gas(GNU Assembler)汇编语法
参考文档Using as, Version 2.42,实验对应chapter8:
- 任何以冒号结尾的标识符都被认为是一个标号label
- 注释:可以用//来指明其后的内容为注释,也可以将#写在一行的开头,表示这行为注释
- #:lo12表示低12位(页内偏移),在使用ADRP指令时会用到
- 指令、伪指令、寄存器可以全部是大写或者小写,GNU风格默认是小写
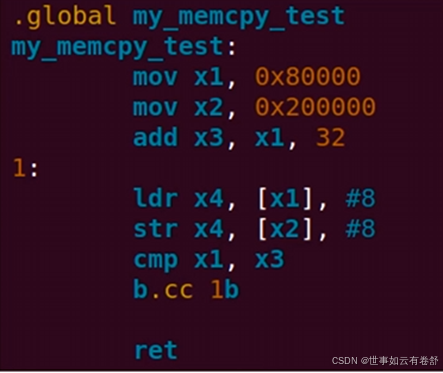
- Symbol:代表它所在的地址,也可以用作变量或者函数来使用。全局symbol可以使用.global来声明,局部symbol主要在局部范围内使用,开头以0-99直接的数字为标号名,通常和b或f指令结合使用(f指示编译器向前搜索,b指示编译器向后搜索),如下图所示:
- 对齐伪指令.align:填充数据来实现对齐,可以填充0或者使用nop指令,对于arm64来说,.align n就是告诉汇编器,.align后面的汇编必须从下一个能被2^n整除的地址开始分配,不同体系结构.align后面的参数有不同的意义,具体可参考as手册第7章
- 数据定义伪指令:.byte是把8位数当成数据插入到汇编中、.hword是把16位数当成数据插入到汇编中、.long和.int是把32位数当成数据插入到汇编中、.quad是把64位数当成数据插入到汇编中、.float是把浮点数当成数据插入到汇编中、.ascii和.string是把string当作数据插入到汇编中,.ascii伪操作定义的字符串需要自行添加结尾字符\0、.asciz类似.ascii,但他会在string后面自动插入一个结尾字符\0;重复定义.rept:如下图,左边等价于右边:

- 赋值操作.equ和.set:.equ abcd,0x45这条语句就是让abcd等于值0x45(也可以用.set)
- .global:定义一个全局的符号;.include:引用头文件
- .if .else .enif:这是和C语言的if else类似的控制语句;if语句的常见变种如下图:

- .section:表示接下来的汇编会链接到哪个段里面,例如代码段、数据段等,每一个段以段名为开始,以下一个段名(就是两个.section之间的部分是属于前一个段的)或者文件结尾为结束,语法为.section name,”falg”,其中name为段名,段名可以自定义但一般会遵循编译器的命名惯例,flag为该段的属性,如下图,具体可参考as手册第七章:
.pushsection:把下面的段push到指定的section中,.popsetion:结束.pushsection的push,这两个通常成对使用,仅仅是把.pushsection和.popsetion圈出来的代码加入到指定的section中,其他的代码还是在原来的section中
- 宏:.macro和.endm组成一个宏定义,语法格式为:
宏参数定义时还可以设置初始化的值,例如:.macro macro_name arg1=0, arg2,此时参数arg1有一个初始化的值0,可以使用macro_name ,b或者macro_name a,b来调用这个宏。对于宏的使用,常见的易出错的情况如下图(下面两种情况汇编器可能无法正确地进行宏参数替换,而是会直接将\l:或\base.\length这些字符原样放在汇编代码中):.macro macro_name arg1, arg2, ...
