
一.我们还是使用简单的bs4库和lxml,使用xpath:
导入下面的库:
import requests
from bs4 import BeautifulSoup
from lxml import etree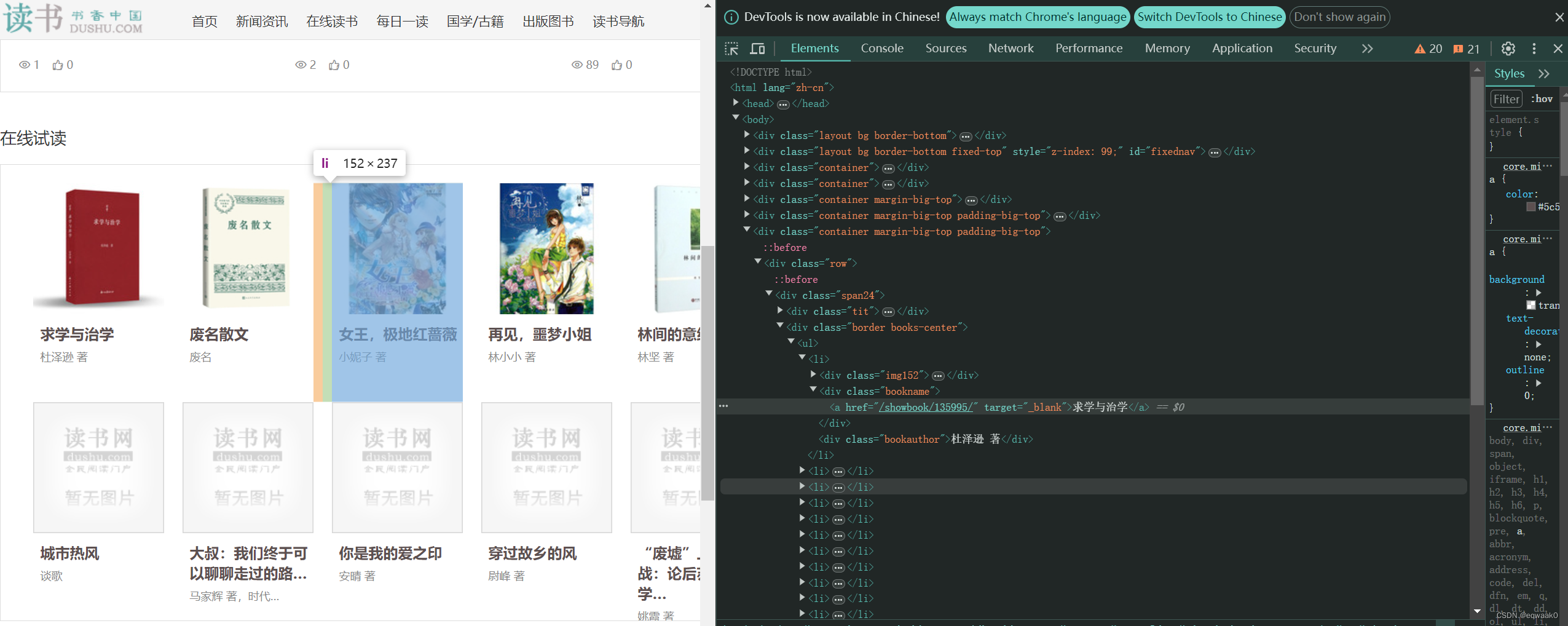
我们可以看见它的div和每个书的div框架,这样会观察会快速提高我们的简单爬取能力。
二.实例代码:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'}
link="https://www.dushu.com/"
r=requests.get(link,headers=headers)
r.encoding='utf-8'soup=BeautifulSoup(r.text,'lxml')
house_list=soup.find_all('div',class_="border books-center")
html=etree.HTML(r.text)# name=html.xpath('//div[@class="property-content-title"]/h3/text()')
