
Hyper-SD:有效图像合成的轨迹分割一致性模型
paper是字节跳动发表在NIPS 2024的工作
paper title:Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
Code:地址

图1。我们的Hyper-SDXL和其他方法之间的视觉比较。从第一列到第四列,这些图像的提示是(1)一只穿着白色T恤的狗,上面写着“ hyper”一词…(2)抽象的美女,接近完美,纯形,形式,黄金比例,简约,未完成,…(3)宁静的禅宗花园中的苔藓躺在苔藓上…(4)科学家雄鹿的拟人化艺术,分别是Krenz Cushart的维多利亚时代启发的服装…分别。
Abstract
最近,已经出现了一系列扩散感知蒸馏算法,以减轻与扩散模型(DMS)多步推理过程相关的计算开销。当前的蒸馏技术通常会分为两个不同的方面:i)ode轨迹保存; ii)ODE轨迹重新制定。但是,这些方法患有严重的性能降解或域移位。为了解决这些局限性,我们提出了Hyper-SD,这是一个新型框架,协同合并ODE轨迹保存和重新制定的优势,同时在台阶压缩过程中保持近乎无情的性能。首先,我们引入轨迹分段的一致性蒸馏,以在预定义的时间段段内逐步执行一致的蒸馏,从而有助于从高阶的角度来保存原始ODE轨迹。其次,我们结合了人类的反馈学习,以在低步骤中提高模型的性能,并减轻蒸馏过程所产生的性能损失。第三,我们集成了分数蒸馏,以进一步提高模型的低步生成能力,并提供首次尝试利用统一的LoRA以在所有步骤中支持推理过程。广泛的实验和用户研究表明,SDXL和SD1.5的Hyper-SD可以从1到8个推理步骤达到SOTA性能。例如,Hyper-SDXL CLIP得分超过0.68,在1步推理中以AES得分+0.51。
1 Introduction
扩散模型(DMS)在生成AI的领域中获得了显着的突出性[9,25,20,24],但与多步推理程序相关的计算需求[36,12]给予了负担[27,10] 。为了克服这些挑战并充分利用DMS的功能,已经提出了几种蒸馏方法[27,32,46,10,16,29,29,14,40,28]蒸馏和轨迹更新的蒸馏。
轨迹蒸馏技术旨在维护普通微分方程(ODE)的原始轨迹[27,46]。这些方法的主要目的是使学生模型能够对流程进行进一步的预测,并减少推理步骤的总数。这些技术优先考虑蒸馏模型和原始模型的输出之间的相似性。也可以利用对抗性损失来提高蒸馏过程中监督指导的准确性[14]。但是,重要的是要注意,尽管它们有好处,但由于模型拟合中不可避免的错误,轨迹保留的蒸馏方法可能会降低生成质量。
轨迹重新构的方法直接利用ode流或真实图像的端点作为监督的主要来源,而无视轨迹的中间步骤[16,29,28]。通过重建更有效的轨迹,这些方法还可以减少推理步骤的数量。轨迹改良的方法可以在有限数量的步骤中探索模型的潜力,从而使其从原始轨迹的约束中解放出来。但是,这可能导致加速模型与原始模型的输出域之间的不一致,通常会导致不希望的效果。
为了浏览这些障碍并利用DMS的全部潜力,我们提出了一个高级框架,该框架熟练地结合了轨迹具有轨迹和轨迹更新的蒸馏技术。首先,我们提出了轨迹分割的一致性蒸馏(TSCD),该曲线将时间步长划分为细分市场并在每个段内实施一致性,同时逐渐减少段数以达到历史一致性。该方法解决了由于模型拟合能力不足和推理中的累积错误而引起的次优的一致性模型性能问题。其次,我们利用人类反馈学习技术[37,44,23]来优化加速模型,修改ode轨迹以更好地适合少数步骤推断。这导致了大幅改进的性能,甚至超过了某些情况下原始模型的功能。第三,我们使用得分蒸馏[35,40]增强了一步生成的性能,通过统一的Lora实现了理想化的历史一致模型。
总而言之,我们的主要贡献总结如下:1)加速:我们提出的TSCD可以为原始的基于得分的模型实现更细粒度和高阶的一致性蒸馏方法。 2)提升:我们对人类的反馈学习不利,以进一步增强少步中的模型性能。 3)统一:我们提供统一的LoRA作为所有NTE的历史一致性模型和支持推断。 4)性能:Hyper-SD可在SDXL和SD1.5的低步推理中达到SOTA性能。
2 Preliminaries
2.1 Diffusion Model Distillation
正如第 1 节所述,目前扩散模型(DMs)的蒸馏技术可以大致分为两类:
一类是保持常微分方程(ODE)轨迹的方法 [ 27 , 32 , 46 , 10 ] [27,32,46,10] [27,32,46,10],另一类是对其进行重构的方法 [ 29 , 14 , 40 , 28 ] [29,14,40,28] [29,14,40,28]。
