
由于LDA是一个无监督机器学习模型,需要手动输入其主题数,如果主题选择不好,很可能导致最后的结果失真,困惑度(Perplexity)和主题一致性(Coherence)是评估主题模型性能的两个重要指标
一、困惑度(Perplexity)
定义:在信息论中,困惑度用来度量一个概率分布或概率模型预测样本的好坏程度。它也可以用来比较两个概率分布或概率模型,即比较两者在预测样本上的优劣。具体来说,困惑度是句子的概率的倒数,表示对于一篇文章,模型有多不确定它是属于某个主题的。因此,困惑度越低,表示模型对句子的预测越准确,即句子越符合语言的规律。
二、主题一致性(Coherence)
定义:主题一致性是衡量主题模型生成的主题质量的一个重要指标。它反映了主题内部词汇之间的语义关联程度和主题的可解释性。更高的一致性分数表示更好的可解释性,意味着主题更有意义、语义上更连贯。
小结:困惑度越低越好,主题一致性越高越好
三、主题数确定
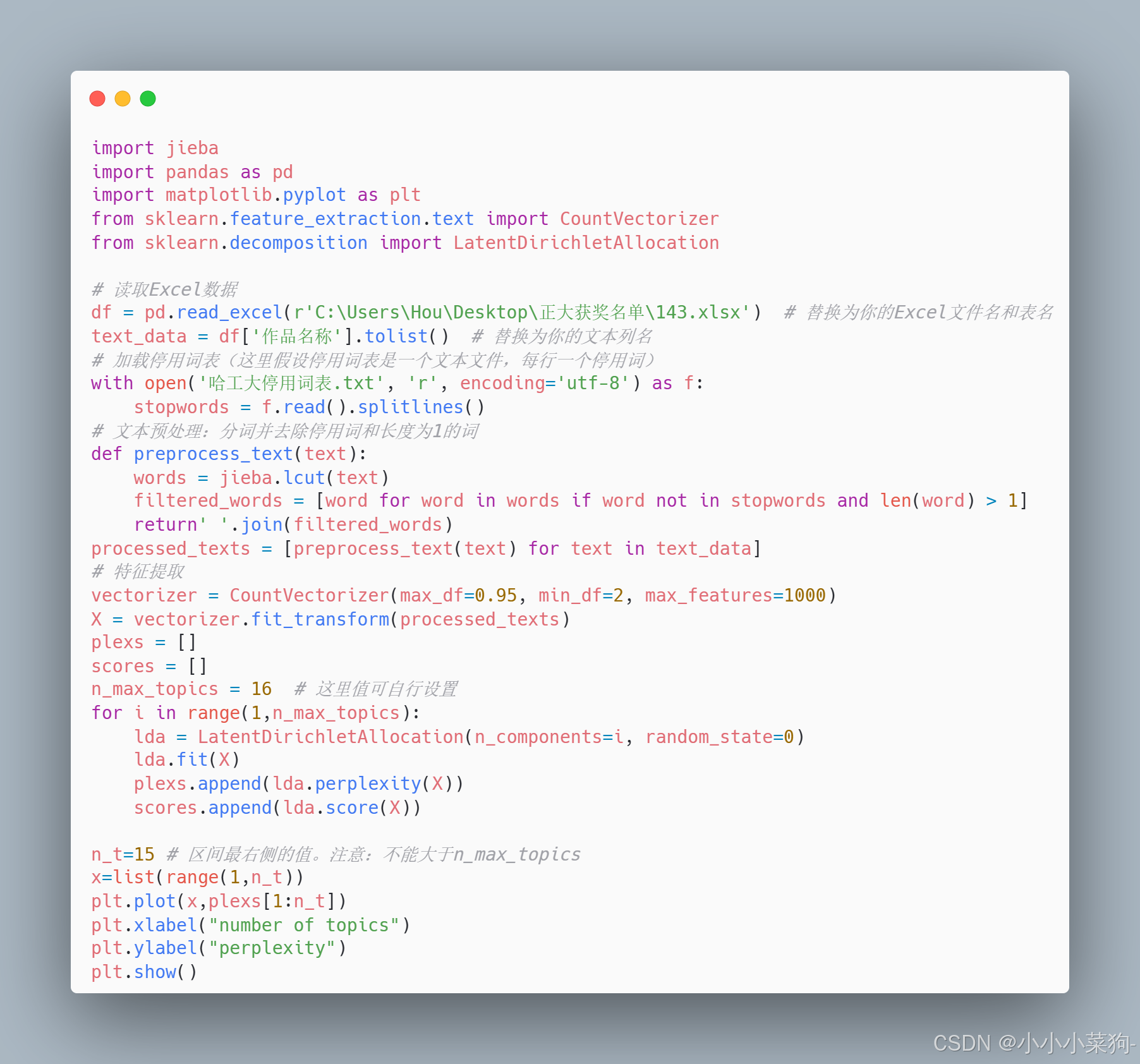
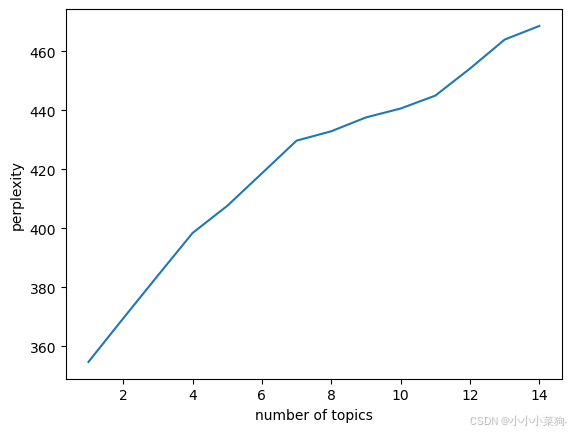
(1)基于sklearn库确定主题数
Sklearn中的LDA模型自带困惑度lda.perplexity函数输出,但没有一致性输出,具体代码和可视化如下
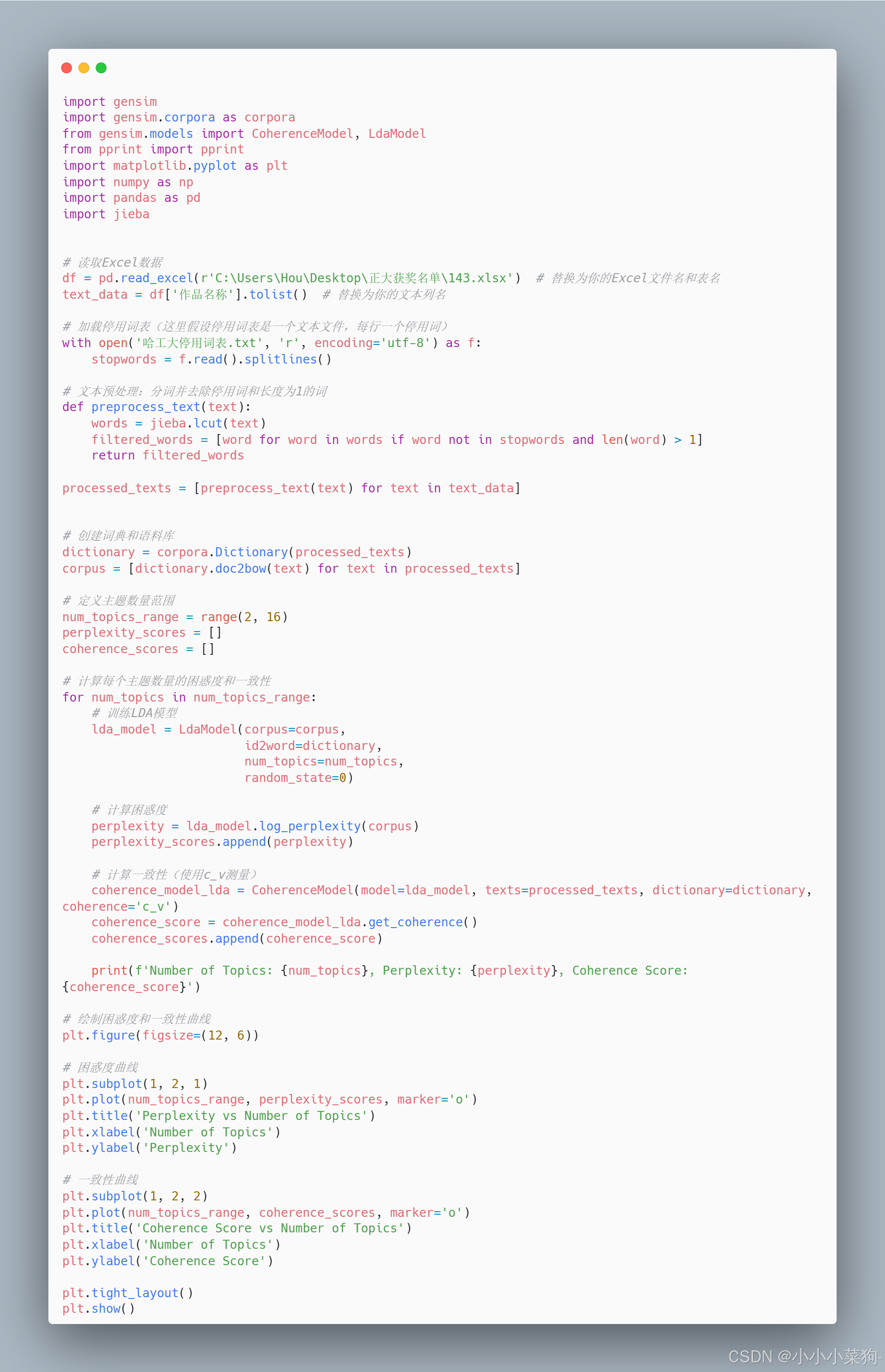
(2)基于gensim库确定主题数