;此处为宏的代码内容,使用参数时在参数前加反斜杠\,例如可以用
;\arg1, \arg2 等表示参数
.endm
左侧报错是因为不能生成一个以l为名称的标号,右侧报错是不能以这种形式连接参数,可以按下图所示方式解决,具体可参考as手册7.63节: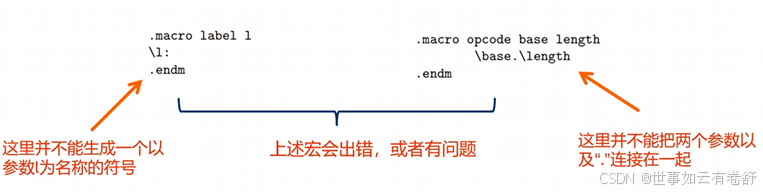
\()可以用来指示字符串或者宏的参数到此处结束,例子见实验8(chapter8)。
- ARM64编译选项如下图所示,可参考as手册第9.1.2节:
如果同时给出了-mcpu和-march选项,则会按照-mcpu执行。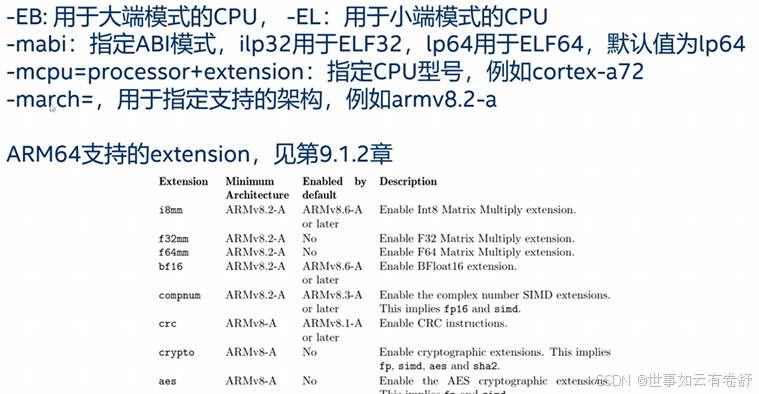
- ARM64特有的伪操作:.bss表示切换到bss段;.dword/.xword表示64位数据;name .req register_name表示为寄存器创建别名。如:foo .req W0表示将符号foo定义为寄存器W0的别名,之后在代码中使用foo就等同于使用寄存器W0
链接器aarch64-linux-gnu-ld
参考文档The GNU linker, Version 2.42,实验对应chapter9:
- 常用参数:-T 指定链接脚本;-Map指定要输出的符号表文件;-o指定最终输出的可执行二进制文件;
- 在链接脚本文件中.表示当前位置,链接脚本中的符号可以像C语言一样赋值,语法格式如下:symbol=expression;、symbol+=expression;、symbol-=expression;、symbol*=expression;、symbol/=expression;、symbol<<=expression;、symbol>>=expression;、symbol&expression;、symbol|=expression;,再如下图所示:
- 链接脚本的作用是链接所有目标文件的输入段(input section),将其链接为单个目标文件的输出段(output section),每个段包括 name和大小段的属性。loadable表示运行时会加载这些段的内容到内存中,allocatable表示应当为该节在内存中预留空间,但不需要加载具体内容(在某些情况下,这段内存必须被清零)。
- VMA(virtual memory address)是虚拟地址,也即运行地址,LMA(load memory address)是加载地址,通常ROM的地址为加载地址,而RAM的地址为VMA
- ENTRY(symbol)表示设置程序的入口函数,例如:ENTRY(_start);表示整个程序从_start函数开始运行。链接程序通常有以下几种方式来确定入口点:链接时在命令行使用-e参数、在链接脚本中使用ENTRY(symbol)、在.text的最开始的地方、0地址
