影刀RPA_HTTP接口进阶教程:API调用+Token管理+签名验证+批量数据同步——从会用到精通

影刀RPA HTTP接口进阶教程API调用Token管理签名验证批量数据同步——从会用到精通影刀的HTTP请求指令看着简单填URL、选方法、发请求就完事了。但真正做项目的时候你会发现80%的坑都在HTTP这一步——Token过期了不知道、接口限流了硬发、签名算法算错了、返回数据格式跟预想的不一样……这篇文章把这些坑全部讲透。一、HTTP请求基础回顾影刀的HTTP请求指令有5个核心参数请求方式GET查/ POST增/查/ PUT改/ DELETE删URL接口地址可以包含查询参数?key1val1key2val2请求头Headers告诉服务器你是谁、你要什么格式的数据请求体BodyPOST和PUT才需要要发过去的数据返回结果保存到变量名最容易被忽略的是请求头。我见过太多人URL填对了、方法选对了但接口返回401或者400就是因为没填Content-Type或者Authorization。必须了解的HTTP状态码按出现频率排序200成功。但200不代表数据一定是对的有些接口查询无结果也返回200只是body里字段是空的。所以要同时检查body里的数据400请求参数错了。检查body的JSON格式是否正确少了个逗号、多了个引号都会400401没认证或者Token过期了。重新获取Token403没有权限。检查app有没有申请对应的权限范围404接口地址错了。检查URL里有没有拼错的路径429请求太频繁被限流了。加等待时间500服务器出问题了。不是你代码的问题等一会儿重试我第一次调飞书API的时候URL里少写了一个斜杠返回404。我以为是权限问题花了半小时查app配置最后才发现是URL拼错了。从那以后每次调新接口我都先用Postman测试确认能通再写到影刀里。二、Token管理的正确姿势几乎所有的开放平台API都需要TokenAccess TokenToken的有效期通常是1-2小时。Token管理的核心是不要每次都重新获取但要确保获取到的Token是有效的。Token管理方案推荐用一个Python函数做Token管理defmain(args):importrequestsimportjson app_idargs.get(app_id,)app_secretargs.get(app_secret,)# 请求获取Tokenresprequests.post(https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal,json{app_id:app_id,app_secret:app_secret})dataresp.json()ifdata.get(code)0:return{token:data[tenant_access_token],expire:data.get(expire,7200)}else:return{error:data}然后把获取到的Token存到影刀的全局变量里用设置变量指令后面所有API调用都用这个Token。Token过期了就再调一次获取Token的函数。为什么要用Python而不是直接在影刀里拼HTTP请求因为Python处理异常和重试比影刀的指令流要灵活——比如Token获取失败了Python可以自动重试3次影刀得用Try-Catch嵌套Try-Catch写出来很丑。Token过期的判断方法不推荐用计时器比如2小时后自动重新获取。因为服务器的时钟和你的电脑时钟可能不一致。推荐做法调API之后检查返回码如果是401未授权就重新获取Token并重试当前请求。