文章目录
- 滑动窗口
- 209.长度最小的子数组
- 3.给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串的长度。
- 713. 给你一个整数数组 nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于 k 的连续子数组的数目。
- 二叉树
- 104. 二叉树的最大深度
- 111. 二叉树的最小深度
- 112.路径总和
- 129. 求根节点到叶节点数字之和
- 1448. 统计二叉树中好节点的数目
- 双指针
- 双向双指针 接雨水
- 11. 盛最多水的容器
- 42.接雨水
- 分成一列一列 理解
- 双指针
- 栈
- 98. 验证二叉搜索树
- 单调栈
- 739. 每日温度
- 496. 下一个更大元素 I
- 1019. 链表中的下一个更大节点
- DFS
- 全排列
- 47. 全排列 II
- 回溯
- 子集回溯
- 17. 电话号码的字母组合
- 78. 子集
- 131. 分割回文串
- 模板77. 组合
- 40. 组合总和 II
- 排序
- 快排
- 计数排序
- 215. 数组中的第K个最大元素
- 链表
- 21合并两个链表
- 原地交换
- LCR 120. 寻找文件副本
- 41. 缺失的第一个正数
- 快慢指针
- 287. 寻找重复数
- 异或
- 136. 只出现一次的数字
- 二分
- 69. x 的平方根
- 240. 搜索二维矩阵 II
- 动态规划(贪心)
- 迷宫问题爆搜模板
- 200.岛屿数量
- 求面积
- BFS
- 拓扑排序
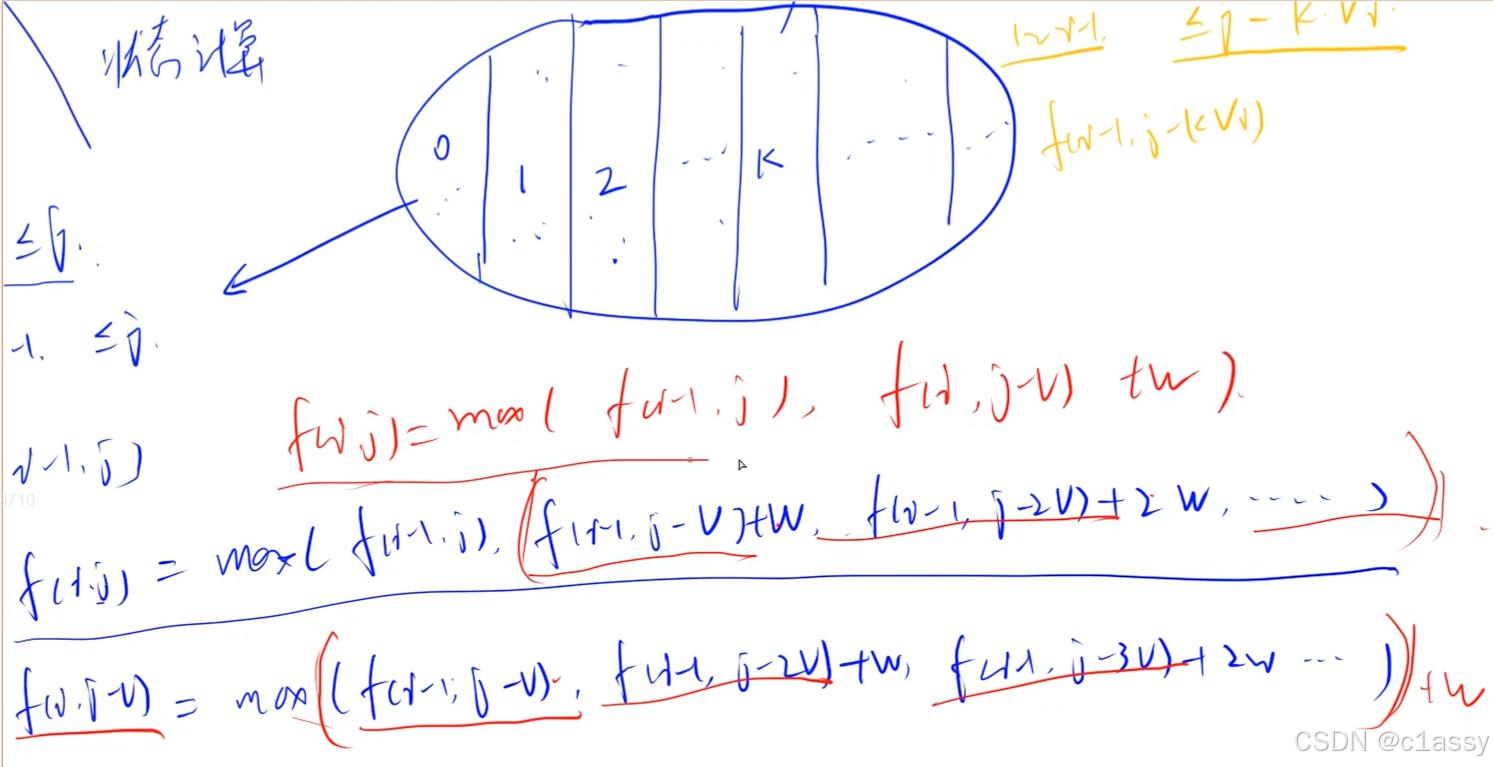
- 背包
- 01背包
- 2915. 和为目标值的最长子序列的长度
- 完全背包
滑动窗口
思路:
遍历右端点,如果不符合条件/符合条件,循环 调整左端点 直至
209.长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其总和大于等于 target 的长度最小的 子数组 [ n u m s l , n u m s l + 1 , . . . , n u m s r − 1 , n u m s r ] [nums_l, nums_{l+1}, ..., nums_{r-1}, nums_r] [numsl,numsl+1,...,numsr−1,numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
遍历右端点,如果符合条件(大于等于 target ),左端点一直调整(调整过程中更新res因为要最短的)
class Solution {
public:int minSubArrayLen(int target, vector<int>& nums) {int l=0,r=0;int res = INT_MAX;int tmp = 0;while(r<nums.size()){tmp += nums[r];while(tmp >= target){res = min(res,r-l+1);tmp -= nums[l];l++;}r++;}if (res< INT_MAX)return res;else return 0;}
};
3.给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
class Solution {
public:int lengthOfLongestSubstring(string s) {int len=s.size();int l=0,r=0;map<char,int> st;//char 次数if(len==0)return 0;int res=1;while(r<len){//l指针移到r 所在位置,因为最大的就是[l,r),这区间的不可能出现更大的了//所以将r之前的全删掉while(st[s[r]]) { //和上面一样都是whilest[s[l]]--;l++;}res=max(res,r-l+1); st[s[r]]+=1;r++; }return res;}
};
713. 给你一个整数数组 nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于 k 的连续子数组的数目。
示例 1:
输入:nums = [10,5,2,6], k = 100
输出:8
解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
示例 2:
输入:nums = [1,2,3], k = 0
输出:0
class Solution {
public:int numSubarrayProductLessThanK(vector<int>& nums, int k) {if (k==0 || k==1)return 0;int l=0,r=0;int len=nums.size();int tmp=1,res=0;while(r<len){tmp *= nums[r];//这两的顺序while(tmp>=k){//好吧,一直都是这样的,先把右端点加进去,然后while直接判断tmp /= nums[l];l++;}res += r-l+1;//如果[l,r]小于k,那么[l+1,r][l+2,r],[r]肯定也小于kr++;}return res;}
};
二叉树
千万不要一上来就陷入二叉树的细节
104. 二叉树的最大深度
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
时间复杂度: O ( n ) O(n) O(n),其中 nnn 为二叉树的节点个数。
空间复杂度: O ( n ) O(n) O(n)。最坏情况下,二叉树退化成一条链,递归需要 O ( n ) O(n) O(n) 的栈空间。
class Solution {
public:int maxDepth(TreeNode* root) {if(root==nullptr) return 0;int l=maxDepth(root->left);int r=maxDepth(root->right);return max(l,r)+1;}
};
方法2:用全局变量
class Solution {int ans = 0;void dfs(TreeNode *node, int cnt) {if (node == nullptr) return;++cnt;ans = max(ans, cnt);dfs(node->left, cnt);dfs(node->right, cnt);}public:int maxDepth(TreeNode *root) {dfs(root, 0);return ans;}
};
111. 二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
class Solution {int ans = INT_MAX;void dfs(TreeNode* root,int cnt){if(root == nullptr) return;cnt++;if(root->left == root->right){ans=min(ans,cnt);return;} dfs(root->left,cnt);dfs(root->right,cnt);return;}
public:int minDepth(TreeNode* root) {dfs(root,0);return root ? ans : 0;}
};