在这里,我们对一些代表性的方法类别进行简要概述。为清晰起见,我们定义:
- 教师模型为 f tea f_{\text{tea}} ftea,学生模型为 f stu f_{\text{stu}} fstu,
- 噪声为 ϵ \epsilon ϵ,提示条件为 c c c,
- 现成的 ODE 求解器为 Ψ ( ⋅ , ⋅ , ⋅ ) \Psi(\cdot, \cdot, \cdot) Ψ(⋅,⋅,⋅),
- 训练总时间步数为 T T T,推理时间步数为 N N N,
- 带噪声的轨迹点为 x t x_t xt,跳步大小为 s s s,其中:
t 0 < t 1 < ⋯ < t N − 1 = T t_0 < t_1 < \dots < t_{N-1} = T t0<t1<⋯<tN−1=T,且 t n − t n − 1 = s t_n - t_{n-1} = s tn−tn−1=s, n n n 均匀分布在 { 1 , 2 , … , N − 1 } \{1,2,\dots,N-1\} {1,2,…,N−1} 之上。
渐进蒸馏(Progressive Distillation,PD)
渐进蒸馏(PD)方法 [ 27 ] [27] [27] 训练学生模型 f stu f_{\text{stu}} fstu 以逼近教师模型 f tea f_{\text{tea}} ftea 通过多个步骤确定的后续流动位置。
以两步渐进蒸馏(2-step PD)为例,教师模型 f tea f_{\text{tea}} ftea 预测的目标 x ^ t n − 2 \hat{x}_{t_{n-2}} x^tn−2 计算如下:
x ^ t n − 1 = Ψ ( x t n , f tea ( x t n , t n , c ) , t n − 1 ) x ^ t n − 2 = Ψ ( x ^ t n − 1 , f tea ( x ^ t n − 1 , t n − 1 , c ) , t n − 2 ) \begin{gathered} \hat{x}_{t_{n-1}} = \Psi\left(x_{t_n}, f_{\text{tea}}\left(x_{t_n}, t_n, c\right), t_{n-1}\right) \\ \hat{x}_{t_{n-2}} = \Psi\left(\hat{x}_{t_{n-1}}, f_{\text{tea}}\left(\hat{x}_{t_{n-1}}, t_{n-1}, c\right), t_{n-2}\right) \end{gathered} x^tn−1=Ψ(xtn,ftea(xtn,tn,c),tn−1)x^tn−2=Ψ(x^tn−1,ftea(x^tn−1,tn−1,c),tn−2)
训练损失定义为:
L P D = ∥ x ^ t n − 2 − Ψ ( x t n , f stu ( x t n , t n , c ) , t n − 2 ) ∥ 2 2 \mathcal{L}_{PD} = \left\|\hat{x}_{t_{n-2}} - \Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), t_{n-2}\right)\right\|_2^2 LPD=∥x^tn−2−Ψ(xtn,fstu(xtn,tn,c),tn−2)∥22
一致性蒸馏(Consistency Distillation,CD)
一致性蒸馏(CD) [ 32 ] [32] [32] 直接将 x t n x_{t_n} xtn 映射到 ODE 轨迹的终点 x 0 x_0 x0。其训练损失定义如下:
L C D = ∥ Ψ ( x t n , f stu ( x t n , t n , c ) , 0 ) − Ψ ( x ^ t n − 1 , f stu − ( x ^ t n − 1 , t n − 1 , c ) , 0 ) ∥ 2 2 \mathcal{L}_{CD} = \left\|\Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), 0\right) - \Psi\left(\hat{x}_{t_{n-1}}, f_{\text{stu}}^{-}\left(\hat{x}_{t_{n-1}}, t_{n-1}, c\right), 0\right)\right\|_2^2 LCD= Ψ(xtn,fstu(xtn,tn,c),0)−Ψ(x^tn−1,fstu−(x^tn−1,tn−1,c),0) 22
