
文章目录
- Redis分布式锁的实现原理
- Redis实现分布式锁如何合理的控制锁的有效时常?
- **redisson实现的分布式锁**
- redisson实现的如何保证主从一致性
- Redis的集群方案
- 1.主从复制
- 主从数据的同步原理
- 全量同步
- 增量同步
- 2.哨兵模式
- Redis的集群脑裂是什么?
- 3.分片集群
Redis分布式锁的实现原理
Redis实现分布式锁主要利用Redis的setnx(SET if not exists)命令,】
- 获取锁:
# 添加锁 NX 是互斥 EX是设置超时时间
SET lock value NX EX 10
- 释放锁
# 释放锁 删除即可
DEL key
Redis实现分布式锁如何合理的控制锁的有效时常?
- 根据业务执行时间预估
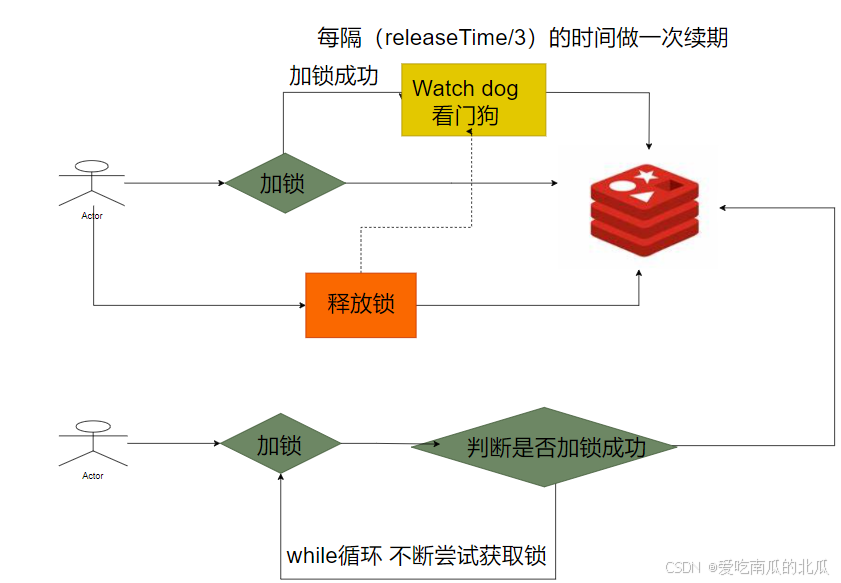
这个时间不好控制,时间长或短都会对业务造成影响 - 给锁延期
我们可以添加一个线程来监控当前线程,如果业务还未完成,就给锁延期,如果业务完成,就释放锁。
有些许麻烦,还需要我们自己创建一个线程,这里有一个现成的解决方案,那就是redisson是实现的分布式锁
redisson实现的分布式锁
redisson实现的锁是可重入的,底层使用hash结构来完成锁的重入。
将锁名作为Key
将线程名和锁可重入的次数作为Value
redisson实现的如何保证主从一致性
RedLOck(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n/2 +1),避免在一个redis实例上上锁
-
获取锁时,向多个 Redis 节点中获取锁,只有每个节点都获取锁成功,才算-获取锁成功。实现了,只要有一个节点存活,其他线程就不能获取锁,锁不会失效。
-
当其中有节点宕机时,其他节点仍然含有锁信息,其他节点仍然有效
Redis的集群方案
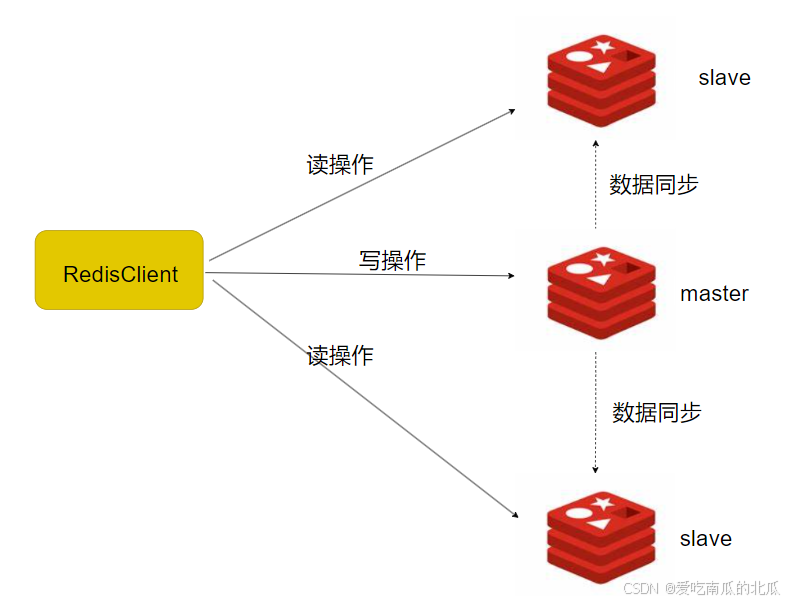
1.主从复制
搭建主从集群,实现读写分离
主从数据的同步原理
全量同步
主从全量同步:
Replication Id: 简称replid,是数据集的标记,id一致说明是同一个数据集,每一个master都有唯一的replid,slave则会继承master节点的replid
offset: 偏移量,随着记录在repl_baklog中的数据增多而逐渐增大,slave完成同步时也会记录当前同步的offset,如果slave的ofset小于master的offset,说明slave数据落后于master,需要更新
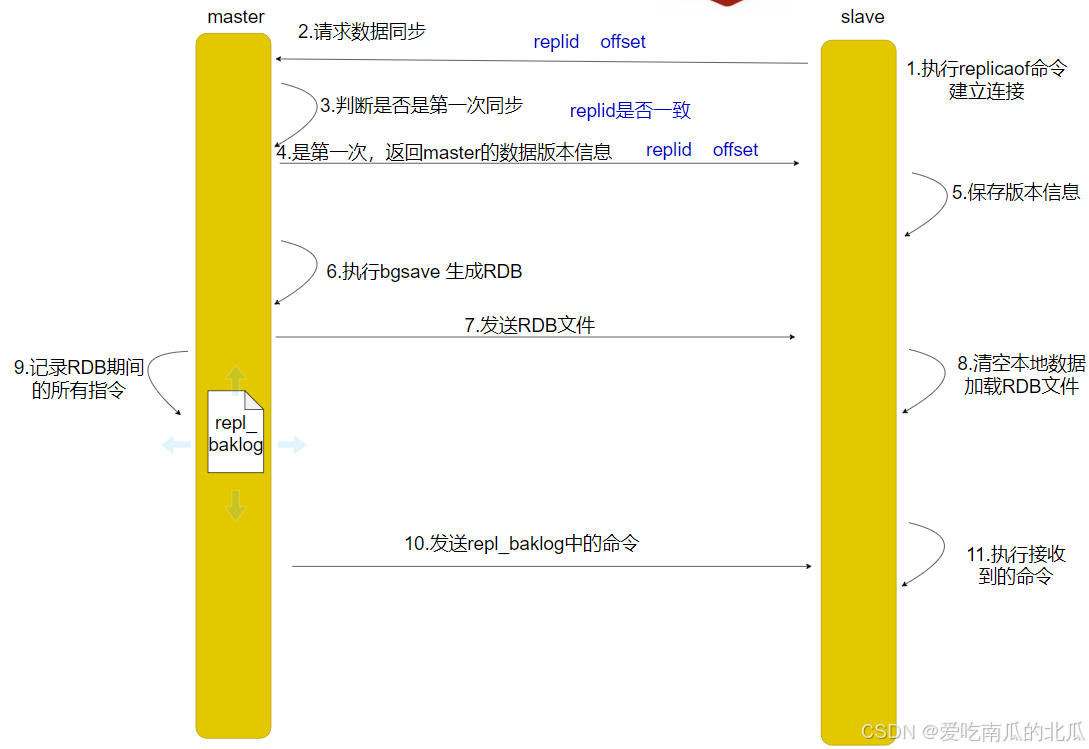
- 从节点请求主节点同步数据,(replication id,offset)
- 主节点判断是否是第一次请求,是的话就同步版本信息(replication id 和 offset)
- 主节点执行bgsave,生成RDB文件,发送给从节点执行
- 在RDB执行期间,主节点会以命令的形式记录到缓冲区(日志文件)
- 把生成的日志文件发送给从节点同步
增量同步
主从增量同步(slave重启或后期数据变化)

1.从节点请求主节点建立连接,主节点判断不是第一次连接,就获取从节点的offset
2. 主节点从日志文件中获取offset之后的值,发送给从节点进行同步
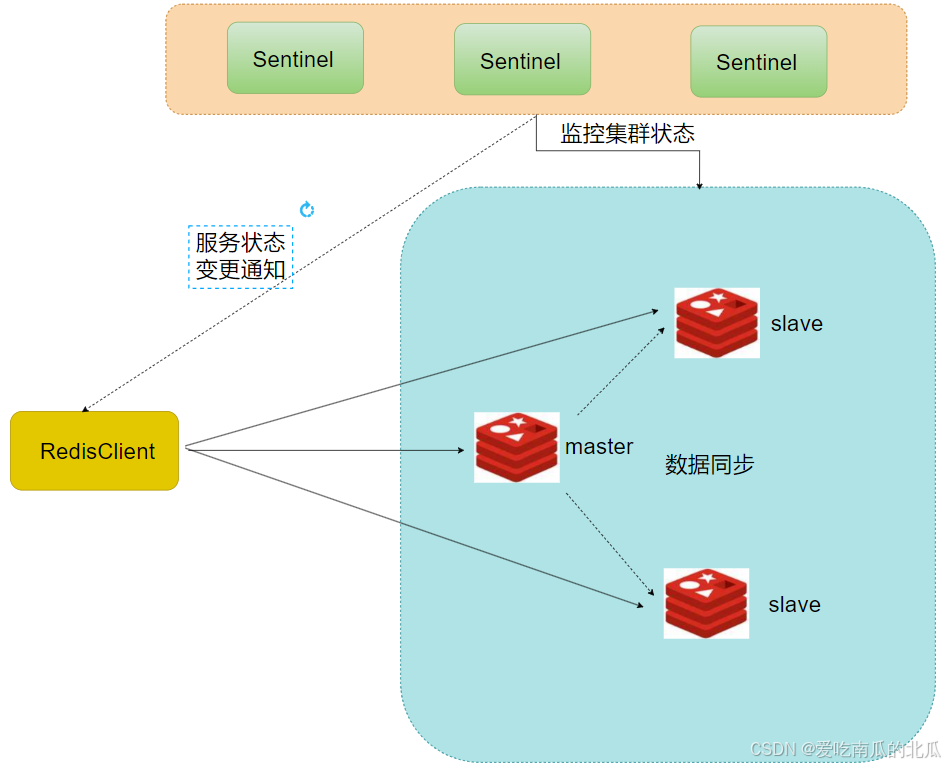
2.哨兵模式
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复
- 监控: Sentinel会不断检查master和slave是否按照与其工作
Sentinel基于心跳监测服务状态,每隔一秒向集群的每个实例发送一个ping命令
– 主观下线: 如果某个Sentinel发现某实例未在规定时间内响应,则认为该实例主观下线
– 客观下线: 超过指定数量(quorum)的sentinel都认为该实例主观下线,则认为该实例客观下线,quorum的值最好超过Sentinel实例数量的一半
- 自动故障恢复: 如果master故障,Sentinel会将一个slave提升为master,当故障实例恢复后也以新的master为主
哨兵选主原则
- 首先判断主从节点断开时间长短,如超过指定值就排除该从节点不会被提升为主节点
判断从节点的slave-priority值,越小优先级越高
如果slave-priority一样,则判断slave节点的offset值,越大优先级越高
最后是判断slave节点的运行id大小,越小优先级越高
- 通知: Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
Redis的集群脑裂是什么?
集群脑裂是由于主节点和从节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主节点,这样就存在了两个master,这样就会导致客户端还在旧的主节点哪里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将旧的主节点降为从节点,再从新的master中同步数据,就会导致数据丢失
解决方案:
修改redis的配置,设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失。
# 表示最少的slave节点为1个
min-replicas-to-write 1 # 表示数据复制和同步的延迟不能超过5秒
min-replicas-max-lag 5
小结:
主从和哨兵可以解决高可用,高并发读的问题
但是当出现数据量很多或者需要高并发写的场景时,主从和哨兵模式就会吃力。 为了解决这个问题,引入分片集群的概念
3.分片集群
分片集群:
- 集群中有多个master,每个master保存不同的数据
- 每个master有自己的slave节点
- master之间通过ping来监测彼此的健康状态
- 客户端的请求可以访问集群任意节点,最终都会被转发到正确节点
工作细节:
- Redis分片集群引入了哈希槽的概念,Redis集群有16384个哈希槽
- 将16384个哈希槽分配到不同的master实例上
- 读写数据:根据key的有效部分计算哈希值(有效部分:如果key前有大括号,那么有效部分就是大括号内的内容,如果没有,则以key本身作为有效部分),对16384取余,余数为插槽,寻找插槽所在的实例