Genism库需要创建词典和语料库才能进行LDA建模,同时genism库中可以通过CoherenceModel函数计算主题一致性,LdaModel中的log_perplexity 函数计算其模型困惑度
(3) 基于sklearn库代码及结果展示
(4)基于gensim库代码及结果展示
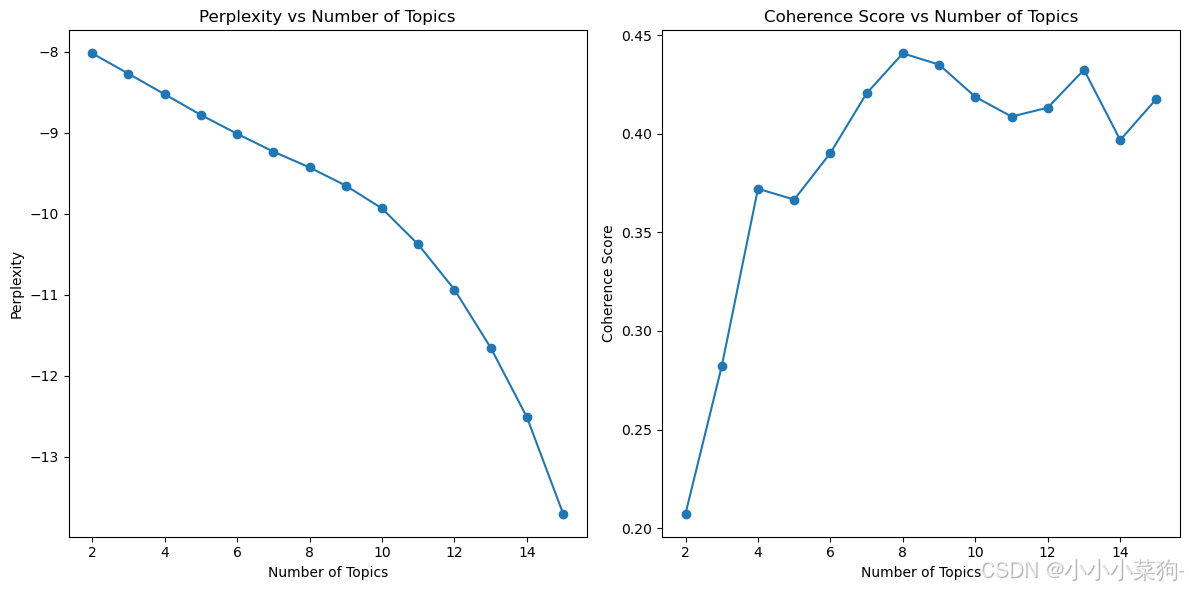
我是直接用的正大杯的获奖名单进行的分析,所以主题不是特别明显,最后选择主题要综合考量困惑度和一致性,困惑度没有最低,那就选一致性最高,一致性没有最高,那就选困惑度最低,或者取二者的中间。困惑度和一致性只是确定了主题的大致范围,最终也可以通过LDA模型的可视化,看看可视化图有没有重叠,来最终确定LDA的最佳主题数。












