
文章目录
- 模块一:后端服务基础概念
- 1. 后端是干什么的?
- 2. 前后端分离
- 3. API 是什么?
- 4. RESTful API 设计原则
- 5. HTTP 状态码
- 模块二:数据库基础
- 1. 数据库是干什么的?
- 2. SQL vs NoSQL 怎么选?
- 3. 数据库设计三大原则
- 4. 事务(Transaction)
- 5. ORM是什么?
- 模块三:鉴权与安全
- 1. 鉴权(Authentication) vs 授权(Authorization)
- 2. 常见鉴权方式
- 3. 密码存储原则
- 4. HTTPS 为什么重要?
- 5. 常见安全威胁
- 模块四:RESTful API 进阶与最佳实践
- 1. 资源嵌套与路由设计
- 2. 版本控制
- 3. 分页、过滤、排序
- 4. 错误处理标准化
- 5. API限流(Rate Limiting)
- 6. 文档化
- 实际案例对比
- 7. Swagger 是什么?
- 模块五:缓存机制与性能优化
- 1. 缓存是什么?为什么需要它?
- 2. 常见缓存位置
- 3. 缓存策略
- 3.1 缓存过期策略
- 3.2 缓存更新策略
- 4. 缓存穿透 vs 缓存击穿 vs 缓存雪崩
- 5. 实战示例:Redis缓存用户信息
- 模块六:消息队列与异步处理
- 1. 为什么需要消息队列?
- 2. 常见消息队列系统
- 3. 消息队列核心概念
- 4. 消息队列工作模式
- 4.1 点对点模式(一对一)
- 4.2 发布/订阅模式(一对多)
- 5. 实战场景:订单超时取消
- 传统同步方式的问题:
- 消息队列优化方案:
- 6. 消息可靠性保证
- 7. 代码示例(Python + RabbitMQ)
- 关键决策点:什么时候用消息队列?
- 模块七:微服务架构基础
- 1. 什么是微服务?
- 2. 微服务 vs 单体架构
- 3. 微服务核心组件
- 3.1 服务注册与发现
- 3.2 API网关
- 4. 服务间通信
- 5. 实战场景:电商下单
- 6. 微服务的代价(不是银弹!)
- 7. 什么时候该用微服务?
模块一:后端服务基础概念
1. 后端是干什么的?
- 核心作用:处理数据、实现业务逻辑、保证安全。
- 类比:像餐厅的后厨,负责“做菜”(处理数据)、“按菜单做菜”(执行业务逻辑)、“检查食材安全”(安全性)。
- 关键能力:接收请求 → 处理数据 → 返回结果。
2. 前后端分离
- 前端:负责界面和用户交互(服务员点单)。
- 后端:负责数据处理和逻辑(后厨做菜)。
- 沟通方式:通过 API(类似服务员和后厨之间的“小票”)。
3. API 是什么?
- 定义:Application Programming Interface(应用程序接口)。
- 作用:前后端交互的“规则手册”,比如:
- 前端问:“如何获取用户信息?”
- 后端答:“调用
/api/users/{id},用 GET 方法。”
4. RESTful API 设计原则
- 核心思想:用 HTTP 方法对应操作类型:
GET:查数据(获取用户)POST:增数据(创建用户)PUT:改数据(全量更新)PATCH:改数据(局部更新)DELETE:删数据
- 示例:
- 错误设计:
/getUser?id=1(动词冗余) - 正确设计:
GET /users/1(用HTTP方法表达动作)
- 错误设计:
PUT&&PATCH 核心区别
- PUT:全量更新 → “把整个东西换掉”(必须提供完整数据)。
- PATCH:局部更新 → “只改某个部分”(只需传要改的字段)。
举个栗子🌰:用户信息更新
假设用户数据长这样:
{"id": 1,"name": "张三","age": 25,"email": "zhangsan@example.com"
}
场景1:用PUT更新
- 需求:把用户信息全部替换成新数据。
- 请求:
PUT /users/1 Body: {"name": "李四","age": 30,"email": "lisi@example.com" } - 结果:整个用户数据被替换,所有字段必须传(如果漏传
email,服务端可能认为你要删掉它,导致数据丢失!)。
场景2:用PATCH更新
- 需求:只修改用户的年龄。
- 请求:
PATCH /users/1 Body: {"age": 26 } - 结果:只更新
age字段,其他字段(如name,email)保持不变。
什么时候用PUT?
