # 捕获异常
# 设置超时为0.5秒
response = requests.get('https://www.baidu.com/', timeout=0.5)
print(response.status_code) # 打印状态码
except Exception as e: # 捕获异常
print('异常'+str(e)) # 打印异常信息
打印结果如图4所示。
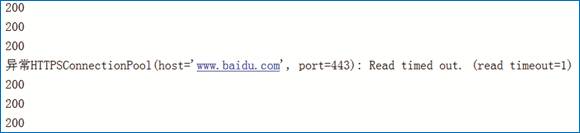
图4 异常信息
说明:上面的代码中,模拟进行了50次循环请求,并且设置了超时的时间为0.5秒,所以在0.5秒内服务器未做出响应将视为超时,所以将超时信息打印在控制台中。根据以上的模拟测试结果,可以确认在不同的情况下设置不同的timeout值。
说起网络异常信息,requests模块同样提供了3种常见的网络异常类,示例代码如下:
import requests
# 导入requests.exceptions模块中的3种异常类
from requests.exceptions import ReadTimeout,HTTPError,RequestException
# 循环发送请求50次
for a in range(0, 50):
try: # 捕获异常
# 设置超时为0.5秒
response = requests.get('https://www.baidu.com/', timeout=0.5)
print(response.status_code) # 打印状态码
except ReadTimeout: # 超时异常
print('timeout')
except HTTPError: # HTTP异常
print('httperror')
except RequestException: # 请求异常
print('reqerror')