- INCLUDE filename表示引入名为filename的链接脚本文件;OUTPUT filename表示指定输出的二进制文件名,类似于在命令行里面使用“-o filename”;OUTPUT_FORMAT()表示指定输出的格式,例如:OUTPUT_FORMAT(elf32-i386) 会将输出文件指定为32位x86架构的ELF格式;OUTPUT_ARCH()表示指定输出的处理器体系结构格式,例如:OUTPUT_ARCH(i386) 会指定目标架构为i386
- 链接脚本中的符号只是内存地址的标签,没有实际的数据存储空间,仅用于指示内存位置,可以在C程序用引用链接脚本中的符号。而 C 语言中的符号(变量)既在符号表中有记录,也会分配实际的存储空间来存储数据值(符号表会给每个符号分配一个结构体存储符号信息,包括符号在字符串表中的偏移以获取符号名、符号对应数据的大小、符号对应的数据类型、符号所在段、符号的值等信息,符号的值实际存储的是符号在其所在段的段内偏移,符号的实际数据值存储在对应段内,而对于链接脚本中的符号,并没有存储其数据值,其符号表中的符号值存储的就是其表示的地址值)。
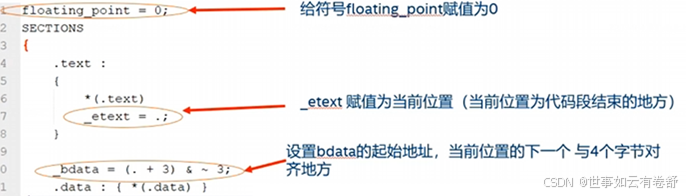
- SECTIONS命令:告诉链接器如何把输入段映射到输出段,以及如何在内存中摆放这些输出端,其语法格式如下:
这里的sections-command可以是ENTRY命令、符号赋值、输出段描述或覆盖描述,具体可参考The GNU linker手册的3.6节,对于输出段描述,其语法格式如下图所示:
每个段都有VMA(虚拟地址,即运行地址)和LMA(加载地址),如上图所示,在输出段描述符中可使用”AT”来指定LMA,如果没有用”AT”指定LMA,通常VMA=LMA,构建一个基于ROM的映像文件常常会设置输出段的虚拟地址和加载地址不一致,下图是一个例子: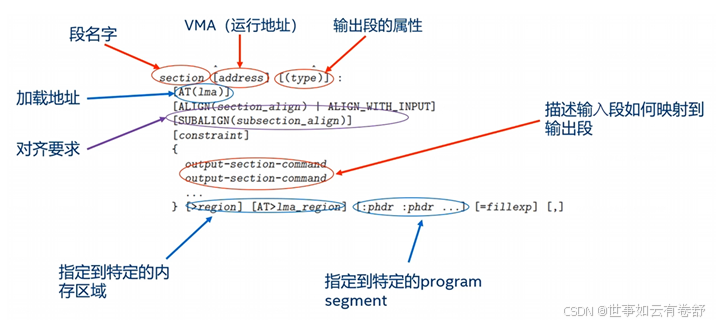
其内存示意图如下,当VMA和LMA不相同时,在程序初始化时需要将相应的段从LMA拷贝到VMA,如下图中的左下侧代码片段所示:

- 常见的内建函数:ABSOLUTE(exp):返回表达式(exp)的绝对值,它主要用于在段定义中给符号赋绝对值。在链接器脚本中,段(section)内的符号通常是相对于该段的起始地址的,这意味着当在段内定义或引用符号时,它们的值是相对于该段的基地址的偏移量,这种偏移量是相对的,因为它们依赖于段在内存中的最终位置,这个位置在链接时确定,如下图:
符号my_offset1使用了ABSOLUTE()内建函数,它把数值0x100赋值给符号my_offset1;而符号my_offset2没有使用内建函数,因此符号my_offset2属于.my_offset段里的符号,于是符号my_offset2的地址为0xB0000+0x100;ADDR(section):返回前面已经定义过的section的VMA地址;LOADADDR(section):返回段的加载地址;ALIGN(n):返回下一个与n字节对齐的地址,它是基于当前的位置(location counter)来计算对齐地址的;SIZEOF(section):返回section的大小;MAX(exp1,exp2)/ MIN(exp1,exp2):返回两个表达式的最大值或最小值