# 通用API调用函数defcall_api(method,url,headers,bodyNone,retry0):resprequests.request(method,url,headersheaders,jsonbody)ifresp.status_code401andretry2:# Token过期了重新获取并重试new_tokenget_token()headers[Authorization]Bearer new_tokenreturncall_api(method,url,headers,body,retry1)returnresp.json()三、元素定位——XPath和CSS在HTTP场景的应用HTTP场景下为什么还要讲元素定位因为很多时候你要调取API之前需要先从网页上抓取一些关键参数比如id、token、cookie等。而这些参数往往藏在网页的HTML里。场景1从网页源码里提取CSRF Token很多网站的表单提交需要带上CSRF Token。Token藏在HTML的meta标签里metanamecsrf-tokencontentabc123def456用影刀的操作先获取网页源码然后用提取文本指令或者正则从源码里提取Token。如果用XPath//meta[namecsrf-token]/content获取该meta标签的content属性值拼多多店群自动化报活动上架场景2从页面元素里提取data-id有些网站的列表项藏着iddivclassitemdata-id12345.../divXPath获取data-id的值//div[classitem]/data-id场景3正则表达式提取从网页源码里提取JavaScript变量importre# 从网页源码里提取 window.__INITIAL_STATE__ 这个JS对象patternrwindow\.__INITIAL_STATE__\s*\s*({.*?});matchre.search(pattern,html_source)四、签名与加密——API安全认证进阶很多API尤其是电商平台、支付平台的请求需要加签名Signature/Sign。签名的本质是把请求参数按一定规则排序后拼接再加上密钥然后算MD5或者SHA256哈希值把哈希值附在请求里发给服务器。服务器用同样的规则算一遍对上了就通过。典型的签名算法以某电商平台为例defmain(args):importhashlibimporttime app_keyargs.get(app_key,)app_secretargs.get(app_secret,)paramsargs.get(params,{})# 1. 把所有参数按字母顺序排序sorted_keyssorted(params.keys())# 2. 拼接成 keyvaluekeyvalue... 的格式param_str.join([f{k}{params[k]}forkinsorted_keys])# 3. 加上密钥sign_strparam_strapp_secretapp_secret# 4. 计算MD5或者SHA256signhashlib.md5(sign_str.encode(utf-8)).hexdigest().upper()return{sign:sign}我第一次写签名算法的时候少了按字母顺序排序这一步算出来的签名跟服务器对不上排查了一整个下午。后来把所有参数打印出来逐个对照才发现是排序的问题。OAuth 2.0 授权流程调用第三方平台数据时需要OAuth 2.0的流程比较复杂简化来说引导用户在浏览器里授权获取authorization code用authorization code换access_token用access_token调APIaccess_token过期后用refresh_token换新的access_token在影刀里实现OAuth 2.0步骤1引导授权需要人工操作或者用浏览器自动化来模拟步骤2-4可以用HTTP请求指令完成。如果你要对接抖音开放平台、淘宝开放平台等大型平台OAuth 2.0是绕不开的。五、网页自动化——抓取网页中的隐藏API很多网站的数据不是直接在HTML里而是通过JavaScript异步加载的前端调后端API后端返回JSON前端渲染到页面上。如果你只抓HTML抓到的是空的。这种情况下要抓的不是HTML而是背后那个API。怎么找到网页背后的API打开Chrome开发者工具F12切到Network网络标签页刷新网页在Filter筛选里输入关键词比如你看到页面上有商品列表就搜list或者goods找到返回JSON的那个请求右键 → Copy → Copy as cURL把cURL的内容分析一下提取出URL、Headers、Body在影刀里用HTTP请求指令复现这个请求注意有些API有反爬机制——比如Headers里必须带特定的Referer、User-Agent或者请求里必须带从上一个页面获取的特定参数。把cURL里的Headers和Cookies原样复制过来就行。iframe里的API有些网站的API请求在iframe里发起的。在Chrome开发者工具的Network标签页左上角有个下拉框默认是top切换到对应的iframe才能看到那个iframe里的网络请求。六、批量数据同步——大规模API调用的策略影刀处理几百条数据的时候还比较轻松但如果是几万条、几十万条数据就要考虑策略了。策略1分批处理不要把几万条数据全部读到内存里再逐条调API。用分页查询API——每次查100条处理完再查下100条。影刀的实现用While循环每次循环调API查100条处理完继续下一次循环。退出条件API返回的has_more字段为false。策略2并发请求进阶Python支持并发用concurrent.futures或者asyncio可以同时发多个API请求大幅提升速度。但要注意不能超过API的频率限制并发数控制在5-10比较安全要处理好异常一个请求失败了不能影响其他请求要合并结果所有请求返回后合并排序fromconcurrent.futuresimportThreadPoolExecutor,as_completedimportrequestsdefmain(args):urlsargs.get(urls,[])results[]deffetch(url):try:resprequests.get(url,timeout10)return{success:True,data:resp.json()}exceptExceptionase:return{success:False,error:str(e)}withThreadPoolExecutor(max_workers5)asexecutor:futures{executor.submit(fetch,url):urlforurlinurls}forfutureinas_completed(futures):results.append(future.result())return{results:results}我第一次做批量数据同步的时候用单线程逐条请求3万条数据跑了4个多小时。改成5线程并发之后20分钟就跑完了。策略3断点续传大数据量同步最怕跑到一半断了网络断了、电脑休眠了下次重跑又要从头开始。解决办法是在处理过程中记录已处理到的位置。做法每处理完100条把当前处理到了第几条/第几页写到一个文本文件里。如果流程中断了重跑的时候先读这个文件从上次中断的位置继续。七、OCR在API场景的妙用——破解接口限流有些平台没有公开API或者说API的免费额度用完了这时候只能继续爬网页。但网页可能加了反爬——弹验证码、图文点击验证等。OCR可以帮你过这些反爬。场景1识别图形验证码截取验证码图片用获取元素截图指令只截取验证码区域用OCR识别图片文字填入识别结果准确率取决于验证码复杂度。简单的数字验证码白底黑字准确率90%。复杂的扭曲变形干扰线验证码准确率50%需要换策略比如用第三方打码平台。场景2识别点击图中的XX类验证码这种验证码要求点击图片中的某个物体比如点击图中的汽车OCR识别不了。解决办法是用第三方图像识别API比如百度AI的图像识别接口但这超出了影刀原生能力的范围。八、Python协同——API数据处理利器API返回的数据往往是嵌套很深的JSON用影刀的获取字典值一层层取很繁琐。用Python处理快很多。常见API返回的JSON结构处理# API返回的数据结构通常是这样response{code:0,data:{items:[{id:1,name:张三,orders:[{price:100},{price:200}]},{id:2,name:李四,orders:[{price:150}]}],total:2,page_info:{has_more:False}}}# Python处理起来非常方便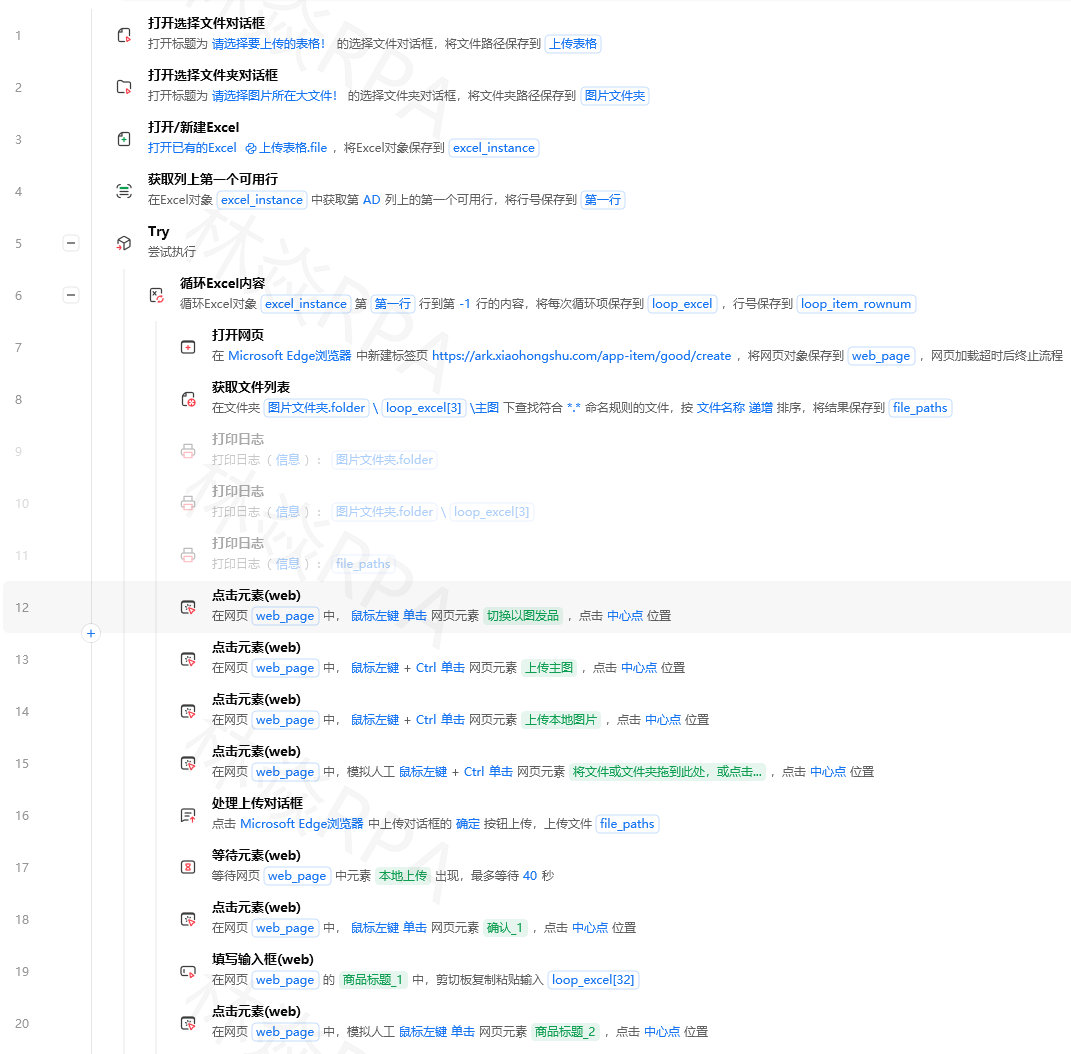defmain(args):dataargs.get(api_response,{})itemsdata.get(data,{}).get(items,[])# 计算每个用户的总订单金额result[]foriteminitems:totalsum(o.get(price,0)foroinitem.get(orders,[]))result.append({name:item[name],total_order_amount:total})return{summary:result}用pandas做数据分析和导出importpandasaspddefmain(args):itemsargs.get(items,[])dfpd.DataFrame(items)# 分组统计summarydf.groupby(category).agg({price:[count,sum,mean]}).reset_index()# 导出为Excelsummary.to_excel(D:/report.xlsx,indexFalse)return{status:done,path:D:/report.xlsx}九、飞书API实战——从入门到搭建完整数据看板飞书API是影刀HTTP请求最常见的对接对象。以一个完整的案例串一下从飞书多维表格读数据 → 用Python做数据分析 → 把分析结果写入飞书多维表格的另一张表 → 飞书消息通知。TEMU店群矩阵自动化运营核价报活动Step 1读取飞书多维表格数据GET https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records?page_size100 Authorization: Bearer {token}Step 2Python做数据分析Step 3写入分析结果到飞书多维表格POST https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{result_table_id}/records Authorization: Bearer {token} 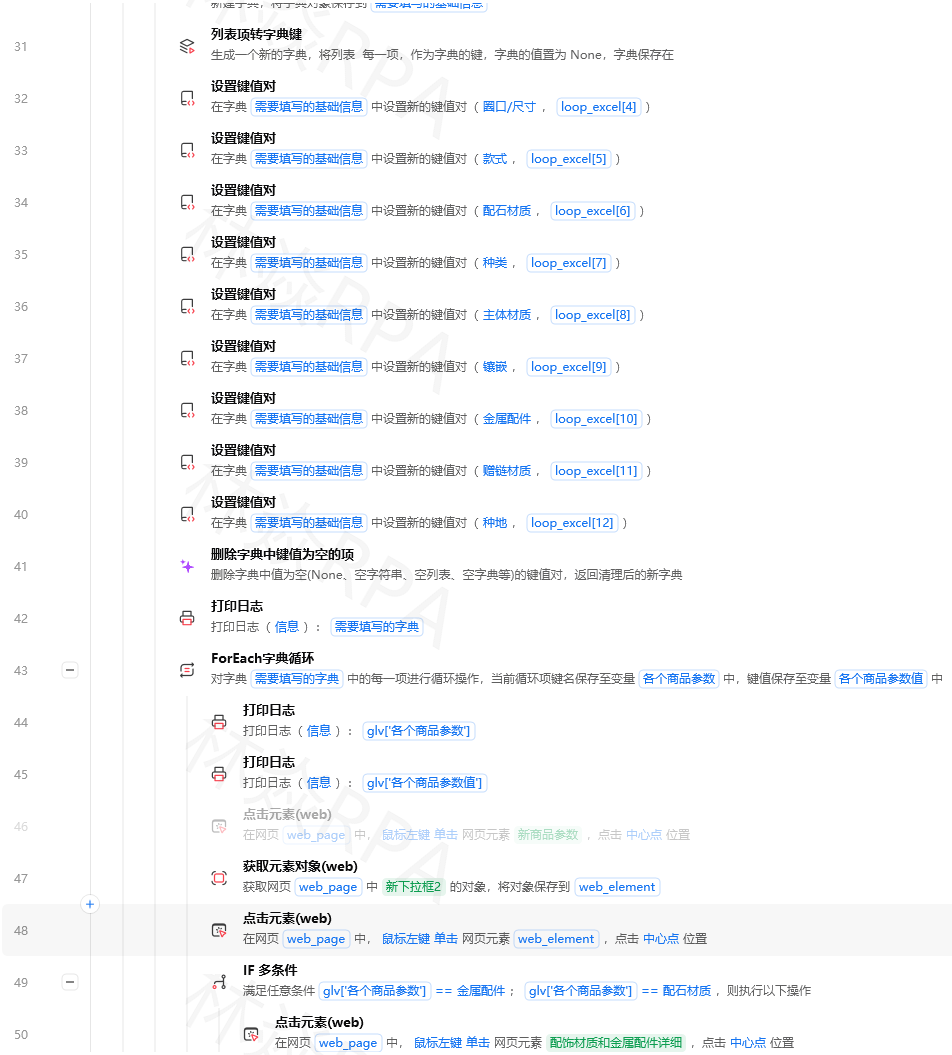 Body: {fields: {...