

一、概念
1、Hive
Apache Hive 是一个分布式的容错数据仓库系统,可实现大规模分析和便于使用 SQL 读取、写入和管理驻留在分布式存储中的PB级数据。
Hive是建立在Hadoop之上的数据仓库框架,它提供了一种类SQL的查询语言—HiveQL,使得熟悉SQL的用户能够在Hadoop上进行数据查询和分析。
2、Hive Metastore

Hive Metastore(HMS)是Apache Hive的一个组件,它提供了一个中央存储库,用于存储有关Hive表和分区的元数据。这些元数据包括表的结构信息、数据类型、列和表之间的关系以及数据存储的位置等信息。Hive Metastore是许多数据湖架构的关键组成部分,因为它允许客户端(包括Hive、Impala和Spark)使用metastore服务API访问这些信息。
Hive Metastore的架构相对简单,通常包括一个关系型数据库(如MySQL、Postgres或Derby)来存储元数据,以及一个Thrift服务,允许客户端通过网络访问这些元数据。尽管它的名字中包含“Hive”,但实际上Hive Metastore与Hive是独立的,可以与其他系统(如Apache Spark和Presto)一起使用。
二、原理

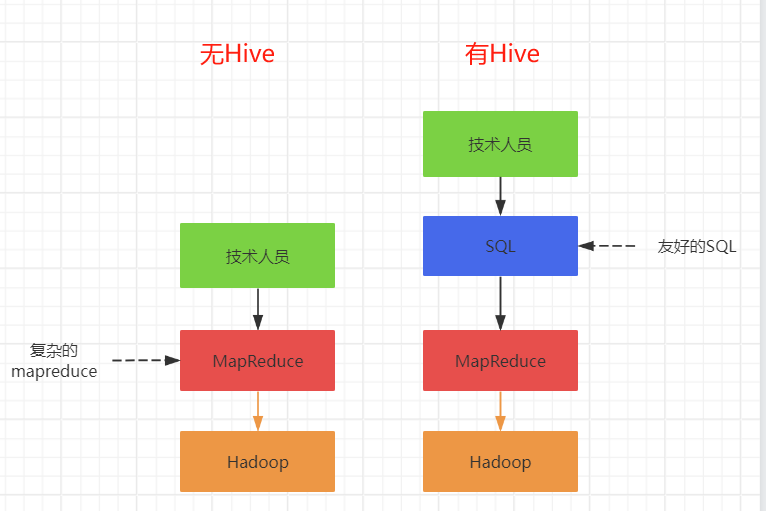
Hive是一个建立在Hadoop之上的数据仓库工具,它将SQL查询转换成MapReduce任务来执行。这是因为Hive的设计目的是让熟悉SQL的用户能够在Hadoop平台上进行数据分析,而不需要直接编写复杂的MapReduce代码。Hive的工作原理与MapReduce的关系可以概括为以下几点:
- 查询转换:当用户在Hive中执行一个查询时,Hive将这个查询转换成一个或多个MapReduce任务。
- 执行计划:Hive的编译器将SQL语句转换成一个执行计划,这个计划描述了如何将查询分解成MapReduce的Map和Reduce阶段。
- 任务执行:Hive将这些MapReduce任务提交给Hadoop集群执行。Map阶段处理输入数据,生成中间结果;Reduce阶段则对这些中间结果进行汇总和处理,以产生最终结果。
- 结果返回:一旦MapReduce任务完成,Hive将处理结果返回给用户。
这种设计使得Hive能够利用Hadoop的分布式计算能力来处理大规模数据集,同时为用户提供了一个更为熟悉和易于使用的SQL接口。然而,这也意味着Hive的查询性能受限于MapReduce的性能,因此在需要快速响应的场景下可能不是最佳选择。
三、优缺点
Hive的优缺点如下:
优点:
- 易于使用:提供类SQL查询语言,减少学习成本。
- 海量数据分析:底层基于MapReduce,适合处理大规模数据集。
- 可扩展性:可以自由扩展集群规模,具有良好的容错性。
- 自定义函数:支持用户根据需求实现自定义函数。
缺点:
- 效率问题:Hive生成的MapReduce作业通常不够智能化,执行延迟较高。
- 表达能力限制:HiveQL的表达能力有限,不擅长迭代式算法和数据挖掘。
- 不支持实时查询:由于MapReduce任务启动需要时间,Hive不适合实时数据查询。