其中, f stu − f_{\text{stu}}^{-} fstu− 是 f stu f_{\text{stu}} fstu 的指数移动平均(EMA),
x ^ t n − 1 \hat{x}_{t_{n-1}} x^tn−1 是教师模型 f tea f_{\text{tea}} ftea 估计的下一个流动位置,与公式 (1) 相同。
一致性轨迹模型(Consistency Trajectory Model,CTM)
一致性轨迹模型(CTM) [ 10 ] [10] [10] 旨在最小化多步一致性模型采样中常见的累计估计误差和离散化误差。
CTM 不再直接预测终点 x 0 x_0 x0,而是目标为 0 ≤ t end ≤ t n − 1 0 \leq t_{\text{end}} \leq t_{n-1} 0≤tend≤tn−1 范围内的任意中间点 x t end x_{t_{\text{end}}} xtend,从而重新定义损失函数如下:
L C T M = ∥ Ψ ( x t n , f stu ( x t n , t n , c ) , t end ) − Ψ ( x ^ t n − 1 , f stu − ( x ^ t n − 1 , t n − 1 , c ) , t end ) ∥ 2 2 \mathcal{L}_{CTM} = \left\|\Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), t_{\text{end}}\right) - \Psi\left(\hat{x}_{t_{n-1}}, f_{\text{stu}}^{-}\left(\hat{x}_{t_{n-1}}, t_{n-1}, c\right), t_{\text{end}}\right)\right\|_2^2 LCTM= Ψ(xtn,fstu(xtn,tn,c),tend)−Ψ(x^tn−1,fstu−(x^tn−1,tn−1,c),tend) 22
对抗扩散蒸馏(Adversarial Diffusion Distillation, ADD)
与渐进蒸馏(PD)和一致性蒸馏(CD)不同,对抗蒸馏(ADD)是在 SDXL-Turbo [29] 和 SD3-Turbo [28] 提出的方法。
该方法绕过了 ODE 轨迹,直接通过对抗目标优化,关注原始状态 x 0 x_0 x0。
生成器损失(Generative Loss)和判别器损失(Discriminative Loss)计算如下:
L A D D G = − E [ D ( Ψ ( x t n , f stu ( x t n , t n , c ) , 0 ) ) ] L A D D D = E [ D ( Ψ ( x t n , f stu ( x t n , t n , c ) , 0 ) ) ] − E [ D ( x 0 ) ] \begin{gathered} \mathcal{L}_{ADD}^G = -\mathbb{E} \left[ D\left(\Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), 0\right)\right) \right] \\ \mathcal{L}_{ADD}^D = \mathbb{E} \left[ D\left(\Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), 0\right)\right) \right] - \mathbb{E} \left[ D\left(x_0\right) \right] \end{gathered} LADDG=−E[D(Ψ(xtn,fstu(xtn,tn,c),0))]LADDD=E[D(Ψ(xtn,fstu(xtn,tn,c),0))]−E[D(x0)]
其中, D D D 代表判别器(discriminator),其任务是区分 x 0 x_0 x0 和 Ψ ( x t n , f stu ( x t n , t n , c ) , 0 ) \Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), 0\right) Ψ(xtn,fstu(xtn,tn,c),0) 之间的差异。
目标 x 0 x_0 x0 可以从真实数据或合成数据中采样。
分数蒸馏采样(Score Distillation Sampling, SDS)
分数蒸馏采样(SDS) [ 21 ] [21] [21] 被集成到扩散蒸馏方法中,例如 SDXL-Turbo [ 29 ] [29] [29] 和 Diffusion Matching Distillation(DMD) [ 40 ] [40] [40]。
