
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

Pandas中基本的数据结构有Series和DataFrame,它们都带标签索引的对象,而索引本身也是一种对象。在数据分析中经常需要通过索引对数据进行操作。索引类似我们图书的目标,通过索引能够大大提高操作数据的效率。
认识索引
前面我们读取csv文件,返回的是DataFrame。默认就给我们生成了行索引和列名(列索引)。
# 导入pandas库,去别名pd
import pandas as pddf = pd.read_csv('student_scores.csv')print(df.index, type(df.index))
print(df.columns, type(df.columns))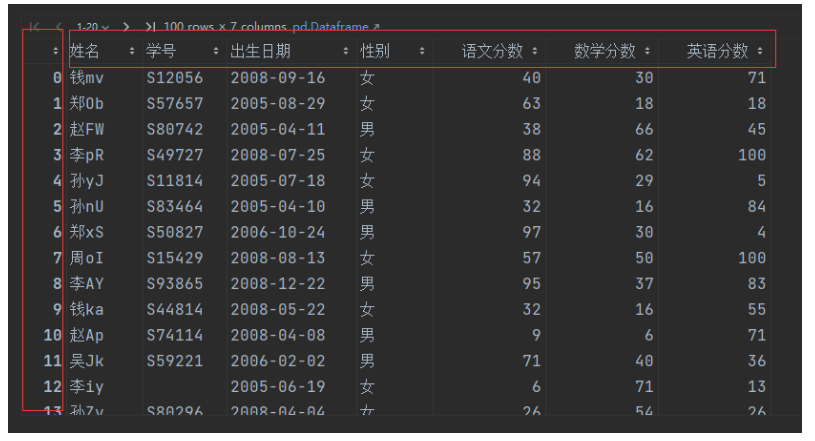
运行输出:
RangeIndex(start=0, stop=100, step=1) <class 'pandas.core.indexes.range.RangeIndex'>
Index(['姓名', '学号', '出生日期', '性别', '语文分数', '数学分数', '英语分数'], dtype='object') <class 'pandas.core.indexes.base.Index'>行索引默认类型 pandas.core.indexes.range.RangeIndex,类索引默认类型 pandas.core.indexes.base.Index
新建索引
新建索引的方式有默认创建,显示创建,指定列创建
默认创建前面也介绍过,我们给个示例:
import pandas as pdimport numpy as npdf = pd.DataFrame(np.arange(1, 16).reshape(5, 3))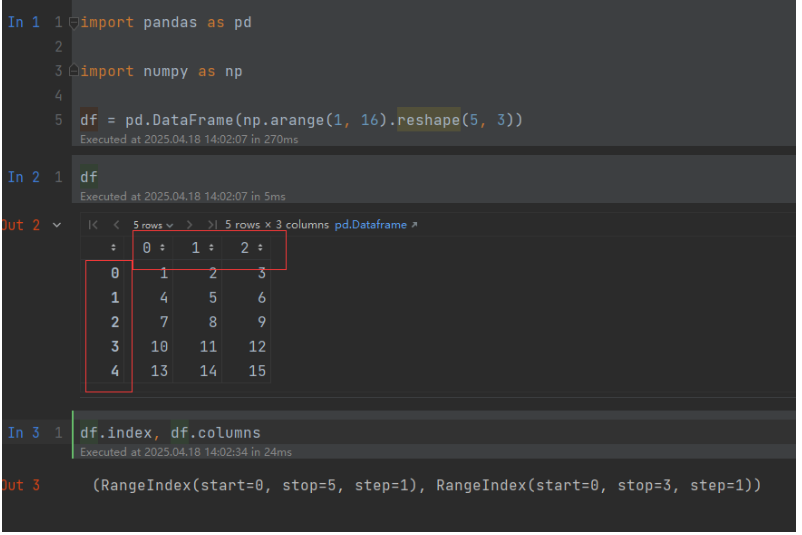
默认索引对象是RangeIndex类型。
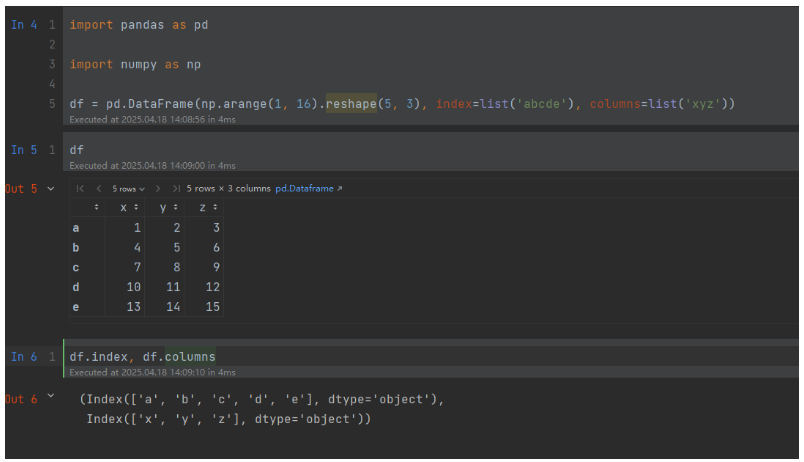
显示创建,我们通过index,columns属性指定索引
参考示例:
import pandas as pdimport numpy as npdf = pd.DataFrame(np.arange(1, 16).reshape(5, 3), index=list('abcde'), columns=list('xyz'))运行结果:
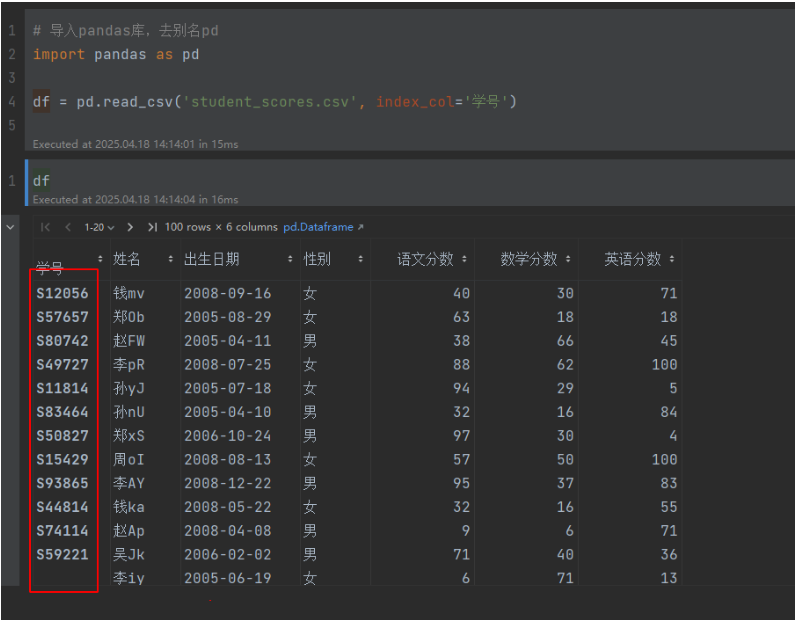
指定列创建,通过index_col属性,或者调用dataframe的set_index()方法指定
import pandas as pddf = pd.read_csv('student_scores.csv', index_col='学号')运行结果:
通过调用dataframe对象的set_index()方法指定:
import pandas as pddf = pd.read_csv('student_scores.csv')
df.set_index('姓名')
索引类型
Pandas中的索引是数据操作的核心组件,用于高效访问和操作数据。以下是主要的索引类型及其特点:
-
Index
-
基础索引:所有索引类型的基类,可存储任意数据类型(整数、字符串等)。
-
通用性:适用于行或列标签,支持基本查询和标签对齐操作。
-
不可变性:创建后不能直接修改,需生成新索引。
-
RangeIndex
-
优化连续整数:默认生成的索引(如
0,1,2...),内存效率高,类似Python的range。 -
动态生成:无需预存所有值,适合大数据集。
-
DatetimeIndex
-
时间序列专用:存储日期时间,支持时间切片、重采样(如按周聚合)、时区转换等。
-
创建方式:通过日期范围生成,常用于金融或日志数据。
-
PeriodIndex
