
Meta 的这篇多标记预测论文显示,与当前的下一标记预测器相比,多头预测器内存效率高、性能更好、训练速度更快。
https://arxiv.org/pdf/2404.19737
主要收获:
- 多标记预测是对 LLM 训练的一种简单而强大的修改,可提高样本效率和各种任务的性能。
- 这种方法在大规模应用中尤为有效,大型模型在 MBPP 和 HumanEval 等编码基准测试中表现出显著优势。
- 多标记预测可通过自指定解码加快推理速度,与下一个标记预测相比,速度可能提高 3 倍。
- 该技术促进了全局模式的学习,提高了 LLM 的算法推理能力。
- 虽然该技术对生成任务很有效,但在基于多选题的基准测试中,论文发现结果好坏参半。
FAIR(Facebook 人工智能研究团队)的研究人员撰写了这篇论文,结果看起来很有希望。我很希望这篇论文能成为实际产品。我认为这篇论文具备了成为像《专家混合物》(Mixture of Experts)那样的开创性论文的所有要素,而《专家混合物》已被证明是当前一代模型的开创性论文。
导言:
论文首先强调了目前基于下一个标记预测的 LLM 训练方法的局限性。尽管这些模型的能力令人印象深刻,但与人类相比,它们需要大量数据才能达到类似的流畅度。作者认为,next-token 预测过于关注局部模式,忽略了 "困难 "决策,导致学习效率低下。他们提出了多标记词预测作为克服这些局限性的解决方案。
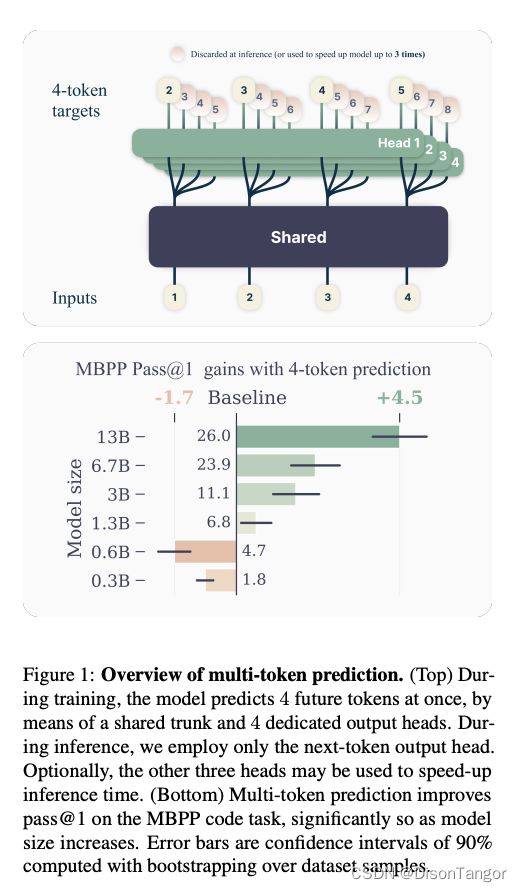
背景:
传统的语言模型使用下一个标记预测损失进行训练,即模型根据前面的上下文预测序列中的下一个标记。本文提出了一种更通用的方法,即模型使用连接到共享模型主干的 n 个独立输出头同时预测 n 个未来标记。这就迫使模型考虑文本中的长期依赖关系和全局模式。












