
前面的博客,我们讲解了应用层协议的编写,在我们需要个性化自己的服务器通信规则时需要自己来编写;但是在网络编程中有现成的应用层协议,这是先辈们已经创建好了,使用至今的协议——http协议;现在我们来好好介绍它:
在介绍它之前我们先讲解一些预备知识;
1.网址URL解释
1.1 什么是URL
我们今天讲解的是与http协议有关的内容,而我们又知道在我们使用浏览器访问网站时,我们总会看见网址带有https和http的前缀,那这究竟是什么意思呢?
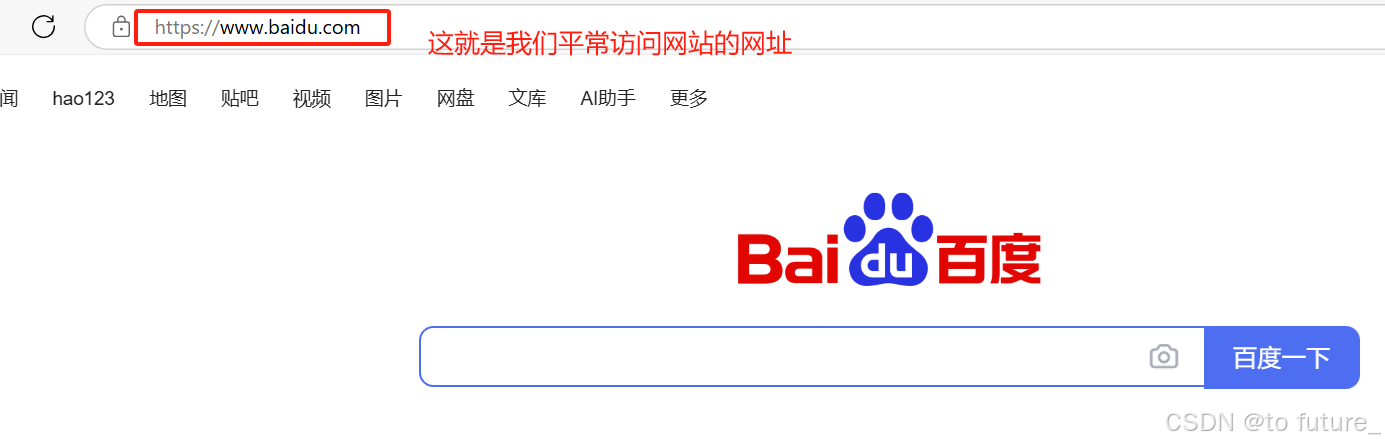
我们一般访问网站时一般都需要网站的网站,这个网址就是URL,通过URL我们可以通过浏览器访问相应的服务器;
1.2 URL的结构
scheme://username:password@hostname:port/path?query#fragment
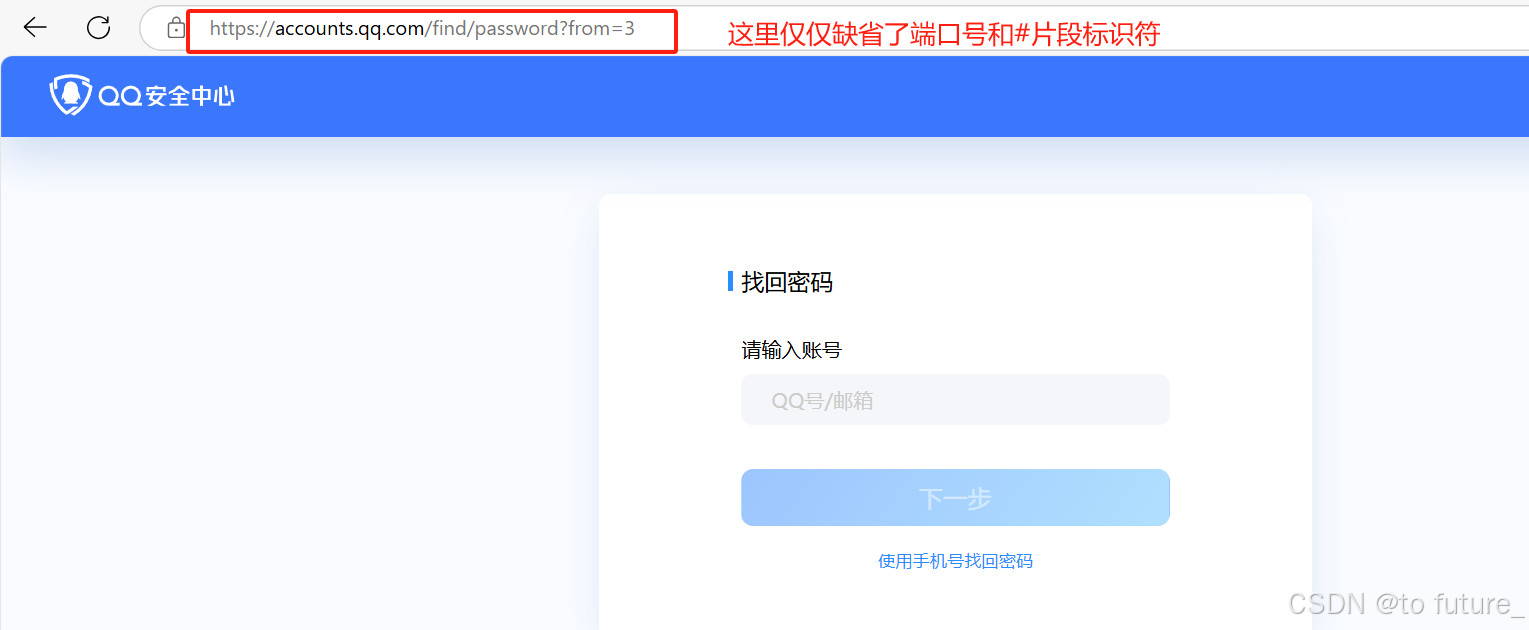
我们可以用上面的图片来对照下面的讲解进行理解;
scheme 协议
这对应着上面的图片中的https,代表协议的意思可以是http,https,ftp等
username:password 登录信息
用于验证主机的用户名和密码,不过这段字节一般不会出现显示在URL中,一般会通过表单或者其他的方式提交
hostname 服务器地址
这是远程主机的IP地址或者域名,在浏览器中一般显示为域名,浏览器底层会将其解析为IP地址,表面上一般是如www.baidu.com这样的域名