-
固定时间段表示:如“2023年1月”,支持按周期(月、年)计算。
-
应用场景:统计季度销售额等周期性分析。
-
TimedeltaIndex
-
时间间隔:表示持续时间(如“5天”),用于时间算术运算。
-
示例用途:计算事件之间的时间差。
-
CategoricalIndex
-
分类数据优化:存储有限类别的数据(如性别“男/女”),节省内存并提升性能。
-
有序支持:可定义类别顺序,适用于排序和分组。
-
MultiIndex(分层索引)
-
多维索引:允许多层索引(如“国家-城市-日期”),支持复杂数据查询。
-
操作灵活:可按层次聚合、透视数据,常见于面板数据或高维分析。
-
IntervalIndex
-
数值区间管理:存储区间范围(如年龄分段“18-25”),便于区间查询和数学运算。
-
左闭右开:默认区间为
[left, right),支持重叠或非重叠区间。
-
其他数值索引(历史版本)
-
Int64Index/Float64Index/UInt64Index:旧版本中专用于特定数值类型的索引,新版本中统一为
Index,自动识别数据类型。
-
Boolean索引(注意区分)
-
非独立索引类型:布尔选择通常通过条件过滤实现(如
df[df['列'] > 5]),而非独立的索引对象。
关键特性与注意事项:
-
不可变性:所有索引对象创建后不可原地修改,需用
set_index或reset_index生成新索引。 -
版本兼容性:Pandas新版本(如≥1.0)逐步统一索引类型,旧类型(如
Int64Index)可能被弃用。 -
性能优化:如
RangeIndex和CategoricalIndex通过特定设计提升内存效率和计算速度。
索引对象及其属性
在Pandas中,索引对象(如Index、DatetimeIndex、MultiIndex等)提供了一系列常用属性,用于查看或操作索引的元信息。以下是核心属性的分类整理:
一、通用属性(适用于所有索引类型)
-
name
-
作用:索引的名称(如列名或行索引名)。
-
示例:
df.index.name = "日期"(设置行索引名)或df.columns.name = "字段"(设置列索引名)。
-
-
values
-
作用:返回索引的底层数据(NumPy数组格式)。
-
注意:直接访问值,不包含元信息(如时区)。
-
-
dtype / dtype_str
-
作用:索引的数据类型(如
int64、datetime64[ns])及其字符串表示。
-
-
shape
-
作用:索引的维度形状(如
(100,)表示100个元素)。
-
-
size
-
作用:索引的元素数量(等价于
len(index))。
-
-
is_unique
-
作用:布尔值,检查索引值是否唯一(无重复)。
-
-
is_monotonic / is_monotonic_increasing / is_monotonic_decreasing
-
作用:检查索引是否单调递增/递减(常用于排序优化)。
-
-
has_duplicates
-
作用:布尔值,检查索引是否存在重复值。
-
二、特定索引类型的扩展属性
1. DatetimeIndex / PeriodIndex / TimedeltaIndex
-
year, month, day, hour, minute, second
-
作用:提取日期时间成分(如
df.index.year获取年份)。
-
-
tz
-
作用:时区信息(需索引包含时区时有效)。
-
-
freq
-
作用:时间频率(如
D表示天,M表示月)。
-
2. CategoricalIndex
-
categories
-
作用:返回分类的类别列表(如
['A', 'B', 'C'])。
-
-
ordered
-
作用:布尔值,检查类别是否有序。
-
3. MultiIndex(分层索引)
-
levels
-
作用:返回各层级的唯一值列表(如国家、城市层级)。
-
-
codes