- 加载地址:存储代码的物理地址,在GNU链接脚本里称为LMA。例如,ARM64处理器上电复位后是从异常向量表开始取第一条指令的,所以通常这个地方存放代码最开始的部分,如异常向量表的处理代码;运行地址:程序运行时的地址,在GNU链接脚本里称为VMA;链接地址:在编译、链接时指定的地址,编程人员设想将来程序要运行的地址。程序中所有标号的地址在链接后便确定了,不管程序在哪里运行都不会改变。当使用aarch64-linux-gnu-objdump(简称objdump)工具进行反汇编时,查看的就是链接地址。
- 在现代操作系统中,具备MMU(内存管理单元)的系统使用地址映射机制,将虚拟地址(链接地址)通过页表映射到物理地址(运行地址)。因此,程序可以按照链接地址进行编译,而在运行时,由MMU动态地重定位这些地址,允许链接地址和运行地址不同。比如,Linux操作系统中通过使用动态库和地址空间布局随机化(ASLR)等技术,使得程序的运行地址在每次执行时可能会有所不同。而在没有MMU的系统中(如某些嵌入式设备),如果链接地址与运行地址不同,就需要通过手动的方式进行重定位。常见的做法包括使用启动代码在程序启动时调整链接地址为实际运行地址,或者在编译和链接时预设运行地址与链接地址一致,从而避免运行时的地址不一致问题。没有MMU的系统通常会选择让运行地址和链接地址一致,以简化实现,减少重定位操作。
gcc内嵌汇编(inline Assembly Language)
可参考Using the GNU Compiler Collection手册version 9.3.0的6.47节How to Use Inline Assembly Language in C Code,实验对应chapter10:
- GCC会把内嵌汇编当成一个字符串,GCC编译器不会去解析和分析内嵌汇编(所以gdb是不能在内嵌汇编中单步执行的),多条汇编指令需要用“\n\t”来换行,每条内嵌汇编语句用“”包围,GCC的优化器可以移动汇编指令的前后位置,如果想要保证汇编指令的顺序,最好使用多条内嵌汇编语句。
- 内联汇编主要有两种形式:基础内嵌汇编形式和扩展内嵌汇编形式,基础内嵌汇编语法为asm asm-qualifiers(Assembler Instructions),这是一个单独的语句,其中asm关键字表明这是一个GNU扩展,asm-qualifiers是修饰词,通常为volatile或inline。如下图所示:
而对于扩展内嵌汇编形式,其语法如下图所示:
其中asm关键字表明这是一个GNU扩展,修饰语通常为volatile(用来关闭GCC优化)、inline(内联,用来建议编译器将函数的代码直接嵌入到调用点,而不是生成一个函数调用的指令,这可以减少函数调用的开销)或goto(在内嵌汇编跳转到C语言的标签里)。输出部用于描述在指令部中可以被修改的C语言变量及约束条件,每个输出约束通常以”=”或”+”号开头,接着的字母表示对操作数的类型的说明,然后是关于变量结合的约束:“=/+”+其他约束修饰符+变量,输出部通常使用“=”或“+”作为输出约束,其中“=”表示被修饰的操作数只具有可写属性,“+”表示被修饰的操作数只具有可读可写属性,如下图所示,可参考Using the GNU Compiler Collection手册第6.47.3.3节。输出部也可以是空的。