优化
如果递归中发现 cnt≥ans,由于继续向下递归也不会让 ans\textit{ans}ans 变小,直接返回。
这一技巧叫做「最优性剪枝」。
void dfs(TreeNode* root,int cnt){if(root == nullptr || cnt>=ans) return;cnt++;if(root->left == root->right){// node 是叶子ans=min(ans,cnt);return;} dfs(root->left,cnt);dfs(root->right,cnt);return;}
时间复杂度: O ( n ) \mathcal{O}(n) O(n),其中 n为二叉树的节点个数。
空间复杂度: O ( n ) \mathcal{O}(n) O(n)。最坏情况下,二叉树退化成一条链,递归需要 O ( n ) \mathcal{O}(n) O(n)的栈空间。
112.路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
class Solution {
public:bool hasPathSum(TreeNode* root, int targetSum) {if(root==nullptr) return false;targetSum -= root->val;//if(root->left == root->right && targetSum==0) return true;return hasPathSum(root->left,targetSum) || hasPathSum(root->right,targetSum);//}
};
129. 求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和 。
class Solution {int ans=0;void dfs(TreeNode* root, int x){if(root==nullptr) return;x = x * 10 + root->val;if(root->left==root->right) {ans += x;return;}dfs(root->left,x);dfs(root->right,x);}
public:int sumNumbers(TreeNode* root) {dfs(root,0);return ans;}
};
int goodNodes(TreeNode* root,int value=INT_MIN) {//value表示当前遇到的最大值if(root==nullptr) return 0;int left = goodNodes(root->left,max(value,root->val));int right = goodNodes(root->right,max(value,root->val));return left+right+(value<=root->val);//如果当前结点的值 < 当前遇到的最大值,该结点就符合要求}
1448. 统计二叉树中好节点的数目
给你一棵根为 root 的二叉树,请你返回二叉树中好节点的数目。
「好节点」X 定义为:从根到该节点 X 所经过的节点中,没有任何节点的值大于 X 的值。
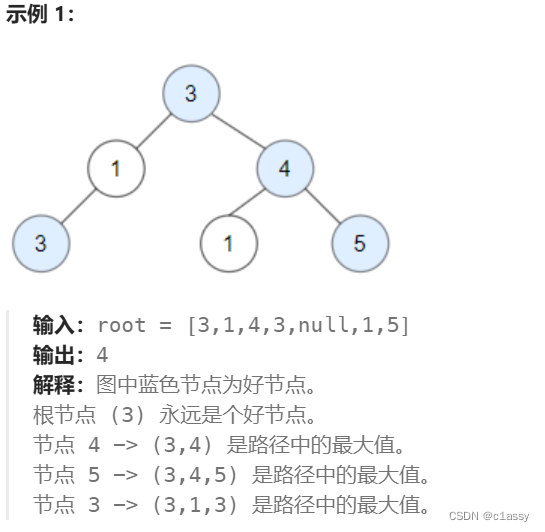
在深度优先遍历的过程中,记录从根节点到当前节点的路径上所有节点的最大值,若当前节点的值大于等于该最大值,则认为当前节点是好节点。
class Solution {int dfs(TreeNode* root,int preMax = INT_MIN){//要用参数传递更新 当前遇到的最大值的if(root==nullptr) return 0;int ans = 0;if(root->val >= preMax){preMax = root->val;ans++;}ans += dfs(root->left,preMax) + dfs(root->right,preMax);return ans;}
public:int goodNodes(TreeNode* root) {//value表示当前遇到的最大值return dfs(root);}
};
双指针
双向双指针 接雨水
11. 盛最多水的容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
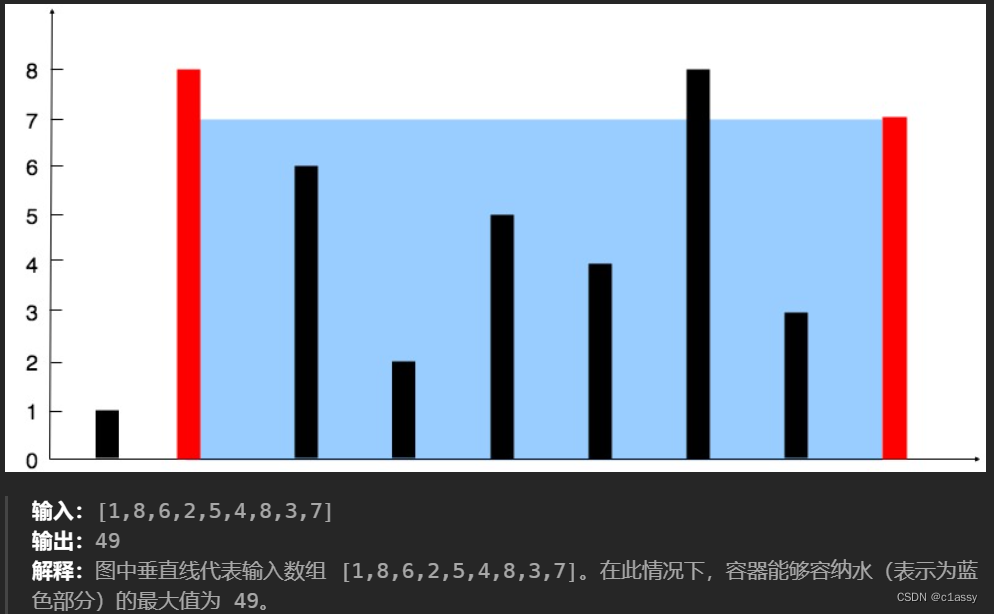
因为宽在缩小,所以 看那边高度小,就不要这个高度小的 「谁小移动谁」
第一次没有想到用双指针。。。
n = = h e i g h t . l e n g t h , 2 < = n < = 1 0 5 , O ( n 2 ) n == height.length,2 <= n <= 10^5, O(n^2) n==height.length,2<=n<=105,O(n2)会超时
在每个状态下,无论长板或短板向中间收窄一格,都会导致水槽 底边宽度 −1-1−1 变短:>
- 若向内 移动短板 ,水槽的短板 min(h[i],h[j])可能变大,因此下个水槽的面积 可能增大 。
- 若向内 移动长板 ,水槽的短板 min(h[i],h[j])不变或变小,因此下个水槽的面积 一定变小 。
class Solution {
public:int maxArea(vector<int>& height) {int len=height.size();int left=0,right=len-1;int ans=0;while(left < right){int tmp = (right-left)*min(height[left],height[right]);ans = max(ans,tmp);if(height[left]<=height[right]) left++;else right--;}return ans;}
};
42.接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
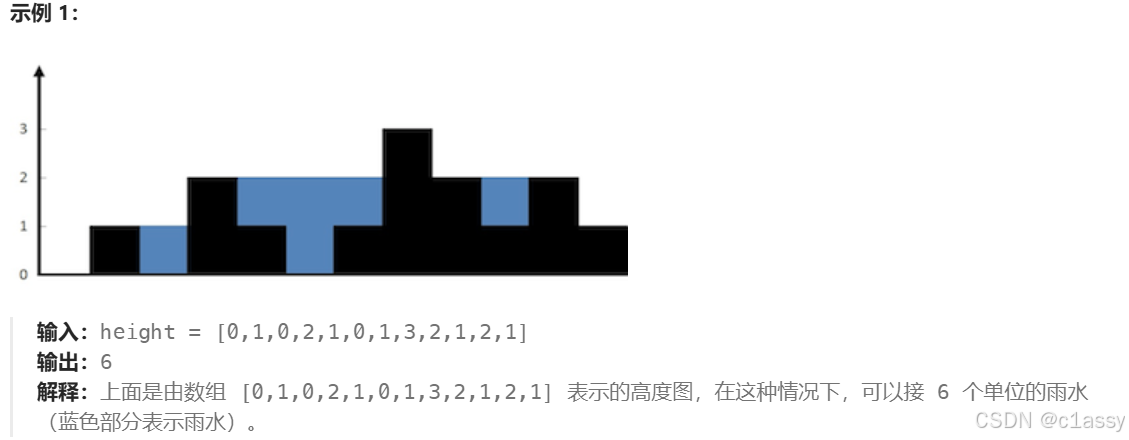
求每一列能装的水,我们只需要关注当前列,以及其左边最高的墙,和其右边最高的墙。
根据较矮的那个墙和当前列的墙的高度可以分为三种情况。
- 较矮的墙的高度大于当前列的墙的高度
- 较矮的墙的高度小于(等于)当前列的墙的高度:正在求的列不会有水,因为它大于了两边较矮的墙。
分成一列一列 理解
第一次时间复杂度 O ( n 2 ) O(n^2) O(n2),超时了
后面想,对于一个序列,每个位置的左边最大值和 右边最大值有关系------->也就是下面的动态规划里的==每个位置的左边最大值max_left [i] = Max(max_left [i-1],height[i-1])。==它前边的墙的左边的最高高度** 和它前边的墙的高度选一个较大的,就是当前列左边最高的墙了。
遍历所有列,每列能接的雨水=min(左边最大值,右边最大值)-当前高度
左边最大值dp[i]=max(dp[i-1],h[i-1]) h(i-1)是因为不包含当前这一列
右边最大值dp[i]=max(dp[i+1],h[i+1])从大到小遍历

public int trap(int[] height) {int sum = 0;int[] max_left = new int[height.length];int[] max_right = new int[height.length];for (int i = 1; i < height.length - 1; i++) {max_left[i] = Math.max(max_left[i - 1], height[i - 1]);}for (int i = height.length - 2; i >= 0; i--) {max_right[i] = Math.max(max_right[i + 1], height[i + 1]);}for (int i = 1; i < height.length - 1; i++) {int min = Math.min(max_left[i], max_right[i]);if (min > height[i]) {sum = sum + (min - height[i]);}}return sum;
}
双指针
max_left [ i ] 和 max_right [ i ] 数组中的元素我们其实只用一次,然后就再也不会用到了。所以我们可以不用数组,只用一个元素就行了。但是会发现我们不能同时把 max_right 的数组去掉,因为最后的 for 循环是从左到右遍历的,而 max_right 的更新是从右向左的。
所以这里要从两个方向去遍历。
那么什么时候从左到右,什么时候从右到左呢?
max_left = Math.max(max_left, height[i - 1]);
max_right = Math.max(max_right, height[i + 1]);
只要保证 height [ left - 1 ] < height [ right + 1 ] ,那么 max_left 就一定小于 max_right
public int trap(int[] height) {int sum = 0;int max_left = 0;int max_right = 0;int left = 1;int right = height.length - 2; // 加右指针进去for (int i = 1; i < height.length - 1; i++) {//从左到右更//当前是left,计算其左1之前的最大值和左一哪个大if (height[left - 1] < height[right + 1]) {max_left = Math.max(max_left, height[left - 1]);int min = max_left;if (min > height[left]) {sum = sum + (min - height[left]);}left++;//从右到左更} else {max_right = Math.max(max_right, height[right + 1]);int min = max_right;if (min > height[right]) {sum = sum + (min - height[right]);}right--;}}return sum;
}
栈
说到栈,我们肯定会想到括号匹配了。我们仔细观察蓝色的部分,可以和括号匹配类比下。每次匹配出一对括号(找到对应的一堵墙),就计算这两堵墙中的水。
-
当前高度小于等于栈顶高度,入栈,指针后移。
-
当前高度大于栈顶高度,出栈,计算出当前墙和栈顶的墙之间水的多少,然后计算当前的高度和新栈的高度的关系,重复第 2 步。直到当前墙的高度不大于栈顶高度或者栈空,然后把当前墙入栈,指针后移。
public int trap6(int[] height) {int sum = 0;Stack<Integer> stack = new Stack<>();int current = 0;while (current < height.length) {//如果栈不空并且当前指向的高度大于栈顶高度就一直循环while (!stack.empty() && height[current] > height[stack.peek()]) {int h = height[stack.peek()]; //取出要出栈的元素stack.pop(); //出栈if (stack.empty()) { // 栈空就出去break; }int distance = current - stack.peek() - 1; //两堵墙之前的距离。int min = Math.min(height[stack.peek()], height[current]);sum = sum + distance * (min - h);}stack.push(current); //当前指向的墙入栈current++; //指针后移}return sum;
}
时间复杂度:虽然 while 循环里套了一个 while 循环,但是考虑到每个元素最多访问两次,入栈一次和出栈一次,所以时间复杂度是 O(n)。
空间复杂度:O(n)。栈的空间。
作者:windliang
链接:https://leetcode.cn/problems/trapping-rain-water/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
方法一:前后缀分解
class Solution {
public:int trap(vector<int>& height) {int len = height.size();vector<int> pre_m(len);vector<int> after_m(len);pre_m[0] = height[0];after_m[len-1] = height[len-1];for(int i=1;i<len;i++){pre_m[i] = max(pre_m[i-1],height[i]);}for(int i=len-2;i>=0;i--){after_m[i] = max(after_m[i+1],height[i]);}int ans=0;for(int i=0;i<len;i++){ans += min(pre_m[i],after_m[i]) - height[i];}return ans;}
};
优化空间复杂度至 O ( 1 ) O(1) O(1)
方法2: 单调栈 TODO
B站讲解
class Solution {
public:int trap(vector<int>& height) {int len = height.size();int ans=0;stack<int> st;for(int i=0;i<len;i++){while(!st.empty() && height[i]>height[st.top()]){//可以接水了int j=st.top();st.pop();if(st.empty()) break;int left = st.top();int dh = min(height[left],height[i]) - height[j];//min(当前,第二个栈顶)-栈顶ans += dh * (i-left-1);}st.push(i);}return ans;}
};
98. 验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
class Solution {long pre = LONG_MIN;
public:bool isValidBST(TreeNode* root,long left=LONG_MIN,long right=LONG_MAX) {if(root==nullptr) return true;long x=root->val;return x>left && x<right && isValidBST(root->left,left,x) && isValidBST(root->right,x,right);}bool isValidBST(TreeNode* root){if(root == nullptr) return true;if(!isValidBST(root->left) || root->val <= pre)return false;pre = root->val; //中序遍历这时候 根节点return isValidBST(root->right);}
};
单调栈
739. 每日温度
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
class Solution {
public:vector<int> dailyTemperatures(vector<int>& temperatures) {stack<int> st;int n = temperatures.size();vector<int> res(n);for(int i=0;i<n;i++){//栈是单减的while(!st.empty() && temperatures[i]>temperatures[st.top()]){int j = st.top();st.pop();res[j] = i - j;//栈顶 被pop()出去,才是下一个比它大的}st.push(i);}return res;}
};
class Solution {public int[] dailyTemperatures(int[] temperatures) {int n = temperatures.length;int[] ans = new int[n];int[] st = new int[n];int top = -1;for(int i = 0; i < n; i++){int t = temperatures[i];while(top >= 0 && t > temperatures[st[top]]){int j = st[top];top --;ans[j] = i - j;}top ++;st[top] = i;}return ans;}
}
496. 下一个更大元素 I
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素

class Solution {
public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {stack<int> st;int n = nums1.size();vector<int> ans(n,-1);unordered_map<int,int> idx;for(int i=0;i<nums1.size();i++){idx[nums1[i]]=i;}for(int i=nums2.size()-1;i>=0;i--){int x=nums2[i];while(!st.empty() && x >= st.top()){//由于 往前有一个更大的,所以当前栈顶肯定不会是左边元素的 下一个更大的元素,当前栈顶没有用st.pop();}if(!st.empty() && idx.contains(x)) {ans[idx[x]] = st.top();//这维护了一个单减的单调栈,比x小的等于的 都被pop出去了,所以栈顶就是下一个比他大的}st.push(x);}for(int i=0;i<nums2.size();i++){int x = nums2[i];while(!st.empty() && x>st.top()){//从左往右,比他大的数,单调栈是递增的ans[idx[st.top()]] = x;//x是栈顶的下一个更大元素st.pop();//构造递增单调栈}if(idx.contains(x)) //该题的特殊要求st.push(x);}return ans;}
};
1019. 链表中的下一个更大节点
给定一个长度为 n 的链表 head
对于列表中的每个节点,查找下一个 更大节点 的值。也就是说,对于每个节点,找到它旁边的第一个节点的值,这个节点的值 严格大于 它的值。
返回一个整数数组 answer ,其中 answer[i] 是第 i 个节点( 从1开始 )的下一个更大的节点的值。如果第 i 个节点没有下一个更大的节点,设置 answer[i] = 0 。
class Solution {
public:vector<int> nextLargerNodes(ListNode* head) {vector<int> ans;stack<pair<int,int>> s;ListNode* cur=head;int idx=-1;while(cur){idx++;ans.push_back(0);while(!s.empty() && cur->val > s.top().first){ans[s.top().second] = cur->val;//x是栈顶的下一个更大元素s.pop();//构造递增单调栈}s.emplace(cur->val,idx);cur=cur->next;}return ans;}
};
DFS
全排列