- 客户端能提供完整资源数据(比如编辑整个表单)。
- 强制要求更新所有字段(比如修改密码必须重新输入所有信息)。
- 明确需要覆盖旧数据(比如替换整个配置文件)。
什么时候用PATCH?
- 只修改部分字段(比如改用户名不改头像)。
- 网络带宽敏感(只传少量数据节省流量)。
- 避免覆盖风险(比如多人协作时,A改名字,B改年龄,互不影响)。
常见误区
- 用PUT做局部更新:
- 错误示例:PUT只传
age字段 → 导致其他字段被清空。
- 错误示例:PUT只传
- 用PATCH传完整数据:
- 虽然技术上可行,但语义错误(PATCH本意是局部更新)。
开发建议
- 服务端实现:
- PUT:检查请求是否包含所有必填字段。
- PATCH:只处理请求中提供的字段。
- API文档明确说明:
- 告诉调用方:“用PUT必须传全字段,用PATCH只需传要改的字段”。
5. HTTP 状态码
- 必知三类:
2xx:成功(200 OK,201 Created)4xx:客户端错误(400 参数错误,404 找不到)5xx:服务器错误(500 代码崩了)
- 误区:别所有错误都返回 200,比如:
{ "code": 404, "message": "用户不存在" } // 错误!应该直接返回HTTP 404状态码
模块二:数据库基础
1. 数据库是干什么的?
- 核心作用:持久化存储数据(把数据存到硬盘而不是内存),方便高效读写。
- 类比:像一个大Excel表格,但能处理百万行数据不卡死。
- 常见类型:
- SQL(关系型数据库):如MySQL、PostgreSQL → 数据按表存储,表之间有联系。
- NoSQL(非关系型):如MongoDB、Redis → 灵活存储(文档、键值对等)。
2. SQL vs NoSQL 怎么选?
- SQL适用场景:
- 需要强数据一致性(比如银行转账)。
- 复杂查询(如跨表关联查询)。
- 数据结构固定(比如用户表字段明确)。
- NoSQL适用场景:
- 数据结构多变(比如随时新增字段)。
- 高并发读写(比如微博热搜实时统计)。
- 简单查询,追求速度。
3. 数据库设计三大原则
-
原则1:范式化(减少冗余)
- 例:用户表和订单表分开,订单表只存用户ID,而不是重复存用户名。
- 好处:数据一致性强,更新时只需改一处。
- 代价:查询时可能需要联表(JOIN)。
-
原则2:主键与外键
- 主键:唯一标识一行数据的字段(比如用户ID)。
- 外键:指向另一张表主键的字段(比如订单表中的用户ID)。
- 作用:建立表之间的关系,保证数据完整性。
-
原则3:索引(加速查询的目录)
- 类比:像书的目录,帮你快速找到章节。
- 常见索引类型:
- 主键索引(自动创建)
- 唯一索引(确保字段值唯一)
- 普通索引(加速查询)
- 注意:索引不是越多越好!索引会占用空间,且增删改数据时会变慢。
4. 事务(Transaction)
- 定义:一组数据库操作,要么全部成功,要么全部失败。
- 经典案例:银行转账(A转100给B,A余额减100,B余额加100,必须同时成功或失败)。
- ACID特性:
- Atomicity(原子性):事务不可拆分。
- Consistency(一致性):事务前后数据状态合法(比如余额不能为负)。
- Isolation(隔离性):多个事务并发执行互不干扰。
- Durability(持久性):事务提交后数据永久保存。
5. ORM是什么?
- 定义:Object-Relational Mapping(对象关系映射),把数据库表映射成代码中的类。
- 作用:不用写SQL,用代码操作对象就能读写数据库。
- 示例(伪代码):
# 传统SQL cursor.execute("SELECT * FROM users WHERE id = 1") # ORM方式 user = User.objects.get(id=1) - 优点:代码更简洁,避免SQL注入风险。
- 缺点:复杂查询可能性能差,需手动优化。
模块三:鉴权与安全
1. 鉴权(Authentication) vs 授权(Authorization)
- 鉴权:验证你是谁 → “你是不是用户张三?”(比如登录)。
- 授权:验证你能做什么 → “张三能不能删除这条数据?”(比如权限控制)。
2. 常见鉴权方式
-
Session-Cookie 模式:
- 流程:用户登录 → 服务端生成Session存到数据库 → 返回Cookie(Session ID)给浏览器 → 后续请求带Cookie验证。
- 优点:成熟稳定。
- 缺点:服务端存储Session,集群环境下需要共享Session(比如用Redis)。
-
JWT(JSON Web Token):
- 流程:用户登录 → 服务端生成Token(包含用户信息+签名)→ 客户端存Token → 后续请求带Token。
- 特点:Token自包含,服务端无需存储,适合分布式系统。
- 风险:Token一旦泄露,无法强制失效(需结合短期有效期+黑名单)。
-
OAuth 2.0:
- 场景:第三方应用授权(比如“用微信登录”)。
- 角色:
- 用户 → 资源所有者
- 微信 → 授权服务器
- 第三方App → 客户端
3. 密码存储原则
- 绝对禁忌:明文存储密码!
- 正确做法:
- 哈希(Hash)处理:如SHA-256(但单纯哈希不够,会被彩虹表破解)。
- 加盐(Salt):每个用户密码加随机字符串再哈希 → 相同密码哈希结果不同。
# 伪代码示例 salt = random_string() hashed_password = sha256(password + salt)
4. HTTPS 为什么重要?
- 作用:加密客户端和服务端之间的通信,防止中间人窃听或篡改。
- 对比HTTP:
- HTTP:裸奔传输数据(密码、Cookie容易被窃取)。
- HTTPS:数据加密传输(即使被抓包,看到的也是乱码)。
5. 常见安全威胁
-
SQL注入:
- 攻击方式:通过输入恶意SQL片段篡改查询。
- 示例:
-- 用户输入:' OR 1=1 -- -- 原SQL:SELECT * FROM users WHERE username = '{input}' AND password = '{pwd}' -- 注入后:SELECT * FROM users WHERE username = '' OR 1=1 --' AND password = '...' -- 结果:绕过密码验证! - 防御:使用ORM或参数化查询(不要拼接SQL!)。
-
XSS(跨站脚本攻击):
- 攻击方式:注入恶意脚本到网页,盗取用户Cookie。
- 示例:用户评论中输入
<script>窃取Cookie代码</script>,未过滤直接展示。 - 防御:对用户输入内容转义(如将
<转成<)。
-
CSRF(跨站请求伪造):
- 攻击方式:诱导用户点击链接,伪造请求(比如偷偷转账)。
- 防御:
- 校验请求头中的
Origin或Referer。 - 使用CSRF Token(服务端生成随机Token,提交时校验)。
- 校验请求头中的
模块四:RESTful API 进阶与最佳实践
1. 资源嵌套与路由设计
- 场景:当资源存在从属关系时(如“博客的评论”)。
- 设计示例:
- 获取某篇文章的评论:
GET /articles/123/comments - 创建评论:
POST /articles/123/comments - 不要这样设计:
GET /getCommentsByArticleId?articleId=123(违反RESTful风格)
- 获取某篇文章的评论:
2. 版本控制
- 为什么需要:API升级后,避免破坏旧客户端。
