
使用标签选取数据
使用loc(location)属性指定想要获取的行和列:
df.loc[row_selection, column_selection]loc支持切片语法,因此可以使用冒号来选取所有的行或者列。
| 编号 | 选择 | 返回的数据类型 | 示例 |
| 示例1 | 单个值 | 标量 | df.loc[1001, "country"] |
| 示例2 | 一列(一维) | Series | df.loc[:, "country"] |
| 示例3 | 一列(二维) | DataFrame | df.loc[:, ["country"]] |
| 示例4 | 多列 | DataFrame | df.loc[:, ["country", "age"]] |
| 示例5 | 列区间 | DataFrame | df.loc[:, "name":"country"] |
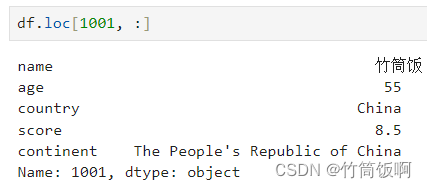
| 示例6 | 一行(一维) | Series | df.loc[1001, :] |
| 示例7 | 一行(二维) | DataFrame | df.loc[[1001], :] |
| 示例8 | 多行 | DataFrame | df.loc[[1003, 1001], :] |
| 示例9 | 行区间 | DataFrame | df.loc[1001:1002, :] |
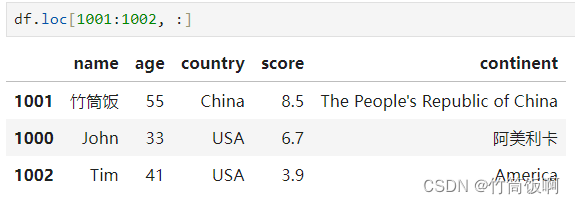
首先构造示例数据:
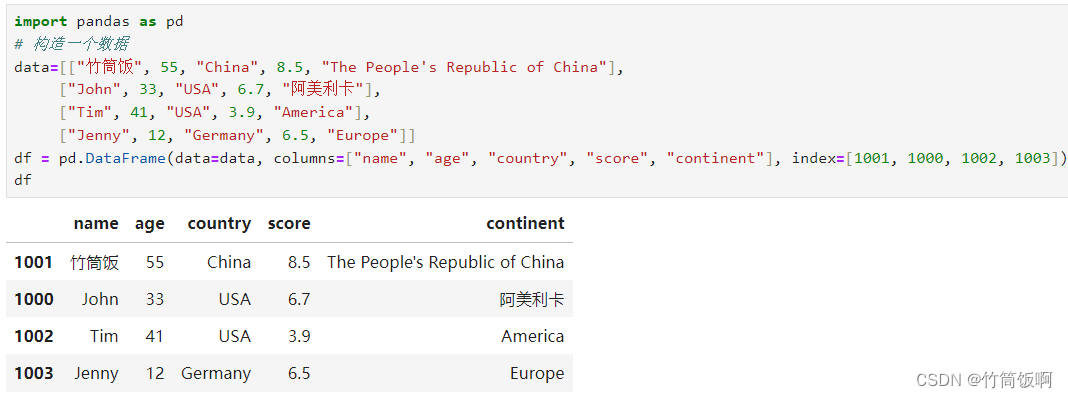
示例1结果:
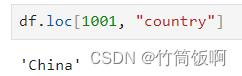
示例2结果:
示例3结果:

示例4结果:

示例5结果:

示例6结果:
示例7结果:
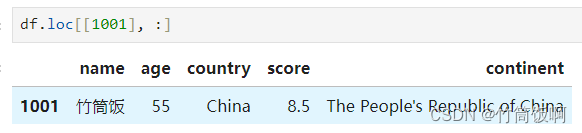
示例8结果:
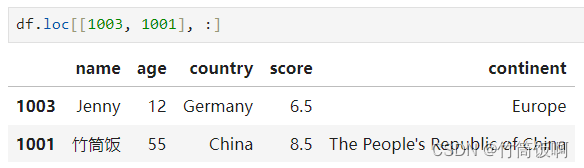
示例9结果:
标签切片是闭区间:和Python内置的切片语法以及pandas的其他地方不同,在使用标签切片时,标签的区间包含区间的首尾的两个标签 。
DataFrame(无论是一列还是多列)与Series之间是有区别的。即使只包含一列,DataFrame也是二维的数据结构,而Series永远是一维的。DataFrame和Series都有索引,但是只有DataFrame由列标题。当选取一列生成Series时,列标题就变成了Series的名称。
列选择的简化:
除了写成
df.loc[:, columns_selection]还可以写成
df[column_selection]通过位置选取数据
需要使用iloc(integer location整数位置)属性。在使用切片时,iloc使用的是标准的半开半闭区间。(下列示例中所有示例结果与上文中对应编号示例结果一致)
| 编号 | 选择 | 返回的数据类型 | 示例 |
| 示例1 | 单个值 | 标量 | df.iloc[0,2] |
| 示例2 | 一列(一维) | Series | df.iloc[:, 2] |
| 示例3 | 一列(二维) | DataFrame | df.iloc[:, [2]] |
| 示例4 | 多列 | DataFrame | df.iloc[:, [2, 1]] |
| 示例5 | 列区间 | DataFrame | df.iloc[:, :3] |
| 示例6 | 一行(一维) | Series | df.iloc[0, :] |
| 示例7 | 一行(二维) | DataFrame | df.iloc[[0], :] |
| 示例8 | 多行 | DataFrame | df.iloc[[3, 0], :] |
| 示例9 | 行区间 | DataFrame | df.iloc[0:3, :] |
使用布尔索引选取数据
布尔索引是借助只包含True或False的Series或DataFrame来选取一个DataFrame的子集。布尔Series可以用来选取DataFrame的特定行和列,布尔DataFrame则用来选取整个DataFrame中的某些值。布尔索引最常见的用例是用来筛选DataFrame的行。
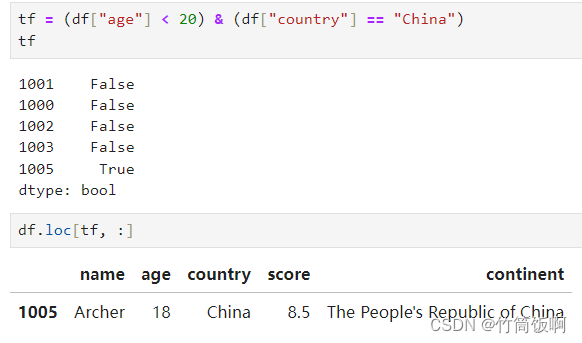
使用布尔索引筛选上述数据中,age在20以下,country为China的人:
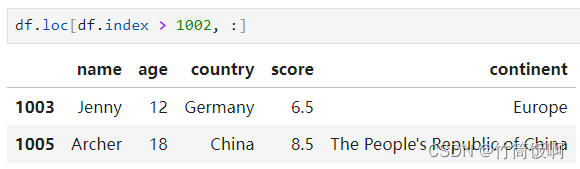
筛选索引大于1002的人:
DataFrame中无法使用Python的布尔运算符,and、or、not分别对应的是&、|、~
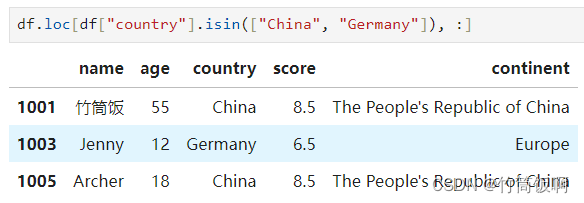
Python的基本数据结构可以使用in运算符判断是否包含某些对象,如果要在Series中进行类似操作,需要使用isin方法。如下筛选来自China和Germany的人:
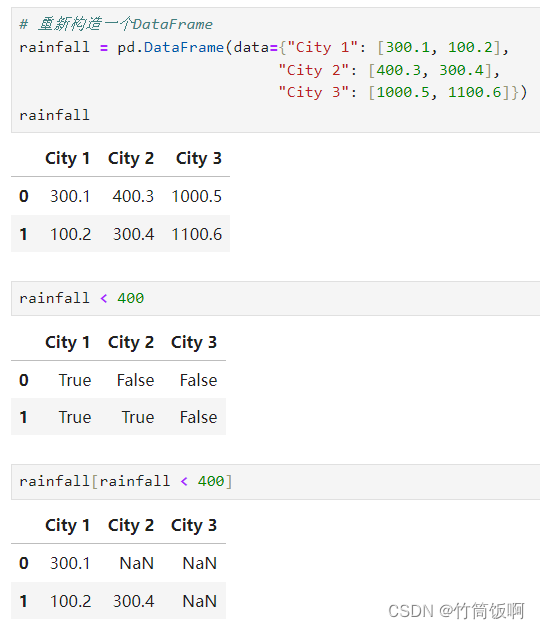
上述例子中是为loc提供一个布尔Series作为参数,不过DataFrame还提供了一种特殊语法,可以不使用loc的情况下传递一整个布尔DataFrame作为参数:
df[boolean_df]在DataFrame只包含数字时这种语法很有用。当提供一个布尔DataFrame作为参考数时,返回的DataFrame会在原DataFrame的基础上,把对应着False的地方变成NaN。布尔值的这种用法经常被用来排除某些值。
使用MultiIndex选取数据
MultiIndex是一种多级索引。可以将数据按层次分组,这样就可以方便的访问DataFrame的子集。这里将continent和country一起设置为df这个DataFrame的索引:
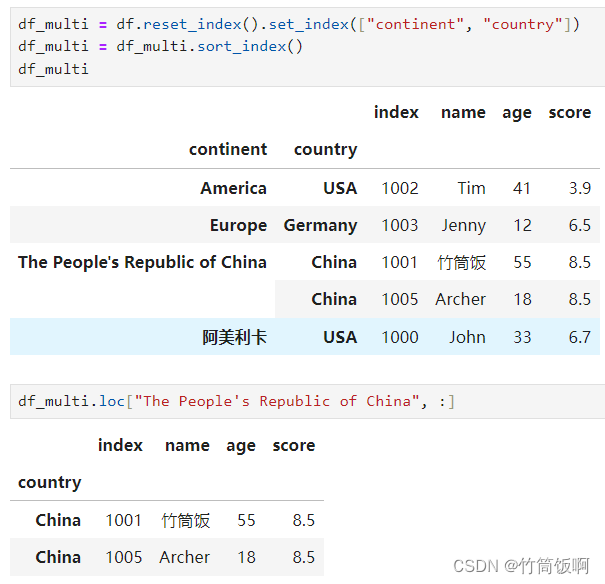
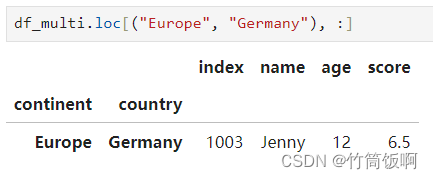
通过多级索引选取数据需要提供一个元组作为参数:
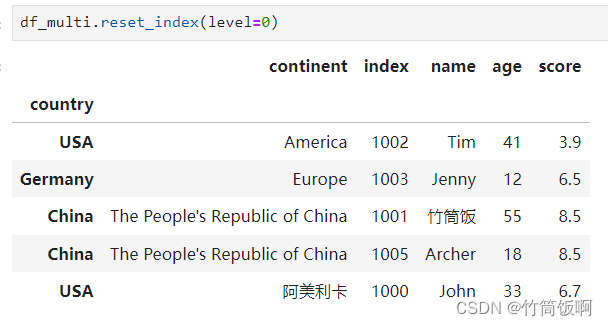
也可以选择性的重置一部分MultiIndex,可以为reset_index提供索引级别的参数。索引级别从左至右从0开始:










 "Java笔试面试题AI答之面向对象(9)")

