
1 Hadoop生态圈概述
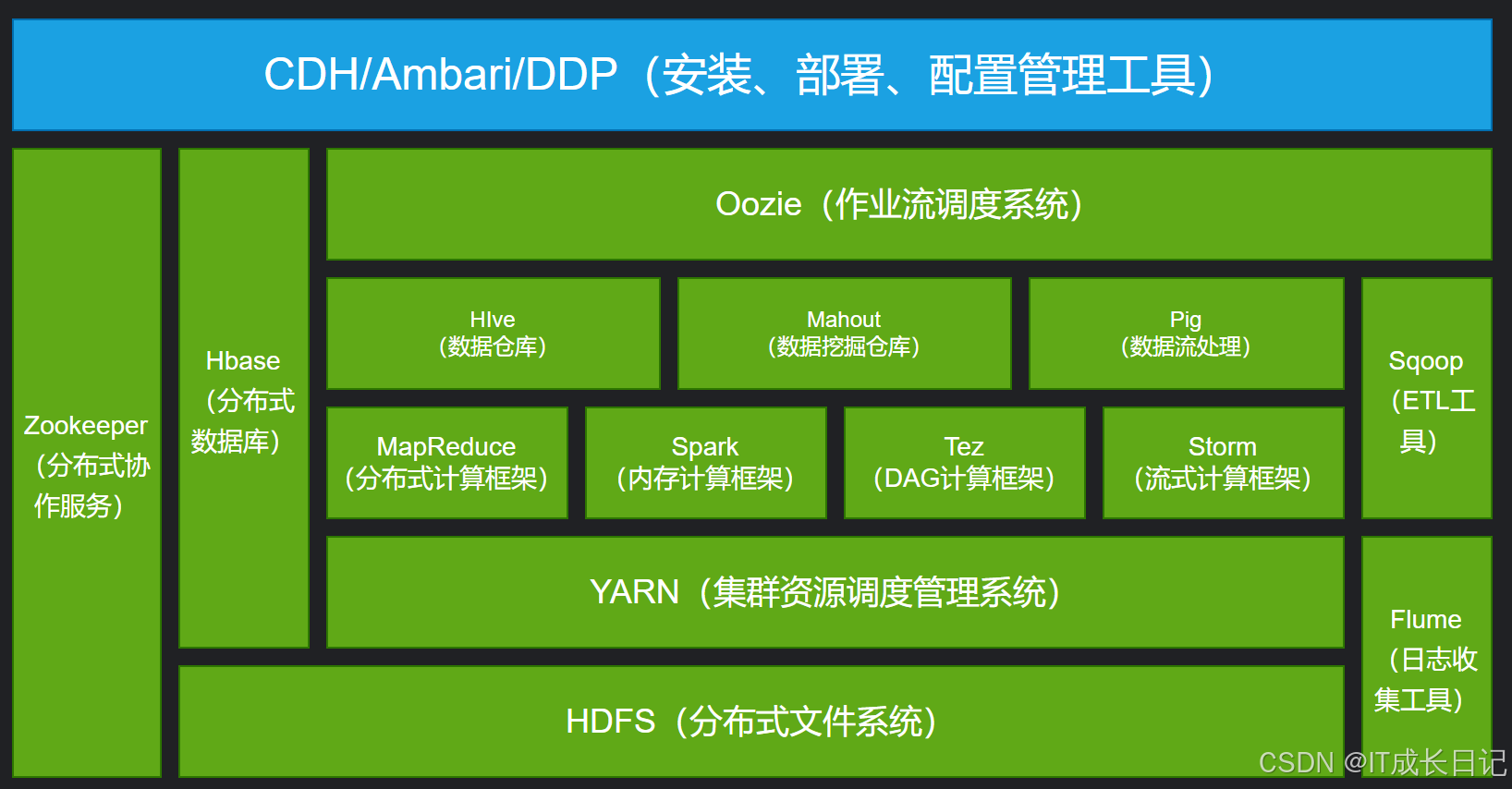
Hadoop生态圈是以 HDFS(分布式存储) 和 YARN(资源调度) 为核心,围绕大数据存储、计算、管理、分析等需求发展出的一系列开源工具集合。核心特点:
- 模块化:各组件专注解决特定问题(如HBase负责实时查询,Spark负责高速计算)
- 可扩展:支持多种计算框架(MapReduce/Spark/Flink)和存储系统(HDFS/HBase)
- 高容错:自动处理节点故障,保证数据可靠性
2 Hadoop生态核心组件
2.1 存储层
| 组件 | 定位 | 关键特性 | 适用场景 |
| HDFS | 分布式文件系统 | 高吞吐、顺序读写、数据分块(默认128MB) | 离线批处理(日志存储) |
| HBase | 分布式NoSQL数据库 | 低延迟随机读写、强一致性 | 实时查询(用户画像) |
| Kudu | 列式存储引擎 | 兼顾实时更新与分析查询 | 时序数据(IoT传感器) |
2.2 计算层
| 组件 | 计算模型 | 优势 | 典型案例 |
| MapReduce | 批处理 | 高容错、适合超大规模数据 | ETL数据清洗 |
| Spark | 内存计算 | DAG执行、比MR快10-100倍 | 机器学习(MLlib) |
| Flink | 流计算 | 低延迟(毫秒级)、精确一次语义 | 实时风控 |
| Tez | DAG优化引擎 | 减少中间数据落盘,提升Hive性能 | 交互式查询 |
2.3 资源管理层
- YARN:统一资源调度系统,可同时运行MR/Spark/Flink等计算框架
- ZooKeeper:分布式协调服务,保障集群一致性(如HBase依赖ZK)
2.4 数据仓库与SQL
| 组件 | 特点 | 查询引擎 |
| Hive | 将SQL转为MapReduce/Tez/Spark作业 | 批处理(分钟级延迟) |
| Impala | 内存计算,免MR启动开销 | 交互式查询(秒级) |
| Presto | 多数据源联邦查询(HDFS/MySQL等) | 即席分析 |
2.5 数据采集与传输
- Flume:高可靠日志收集(如服务器日志 → HDFS)
- Kafka:分布式消息队列(实时数据缓冲)
- Sqoop:关系数据库 ↔ HDFS双向数据传输
2.6 机器学习与高级分析
- Mahout:基于MapReduce的机器学习库
- Spark MLlib:支持分类、回归、推荐等算法
- H2O:深度学习集成
3 Hadoop生态技术选型指南
| 需求 | 推荐组件 | 原因 |
| 海量日志存储 | HDFS + Parquet | 高压缩比,列式存储优化查询 |
| 实时用户行为分析 | Kafka + Flink | 低延迟流处理 |
| 交互式报表 | Hive on Spark + Superset | 平衡速度与成本 |
| 高并发点查询 | HBase | 毫秒级响应 |
4 Hadoop生态发展趋势
云原生转型:
- 存储计算分离(HDFS → S3/OBS)
- 容器化部署(YARN → Kubernetes)
实时化演进:
- 批流统一(Spark Structured Streaming/Flink)
AI融合:
- 大数据+机器学习Pipeline(TensorFlow on YARN)