# for house in house_list:
# name=soup.find('div',class_="nlist").a.strong.text()
#
# print(name)
name=html.xpath('//div[@class="bookname"]/a/text()')
# href=html.xpath('//div[@class="nlist"]/div/ul/li/a/@href')print(name)
for i in name:print(i)运行结果如下:
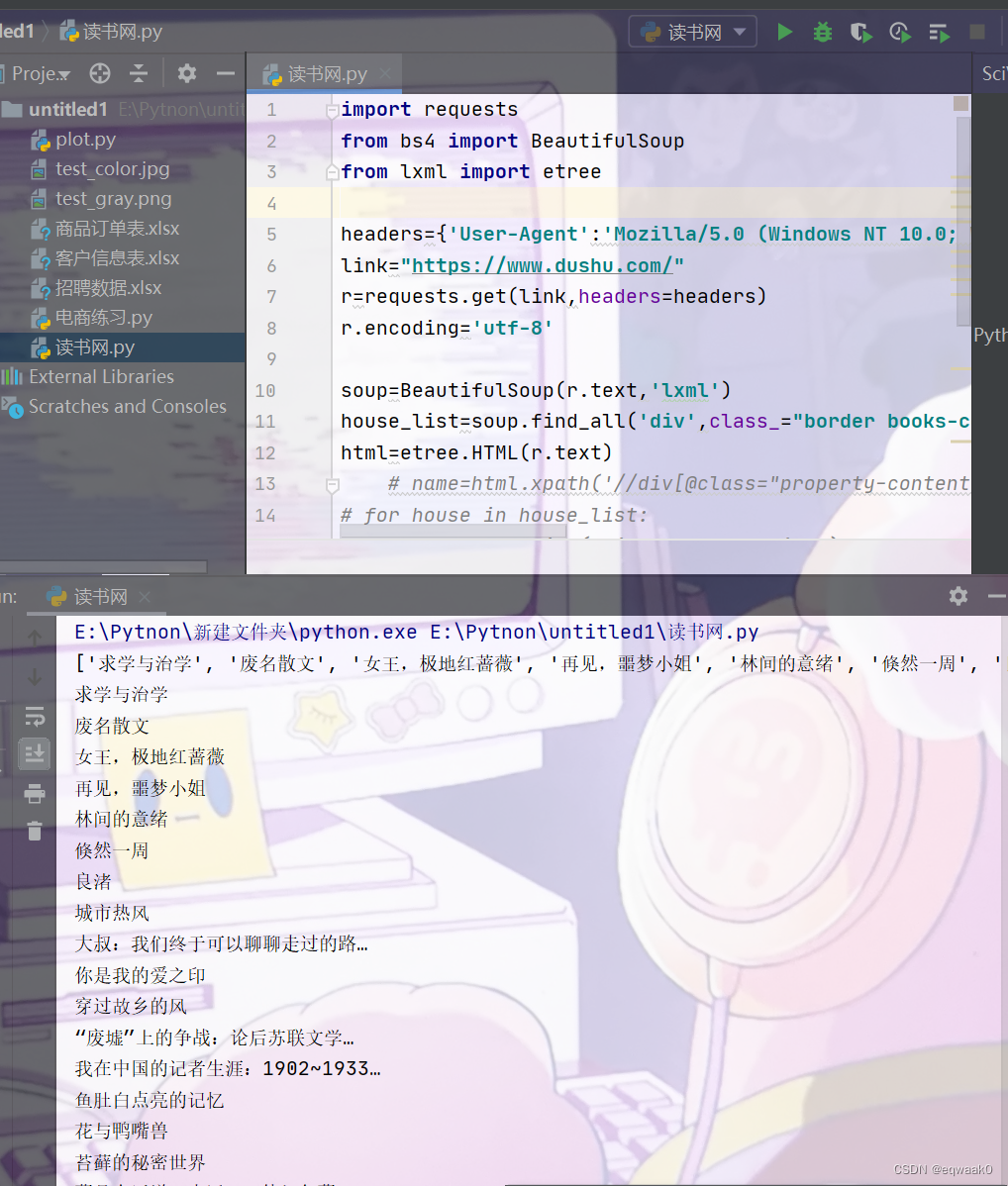
我们成功抓取了网页上书籍的名字,我们可以把它放入一个文件或者文本里面。
三.总结
我们简单的抓取书籍,先找到它需要的大div或者是ur、然后在里面找到自己需要抓取的数据,我们开始练习这样简单案例,会提高爬虫的理解。下次我会加上数据库和可视化









 "CP AUTOSAR标准中文文档链接索引(更新中)")