class Solution {vector<vector<int>> ans;vector<int> path;vector<int> st;void dfs(vector<int>& nums, int i){if(i == nums.size()) {ans.push_back(path);return;}for(int j = 0; j < nums.size(); j ++ ){if(!st[j]){path.push_back(nums[j]);st[j] = 1;dfs(nums, i + 1);path.pop_back();st[j] = 0;}}}
public:vector<vector<int>> permute(vector<int>& nums) {for(int i = 0; i < nums.size(); i++) st.push_back(0);dfs(nums, 0);return ans;}
};
47. 全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
//st[j-1] == false是因为nums[j-1]在回溯的过程中被撤销选择
//candidates[j] == candidates[j - 1]是同层的,所以答案中仍然会有[1,1’,2]这样的,但是不会存在[1’,1,2]
class Solution {vector<vector<int>> ans;vector<int> path;vector<bool> st;void dfs(vector<int>& candidates, int u){if(u == candidates.size()) {ans.emplace_back(path);return;}for(int j = 0; j < candidates.size(); j++ ){if(!st[j]) {//st[j-1] == false是因为nums[j-1]在回溯的过程中被撤销选择//candidates[j] == candidates[j - 1]是同层的,所以答案中仍然会有[1,1',2]这样的,但是不会存在[1',1,2]if(j != 0 && candidates[j] == candidates[j - 1] && st[j-1] == false) continue; st[j] = true;path.push_back(candidates[j]);//从左到右依次枚举每个数,每次将它放在一个空位上;dfs(candidates, u + 1);path.pop_back();st[j] = false;}}}
public:vector<vector<int>> permuteUnique(vector<int>& nums) {sort(nums.begin(), nums.end());//先将所有数从小到大排序,这样相同的数会排在一起; 因为结果是要去重的&candidates[j] == candidates[j - 1]st = vector<bool>(nums.size(), false);dfs(nums, 0);return ans;}
};
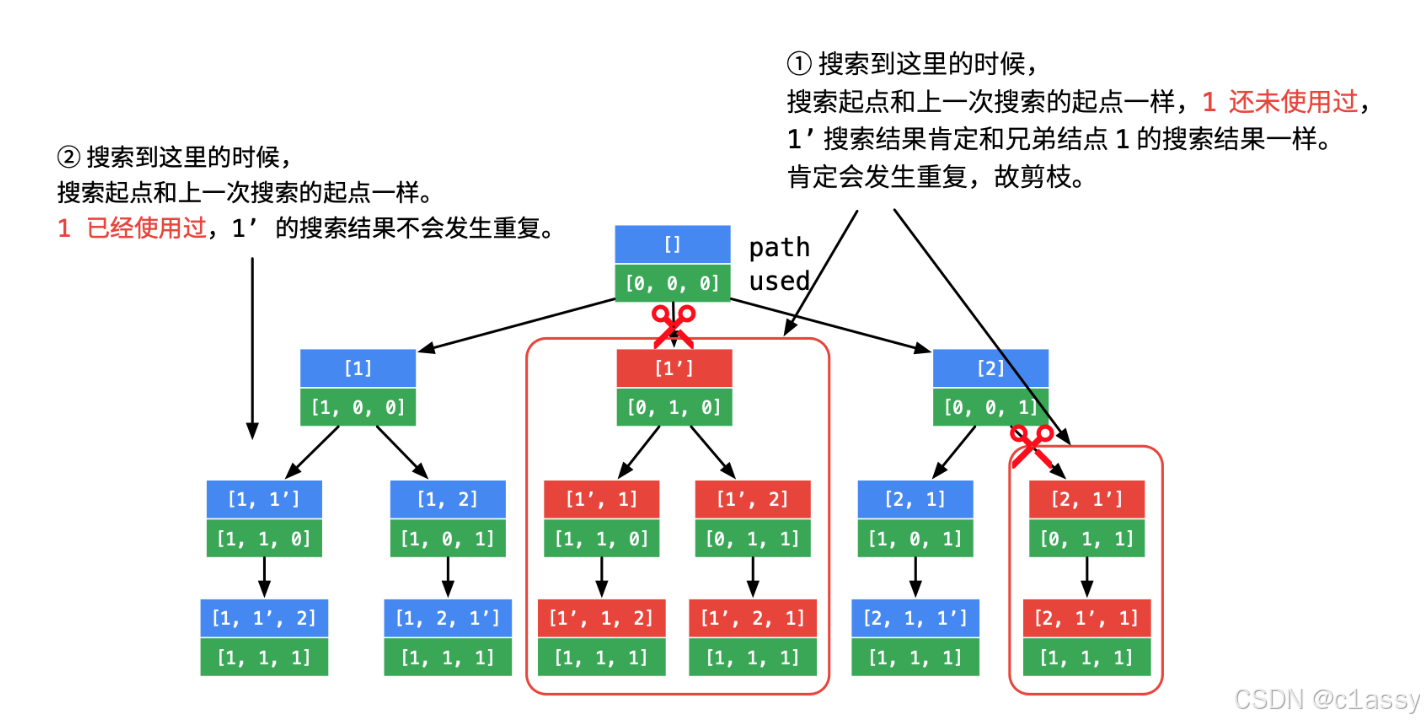
详细题解
回溯
子集回溯

递归不要想太多层(想太多反而把自己弄晕了),只需要把边界条件和非边界条件写对

17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

78. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的
子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
class Solution {string MAPPING[10] = {"","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"};//用数组表示哈希表。数组比哈希表更快void dfs(string digits,int len,int idx,vector<string>& ans,string& path){if(idx == len){//边界条件ans.emplace_back(path);return;}for(char c:MAPPING[digits[idx] - '0']){path[idx] = c;dfs(digits,len,idx+1,ans,path);//下一个子问题//不需要返回现场 因为MAPPING没有受到影响没有改变,对于idx+1,还是可以从头选择for(char c:MAPPING[digits[idx] - '0'])}}
public:vector<string> letterCombinations(string digits) {int len = digits.size();if(len==0) return {};vector<string> ans;string path(len,0);//这个不初始化,后面path一直是""dfs(digits,len,0,ans,path);return ans;}
};
每一个数字都有(3−4)个字符选择,可以算成4;总共有 n 个字符,因此有 4 n 4^n 4n种选择(状态), 对于每一种选择(状态),都需要$O(n)的时间 append 到 ans, 因此是 O ( n ∗ 4 n ) O(n*4^n) O(n∗4n)
方法一:选谁不选谁的视角
class Solution {void dfs(int i, int len, vector<int>& nums, vector<int>& path, vector<vector<int>>& ans){if(i == len) {// 子集构造完毕ans.emplace_back(path);return;}dfs(i+1,len, nums, path, ans); // 不选 nums[i]path.push_back(nums[i]);dfs(i+1, len, nums, path, ans);path.pop_back();//恢复现场}
public:vector<vector<int>> subsets(vector<int>& nums) {int len = nums.size();vector<vector<int>> ans;vector<int> path;dfs(0,len, nums, path, ans);return ans;}
};
方法二: 放在哪个位置答案的视角【不保证有序】
相似子问题分解+递归
枚举子集(答案)的第一个数选谁,第二个数选谁,第三个数选谁,依此类推。
class Solution {void dfs(int i, int len, vector<int>& nums, vector<int>& path, vector<vector<int>>& ans){if(i == len) {// 子集构造完毕ans.emplace_back(path);return;}
//如果选 nums[j] 添加到 path 末尾,那么下一个要添加到 path 末尾的数,就要在 nums[j+1] 到 nums[n−1] 中枚举了。for(int j=i;j<len;j++){path.push_back(nums[j]);dfs(j+1,len,nums,path,ans);path.pop_back();}}
public:vector<vector<int>> subsets(vector<int>& nums) {int len = nums.size();vector<vector<int>> ans;vector<int> path;dfs(0,len, nums, path, ans);return ans;}
};
131. 分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文串。返回 s 所有可能的分割方案。
示例 1:
输入:s = “aab”
输出:[[“a”,“a”,“b”],[“aa”,“b”]]
示例 2:
输入:s = “a”
输出:[[“a”]]
1. 选不选谁的视角

