
目录
1. 前言
2. 回归任务中的损失函数
2.1 L1损失(Mean Absolute Error, MAE)
2.2 平方损失(Mean Squared Error, MSE)
2.3 平滑L1损失(Smooth L1 Loss)
3. 分类任务中的损失函数
3.1 交叉熵损失(CrossEntropyLoss)
3.2 二元交叉熵损失(Binary Cross Entropy, BCELoss)
3.3 负对数似然损失(Negative Log-Likelihood Loss, NLLLoss)
4. 排序任务中的损失函数
4.1 三元组损失(Triplet Margin Loss)
5. 总结
1. 前言
在学习神经网络过程中,损失函数太多又太杂,这里集中学习一次以便后续写代码。
在深度学习中,损失函数是衡量模型预测结果与真实值之间差异的重要工具。它不仅指导模型的训练过程,还直接影响模型的性能和泛化能力。PyTorch作为一个强大的深度学习框架,提供了多种预定义的损失函数,涵盖了回归、分类和排序等多种任务场景。本文将详细介绍PyTorch中常用的损失函数,结合数学公式和代码示例,帮助读者全面理解这些损失函数的应用场景和使用方法。
2. 回归任务中的损失函数
2.1 L1损失(Mean Absolute Error, MAE)
L1损失计算预测值与真实值之间的绝对误差的平均值。其公式如下:
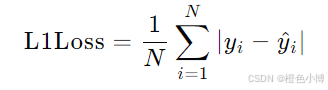
其中,yi 是真实值,y^i 是预测值,N 是样本数量。
应用场景:
-
回归任务,尤其是目标变量包含异常值时。
-
对噪声和异常值具有鲁棒性。
代码示例:
import torch
import torch.nn as nninput = torch.randn(4, 5, requires_grad=True)
target = torch.randn(4, 5)
loss_fn = nn.L1Loss(reduction='mean')
output = loss_fn(input, target)
print(output)reduction参数决定了如何对计算出的损失值进行聚合。它有以下几种可能的取值:
-
'none':不对损失值进行聚合,直接返回每个样本的损失值。 -
'mean':对所有样本的损失值取平均,返回一个标量值。 -
'sum':对所有样本的损失值求和,返回一个标量值。
requires_grad 是一个布尔参数,用于指定该张量是否需要计算梯度。默认情况下,requires_grad 的值为 False,表示该张量不需要计算梯度。当设置为 True 时,PyTorch 会在计算图中跟踪该张量的所有操作,以便在反向传播时计算梯度。在深度学习中,通常将模型的参数设置为 requires_grad=True,以便在训练过程中更新这些参数。而输入数据(如 input)通常不需要计算梯度,因此默认情况下 requires_grad 为 False。
2.2 平方损失(Mean Squared Error, MSE)
MSE损失计算预测值与真实值之间平方误差的平均值。其公式如下:
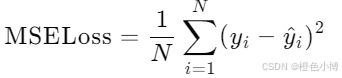
MSE对较大的误差惩罚更严重,因此对异常值敏感。
应用场景:
-
回归任务,尤其是特征值较小且数据维度不高时。
代码示例:
loss_fn = nn.MSELoss(reduction='mean')
output = loss_fn(input, target)
print(output)2.3 平滑L1损失(Smooth L1 Loss)
Smooth L1损失结合了L1和L2损失的优点,当误差小于阈值时使用平方项,否则使用绝对项。其公式如下:
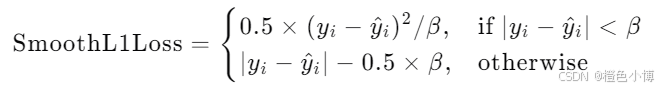
其中,β 是控制阈值的参数。
应用场景:
-
回归任务,尤其是特征值较大时。
-
对异常值的鲁棒性较好。
代码示例:
loss_fn = nn.SmoothL1Loss(beta=1.0)
output = loss_fn(input, target)
print(output)3. 分类任务中的损失函数
3.1 交叉熵损失(CrossEntropyLoss)
交叉熵损失结合了log-softmax和负对数似然损失,适用于多分类任务。其公式如下:
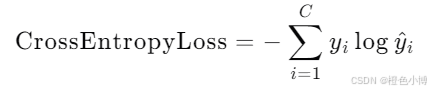
其中,C 是类别数。
应用场景:
-
多分类任务,尤其是需要模型对预测结果有较高置信度时。
代码示例:
input = torch.randn(4, 5, requires_grad=True)
target = torch.empty(4, dtype=torch.long).random_(5)
loss_fn = nn.CrossEntropyLoss()
output = loss_fn(input, target)
print(output)torch.empty 是 PyTorch 中的一个函数,用于创建一个未初始化的张量。参数 4 指定了张量的大小(即张量包含 4 个元素)。dtype=torch.long 指定了张量的数据类型为 torch.long,即 64 位整数。