输入部用来描述在指令部只能被读取访问的C语言变量及约束条件,输入部描述的参数是只有只读属性,不能修改输入部参数的内容,因为GCC编译器假定输入部的参数的内容在内嵌汇编前后都是一致的。在输入部中不能使用“+”或“=”约束条件,否则编译器会报错,输入部也可以是空的。输出部和输入部的共用的约束修饰符见下图,更多信息可参考Using the GNU Compiler Collection手册第6.47.3.1节: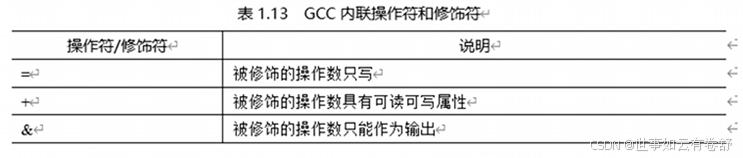
对于不同的体系架构还有其特有的约束修饰符,例如对于ARM64的约束修饰符如下图所示:
损坏部通常的值为“memory”或“cc”,“memory"告诉GCC编译器内联汇编指令改变了内存中的值,强迫编译器在执行该汇编代码前存储所有缓存的值,在执行完汇编代码之后重新加载该值,目的是防止编译乱序;“cc”表示内嵌汇编代码修改了状态寄存器相关的标志位(比如修改了PSTATE中的NCZV位)。指令部中的参数表示:在内嵌汇编代码中,使用%0对应输出部和输入部的第一个参数,使用%1表示第二个参数,依此类推,如下图所示: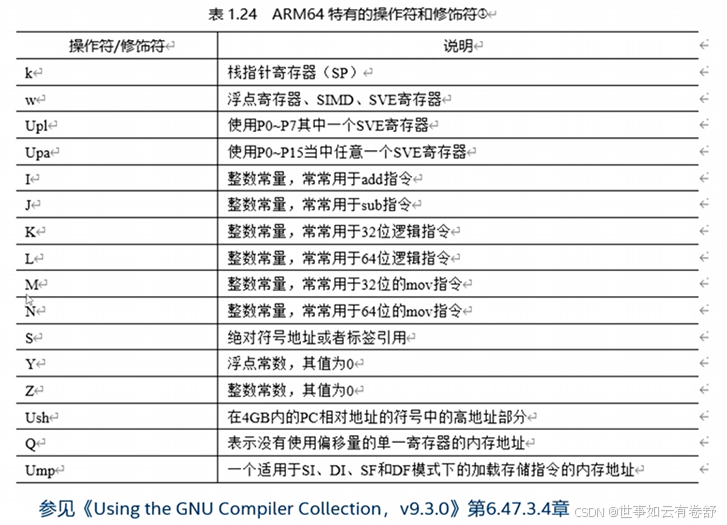
这样表示容易弄混,还可以采用下图所示的表示方式,其中w说明是32位寄存器,下图中的result、input_i、input_j是一个符号,可以用任何其他字符串表示。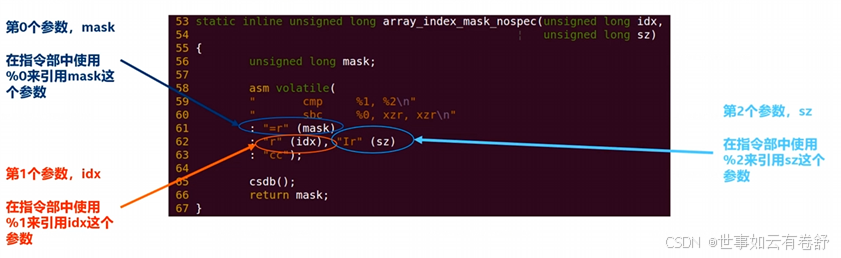
如下图是一个例子: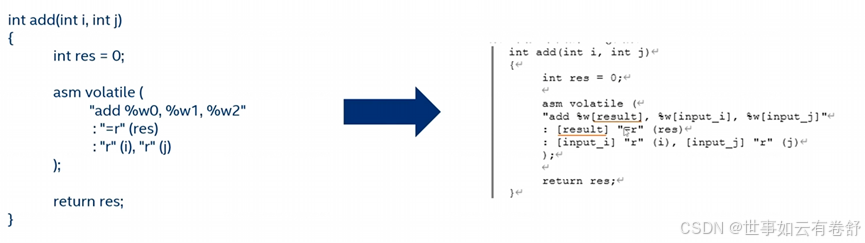
当输入部分和输出部分显式地使用了通用寄存器时,应该在损坏部分明确告诉编译器,编译器在选择使用哪个寄存器来表示输入和输出操作数时,不会使用损坏部分里声明的任何寄存器,以免发生冲突。内嵌汇编的goto模板如下图所示,它可以跳转到C语言的标签里面,goto模板的输出部必须为空,否则编译器会报错,它新增了一个gotolabels部,里面列出了C语言的label,是允许跳转的label: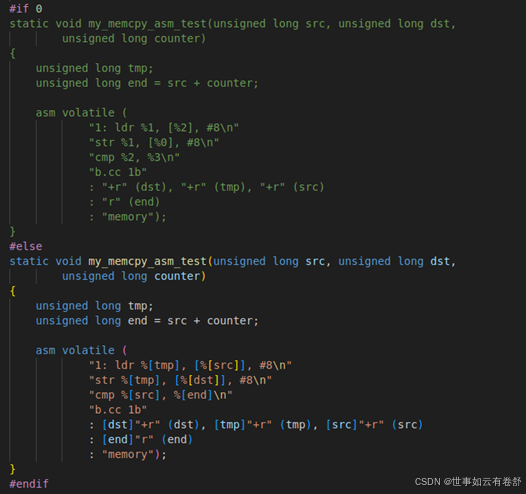
下面是一个goto模板的例子,其中%l表示的是gotolabels部的标签,下图中的%l[label]也可以写成%l2,因为gotolabels部的标签也被看成是参数,gotolabels部还可以有多个标签:
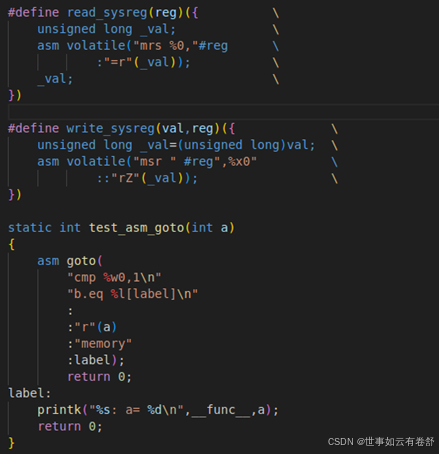
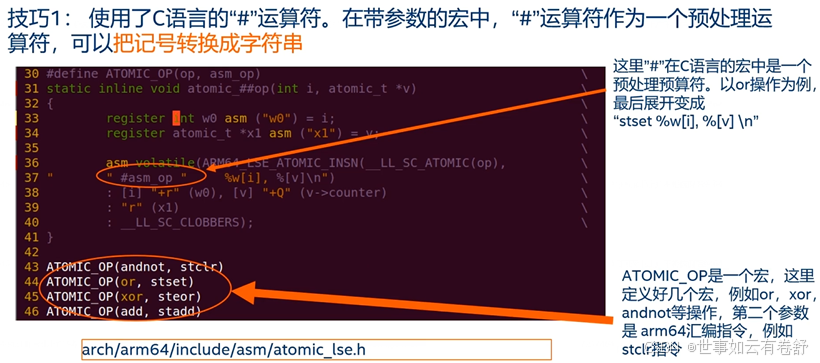
- 内嵌汇编还可以与宏结合使用,如下图所示,其中“#”运算符可以把记号转换为字符串: