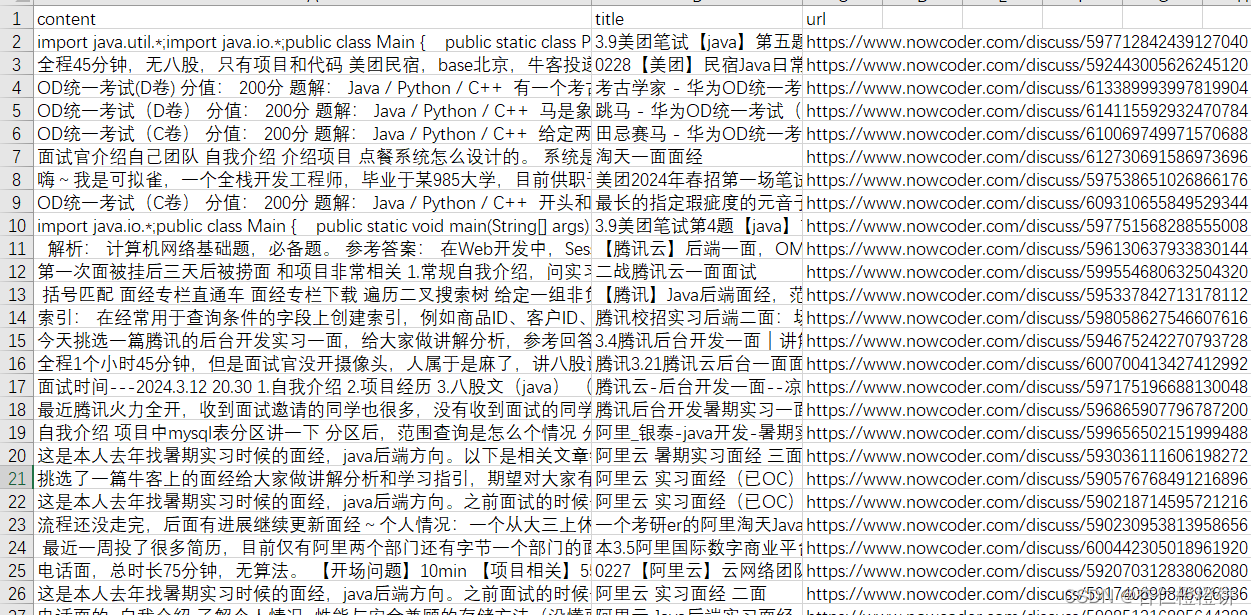
在前期经过团队成员对牛客网面试经验帖子的爬取,已经获得了部分面试经验的相关数据,但是在使用过程中,发现存在大量内容为空的数据记录,为了保证数据的可用性,我对这些页面重新进行了爬取。
- 牛客中之前爬取的面经存在一些空白页
经查询,发现这些页面与大部分页面源代码布局不一致,比如,下边所要爬取的内容在
标签中的p标签下,(还有的是在div标签的div标签下)
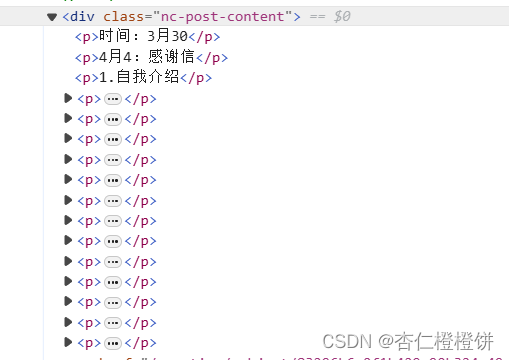
于是采用以下方式:

- 然后又出现页面格式不同的页面:
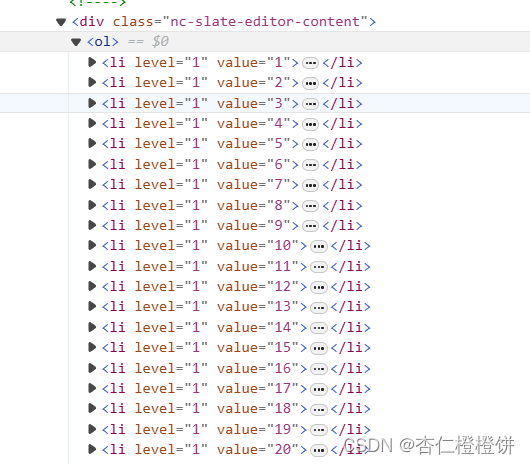
因此需要继续针对此种类型页面编写相应代码:
content_elements = list_item.find_elements(by=By.XPATH, value='//div[@class="nc-slate-editor-content"]//ol/li')content = ' '.join([element.text for element in content_elements])item['content'] = content
- 还有这种:
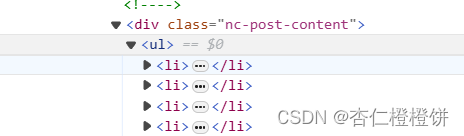
content_elements = list_item.find_elements(by=By.XPATH, value='//div[@class="nc-post-content"]//ul/li')
- 还有:
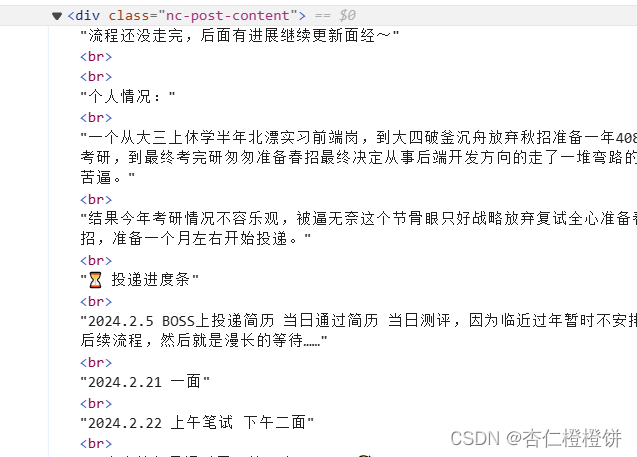
- 以及:
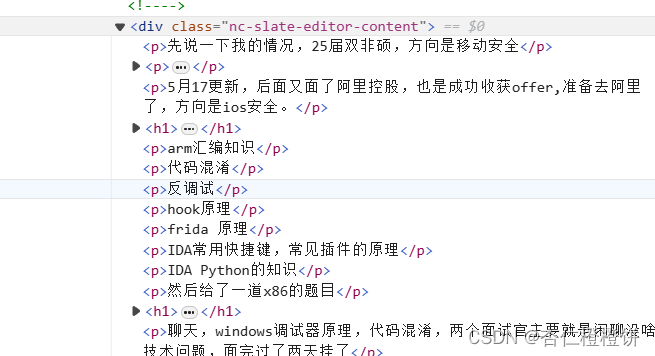
- 以及:
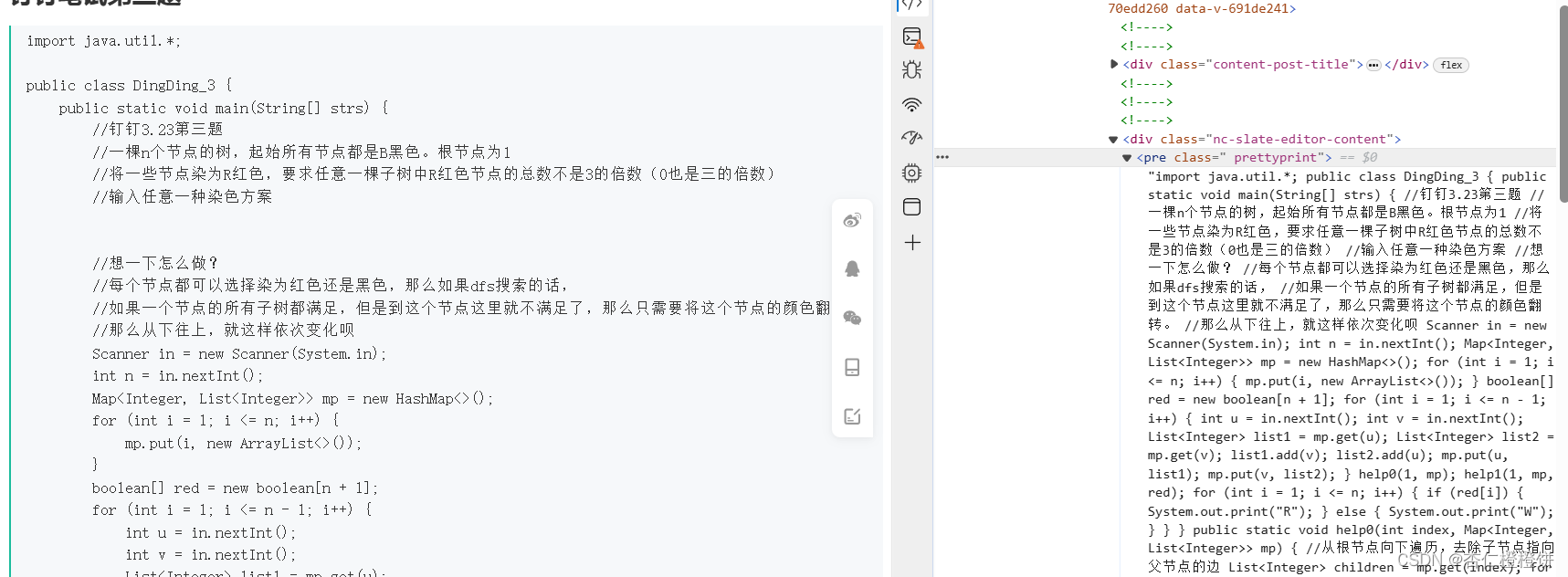
以上的所有不同的页面结构,都需要根据相应的标签格式定位标签,因此需要编写不同的xpath来定位标签
