
数据已经由生产者Producer发送给Kafka集群,当Kafka接收到数据后,会将数据写入本地文件中。
存储组件
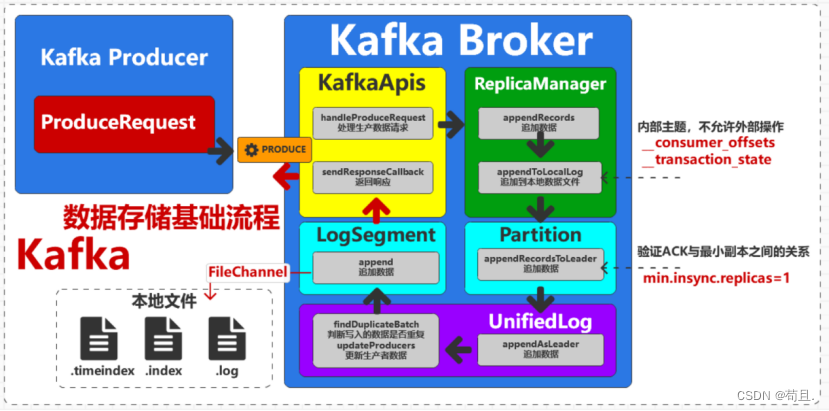
Kafka 的消息存储涉及多个关键组件,每个组件在消息的存储和管理过程中扮演着特定的角色。以下是 Kafka 存储消息过程中涉及的主要存储组件及其作用的详细解释:
1. KafkaApis:
- 作用:KafkaApis 是 Kafka 服务器端的 API 层,它负责处理从客户端接收到的请求,例如生产者的发送请求、消费者的拉取请求、元数据请求等。
- 处理过程:它会进行
基本的请求校验,例如检查主题和分区是否存在、验证消息格式等。 - 如果验证通过,KafkaApis 将请求转发给 ReplicaManager。
2. ReplicaManager:
- 作用:ReplicaManager 是管理 Kafka 集群中副本(replica)的核心组件。它负责管理所有分区的副本,处理消息的读写请求,并确保数据的高可用性和一致性。
- 首先检查当前节点是否是请求目标分区的主副本(leader)。如果不是,返回错误并告知客户端正确的 leader。如果是 leader,ReplicaManager 开始处理消息写入请求。
- 处理过程:ReplicaManager 接收到 KafkaApis 转发的消息发送请求后,会将消息写入相应分区的日志中。
3. Partition:
- 作用:Partition 是 Kafka 中消息存储的基本单元。每个主题(topic)可以有多个分区,每个分区是一个有序的消息队列。
- 处理过程:Partition 负责具体的消息存储和读取操作。每个分区由一个主副本(leader)和多个从副本(follower)组成。消息首先写入主副本,然后复制到从副本。
4. UnifiedLog:
- 作用:UnifiedLog 是对 Kafka 日志的抽象,它代表了一个分区的物理日志文件。
- 处理过程:UnifiedLog 管理分区的日志数据,包括日志的追加、截断和清理等操作。它将消息追加到分区的日志中,并负责维护日志的索引。
5. LocalLog:
- 作用:LocalLog 是 Kafka 中实际存储日志的本地文件系统表示。它封装了对物理日志文件的访问。
- 处理过程:LocalLog 负责将消息写入磁盘,并提供消息的读取接口。它是日志数据的实际存储位置。
6. LogSegment:
- 作用:LogSegment 是 Kafka 日志文件的一个片段,每个分区的日志由多个 LogSegment 组成。
- 处理过程:LogSegment 管理一个日志片段的消息数据和索引。每个 LogSegment 包含一个日志文件和一个索引文件,日志文件存储实际的消息数据,索引文件存储消息在日志文件中的位置。
7. LogConfig:
- 作用:LogConfig 是日志配置的管理类,它定义了日志的相关配置参数,如段大小、保留策略、压缩设置等。
- 处理过程:LogConfig 为每个主题和分区提供配置信息,指导日志文件的创建、滚动和清理等操作。
- 具体参数如下
| 参数名 | 参数作用 | 默认值 | 推荐值 |
|---|---|---|---|
| min.insync.replicas | 最小同步副本数量 | 1 | 2 |
| log.segment.bytes | 文件段字节数据大小限制 | 1G = 1024 * 1024 * 1024 byte | / |
| log.roll.hours | 文件段强制滚动时间阈值 | 7天 =24 * 7 * 60 * 60 * 1000L ms | / |
| log.flush.interval.messages | 满足刷写日志文件的数据条数 | Long.MaxValue | 不推荐 |
| log.flush.interval.ms | 满足刷写日志文件的时间周期 | Long.MaxValue | 不推荐 |
| log.index.interval.bytes | 刷写索引文件的字节数 | 4 * 1024 | / |
| replica.lag.time.max.ms | 副本延迟同步时间 | 30s | / |
这些组件共同协作,形成了 Kafka 的消息存储机制:
数据存储的流程
-
消息写入 UnifiedLog:
- UnifiedLog 是 Kafka 分区日志的抽象层,它负责将消息追加到分区的日志中。
- 每个分区都有一个对应的 UnifiedLog 实例,处理消息的追加、截断和清理等操作。
-
消息持久化到 LocalLog:
- LocalLog 封装了对物理日志文件的访问,实际将消息写入磁盘。
- 它负责管理磁盘上的日志文件和索引文件。
- 消息以 LogSegment 的形式存储在磁盘上,一个分区的日志由多个 LogSegment 组成。
-
LogSegment 管理:
- LogSegment 包含日志文件和索引文件,分别存储实际的消息数据和消息在日志文件中的位置。
- LogSegment 管理消息的物理存储和索引,以便后续的快速查找和读取。
-
索引更新:
- 在消息写入磁盘的同时,更新日志文件的索引,包括时间索引和偏移量索引。
- 这些索引帮助快速定位和读取消息。
-
刷写磁盘:
- 根据配置参数(如
log.flush.interval.messages和log.flush.interval.ms),定期将内存中的消息刷写到磁盘,确保消息持久化。 - 刷写操作将内存缓冲区中的消息持久化到磁盘,以防止数据丢失。
- 根据配置参数(如
-
返回客户端响应:
- 当消息成功写入磁盘并同步到所有副本后,ReplicaManager 返回成功响应给客户端。
- 如果写入过程中发生错误,返回相应的错误信息。
通过以上步骤和流程,Kafka 确保消息从接收到存储的过程是高效、安全且可靠的。每个组件在这个过程中都发挥了关键作用,协同工作以实现高性能的消息存储和管理。
数据刷写
在Linux系统中,当我们把数据写入文件系统之后,其实数据在操作系统的PageCache(页缓冲)里面,并没有刷到磁盘上。如果操作系统挂了,数据就丢失了。一方面,应用程序可以调用fsync这个系统调用来强制刷盘,另一方面,操作系统有后台线程,定时刷盘。频繁调用fsync会影响性能,需要在性能和可靠性之间进行权衡。
Kafka提供了参数进行数据的刷写
- log.flush.interval.messages :达到消息数量时,会将数据flush到日志文件中。
- log.flush.interval.ms :间隔多少时间(ms),执行一次强制的flush操作。
- flush.scheduler.interval.ms:所有日志刷新到磁盘的频率
log.flush.interval.messages和log.flush.interval.ms无论哪个达到,都会flush。
官方不建议通过上述的三个参数来强制写盘,数据的可靠性应该通过replica来保证,而强制flush数据到磁盘会对整体性能产生影响。