- 实现方式:
- URL中体现版本:
/api/v1/users - 请求头中体现:
Accept: application/vnd.myapi.v1+json
- URL中体现版本:
- 建议:初期至少预留版本号,即使只v1一个版本。
3. 分页、过滤、排序
- 通用参数设计(通过Query Parameters实现):
GET /users?page=2&limit=10&sort=name,asc&role=adminpage:当前页码limit:每页数量sort:排序字段和方向(asc/desc)role:过滤条件(只返回角色为admin的用户)
- 响应格式建议:
{"data": [...], // 当前页数据"pagination": {"page": 2,"limit": 10,"total": 345} }
4. 错误处理标准化
- 统一响应格式:
{"error": {"code": "INVALID_EMAIL", // 自定义错误码"message": "邮箱格式不正确","details": "输入的邮箱缺少@符号" // 可选,调试用详细信息} } - HTTP状态码配合:
- 业务逻辑错误用4xx状态码(如400 Bad Request)。
- 错误信息要友好,避免暴露服务器细节(如不要返回数据库错误日志)。
5. API限流(Rate Limiting)
- 为什么需要:防止恶意请求或过量调用拖垮服务器。
- 常见策略:
- 按用户限制:每个用户每分钟最多100次请求。
- 按IP限制:每个IP每天1000次请求。
- 响应头告知客户端:
HTTP/1.1 200 OK X-RateLimit-Limit: 100 // 总限额 X-RateLimit-Remaining: 99 // 剩余次数 X-RateLimit-Reset: 3600 // 重置剩余时间(秒)
6. 文档化
- 工具推荐:
- Swagger/OpenAPI:自动生成交互式文档。
- Postman:提供API集合和示例。
- 文档必备内容:
- 端点URL、支持的HTTP方法
- 请求参数(Query、Body、Headers)
- 响应格式(成功和失败示例)
实际案例对比
差的设计:
GET /getUserList?pageNum=1 // 动词冗余
POST /updateUserInfo // 动作藏在URL里
响应:所有错误都返回200,错误信息藏在body里
好的设计:
GET /users?page=1 // 资源化路径
PATCH /users/123 // 用HTTP方法表达动作
响应:404状态码 + 明确错误体
7. Swagger 是什么?
- 一句话:自动生成 API 文档的工具,能直接在线测试接口。
- 核心价值:
- 不用手动写文档 → 代码和文档同步更新。
- 前端可以直接在网页上测试接口 → 省去Postman调试时间。
- 相关概念:
- OpenAPI:一种描述API的规范标准(Swagger是它的实现工具)。
- Swagger UI:把API文档变成可视化网页。
- Swagger Editor:在线编写OpenAPI定义的编辑器。
Swagger 使用四步走
1. 安装配置(以Spring Boot为例)
- 步骤:
- 添加Maven依赖:
<dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter</artifactId><version>3.0.0</version> </dependency>- 添加配置类:
@Configuration @EnableSwagger2 public class SwaggerConfig {@Beanpublic Docket api() {return new Docket(DocumentationType.SWAGGER_2).select().apis(RequestHandlerSelectors.basePackage("com.example.controller")).paths(PathSelectors.any()).build().apiInfo(apiInfo());}private ApiInfo apiInfo() {return new ApiInfoBuilder().title("用户管理API文档").description("用户增删改查接口").version("1.0").build();} }
2. 代码中添加注解(关键!)