代码如下:
class SpiderSpider(scrapy.Spider):name = "spider"allowed_domains = ["www.nowcoder.com"]start_urls = ["https://www.nowcoder.com/interview/center?entranceType=%E5%AF%BC%E8%88%AA%E6%A0%8F"]base_url = "http://www.nowcoder.com"driver = webdriver.Edge()def parse(self, response):self.driver.get(response.url)time.sleep(3)url_list =['https://www.nowcoder.com/discuss/603209336625590272',]for url in url_list:yield scrapy.Request(url, callback=self.parse_detail,meta={'url':url})def parse_detail(self, response):browser = webdriver.Edge()browser.get(response.url)# 等待页面加载和渲染完成wait = WebDriverWait(browser, 10) # 设置等待时间,单位为秒wait.until(EC.presence_of_element_located((By.XPATH, '/html/body')))time.sleep(5)item = NiukeItem()list_items = browser.find_elements(by=By.XPATH, value='/html/body')for list_item in list_items:item['url'] = response.meta['url']item['title'] = list_item.find_element(by=By.XPATH,value='//*[@id="jsApp"]/main/div/div/div/section/div[3]/div/div/section[1]/div[1]/h1').text# content_elements= list_item.find_elements(# by=By.XPATH, value='//div[@class="nc-post-content"]//div | //div[@class="nc-post-content"]//p')content_elements = list_item.find_elements(by=By.XPATH, value='//div[@class="nc-post-content"]//ul/li')# content = list_item.find_element(# by=By.XPATH, value='//div[@class="nc-post-content"]').text# content_elements = list_item.find_elements(# by=By.XPATH, value='//div[@class="nc-slate-editor-content"]//ol/li')content = ' '.join([element.text for element in content_elements])item['content'] = content# item['content'] = list_item.find_element(by=By.XPATH,value='//*[@id="jsApp"]/main/div/div/div/section/div[3]/div/div/section[1]/div[2]/pre').textprint(item['title'])print(item['content'])yield itembrowser.quit()
得到最终结果如下: