目录
- 代码
- 代码解释
- netron可视化
代码
from torch import nn
import torch
import torch.nn.functional as Fclass FeedForward(nn.Module):def __init__(self, dim: int, hidden_dim: int = None, dropout: float = 0.0, multiple_of: int = 64):super().__init__()if hidden_dim is None:# 计算隐藏层维度hidden_dim = 4 * dimhidden_dim = int(2 * hidden_dim / 3)hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)self.w1 = nn.Linear(dim, hidden_dim, bias=False)self.w2 = nn.Linear(hidden_dim, dim, bias=False)self.w3 = nn.Linear(dim, hidden_dim, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
代码解释
详细解释这段代码的实现:
- 导入必要的库:
from torch import nn
import torch
import torch.nn.functional as F
nn: PyTorch 的神经网络模块F: 提供激活函数等功能性操作
- FeedForward 类的定义:
class FeedForward(nn.Module):
这是一个前馈神经网络模块,实现了 LLaMA 中使用的 SwiGLU 变体。
- 隐藏层维度计算逻辑:
if hidden_dim is None:hidden_dim = 4 * dim # 首先扩展到4倍hidden_dim = int(2 * hidden_dim / 3) # 然后取2/3hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of) # 确保是multiple_of的倍数
这是 LLaMA 论文中的计算方式,确保隐藏层维度满足特定要求。
- 网络结构定义:
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
self.dropout = nn.Dropout(dropout)
w1,w3: 将输入从 dim 维映射到 hidden_dim 维w2: 将结果映射回 dim 维- 所有线性层都不使用偏置项
- 前向传播:
def forward(self, x):return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
- 使用 SiLU(也称为 Swish)激活函数
- 实现了门控机制:
F.silu(self.w1(x)) * self.w3(x) - 最后应用 dropout 进行正则化
这种设计在现代语言模型中很常见,能提供更好的性能和训练稳定性。
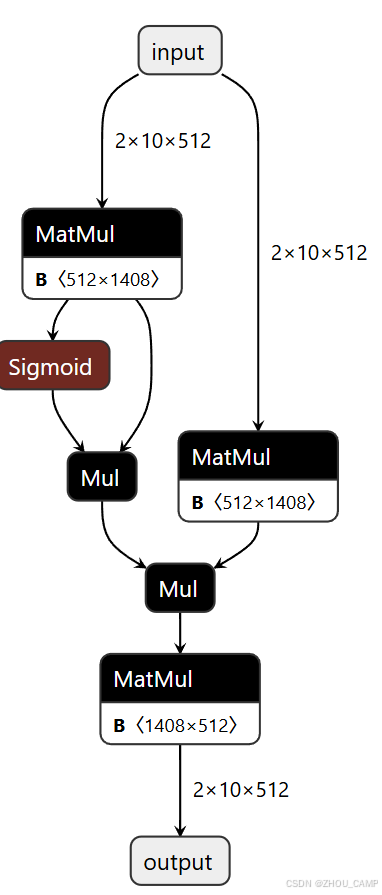
netron可视化
ffn = FeedForward(dim=512, # 输入维度hidden_dim=None, # 让模型自动计算隐藏维度dropout=0.1, # dropout率multiple_of=64 # 确保隐藏维度是64的倍数
)
# 实例化 FeedForward 模块
ffn.eval() # 设置为评估模式# 创建示例输入
batch_size = 2
seq_len = 10
x = torch.randn(batch_size, seq_len, 512)# 导出为ONNX格式
torch.onnx.export(ffn, # 要导出的模型x, # 模型输入"ffn.onnx", # 输出文件名input_names=['input'], # 输入名称output_names=['output'], # 输出名称opset_version=17
)