- 示例代码:
@RestController @RequestMapping("/users") @Api(tags = "用户管理") // 类级别描述 public class UserController {@GetMapping("/{id}")@ApiOperation("根据ID获取用户") // 接口描述@ApiImplicitParam(name = "id", value = "用户ID", required = true, paramType = "path")public User getUser(@PathVariable Long id) {// 业务代码}@PostMapping@ApiOperation("创建用户")public User createUser(@RequestBody @ApiParam("用户信息") User user) {// 业务代码} }
3. 访问Swagger UI
-
启动项目后,访问:
http://localhost:8080/swagger-ui.html -
你会看到一个这样的页面:
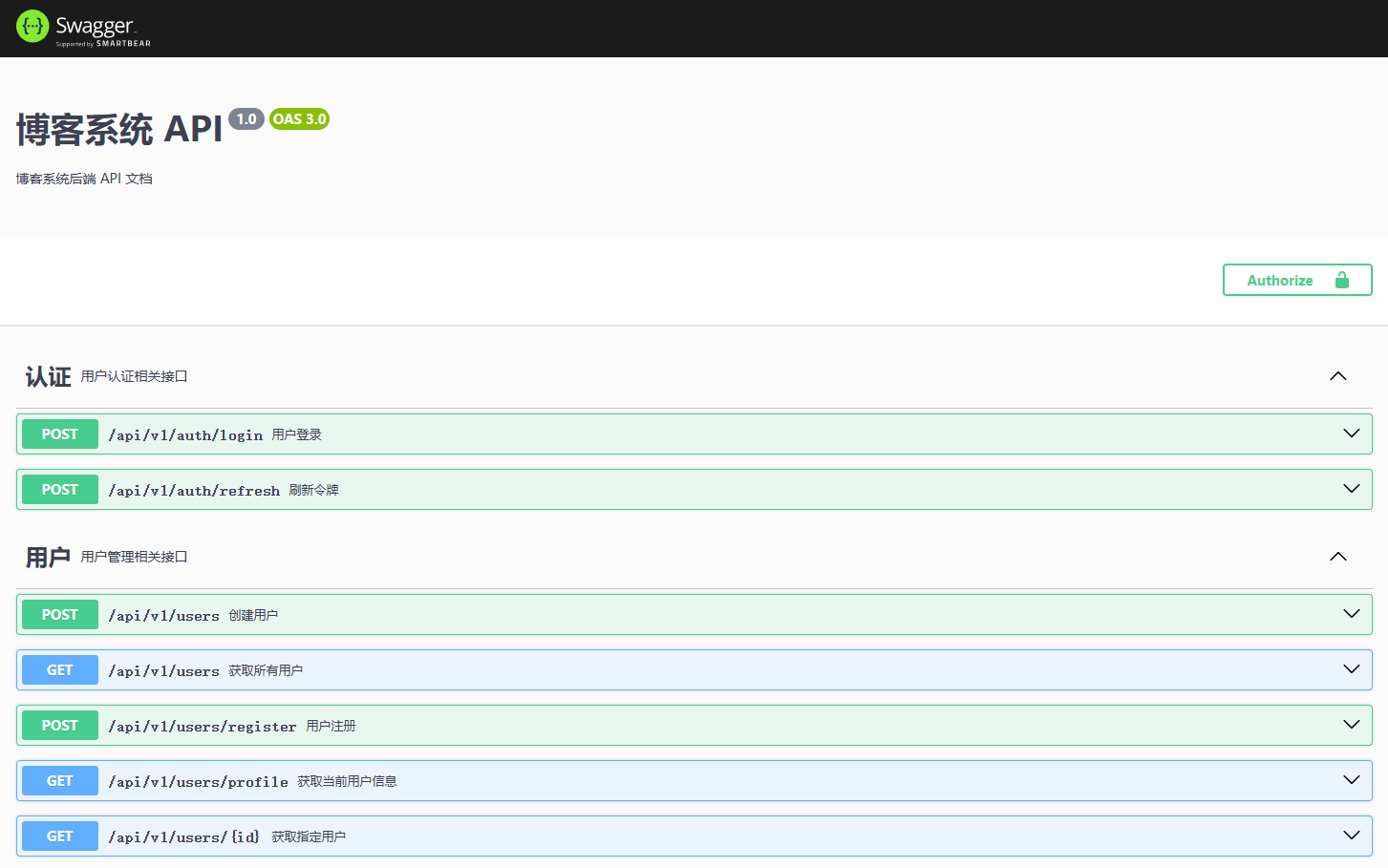
(实际界面包含所有API列表,可展开测试)
4. 在Swagger UI中测试接口
- 找到要测试的接口 → 点击“Try it out” → 输入参数 → 点击“Execute”发送请求。
- 优势:无需手动拼接URL或Header,自动生成请求格式。
Swagger 注解速查表
| 注解 | 作用 | 示例 |
|---|---|---|
@Api | 描述Controller类 | @Api(tags = "用户管理") |
@ApiOperation | 描述接口方法的功能 | @ApiOperation("创建用户") |
@ApiParam | 描述单个参数 | @ApiParam("用户年龄") int age |
@ApiModel | 描述数据模型(DTO/VO) | @ApiModel("用户信息") |
@ApiModelProperty | 描述模型字段 | @ApiModelProperty("用户名") |
高级技巧
1. 隐藏敏感接口
- 不想暴露某些接口给文档?
@ApiIgnore // 加上这个注解,Swagger会忽略该接口 @PostMapping("/secret") public void secretMethod() { ... }
2. 添加全局授权(JWT为例)
- 在Swagger配置类中添加:
.securityContexts(Arrays.asList(securityContext())) .securitySchemes(Arrays.asList(apiKey()));private SecurityContext securityContext() {return SecurityContext.builder().securityReferences(defaultAuth()).build(); }private List<SecurityReference> defaultAuth() {AuthorizationScope scope = new AuthorizationScope("global", "accessEverything");return Arrays.asList(new SecurityReference("JWT", new AuthorizationScope[]{scope})); }private ApiKey apiKey() {return new ApiKey("JWT", "Authorization", "header"); // 在Header中传Token } - 效果:Swagger UI 右上角会出现“Authorize”按钮,可输入Token。
最佳实践
- 及时更新注解:代码变了,Swagger注解也要跟着改!
- 详细描述参数:用
@ApiParam或@ApiModelProperty说明参数规则(如“长度至少6位”)。 - 结合代码注释:Swagger支持读取JavaDoc,保持注释和注解一致。
模块五:缓存机制与性能优化
1. 缓存是什么?为什么需要它?
- 核心作用:用更快的存储(如内存)暂存高频访问数据,减少对慢速存储(如数据库)的访问。
- 类比:就像你桌上的常用文件(缓存) vs 档案室的全部文件(数据库)。
2. 常见缓存位置
| 缓存层级 | 示例 | 速度 | 容量 |
|---|---|---|---|
| 客户端缓存 | 浏览器缓存 | 最快 | 最小 |
| CDN缓存 | 静态资源缓存 | 快 | 中 |
| 服务端缓存 | Redis/Memcached | 较快 | 大 |
| 数据库缓存 | MySQL查询缓存 | 慢 | 大 |
3. 缓存策略
3.1 缓存过期策略
- TTL(Time To Live):设置缓存有效期(如5分钟)。
3.2 缓存更新策略
- Cache Aside(旁路缓存):
- 读时先查缓存,未命中再查数据库并回填。
- 写时先更新数据库,再删除缓存。
4. 缓存穿透 vs 缓存击穿 vs 缓存雪崩
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 缓存穿透 | 查询不存在的数据(如id=-1) | 1. 布隆过滤器过滤非法请求 2. 缓存空值 |
| 缓存击穿 | 热点数据过期瞬间,大量请求打崩数据库 | 1. 互斥锁更新缓存 2. 永不过期+后台更新 |
| 缓存雪崩 | 大量缓存同时过期导致请求涌向数据库 | 1. 随机TTL 2. 集群高可用 |
5. 实战示例:Redis缓存用户信息
# 伪代码:用户查询接口
def get_user(user_id):# 1. 先查缓存user = redis.get(f"user:{user_id}")if user:return user# 2. 缓存未命中,查数据库user = db.query("SELECT * FROM users WHERE id = ?", user_id)if not user:return None# 3. 回填缓存,TTL 1小时redis.setex(f"user:{user_id}", 3600, user)return user
缓存策略流程图
模块六:消息队列与异步处理
1. 为什么需要消息队列?