class Solution {bool isPalindrome(string& s, int left, int right){while(left < right)//双向 双指针 判断s[left,right]是不是回文串if(s[left++] != s[right--])return false;return true;}//通过引入一个start变量解决void dfs(int i,int start,int len,vector<vector<string>>& ans,vector<string>& path,string& s){if(i == len) {ans.emplace_back(path);return;}//不选 i 和 i+1 之间的逗号if (i < len - 1)//i=n-1 时,也就是剩最后一个的时候 一定要选(因为是将S分割的,必须包含所有的 最后一个字母必须要选上)dfs(i+1,start,len,ans,path,s);if(isPalindrome(s, start, i)){//s[start,i]//选 i 和 i+1 之间的逗号path.push_back(s.substr(start,i-start+1));dfs(i+1,i+1,len,ans,path,s);//对于s,下一个子串的选择从s的i+1开始。所以还是一个一个 看选不选path.pop_back();//恢复现场}}
public:vector<vector<string>> partition(string s) {int len = s.length();vector<vector<string>> ans;vector<string> path;dfs(0,0,len,ans,path,s);return ans;}
};
时间复杂度: O ( n 2 n ) O(n2^n) O(n2n),其中 n 为 s 的长度。每次都是选或不选,递归次数为一个满二叉树的节点个数,那么一共会递归 O ( 2 n ) O(2^n) O(2n) 次(等比数列和),再算上判断回文和加入答案时需要 O(n) 的时间,所以时间复杂度为 O ( n 2 n ) O(n2^n) O(n2n)。
空间复杂度: O ( n ) O(n) O(n)。返回值的空间不计。
2. 答案的视角(枚举子串结束位置)
class Solution {bool isPalindrome(string& s, int left, int right){while(left < right)//双向 双指针 判断s[left,right]是不是回文串if(s[left++] != s[right--])return false;return true;}void dfs(int i,int len,vector<vector<string>>& ans,vector<string>& path,string& s){if(i == len) {ans.emplace_back(path);return;}for(int j=i;j<len;j++){// 枚举子串的结束位置if(isPalindrome(s,i,j)){//s[i,j]path.push_back(s.substr(i,j-i+1));dfs(j+1,len,ans,path,s);//处理s[j+1]path.pop_back();//恢复现场}}}
public:vector<vector<string>> partition(string s) {int len = s.length();vector<vector<string>> ans;vector<string> path;dfs(0,len,ans,path,s);return ans;}
};
时间复杂度: O ( n 2 n ) O(n2^n) O(n2n),其中 n 为 s 的长度。答案的长度至多为逗号子集的个数,即 O ( 2 n ) O(2^n) O(2n),因此会递归 O ( 2 n ) O(2^n) O(2n) 次,再算上判断回文和加入答案时需要 O(n) 的时间,所以时间复杂度为 O ( n 2 n ) O(n2^n) O(n2n)。
空间复杂度: O ( n ) O(n) O(n)。返回值的空间不计。

class Solution {vector<vector<string>> ans;vector<string> path;unordered_set<string> sset;void dfs(int i,int len,string& s){if(i == len){ans.emplace_back(path);return;}for(int j=i;j<len;j++){string str = s.substr(i,j-i+1);if(sset.find(str) == sset.end()){sset.insert(str);path.push_back(str);dfs(j+1,len,s);path.pop_back();sset.erase(str);}}}public:int maxUniqueSplit(string s) {int len = s.length();int num = 0;dfs(0,len,s);for(int i=0;i<ans.size();i++){int n=ans[i].size();num = max(num,n);}return num;}
};
模板77. 组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。

class Solution {vector<int> path;vector<vector<int>> ans;void dfs(int k, int n, int idx){if (path.size() == k) { // 选好了ans.emplace_back(path);return;}for(int j = idx; j <= n; j++){ //模板循环j从当前下标开始path.push_back(j);dfs(k, n, j+1);//模板 j+1path.pop_back();}}
public:vector<vector<int>> combine(int n, int k) {dfs(k, n, 1);return ans;}
};

排序:// 这是因为数组已排序,后边元素更大,子集和一定超过 target。数组 candidates 有序,也是 深度优先遍历 过程中实现「剪枝」的前提
//将数组先排序的思路来自于这个问题:去掉一个数组中重复的元素。很容易想到的方案是:先对数组 升序 排序,重复的元素一定不是排好序以后相同的连续数组区域的第 1 个元素。
class Solution {vector<vector<int>> ans;vector<int> path;void dfs(vector<int>& candidates, int target, int i){if(target == 0) {ans.emplace_back(path);return;}for(int j = i; j < candidates.size(); j++ ){if(target - candidates[j] < 0) break;// 剪枝 不可能直接break不继续下去了path.push_back(candidates[j]);dfs(candidates, target - candidates[j], j); //这里是j的话,实现了 可以重复选;j+1是不可重复path.pop_back();}}
public:vector<vector<int>> combinationSum(vector<int>& candidates, int target) {sort(candidates.begin(), candidates.end()); // 为啥要先排序呢?降序的话会报错dfs(candidates, target, 0);return ans;}
};
40. 组合总和 II
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
if(j > start && candidates[j] == candidates[j-1]) continue; 解释:

class Solution {vector<vector<int>> ans;vector<int> path;void dfs(vector<int>& candidates, int target, int start){if(target == 0) {ans.emplace_back(path);return;}for(int j = start; j < candidates.size(); j++ ){if(target - candidates[j] < 0) break;// 剪枝 不可能直接break不继续下去了if(j > start && candidates[j] == candidates[j-1]) continue;// j > start 跳过,[1,1,5]这种,后面遇到第二个1的时候没有continue跳过path.push_back(candidates[j]);dfs(candidates, target - candidates[j], j + 1); //只用一次path.pop_back();}}
public:vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {sort(candidates.begin(), candidates.end()); // 为啥要先排序呢?降序的话会报错dfs(candidates, target, 0);return ans;}
};
排序
快排
时间: O ( n l o g n ) O(nlogn) O(nlogn)
void quick_sort(int q[], int l, int r)
{//递归的终止情况if(l >= r) return;//第一步:分成子问题int i = l - 1, j = r + 1, x = q[l + r >> 1];while(i < j){do i++; while(q[i] < x);do j--; while(q[j] > x);if(i < j) swap(q[i], q[j]);}//第二步:递归处理子问题quick_sort(q, l, j), quick_sort(q, j + 1, r);//第三步:子问题合并.快排这一步不需要操作,但归并排序的核心在这一步骤
}
快速选择 O ( n ) O(n) O(n):
int quickSort(vector<int>& nums, int l, int r, int k) { //快速选择 第k个(id:k-1)if(l == r) return nums[k];int x = nums[l], i = l - 1, j = r + 1;while(i < j) {do i ++ ; while(nums[i] > x); //从大往小 降序排do j -- ; while(nums[j] < x);if(i < j) swap(nums[i], nums[j]);}if(k <= j) return quickSort(nums, l, j, k);//已经确定第k大的元素在前半截 else return quickSort(nums, j+1, r, k);}
计数排序
时间复杂度 O ( n ) O(n) O(n)
hash是统计每个元素出现次数,s是统计出现次数的个数,比如[1,1,2,2,3] s[2]=2,s[1]=1。后面操作是,从出现次数最大的,累加到k
class Solution {
public:vector<int> topKFrequent(vector<int>& nums, int k) {unordered_map<int,int> hash;vector<int> res;for (int x : nums) hash[x] ++;int n = nums.size();vector<int>s(n + 1, 0);for (auto &p : hash) s[p.second] ++ ;int i = n, t = 0;while (t < k) t += s[i -- ];for (auto &p : hash)if (p.second > i)res.push_back(p.first);return res;}
};
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {return quickSelect(nums, k);}int quickSelect(vector<int>& nums, int k) {// 基于快排的快速选择// 随机选择基准数字int p = nums[rand() % nums.size()];// 将大于等于小于的元素分别放入三个数组vector<int> big, equal, small;for (int a : nums) {if (a < p) small.push_back(a);else if (a == p) equal.push_back(a);else big.push_back(a);}// 第k大元素在big中, 递归划分if (k <= big.size()) {return quickSelect(big, k);}// 第k大元素在small中, 递归划分if (big.size() + equal.size() < k) {return quickSelect(small, k - (big.size() + equal.size()));}// 第k大元素在equal中, 返回preturn p;}
};
链表
21合并两个链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
递归:
class Solution {public ListNode mergeTwoLists(ListNode l1, ListNode l2) {if (l1 == null) {return l2;} else if (l2 == null) {return l1;} else if (l1.val < l2.val) {l1.next = mergeTwoLists(l1.next, l2); //return l1; //} else {l2.next = mergeTwoLists(l1, l2.next);return l2;}}
}作者:力扣官方题解
链接:https://leetcode.cn/problems/merge-two-sorted-lists/solutions/226408/he-bing-liang-ge-you-xu-lian-biao-by-leetcode-solu/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
迭代:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {ListNode* pre = new ListNode(-1);ListNode* res = pre;while(list1 != nullptr && list2 != nullptr){if(list1->val < list2->val) {res->next = list1;list1 = list1->next;}else{res->next = list2;list2 = list2->next;}res = res->next;}if(list1 != nullptr) res->next = list1;else res->next = list2;return pre->next;}
};
原地交换
限制条件:时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1) 允许修改数组
LCR 120. 寻找文件副本
设备中存有 n 个文件,文件 id 记于数组 documents。若文件 id 相同,则定义为该文件存在副本。请返回任一存在副本的文件 id。
提示:
0 ≤ documents[i] ≤ n-1
2 <= n <= 100000
示例 1:
输入:documents = [2, 5, 3, 0, 5, 0]
输出:0 或 5
在一个长度为 n 的数组 nums里的所有数字都在 0 ~ n-1 的范围内 。 此说明含义:数组元素的 索引 和 值 是 一对多 的关系。因此,可遍历数组并通过交换操作,使元素的 索引 与 值一一对应(即 n u m s [ i ] = i nums[i]=i nums[i]=i )。因而,就能通过索引映射对应的值,起到与字典等价的作用。
对于 i i i,一直交换swap(nums[i],nums[nums[i]]),(该交换操作保证 nums[i]位置上一定是nums[i])
直至nums[i]=i (i位置上是i)或者找到重复的元素 i++
找到重复元素:nums[nums[i]]==nums[i] && nums[i] != i第一次出现是在i位置,第二次出现是在nums[i]位置,所以返回nums[i]
class Solution {
public:int findRepeatDocument(vector<int>& nums) {int i=0;while(i<nums.size()){if(nums[i]!=i) {// 对于i,一直交换,直至nums[i]=i或者找到重复的元素if(nums[nums[i]]!=nums[i])//因为都在[0,n)之间,不会越界swap(nums[i],nums[nums[i]]);//如果nums[x]==x,这是x第二次出现了,第一次是nums[i]=x//举例子:[3,?,?,3,;;] nums[0]=3=nums[3]=nums[nums[0]] else return nums[i];}else i++;}return -1;}
};
41. 缺失的第一个正数
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
输入:nums = [1,2,0]
输出:3
解释:范围 [1,2] 中的数字都在数组中。
示例 2:
输入:nums = [3,4,-1,1]
输出:2
解释:1 在数组中,但 2 没有。
class Solution {
public:int firstMissingPositive(vector<int>& nums) {int len = nums.size();for(int i = 0; i < len; i++) {while(nums[i] != i + 1 && nums[i] > 0 && nums[i] <= len && nums[i] != nums[nums[i]-1]) swap(nums[i],nums[nums[i] - 1]);}for(int i = 0; i < len; i++) {if(nums[i] != i + 1) return i + 1;}return len + 1;}
};
快慢指针
限制条件:时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( 1 ) O(1) O(1) 不允许修改数组
287. 寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间
不能修改数组,题目给的特殊的数组当作一个链表来看,数组的下标就是指向元素的指针,把数组的元素也看作指针。如 0 是指针,指向 nums[0],而 nums[0] 也是指针,指向 nums[nums[0]].
int point = 0;
while(true){point = nums[point]; // 等同于 next = next->next;
}
链表中的环:
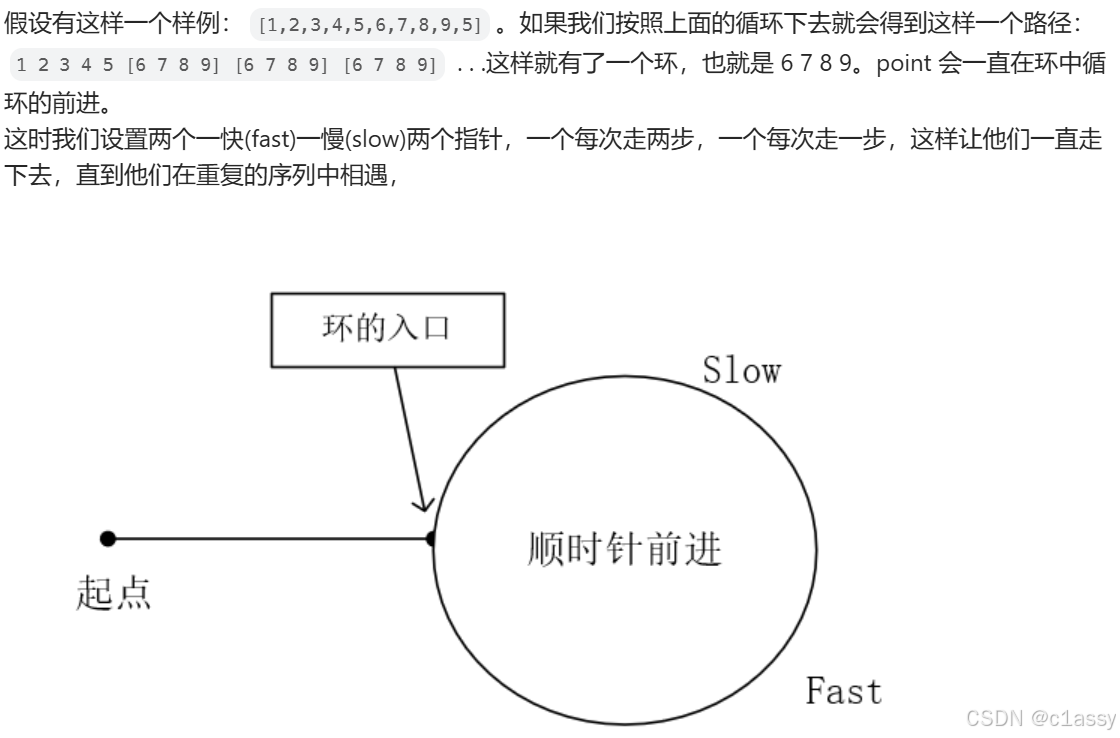
slow 和 fast 会在环中相遇,先假设一些量:起点到环的入口长度为 m,环的周长为 c,在 fast 和 slow 相遇时 slow 走了 n 步。则 fast 走了 2n 步,fast 比 slow 多走了 n 步,而这 n 步全用在了在环里循环(n%c==0)。
当 fast 和 last 相遇之后,我们设置第三个指针 finder,它从起点开始和 slow(在 fast 和 slow 相遇处)同步前进,当 finder 和 slow 相遇时,就是在环的入口处相遇,也就是重复的那个数字相遇。
为什么 finder 和 slow 相遇在入口
fast 和 slow 相遇时,slow 在环中行进的距离是 n-m,其中 n%c==0。这时我们再让 slow 前进 m 步——也就是在环中走了 n 步了。而 n%c==0 即 slow 在环里面走的距离是环的周长的整数倍,就回到了环的入口了,而入口就是重复的数字。
我们不知道起点到入口的长度 m,所以弄个 finder 和 slow 一起走,他们必定会在入口处相遇。finder走了m步刚好到入口,slow和finder走的步数一样,也是m,slow走了n+m,也刚好到入口。相遇
链接:https://leetcode.cn/problems/find-the-duplicate-number/solutions/18952/kuai-man-zhi-zhen-de-jie-shi-cong-damien_undoxie-d/
class Solution {
public:
//1.将数组等价成链表,快指针走2步慢指针每次1步 直至相遇: n%c==0
//2.再定义finder,从入口开始走直至和slow相遇。目的是使slow前进m步,(相遇时finder肯定走了m步)int findDuplicate(vector<int>& nums) {int fast = 0;int slow = 0;while(true){fast = nums[nums[fast]];slow = nums[slow];if(fast == slow) break;}int finder = 0;while(finder != slow){slow = nums[slow];finder = nums[finder];if(finder == slow) break;}return slow;}
};
异或
136. 只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
a^0 = a; a^a = 0
a1^a2^a3^a4^a5^a6...^a_{2m} ^a_{2m+1} = a_{2m+1} 假设a1-2m中每个元素出现两次,a2m+1出现一次
class Solution {
public:int singleNumber(vector<int>& nums) {int ans = 0;for(int num : nums){ans = ans ^ num;}return ans;}
};
二分
第一段满足一个性质,第二段都不满足该性质,通过二分找出边界点(满足该性质的最后一个数)
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// lower_bound 返回最小的满足 nums[i] >= target 的 i
def lower_bound(nums: List[int], target: int) -> int:left, right = 0, len(nums) - 1 # 闭区间 [left, right]while left <= right: 区间不为空# 闭区间写法# 循环不变量:# nums[left-1] < target# nums[right+1] >= targetmid = (left + right) // 2if nums[mid] < target:left = mid + 1 # 范围缩小到 [mid+1, right]else:right = mid - 1 # 范围缩小到 [left, mid-1]return left # 或者 right+1// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{while (l < r){int mid = l + r >> 1;if (nums[mid] >= target) r = mid; // 找>=target的第一个else l = mid + 1;}return l;
}// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{while (l < r){int mid = l + r + 1 >> 1;if (check(mid)) l = mid;else r = mid - 1;}return l;
}
69. x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
class Solution {
public:int mySqrt(int x) {if(x == 0) return 0;if(x < 4) return 1;int left = 0;int right = x - 1;while(left < right){int mid = (left + right) / 2;// 注意:这里为了避免乘法溢出,改用除法if(mid > x / mid) {right = mid;}else{left = mid + 1;}}return left - 1;//以前返回left的时候是left和right是数组的索引,这次是数,不一样}
};