-
作用:各层级中元素对应的整数编码(映射到
levels)。
-
-
nlevels
-
作用:层级的数量(如3层索引返回
3)。
-
4. IntervalIndex
-
left / right
-
作用:返回区间左端点和右端点的值。
-
-
closed
-
作用:区间闭合方式(
left、right、both、neither)。
-
三、常用方法(非属性但相关)
-
to_list()
-
作用:将索引转换为Python列表。
-
-
astype(dtype)
-
作用:转换索引的数据类型(如字符串转整数)。
-
-
rename(name)
-
作用:修改索引名称(生成新索引对象)。
-
-
unique()
-
作用:返回唯一值数组(类似
np.unique)。
-
四、注意事项
-
不可变性:直接修改索引属性会报错,需通过方法生成新索引(如
set_index()或rename())。 -
兼容性:旧版本中某些属性(如
Int64Index)已合并到通用Index。 -
性能:频繁操作索引时,优先使用内置方法而非手动循环。
掌握这些属性能快速获取索引信息,并为数据清洗、分析和可视化提供关键支持。
下面是一个示例:
import pandas as pddf = pd.read_csv('student_scores.csv', index_col='学号')print('索引对象', df.index)
print('索引名称', df.index.name)
print('索引array数组', df.index.array)
print('索引数据类型', df.index.dtype)
print('索引形状', df.index.shape)
print('索引元素长度', df.index.size)运行输出:
索引对象 Index(['S12056', 'S57657', 'S80742', 'S49727', 'S11814', 'S83464', 'S50827','S15429', 'S93865', 'S44814', 'S74114', 'S59221', ' ', 'S80296','S68914', 'S33674', 'X', 'S96364', 'S38987', 'S35879', 'S60450','S50755', 'S44096', 'S99169', 'S82374', 'S98890', 'S24822', 'S35444','S64495', 'S12225', 'S49641', 'S93576', 'S77065', 'S76379', 'S86767','S86145', 'S42055', 'S10907', 'S89270', 'S22801', 'S89847', 'S38197','S12757', 'S63039', 'S47239', 'S75504', 'S25549', 'S10545', 'S12661','S27069', 'S97479', 'S29521', 'S60079', 'S90673', 'S65240', 'S40357','S10536', 'S48575', 'S64026', 'S41416', 'S36742', 'S54164', 'S24242','S99992', 'S64588', 'S26960', 'S20638', 'S50770', 'S46379', 'S52465','S67777', 'S99375', 'S83641', 'S49892', 'S42862', 'S86192', 'S96823','S96457', 'S12141', 'S28960', 'S79904', 'S12923', 'S97172', 'S31142','S98692', 'S19497', 'S14760', 'S71776', 'S30359', 'S40891', 'S51679','S75036', 'S44247', 'S99850', 'S83326', 'S35518', 'S13068', 'S74646','S86947', 'S45564'],dtype='object', name='学号')