}}注意批量写入时API支持一次写入多条records数组比逐条写快很多。Step 4发送飞书卡片消息通知{msg_type:interactive,card:{header:{title:{content:数据分析完成,tag:plain_text}},elements:[{tag:div,text:{content:本次分析共处理1000条数据,tag:lark_md}}]}}十、定时任务——API数据的自动同步有了API处理能力加上定时任务就能实现数据的自动同步。典型的定时同步场景每天凌晨2点从电商平台API拉取昨天的订单数据写入本地数据库每小时从天气API拉取气象数据更新到飞书多维表格每周一从招聘平台API拉取岗位数据生成竞品招聘动态报告定时任务的配置要点运行时间选API服务器负载低的时间凌晨2-5点设置超时时间数据量大的时候可能跑很久默认5分钟超时可能不够开启失败重试网络波动很正常重试2-3次能解决90%的偶发失败十一、调试技巧——HTTP请求的排障方法论HTTP请求出问题是最让人头大的因为你看到的只是错误信息不知道是请求的问题还是服务器的问题。排障三步法在Postman里测试把影刀里的URL、Headers、Body原样复制到Postman里发送如果Postman能成功说明问题在影刀的配置如果Postman也失败说明问题在请求参数本身打印关键信息在影刀里把请求的URL、Headers、Body和返回的Status Code、Body全部打印到调试输出面板逐个对比逐步简化把复杂的请求逐步简化只保留核心参数看简化到哪一步问题消失了就找到了根因常见坑Headers里的Content-Type写成了content-type大小写不对有些服务器严格区分Body里的JSON有中文字符没做编码用JSON转文本指令导出的时候确认编码是UTF-8URL里有中文或者空格没做URL编码用Python的urllib.parse.quote()处理请求超时时间设太短默认3秒大数据量接口建议设30秒以上十二、速查表——HTTP请求相关报错报错常见原因解决Connection refused目标服务器没开或者网络不通检查URL是否正确ping一下服务器SSL certificate errorHTTPS证书校验失败检查系统时间是否准确或者关闭SSL验证不推荐Read timed out服务器响应太慢增大超时时间或者减少每次请求的数据量400 Bad Request请求格式不对用Postman测试确认Body的JSON格式正确TypeError: Object not callable把HTTP返回写了函数调用检查变量名确认是在读属性不是调函数KeyError in response响应里没有预期的字段先打印整个响应确认字段名拼写正确签名校验失败签名算法或排序错了逐个打印参数对比文档里的签名示例HTTP接口是影刀的上限所在——学会了API对接你就不再局限于网页操作可以跟任何有API的系统对接。CRM、ERP、电商平台、数据分析工具……整个互联网的数据都变成你的原材料。#影刀RPA #RPA教程 #HTTP接口 #API对接 #Python #签名加密 #飞书API #数据同步作者林焱

参数解析)