- SDXL-Turbo [ 29 ] [29] [29] 使用 教师模型 f tea f_{\text{tea}} ftea 来估计分数(score),以匹配真实数据分布。
- DMD [ 40 ] [40] [40] 进一步引入 虚假分布模拟器 f fake f_{\text{fake}} ffake 来校准分数方向,并使用原始模型的输出分布作为真实分布,从而实现一步推理(One-Step Inference)。
利用 DMD 方法,真实分布和伪分布之间的 Kullback-Leibler(KL)散度梯度近似如下:
∇ D K L = E z ∼ N ( 0 , I ) x = f stu ( z ) [ − ( f real ( x ) − f fake ( x ) ) ∇ f stu ( z ) ] \nabla D_{KL} = \underset{\substack{z \sim \mathcal{N}(0, I) \\ x=f_{\text{stu}}(z)}}{\mathbb{E}} \left[ -\left(f_{\text{real}}(x) - f_{\text{fake}}(x)\right) \nabla f_{\text{stu}}(z) \right] ∇DKL=z∼N(0,I)x=fstu(z)E[−(freal(x)−ffake(x))∇fstu(z)]
其中:
- z z z 是从标准正态分布 N ( 0 , I ) \mathcal{N}(0, I) N(0,I) 采样的随机潜变量。
- 该方法允许一步扩散模型(One-Step Diffusion Model)优化其生成过程,使其最小化 KL 散度,从而生成的图像逐渐逼近教师模型的分布。
2.2 Human Feedback Learning
ReFL(Reference-Free Learning)
ReFL [ 37 , 13 , 44 ] [37,13,44] [37,13,44] 已被证明是一种针对扩散模型的人类反馈学习的有效方法。它主要包括两个阶段:
(1) 奖励模型训练 (Reward Model Training) 和 (2) 偏好微调 (Preference Fine-Tuning)。
(1) 奖励模型训练
在第一阶段,给定人类偏好数据对:
- x w x_w xw(偏好生成的图像)
- x l x_l xl(不偏好生成的图像)
通过以下损失函数训练奖励模型 r θ r_\theta rθ:
L ( θ ) r m = − E ( c , x w , x l ) ∼ D [ log ( σ ( r θ ( c , x w ) − r θ ( c , x l ) ) ) ] \mathcal{L}(\theta)_{r m}=-\mathbb{E}_{\left(c, x_w, x_l\right) \sim \mathcal{D}}\left[\log \left(\sigma\left(r_\theta\left(c, x_w\right)-r_\theta\left(c, x_l\right)\right)\right)\right] L(θ)rm=−E(c,xw,xl)∼D[log(σ(rθ(c,xw)−rθ(c,xl)))]
其中:
- D \mathcal{D} D 代表收集的反馈数据,
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 为 Sigmoid 函数,
- c c c 表示文本提示(text prompt)。
奖励模型 r θ r_\theta rθ 经过优化后,可生成与人类偏好一致的奖励分数。
(2) 偏好微调
在第二阶段,ReFL 以输入提示 c c c 和随机初始化的潜变量 x T = z x_T = z xT=z 作为起点。
然后对潜变量进行迭代去噪,直至到达随机选择的时间步 t n ∈ [ t left , t right ] t_n \in \left[t_{\text{left}}, t_{\text{right}}\right] tn∈[tleft,tright],此时直接从 x t n x_{t_n} xtn 预测去噪图像 x 0 ′ x_0^{\prime} x0′。
t left t_{\text{left}} tleft 和 t right t_{\text{right}} tright 是预定义边界。
奖励模型随后应用于该去噪图像,生成期望的偏好分数 r θ ( c , x 0 ′ ) r_\theta\left(c, x_0^{\prime}\right) rθ(c,x0′),用于微调扩散模型:
