
1. AlexNet
1.1 原理
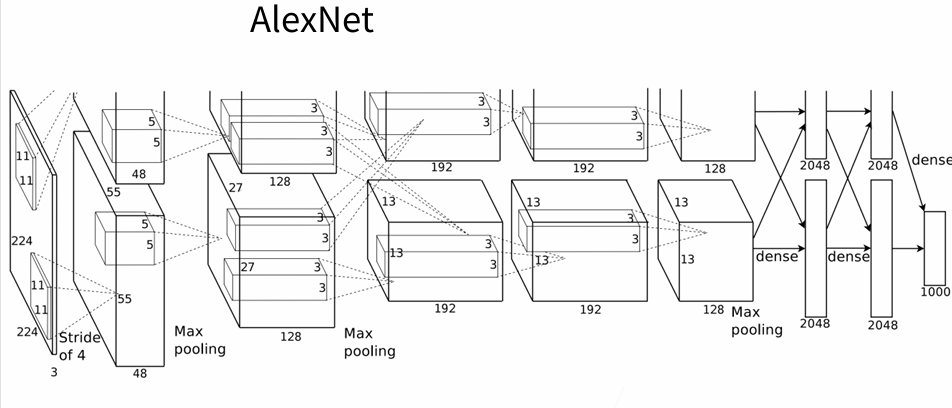
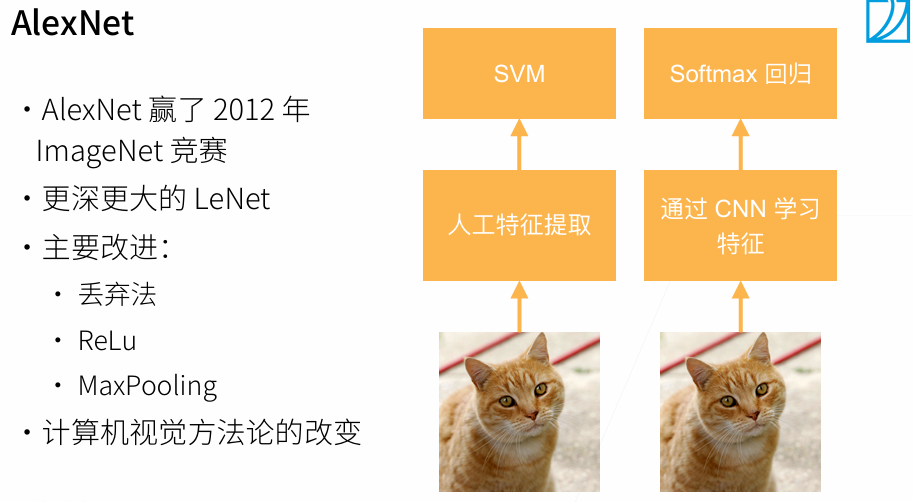
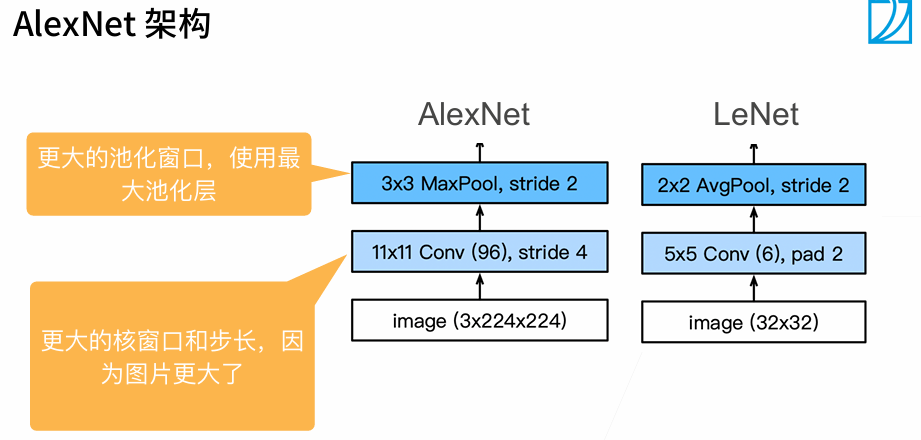
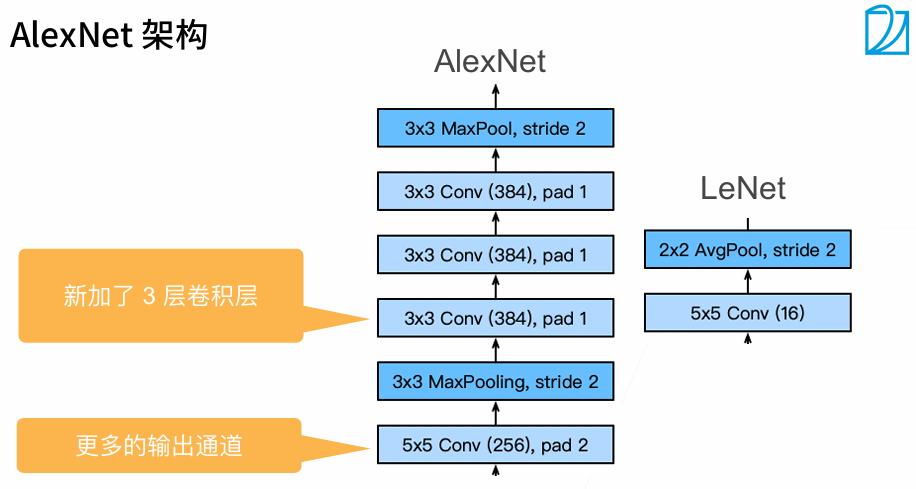


1.2 代码
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11,stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),nn.Linear(4096, 10)
)我们构造一个 单通道数据,来观察每一层输出的形状
X = torch.randn(1, 1, 224, 224)
for layer in net:X = layer(X)print(layer.__class__.__name__,'outshape:\t', X.shape)
Fashion-MNIST图像的分辨率 低于ImageNet图像。 我们将它们增加到 224×224(只是为了匹配ImageNet的尺寸)
batch_size= 123
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)训练AlexNet
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())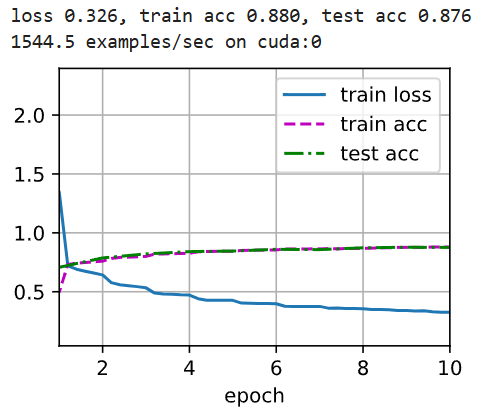
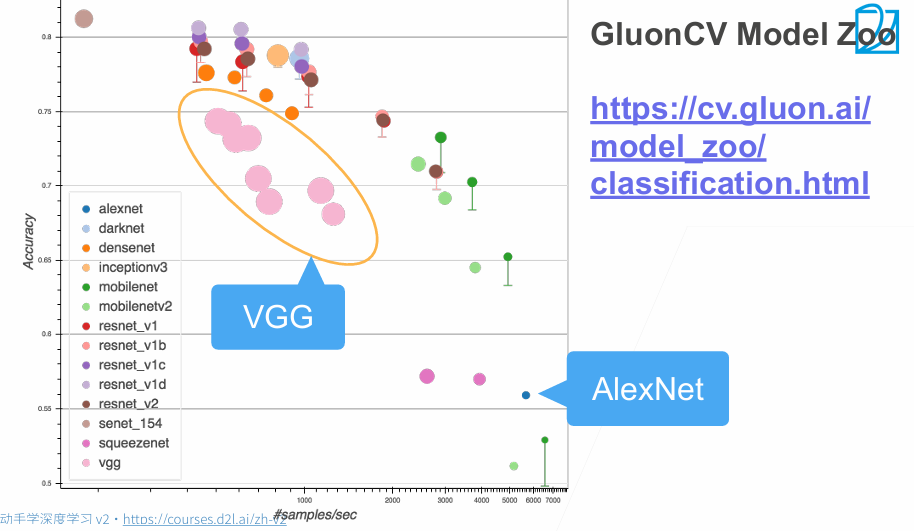
每秒钟处理1500多个样本,精度提升为87% ,轮次增加可能会过拟合。
小结
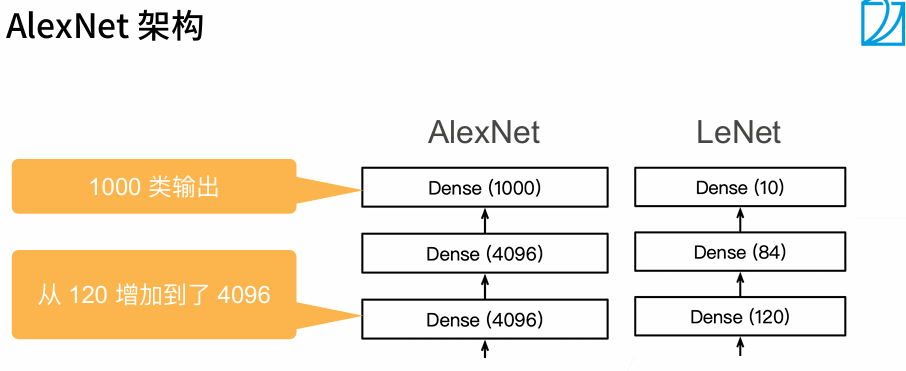
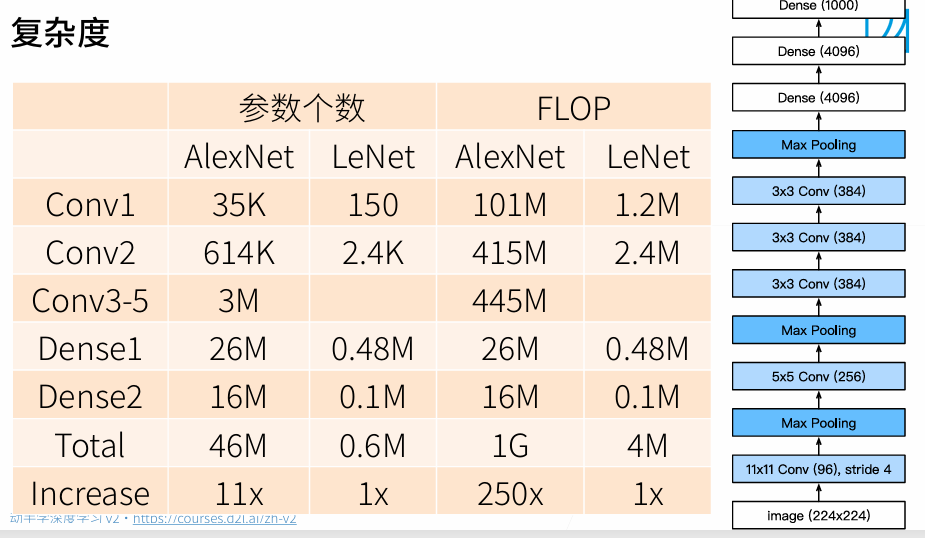
- AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
- 今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
- 尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
- Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。
2. VGG
2.1 原理
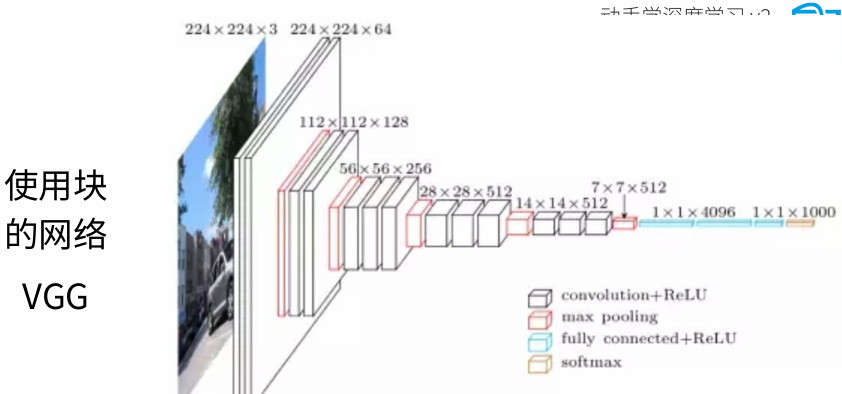

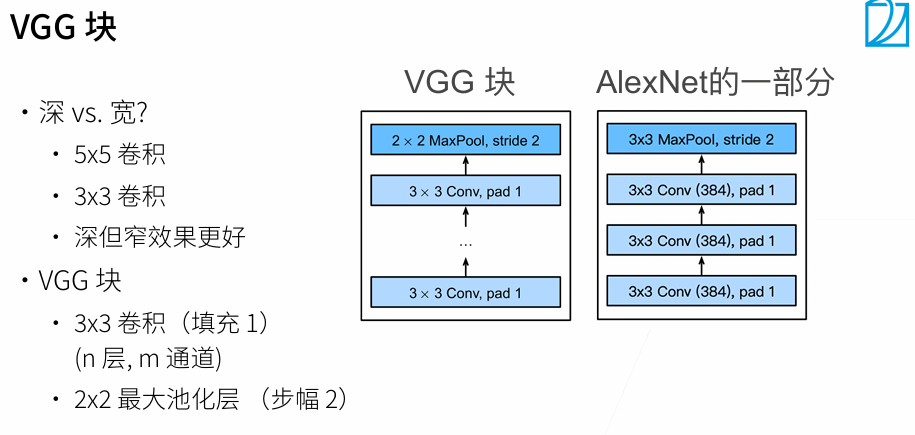
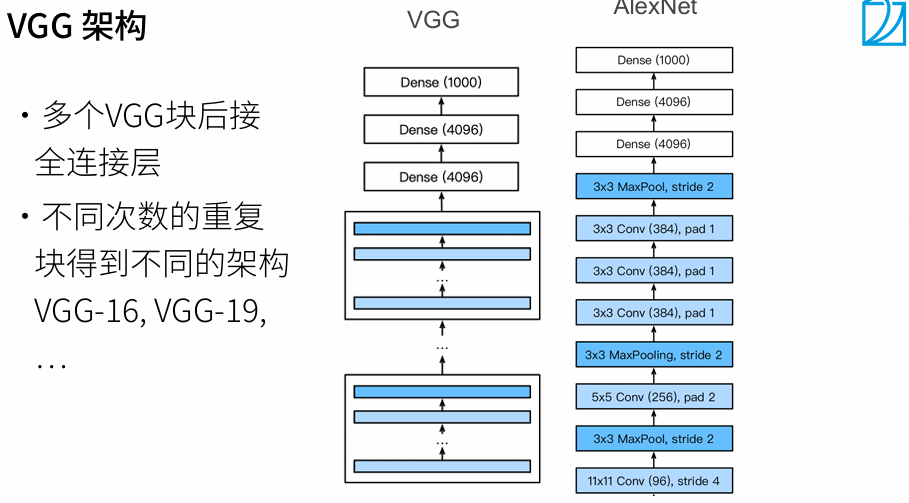
通常是网络每加深一层,通道数加倍,长和宽减半。

2.2 代码
VGG块
import torch
from torch import nn
from d2l import torch as d2ldef vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2,stride=2))return nn.Sequential(*layers) 原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))def vgg(conv_arch):conv_blks = []in_channels = 1for (num_convs, out_channels) in conv_arch:conv_blks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*conv_blks, nn.Flatten(),nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096, 10))net = vgg(conv_arch)观察每个层输出的形状
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:X = blk(X)print(blk.__class__.__name__, 'output shape:\t', X.shape)
由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]net = vgg(small_conv_arch)lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())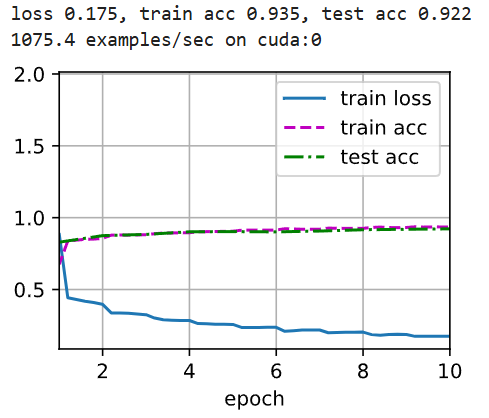
正确率达到90%多,但是处理速度变慢了。
小结
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即3×3)比较浅层且宽的卷积更有效。