索引名称 学号
索引array数组 <NumpyExtensionArray>
['S12056', 'S57657', 'S80742', 'S49727', 'S11814', 'S83464', 'S50827','S15429', 'S93865', 'S44814', 'S74114', 'S59221', ' ', 'S80296','S68914', 'S33674', 'X', 'S96364', 'S38987', 'S35879', 'S60450','S50755', 'S44096', 'S99169', 'S82374', 'S98890', 'S24822', 'S35444','S64495', 'S12225', 'S49641', 'S93576', 'S77065', 'S76379', 'S86767','S86145', 'S42055', 'S10907', 'S89270', 'S22801', 'S89847', 'S38197','S12757', 'S63039', 'S47239', 'S75504', 'S25549', 'S10545', 'S12661','S27069', 'S97479', 'S29521', 'S60079', 'S90673', 'S65240', 'S40357','S10536', 'S48575', 'S64026', 'S41416', 'S36742', 'S54164', 'S24242','S99992', 'S64588', 'S26960', 'S20638', 'S50770', 'S46379', 'S52465','S67777', 'S99375', 'S83641', 'S49892', 'S42862', 'S86192', 'S96823','S96457', 'S12141', 'S28960', 'S79904', 'S12923', 'S97172', 'S31142','S98692', 'S19497', 'S14760', 'S71776', 'S30359', 'S40891', 'S51679','S75036', 'S44247', 'S99850', 'S83326', 'S35518', 'S13068', 'S74646','S86947', 'S45564']
Length: 100, dtype: object
索引数据类型 object
索引形状 (100,)
索引元素长度 100重置索引
如果我们想取消已有的索引,我们可是调用dataframe的reset_index()方法来操作。
参考示例:
import pandas as pddf = pd.read_csv('student_scores.csv', index_col='学号') # 指定索引
df.reset_index() # 重置索引运行输出:
其他索引操作方法
在Pandas中,索引操作是数据处理的核心,以下是常用的索引操作方法,按功能分类整理:
一、基础索引操作
-
set_index()
-
功能:将指定列转换为索引(支持单列或多列),常用于行索引的重定义。
-
参数:
keys(列名)、drop(是否删除原列)、append(是否保留原索引)。
-
-
reset_index()
-
功能:将索引还原为普通列,并生成默认整数索引,常用于数据扁平化。
-
参数:
level(指定要还原的索引层级)、drop(是否丢弃原索引)。
-
-
reindex()
-
功能:根据新索引标签调整数据,填充缺失值或删除多余值。
-
参数:
index(新索引)、method(填充方式,如向前填充ffill)、fill_value(自定义填充值)。
-
-
rename() / rename_axis()