L ( θ ) r e f l = E c ∼ p ( c ) E x 0 ′ ∼ p ( x 0 ′ ∣ c ) [ − r ( x 0 ′ , c ) ] \mathcal{L}(\theta)_{r e f l}=\mathbb{E}_{c \sim p(c)} \mathbb{E}_{x_0^{\prime} \sim p\left(x_0^{\prime} \mid c\right)}\left[-r\left(x_0^{\prime}, c\right)\right] L(θ)refl=Ec∼p(c)Ex0′∼p(x0′∣c)[−r(x0′,c)]
3 Method
在这项研究中,我们将Ode-preserve和Ode-Reforment的蒸馏技术同时整合到了统一的框架中,从而在加速扩散模型中取得了重大进步。在第二部分。 3.1,我们提出了一种创新的一致性蒸馏方法,该方法采用了时步分割策略,从而促进了轨迹分割的一致性蒸馏。在第二部分。 3.2,我们结合了人类的反馈学习技术,以进一步增强加速扩散模型的性能。在第二部分。 3.3,我们通过利用基于得分的分布匹配蒸馏来实现历史一致性,包括一步。
3.1 Trajectory Segmented Consistency Distillation
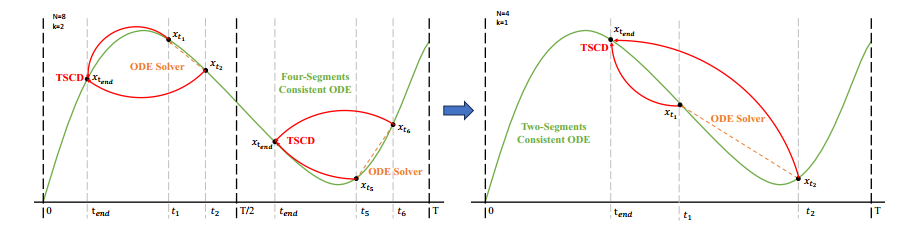
两阶段轨迹分段一致性蒸馏(TSCD)的示意图。
第一阶段在两个独立的时间段 [ 0 , T 2 ] \left[0, \frac{T}{2}\right] [0,2T] 和 [ T 2 , T ] \left[\frac{T}{2}, T\right] [2T,T] 内进行一致性蒸馏,以获得两段一致性 ODE 轨迹。 随后,在第二阶段,这些 ODE 轨迹被用于训练全局一致性模型。
轨迹分段一致性蒸馏(Trajectory Segmented Consistency Distillation, TSCD)
一致性蒸馏(Consistency Distillation, CD)[32] 和一致性轨迹模型(Consistency Trajectory Model, CTM)[10] 旨在通过单阶段蒸馏,在整个时间步范围 [ 0 , T ] [0, T] [0,T] 内,将扩散模型转化为一致性模型。然而,由于模型拟合能力的限制,这些蒸馏模型通常难以达到最优性能。
借鉴 CTM 提出的软一致性目标,我们改进了训练流程:
- 将整个时间步范围 [ 0 , T ] [0, T] [0,T] 划分为 k k k 个子区间
- 逐步进行分段一致性模型蒸馏
第一阶段
在初始阶段,我们设定 k = 8 k=8 k=8,并使用原始扩散模型来初始化 f stu f_{\text{stu}} fstu 和 f tea f_{\text{tea}} ftea。
起始时间步 t n t_n tn 从集合 { t 1 , t 2 , … , t N − 1 } \left\{t_1, t_2, \ldots, t_{N-1}\right\} {t1,t2,…,tN−1} 中均匀随机采样。
随后,结束时间步 t end t_{\text{end}} tend 从区间 [ t b , t n − 1 ] \left[t_b, t_{n-1}\right] [tb,tn−1] 中采样,其中:
t b = ⌊ t n ⌊ T k ⌋ ⌋ × ⌊ T k ⌋ t_b=\left\lfloor\frac{t_n}{\left\lfloor\frac{T}{k}\right\rfloor}\right\rfloor \times\left\lfloor\frac{T}{k}\right\rfloor tb=⌊⌊kT⌋tn⌋×⌊kT⌋
训练损失计算如下:
L T S C D = d ( Ψ ( x t n , f stu ( x t n , t n , c ) , t end ) , Ψ ( x ^ t n − 1 , f stu − ( x ^ t n − 1 , t n − 1 , c ) , t end ) ) L_{TSCD} = d\left(\Psi\left(x_{t_n}, f_{\text{stu}}\left(x_{t_n}, t_n, c\right), t_{\text{end}}\right), \Psi\left(\hat{x}_{t_{n-1}}, f_{\text{stu}}^{-}\left(\hat{x}_{t_{n-1}}, t_{n-1}, c\right), t_{\text{end}}\right)\right) LTSCD=d(Ψ(xtn,fstu(xtn,tn,c),tend),Ψ(x^tn−1,fstu−(x^tn−1,tn−1,c),tend))
其中:
- x ^ t n − 1 \hat{x}_{t_{n-1}} x^tn−1 参考方程 (1),
- f stu − f_{\text{stu}}^{-} fstu− 表示 f stu f_{\text{stu}} fstu 的指数移动平均(EMA)。
逐步缩小区间 k k k
接下来,我们继承前一阶段的模型权重,继续训练 f stu f_{\text{stu}} fstu,逐步降低 k k k,具体步骤如下:
k → [ 8 , 4 , 2 , 1 ] k \rightarrow [8, 4, 2, 1] k→[8,4,2,1]
值得注意的是,当 k = 1 k=1 k=1 时,该训练策略即退化为标准 CTM 训练方案。
损失函数设计
对于距离度量 d d d,我们采用:
- 对抗损失(Adversarial Loss)(参考 SDXL-Lightning [14])
- 均方误差(MSE)损失
我们在实验中观察到:
- 当预测值和目标值接近时(例如 k = 8 , 4 k=8,4 k=8,4),MSE 损失效果更好。
- 当预测值和目标值偏差较大时(例如 k = 2 , 1 k=2,1 k=2,1),对抗损失更为精准。
因此,在训练过程中,我们动态增加对抗损失的权重,并减少 MSE 损失的影响。
此外,我们还集成了噪声扰动机制 [8] 以提高训练稳定性。
两阶段 TSCD 过程
以 两阶段轨迹分段一致性蒸馏(TSCD) 为例:
- 第一阶段:分别在两个时间段 [ 0 , T 2 ] \left[0, \frac{T}{2}\right] [0,2T] 和 [ T 2 , T ] \left[\frac{T}{2}, T\right] [2T,T] 内进行独立的一致性蒸馏。
- 第二阶段:基于前两个子区间的蒸馏结果,执行全局一致性轨迹蒸馏。
TSCD 的主要优势
- 细粒度分段蒸馏降低了模型拟合难度,减少了误差,从而提升生成质量。
- 保持了原始 ODE 轨迹的特性:
- 训练过程中,每个阶段的模型可以用于对应步数的推理,
- 生成质量与原始模型高度一致。
完整的 轨迹分段一致性蒸馏(TSCD) 过程详见附录 B。
LoRA 适配
值得注意的是,我们利用低秩适配(LoRA)技术,使 TSCD 训练的模型可以作为即插即用的插件,无需额外微调,即可直接用于推理。
3.2 Human Feedback Learning
反馈学习在扩散蒸馏中的应用
除了蒸馏方法外,我们进一步提出结合反馈学习(Feedback Learning),以提升加速扩散模型的性能。
特别地,我们利用来自人类美学偏好和现有视觉感知模型的反馈信息,来提高加速模型的生成质量。
(1) 美学偏好反馈
针对美学反馈,我们采用:
- LAION 数据集的美学预测器,
- ImageReward 提供的美学偏好奖励模型 [37]。
通过这些美学反馈,我们引导模型生成更具美学质量的图像,损失函数定义如下:
L ( θ ) aes = ∑ E c ∼ p ( c ) E x 0 ′ ∼ p ( x 0 ′ ∣ c ) [ ReLU ( α d − r d ( x 0 ′ , c ) ) ] \mathcal{L}(\theta)_{\text{aes}}=\sum \mathbb{E}_{c \sim p(c)} \mathbb{E}_{x_0^{\prime} \sim p\left(x_0^{\prime} \mid c\right)}\left[\operatorname{ReLU}\left(\alpha_d-r_d\left(x_0^{\prime}, c\right)\right)\right] L(θ)aes=∑Ec∼p(c)Ex0′∼p(x0′∣c)[ReLU(αd−rd(x0′,c))]
其中:
- r d r_d rd 为美学奖励模型,包括 LAION 数据集的美学预测器 和 ImageReward 模型。
- c c c 为文本提示(textual prompt)。
- α d \alpha_d αd 和 ReLU 函数共同构成 Hinge Loss。
(2) 视觉感知模型反馈
除了美学偏好反馈,我们观察到已有的视觉感知模型(嵌入了丰富的先验知识)也能作为高效的反馈信号。
实验表明,实例分割模型可以引导模型生成结构合理的目标。
具体步骤
- 利用原始图像 x 0 x_0 x0 进行加噪,从潜空间扩散至 x t x_t xt(参见方程 (16))。
- 在特定时间步 d t d_t dt 执行去噪,预测生成 x 0 ′ x_0^{\prime} x0′,方法类似于 [37]。
- 利用实例分割模型评估结构合理性:
- 计算去噪图像 x 0 ′ x_0^{\prime} x0′ 与真实图像 x 0 x_0 x0 的实例分割差异。
- 通过感知差异损失优化模型:
L ( θ ) percep = E x 0 ∼ D x 0 ′ ∼ G ( x t a ) L instance ( ( m I ( x 0 ′ ) ) , G T ( x 0 ) ) \mathcal{L}(\theta)_{\text{percep}}=\underset{\substack{x_0 \sim \mathcal{D} \\ x_0^{\prime} \sim G\left(x_{t_a}\right)}}{\mathbb{E}} \mathcal{L}_{\text{instance}}\left(\left(m_I\left(x_0^{\prime}\right)\right), GT\left(x_0\right)\right) L(θ)percep=x0∼Dx0′∼G(xta)ELinstance((mI(x0′)),GT(x0))
其中:
- m I m_I mI 代表实例分割模型(如 SOLO [34])。
- 实例分割模型可以更精准地捕捉生成图像的结构缺陷,并提供更有针对性的反馈信号。
值得注意的是,除了实例分割模型外,其他视觉感知模型也适用。
我们正在探索先进的大规模视觉感知模型(如 SAM) 来提供增强的反馈学习。
这些感知模型可以作为美学反馈的补充,更侧重于客观的生成质量。
(3) 反馈学习损失
基于上述两类反馈信号,我们优化扩散模型的损失函数如下:
L ( θ ) feedback = L ( θ ) aes + L ( θ ) percep \mathcal{L}(\theta)_{\text{feedback}}=\mathcal{L}(\theta)_{\text{aes}}+\mathcal{L}(\theta)_{\text{percep}} L(θ)feedback=L(θ)aes+L(θ)percep
(4) LoRA 插件化
虽然人类反馈学习能够提升模型性能,但它可能会无意中改变输出域,这并不总是理想的。
因此,我们将人类反馈学习知识作为 LoRA 插件进行训练。
通过将反馈学习 LoRA 与 TSCD LoRA(第 3.1 节讨论) 进行合并,
我们可以在生成质量和输出域相似性之间实现灵活平衡。
3.3 One-step Generation Enhancement
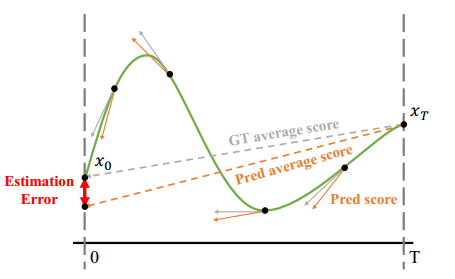
对比了基于分数的模型与一致性模型的分数蒸馏:- 基于分数的模型估计误差通常比一致性模型更大。- 一致性模型的蒸馏目标更加稳定,更适合引导模型收敛至 x 0 x_0 x0。
一致性模型框架下的一步生成
一致性模型框架内的一步生成并不理想,其主要限制来自一致性损失的固有缺陷。
如 图 3 所示,一致性蒸馏模型在指导轨迹端点 x 0 x_0 x0 方面表现出色,尤其在 x t x_t xt 位置预测时更具准确性。
因此,分数蒸馏(Score Distillation) 是提升 TSCD 模型 一步生成能力的有效方法。
(1) 分布匹配蒸馏(DMD)优化
我们采用优化后的 分布匹配蒸馏(DMD)[40] 技术来增强一步生成:
- DMD 通过两个不同的分数函数提升模型输出:
- f real ( x ) f_{\text{real}}(x) freal(x) 来自教师模型分布。
- f fake ( x ) f_{\text{fake}}(x) ffake(x) 来自伪模型分布。
- 结合均方误差(MSE)损失:
- MSE 旨在提升训练稳定性。
- 结合人类反馈学习(参见 第 3.2 节):
- 进一步微调模型,提高生成的图像质量。
(3) TSCD 模型的一步推理
在增强 TSCD 模型 的一步推理能力后,我们可以获得理想的全局一致性模型。
TCD 采样调度器
- 采用 TCD 采样调度器 [46],增强后的模型可支持 1 到 8 步推理。
- 无需转换为 x 0 x_0 x0 预测模型 [14],可直接实现一步 LoRA 插件。
- 第 4.3 节 详细展示了一步 LoRA 插件的有效性。
更小的时间步输入
- 较小的时间步输入可提高一步扩散模型的噪声预测可靠性 [7]。
- 因此,我们使用该技术训练专门的单步生成模型。