- 核心作用:解耦系统、异步处理、流量削峰。
- 类比:像快递柜,发送方(生产者)投递包裹,接收方(消费者)按需取件,双方无需同时在线。
2. 常见消息队列系统
| 系统 | 特点 | 适用场景 |
|---|---|---|
| RabbitMQ | 支持复杂路由,AMQP协议 | 订单处理、任务分发 |
| Kafka | 高吞吐量,持久化,分布式流处理 | 日志收集、实时数据分析 |
| Redis Stream | 轻量级,基于内存 | 简单消息队列,延迟队列 |
3. 消息队列核心概念
- 生产者(Producer):发送消息的程序。
- 消费者(Consumer):接收并处理消息的程序。
- 队列(Queue):消息的存储载体(先进先出)。
- 交换机(Exchange):决定消息路由到哪个队列(RabbitMQ特有)。
4. 消息队列工作模式
4.1 点对点模式(一对一)
# 竞争消费,一条消息只能被一个消费者处理
4.2 发布/订阅模式(一对多)
# 每个队列独立消费,消息被复制多份
5. 实战场景:订单超时取消
传统同步方式的问题:
# 问题:长时间阻塞线程,浪费资源!
消息队列优化方案:
6. 消息可靠性保证
- 生产者确认:确保消息成功到达队列。
- 持久化存储:消息写入磁盘,防止服务器重启丢失。
- 消费者ACK机制:处理完成后再确认消费,避免消息丢失。
7. 代码示例(Python + RabbitMQ)
# 生产者发送消息
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='order_queue')
channel.basic_publish(exchange='', routing_key='order_queue', body='订单ID:1001')
connection.close()# 消费者处理消息
def callback(ch, method, properties, body):print("收到订单:", body.decode())# 处理业务逻辑...ch.basic_ack(delivery_tag=method.delivery_tag) # 手动ACKchannel.basic_consume(queue='order_queue', on_message_callback=callback)
channel.start_consuming()
关键决策点:什么时候用消息队列?
- 解耦系统:A系统发通知,B/C系统异步处理,互不影响。
- 异步处理:耗时操作(如发邮件、生成报表)后台执行。
- 流量削峰:突发流量先堆积到队列,消费者逐步处理。
- 顺序保证:确保操作按顺序执行(如日志同步)。
模块七:微服务架构基础
1. 什么是微服务?
- 一句话:把一个大系统拆成多个独立的小服务,每个服务专注一件事。
- 类比:像餐厅分工——厨师管做菜,收银员管结账,清洁工管打扫,各司其职互不干扰。
2. 微服务 vs 单体架构
| 对比维度 | 单体架构 | 微服务架构 |
|---|---|---|
| 代码结构 | 所有功能在一个代码库 | 每个服务独立代码库 |
| 数据库 | 共享一个数据库 | 每个服务有自己的数据库 |
| 部署 | 整体部署(牵一发动全身) | 独立部署(只更新受影响的服务) |
| 团队协作 | 需高度协调 | 团队自治(小团队负责1-2服务) |
3. 微服务核心组件
3.1 服务注册与发现
- 问题:服务A如何找到服务B的地址?
- 解决方案:服务启动时向注册中心报到,其他服务查询注册中心。
3.2 API网关
- 作用:统一入口(门卫),处理鉴权、限流、路由。
4. 服务间通信
- 方式1:HTTP/REST
# 订单服务调用支付服务(伪代码) requests.post("http://payment-service/api/payments", json=order_data) - 方式2:RPC(如gRPC)
// 定义接口(payment.proto) service PaymentService {rpc CreatePayment (PaymentRequest) returns (PaymentResponse); }
5. 实战场景:电商下单
6. 微服务的代价(不是银弹!)
- 优点:
- 灵活扩展(只扩容热门服务)
- 技术栈自由(不同服务可用不同语言)
- 故障隔离(一个服务挂了不影响其他)
- 缺点:
- 运维复杂度高(需管理多个服务)
- 分布式事务难题(如订单+库存+支付的一致性)
- 网络延迟(服务间调用变慢)
7. 什么时候该用微服务?
- 适合场景:
- 大型团队协作(>50人)
- 系统模块边界清晰
- 需要快速迭代部分功能
- 不适合场景:
- 初创小系统(过度设计)
- 模块耦合严重(拆分困难)












