
机器学习的常规流程

在真正进入机器学习算法之前,数据准备和处理过程会尤为重要,这直接关系到后续模型的效果和最终的业务判决。
数据分析
什么是数据分析
数据分析指对原始数据进行检查、清理、转换及筛选等一系列动作,找到数据对结果的影响关系。
怎么数据分析
数据分析的三板斧:数据对比、数据细分和数据溯源。
- 数据对比:对比是能够看到数据自身以及和其它变量的关系。比如,电商场景中上个月和这个月的用户数量变化,GMV变化;
- 数据细分:系分是指对数据增加维度、降低粒度,便于更好的对比。比如客群,会分为男性、女性,性别下又会有年龄的划分,年龄后还会有职业等等;
- 数据溯源:分析的数据有可能是二手的,得到的信息片面、阉割,所以需要找到一手原始数据,真实反应业务情况。当然,另一种可能是数据本身采集指标不合理,所以需要找到源头;
数据分析的维度

描述性统计指标
- 集中趋势看平均值、中位数和众数
- 离散程度看极差、方差、标准差、离散系数;(极差:样本最大值和最小值的间距; 方差:度量数据离散程度;标准差:反应数据在均值附近的波动;离散系数:标注差和均值的比例)
- 分布形态:正态分布、高斯分布、峰度等;通常,数据处于正态分布情况下,训练越容易收敛,所以会看到数据的归一化处理;
交叉维度
- 相关系数:反应两个变量的相关性;
- 线性回归:回归分析两种或两种以上变量的相互依赖;有一元线性回归和多元线性回归。
概率分布
- 连续性变量正态分布
- 离散性变量伯努利分布、泊松分布
数据分析抽样方式
如果原始的数据量很大,需要对数据进行抽样分析,用局部替代整体的分布情况,加快数据搜索。抽样方式有:
- 随机抽样
- 分层抽样
- 群体抽样
- 系统抽样
数据分析与业务关系
数据分析的前提是要了解业务,知道业务目标,分析不是漫无目的的看数据。比如,要分析电商GMV的影响,得知道GMV是什么,影响的因素有哪些,有什么样的影响关系。这里不做过多赘述。
业务分析模型
- ABTest 最常用的线上业务对比方法;
- RFM分析:衡量客户价值和客户创利能力的重要工具和手段。通过细分Recently最近一次消费、Frequency消费频率和Monetary消费金额。
- AARRR漏洞分析法,描述产品生命周期中用户的参与行为深度
- 同期群分析,分析性质完全一样的、可对比群体随时间的变化
- 对比分析,环比、同比、标准对比等
数据异常值分析
Python提供了数据形状描绘的工具,可以通过工具快速看到数据的分布。如用seaborn的测试数据titanic.csv,可以得到整体的分布图:
raw = pd.read_csv('dataset/titanic.csv')
sns.set(style="whitegrid")
df_melted = pd.melt(raw, value_vars=raw.columns)
g = sns.FacetGrid(df_melted, col="variable", col_wrap=4, sharex=False, sharey=False)
g.map(sns.histplot, "value")
g.set_titles(col_template="{col_name}") # 添加标题和调整布局
g.tight_layout() # 保持布局紧凑
plt.show()
异常值监测和分析
异常值分析是检验数据中是否有不合理的数据。注意:数据异常值不一定是错误值。常用的异常值分析办法有:
-
描述统计性分析
如上所述,常见的有min/max/avg/mid等,明显不合理的数据清除或填充处理
2. Z-Score分析(描述与平均值的距离是标准差的多少倍)
在正态分布下,距离平均值 3之外的值出现的概率为 P(|x-μ|>3σ)<=0.003,属于极个别的小概率事件。如果观测值与平均值的差值超过3倍标准差,那么可以将其视为异常值。
如测试数据中,票价fare的分析,存在异常点
from scipy.stats import zscore z_scores = zscore(df['fare'])

3. 箱线图 IQR异常监测(连续变量)
四分位点内距(Inter-Quartile Range,IQR),是指在第75个百分点与第25个百分点的差值,或者说,上四分位数与下四分位数之间的差。通常把小于Q1-1.5*IQR和Q3+1.5*IQR的数据视为离群点;

4. 基于密度
考察当前点周围密度,局部异常点/离群点的局部密度显著低于大部分近邻点。这类方法适用于非均匀的数据集。
缺点:基于邻近度的算法时间复杂度是O(n^2),大数据集不适用
基于聚类、基于距离等都各有优点,但时间复杂度不使用大数据集
异常值处理
异常值处理有3中模式:删除异常值数据、插补替换异常值和不处理,将异常值视为特殊的类别;
数据缺失值分析处理
查找数据中的缺失值:
data.isnull().sum()
缺失值的分析处理流程:
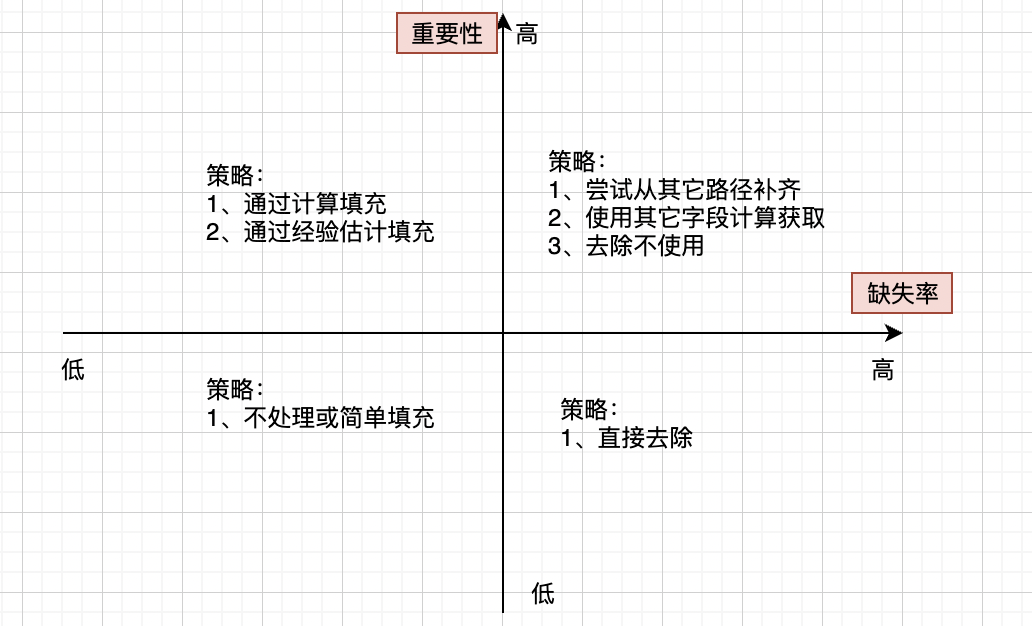
- 删除数据行:如果缺失值较少,可以考虑删除对应的行数据. df采用
dt.dropna(axis=0, how='any', subset=['embarked'], inplace=True)s
- 数值填充:包含特殊值填充,统计量(中位数、众数、平均值)填充。缺失值较少一般用众数填充,缺失值较多用中位数
dt['embark_town'] = dt['embark_town'].fillna(dt['embark_town'].mode()[0])
- 同类均值填充。先进行分组,落在同一个组内的数据,然后再用这个组的均值填充。
# 找到要填充的分组均值,并且得到index age_group_mean = dt.groupby(['pclass', 'sex','who'])['age'].mean().reset_index()# 定义筛选函数
def select_group_age_mean(row):condition = ((row['sex'] == age_group_mean['sex']) & (row['pclass'] == age_group_mean['pclass'])& (row['who'] == age_group_mean['who']))# 输出的是每一个列名对应的筛选return age_group_mean[condition]['age'].values[0]# 数据应用函数
dt['age'] = dt.apply(lambda x: select_group_age_mean(x) if np.isnan(x['age']) else x['age'], axis=1)
- 模型预测值填充:将填充字段视为label,没有缺失的数据作为训练数据,建立分类/回归模型,对缺失值填充。
import pandas as pd
import numpy as npdata = pd.read_csv('titanic.csv')
# 选取特征
df_age = dt[['age', 'pclass', 'sex', 'who','fare', 'parch', 'sibsp']]
# 离散类别 哑变量
df_age = pd.get_dummies(df_age)# 进行数据筛选
known_age = df_age[df_age.age.notnull()]
unknown_age = df_age[df_age.age.isnull()]# 确定y label
y_label = known_age['age']
train_data = known_age.drop(['age'], axis=1)
test_data = unknown_age.drop(['age'], axis=1)# 采用随机森林算法计算缺失值y
from sklearn.ensemble import RandomForestRegressor
# n_jobs =-1,表示不限制CPU数量
model = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
# 进行预测
model.fit(train_data, y_label)
y_pred = model.predict(test_data)# 使用得到的预测结果填补原来的值
dt.loc[dt.age.isnull(),'age'] = y_pred- 插值法填充
dt['fare'].interpolate(method='linear', axis=0)