-
功能:
-
rename():修改索引标签(行或列)。 -
rename_axis():修改索引名称(如行索引或列索引的名称)。
-
-
参数:支持字典或函数映射。
-
-
sort_index()
-
功能:按索引标签排序(行或列),默认升序。
-
参数:
axis(按行或列排序)、ascending(排序方向)、inplace(是否原地修改)。
-
二、层级索引(MultiIndex)操作
-
stack() / unstack()
-
功能:
-
stack():将列层级转换为行索引(“宽表”变“长表”)。 -
unstack():将行索引层级转换为列(“长表”变“宽表”)。
-
-
参数:
level(指定操作的层级)。
-
-
swaplevel()
-
功能:交换索引层级的顺序(如将第0层与第1层互换)。
-
参数:
i和j(指定交换的层级位置)。
-
-
droplevel()
-
功能:删除指定的索引层级。
-
参数:
level(层级名称或位置)。
-
-
set_levels() / set_codes()
-
功能:
-
set_levels():修改某一层级的唯一值(如替换国家名称)。 -
set_codes():修改层级编码(映射到新值)。
-
-
三、时间索引操作
-
asfreq()
-
功能:按指定频率重新采样时间索引,生成等间隔时间点(如日频转月频)。
-
参数:
freq(目标频率)、method(填充方式)。
-
-
to_period() / to_timestamp()
-
功能:
-
to_period():将时间戳索引转换为周期索引(如“2023-01-01”转为“2023年1月”)。 -
to_timestamp():将周期索引转换回时间戳。
-
-
-
shift()
-
功能:将索引标签整体平移(如时间序列滞后一期)。
-
参数:
periods(平移步数)、freq(按时间频率平移)。
-
四、索引查询与过滤
-
drop()
-
功能:删除指定的索引标签(行或列)。
-
参数:
labels(要删除的标签)、level(针对层级索引)。
-
-
loc[] / iloc[]
-
功能:
-
loc[]:按标签选择数据(支持布尔条件)。 -
iloc[]:按位置选择数据(整数索引)。
-
-
-
isin()
-
功能:筛选索引标签是否在指定列表中,返回布尔数组。
-
参数:
values(目标值列表)。
-
-
where() / mask()
-
功能:
-
where():保留满足条件的值,不满足的替换为默认值。 -
mask():与where()相反,替换不满足条件的值。
-
-
五、索引类型转换
-
astype()
-
功能:转换索引数据类型(如字符串转整数)。
-
参数:
dtype(目标类型)。
-
-
to_numpy()
-
功能:将索引转换为NumPy数组,便于与其他库交互。
-
六、其他实用方法
-
duplicated()
-
功能:检查索引标签是否重复,返回布尔数组。
-
参数:
keep(标记重复值的策略,如保留第一个或最后一个)。
-
-
unique()
-
功能:返回索引的唯一值数组(去重后)。
-
-
str访问器(字符串索引)
-
功能:对字符串类型的索引执行文本操作(如切片、正则匹配)。
-
示例方法:
contains(),startswith(),upper()。
-
注意事项
-
不可变性:索引对象不可原地修改,操作后需重新赋值(如
df.index = df.index.rename())。 -
性能优化:使用
sort_index()可加速后续查询;层级索引操作可能增加计算复杂度。 -
层级顺序:MultiIndex的层级顺序影响
stack()/unstack()的结果。 -
时间索引:确保时间索引频率一致(
freq属性),避免重采样时出错。
掌握这些方法可以高效管理索引,适应数据重塑、时间序列分析、多维数据查询等场景。