.random_ 是一个张量方法,用于将张量中的元素填充为随机整数。参数 5 表示随机整数的范围是从 0 到 4(包括 0 和 4)。也就是说,每个元素都是从 [0, 1, 2, 3, 4] 中随机选择的。
input 的第一个维度(4)与 target 的第一个维度(4)一致,表示样本数量。
input 的第二个维度(5)表示类别数量,而 target 中的每个元素是一个整数,取值范围是 [0, 4],表示类别索引。
nn.CrossEntropyLoss 在内部会先对 input 应用 log_softmax 函数,将 logits 转换为对数概率分布。
3.2 二元交叉熵损失(Binary Cross Entropy, BCELoss)
BCELoss适用于二分类任务,计算预测值与真实值之间的二元交叉熵。其公式如下:
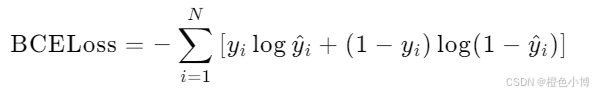
应用场景:
-
二分类任务。
代码示例:
input = torch.tensor([0.7])
target = torch.tensor([1.0])
loss_fn = nn.BCELoss()
output = loss_fn(input, target)
print(output)计算过程如下:
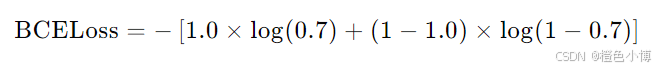
3.3 负对数似然损失(Negative Log-Likelihood Loss, NLLLoss)
NLLLoss适用于分类任务,直接计算对数似然的负值。其公式如下:
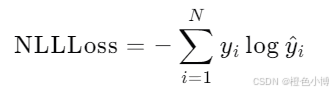
应用场景:
-
分类任务,尤其是简单任务或训练速度较快时。
代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as F# 创建一个 3x5 的张量,表示 3 个样本,每个样本有 5 个特征
input = torch.randn(3, 5, requires_grad=True)# 创建一个大小为 3 的张量,表示每个样本的类别索引(0 到 4)
target = torch.tensor([1, 0, 4])# 定义负对数似然损失函数
loss_fn = nn.NLLLoss()# 应用 LogSoftmax 函数到输入张量
log_softmax_output = F.log_softmax(input, dim=1)# 计算损失
output = loss_fn(log_softmax_output, target)print(output)其实这和交叉熵是一样的:
loss_CEL=nn.CrossEntropyLoss()
output=loss_CEL(input,target)4. 排序任务中的损失函数
4.1 三元组损失(Triplet Margin Loss)
三元组损失用于嵌入学习,通过最小化锚点和正样本之间的距离,同时最大化锚点和负样本之间的距离。其公式如下:

其中,dap 是锚点和正样本之间的距离,dan 是锚点和负样本之间的距离。
应用场景:
-
排序任务,如人脸验证和搜索检索。
嵌入学习(Embedding Learning)是一种将复杂、高维数据(如文本、图像或声音)转换为低维、稠密向量表示的技术。这些向量能够捕捉数据之间的内在联系,如相似性,使得相似的数据点在向量空间中彼此接近。嵌入学习通常涉及无监督或半监督的学习过程,模型在大量未标记的数据上进行预训练,以学习数据的基本特征和结构。预训练的嵌入可以被进一步微调,以适应特定的下游任务,如分类、聚类或推荐系统。
排序任务(Learning to Rank,LTR)是机器学习中的一个重要任务,尤其在信息检索、推荐系统和广告排序等领域有着广泛的应用。排序任务的目标是将数据按照一定的标准进行排序,以满足特定的需求,如将最相关的文档排在搜索结果的前面,或者将最符合用户兴趣的商品推荐给用户。
TripletMarginLoss 是一种用于嵌入学习和排序任务的损失函数。它通过优化锚点和正样本之间的距离与锚点和负样本之间的距离的差值,使得相似样本的嵌入更接近,不相似样本的嵌入更远离。这种损失函数在人脸识别、图像检索、推荐系统等任务中被广泛应用,能够有效提高模型的嵌入质量,使得模型在处理相似性匹配和排序问题时表现更优。
代码示例:
anchor = torch.randn(200, 128, requires_grad=True)
positive = torch.randn(200, 128, requires_grad=True)
negative = torch.randn(200, 128, requires_grad=True)
loss_fn = nn.TripletMarginLoss(margin=1.0)
output = loss_fn(anchor, positive, negative)
print(output)5. 总结
PyTorch提供了多种损失函数,涵盖了回归、分类和排序等多种任务场景。选择合适的损失函数对模型的性能至关重要。L1和MSE损失适用于回归任务,而交叉熵损失和BCE损失则广泛应用于分类任务。对于嵌入学习和排序任务,三元组损失是一个强大的工具。在实际应用中,应根据具体任务和数据特点选择合适的损失函数,以达到最佳的模型性能。我是橙色小博,关注我,一起在人工智能领域学习进步。