两次二分:
第一次二分:定位到所在行(从上往下,找到最后一个满足 mat[x]][0] <= t 的行号)
第二次二分:从所在行中定位到列(从左到右,找到最后一个满足 mat[row][x] <= t 的列号)
要先找行。因为target可能大于第0行的最大的,先遍历会找不到
class Solution {
public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int m = matrix.size();int n = matrix[0].size();int rl = 0, rr = m - 1;int cl = 0, cr = n -1;while(rl < rr){int rmid = (rl + rr + 1) >> 1;if(matrix[rmid][0] <= target) rl = rmid;else rr = rmid - 1;}int row = rl;if(matrix[row][0] == target) return true;if(matrix[row][0] > target) return false;while(cl < cr){int cmid = (cl + cr + 1) >> 1;if(matrix[row][cmid] <= target) cl = cmid;else cr = cmid - 1;}int col = cl;return matrix[row][col] == target;}
};
改进成一次二分查找,利用性质:一维和二维矩阵的对应
bool searchMatrix(vector<vector<int>>& matrix, int target) {int m = matrix.size();int n = matrix[0].size();int l = 0, r = m*n - 1;while(l < r){int rmid = (l + r + 1) >> 1;if(matrix[rmid/n][rmid%n] <= target) l = rmid;else r = rmid - 1;}if(matrix[l/n][l%n] == target) return true;return false;}
240. 搜索二维矩阵 II
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
因为没有下一行肯定比上一行都大这个性质,用不了二次二分
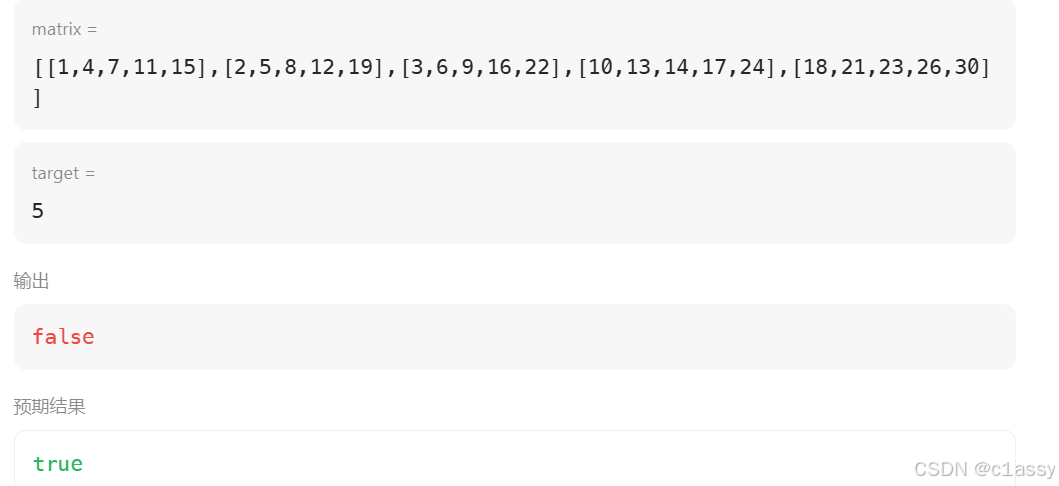
使用二分的话,时间复杂度:O(mlogn)。要对每一行使用二分查找的时间复杂度为 O(logn),最多需要进行 m 次二分查找。
抽象BST,也是Z 字形查找: 每次搜索可以排除一行或一列的元素。
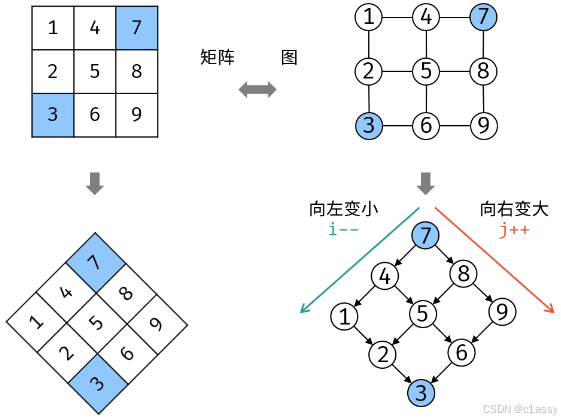
class Solution {
public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int m = matrix.size();int n = matrix[0].size();for(int i = 0, j = n -1; i < m && j >= 0; ){if(matrix[i][j] > target) j--;else if(matrix[i][j] < target) i++;else return true;}return false;}
};
动态规划(贪心)
45.跳跃游戏 II
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
0 <= j <= nums[i]
i + j < n
返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。

class Solution {
public:int jump(vector<int>& nums) {int n = nums.size();vector<int> f(n);for(int i = 1, last = 0; i < n; i ++ ) {while(i > last + nums[last]) last ++ ;//后面的i无法经由last跳到了(这里都是位置,下标)f[i] = f[last] + 1;//f[i]:从0到i需要的最短步数//if(last == i) return false; 说明无法跳到i位置了,也就无法跳到最后}return f[n-1];}
};
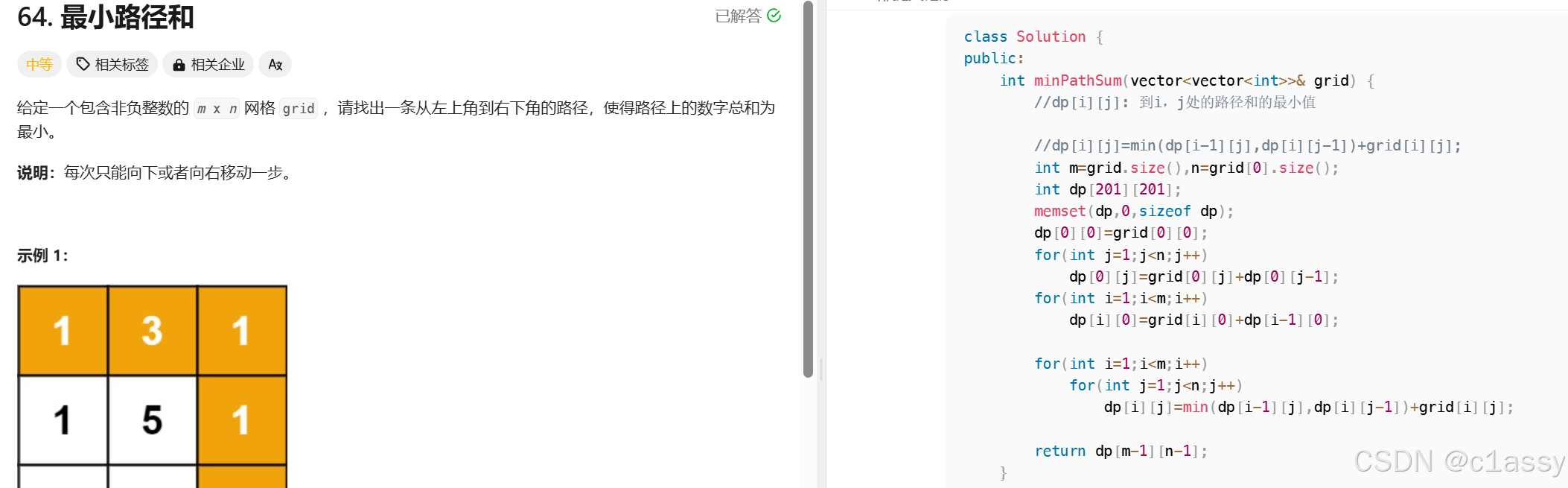
迷宫问题爆搜模板

class Solution {bool dfs(vector<vector<char>>& board, int u, string word, int i, int j) {if(board[i][j] != word[u]) return false;if(u == word.size() - 1) return true;int X[4] = {1, 0, -1,0}, Y[4] = {0, 1, 0, -1};char tmp = board[i][j];board[i][j] = '*';for(int t = 0; t < 4; t ++ ) {int nx = i + X[t], ny = j + Y[t];if(nx>=0 && ny>=0 && nx<board.size() && ny<board[0].size()) {if(dfs(board, u + 1, word, nx, ny)) return true;}}board[i][j] = tmp; return false;}
public:bool exist(vector<vector<char>>& board, string word) {for(int i = 0; i < board.size(); i ++ ) for(int j = 0; j < board[0].size(); j ++ ) if(dfs(board, 0, word, i, j))return true;return false;}
};
200.岛屿数量
还是像爆搜一样的遍历,找到1,然后dfs,将所有相连的1变为0,找完所有相连的返回。
【注意 这个不用恢复现场】
class Solution {bool dfs(vector<vector<char>>& grid, int x, int y) {if(grid[x][y] == '0') return false;int X[4] = {1,0,-1,0}, Y[4] = {0,1,0,-1};grid[x][y] = '0';for(int i = 0; i < 4; i ++ ) {int a = x + X[i], b = y + Y[i];if(a >= 0 && a < grid.size() && b >= 0 && b < grid[0].size()) {if(dfs(grid, a, b)) return true;}}return false;}
public:int numIslands(vector<vector<char>>& grid) {int ans = 0;for(int i = 0; i < grid.size(); i ++ ) for(int j = 0; j < grid[0].size(); j ++) if(grid[i][j] == '1') {ans ++;dfs(grid, i, j);}return ans;}
};
求面积
public int maxAreaOfIsland(int[][] grid) {int res = 0;for (int r = 0; r < grid.length; r++) {for (int c = 0; c < grid[0].length; c++) {if (grid[r][c] == 1) {int a = area(grid, r, c);res = Math.max(res, a);}}}return res;
}int area(int[][] grid, int r, int c) {if (!inArea(grid, r, c)) {return 0;}if (grid[r][c] != 1) {return 0;}grid[r][c] = 2;return 1 + area(grid, r - 1, c)+ area(grid, r + 1, c)+ area(grid, r, c - 1)+ area(grid, r, c + 1);
}boolean inArea(int[][] grid, int r, int c) {return 0 <= r && r < grid.length && 0 <= c && c < grid[0].length;
}
题解类似的题
BFS
class Solution {int ans = -1;int fresh = 0;void bfs(vector<vector<int>> &grid){queue<pair<int, int>> q;//多源BFSfor(int i = 0; i < grid.size(); i ++) for(int j = 0; j < grid[0].size(); j ++){if(grid[i][j] == 2) q.push({i,j});if(grid[i][j] == 1) fresh ++;} int dx[4] = {1,0,-1,0}, dy[4] = {0,1,0,-1};while(!q.empty()) {ans ++; //为啥以-1开始,这时候是0分钟int sz = q.size();while(sz--) {auto t = q.front(); q.pop();for(int i = 0; i < 4; i ++) {int x = t.first + dx[i], y = t.second + dy[i];if(x < 0 || x >= grid.size() || y < 0 || y >= grid[0].size()) continue;if(grid[x][y] == 1) {fresh --;q.push({x,y}); grid[x][y] = 2; }}}}}
public:int orangesRotting(vector<vector<int>>& grid) {bfs(grid);return fresh ? -1 : max(ans, 0);;}
};

拓扑排序
class Solution {
public:bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {int n = prerequisites.size();vector<int> result;vector<int> inDegree(numCourses, 0);//记录入度数unordered_map<int, vector<int>> umap;//数据结构中的啥表啊for (int i = 0 ; i < n ; i ++ ) {inDegree[prerequisites[i][1]] ++;umap[prerequisites[i][0]].push_back(prerequisites[i][1]);}queue<int> que;for (int i = 0 ; i < numCourses ; i ++ ) {if (inDegree[i] == 0) {que.push(i);}}while(que.size()) {int cur = que.front();que.pop();result.push_back(cur);vector<int> files = umap[cur];if (files.size()) {for (int i = 0 ; i < files.size() ; i ++ ) {inDegree[files[i]] --;if (inDegree[files[i]] == 0) que.push(files[i]);}}}if (result.size() == numCourses) {return true;}else {return false;}}
};
法2:DFS是否有环
class Solution {bool dfs(unordered_map<int, vector<int>>& mPre, vector<int>& inDegree, vector<int> mVisit, int i) {if(mVisit[i] == 1) return false;if(inDegree[i] == 0) return true;mVisit[i] = 1;//这错了,你咋知道i就可以被访问(即i的入读不一定是0) 怎么改啊for(int k = 0; k < mPre[i].size(); k ++ ) {inDegree[mPre[i][k]]--;if(!dfs(mPre, inDegree, mVisit, mPre[i][k])) return false;}mVisit[i] = 0;return true;}
public:bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {vector<int> m_visit(numCourses,0);vector<int> inDegree(numCourses, 0);//记录入度数unordered_map<int, vector<int>> m_pre;for(int i = 0; i < prerequisites.size(); i ++) {m_pre[prerequisites[i][0]].push_back(prerequisites[i][1]); //[1]<-[0]inDegree[prerequisites[i][1]]++;}for(int i = 0; i< numCourses; i ++ ) {if(!dfs(m_pre, inDegree, m_visit, i)) return false;}return true;}
};
#TODO: 上面法2哪里错了
有三种方式判断图内是否有环,拓扑排序,dfs,和union and find:
dfs相当于判定有没有回溯边,并查集的两端如果已经在同一集合也说明有环
并查集不能用于判断有向图存在环,只能用于无向图
背包

01背包
2915. 和为目标值的最长子序列的长度
给你一个下标从 0 开始的整数数组 nums 和一个整数 target 。
返回和为 target 的 nums 子序列中,子序列 长度的最大值 。如果不存在和为 target 的子序列,返回 -1 。
子序列 指的是从原数组中删除一些或者不删除任何元素后,剩余元素保持原来的顺序构成的数组。
class Solution {
public:int lengthOfLongestSubsequence(vector<int>& nums, int target) {//0-1背包问题,f[i][j]表示从前i个物品中选,总量刚好为j 情况下选择的最多物品数量(每件只能选一次)// f[i][j] = max(f[i-1][j], f[i-1][j-nums[i]]+1) f[i-1][j]:不选第i个物品vector<vector<int>> f(nums.size()+1, vector<int>(target+1, INT_MIN));//初始值设为INT_MIN,是让f(j)里的值如果大于0,那肯定是从f(0)递归来的,就是题目说的要完全填满背包的意思。如果不设定这个,是可以全部设为0,表示最多能装几个数字~f[0][0] = 0;for(int i = 0; i < nums.size(); i ++ ) {for(int j = 0; j <= target; j ++ ) {f[i+1][j] = f[i][j];if(j >= nums[i]) f[i+1][j] = max(f[i][j], f[i][j-nums[i]]+1); f[i+1][j] = max(f[i][j], f[i][j-nums[i]]+1) 否则nums[i]会溢出}}int res = f[nums.size()][target];return res > 0 ? res: -1;}
};
优化:
class Solution {
public:int lengthOfLongestSubsequence(vector<int>& nums, int target) {vector<int> f(target+1, INT_MIN);f[0] = 0;for(int i = 0; i < nums.size(); i ++ ) {for(int j = target; j >= nums[i]; j -- ) { //逆序 从target到nums[i]f[j] = max(f[j], f[j-nums[i]]+1); }}int res = f[target];return res > 0 ? res: -1;}
};
二维01背包:设 f(t,i,j)表示考虑了前 t 个物品,体积 为 i 重量为 j 所能得到最大价值
signed main () {cin >> n >> V >> M;for (int i = 1; i <= n; i ++) {cin >> v[i] >> m[i] >> w[i];//体积,重量,价值}for (int i = 1; i <= n; i ++)for (int j = V; j >= v[i]; j --)for (int k = M; k >= m[i]; k --)f[j][k] = max (f[j - v[i]][k - m[i]] + w[i], f[j][k]);//动态转移方程,01 背包的思路cout << f[V][M];
}
完全背包