port 端口号
这是远程主机上对用进程的端口号,http协议默认链接80号端口,https默认链接443号端口,所以这个端口号有时候可以不显示输入
/path 网络根目录下的文件
访问我们远程主机网络根目录下的某个文件,"/"代表网络根目录的意思
?query#fragment 参数信息和片段标识符
这两个参数一般是传递给主机下文件的参数,可以通过这些参数进行某些操作或者传递某些信息
小tip:
1.我们在日常访问网站时一般只需要一个域名即可,这是因为浏览器帮我们将剩余的部分自动补齐了 ;
2.另外,我们可以看到我们的URL上有/ @ :?这样的分隔符如果我们的参数信息中也有这样的符号,这些符号会被转义,会将这些字符转换为16进制数并从右往左取4位,不足四位直接处理,再在前面加上%符号

我们可以看到空格被处理为了%20,/被处理为了%2F,这些是它们的16进制的ASCII码;
2.http协议的请求与响应格式
http协议是建立在tcp协议之上的,所以http协议是遵守字节流传输的;那么我们的http协议其实也是通过将结构化数据序列化为字符串传输的;那我们的请求和响应肯定也都是字符串;接下来我们来看看它们究竟是什么样子的:
2.1 请求格式
我们想要看到请求发送的报文,我们可以自己创建一个tcp服务器(前面就有实现过),再接收浏览器发送过来的报文,查看浏览器的请求;
我们先直接看看报文的样子,再来做讲解:
下面的红色框框中的部分就是浏览器发送给服务器的请求报文
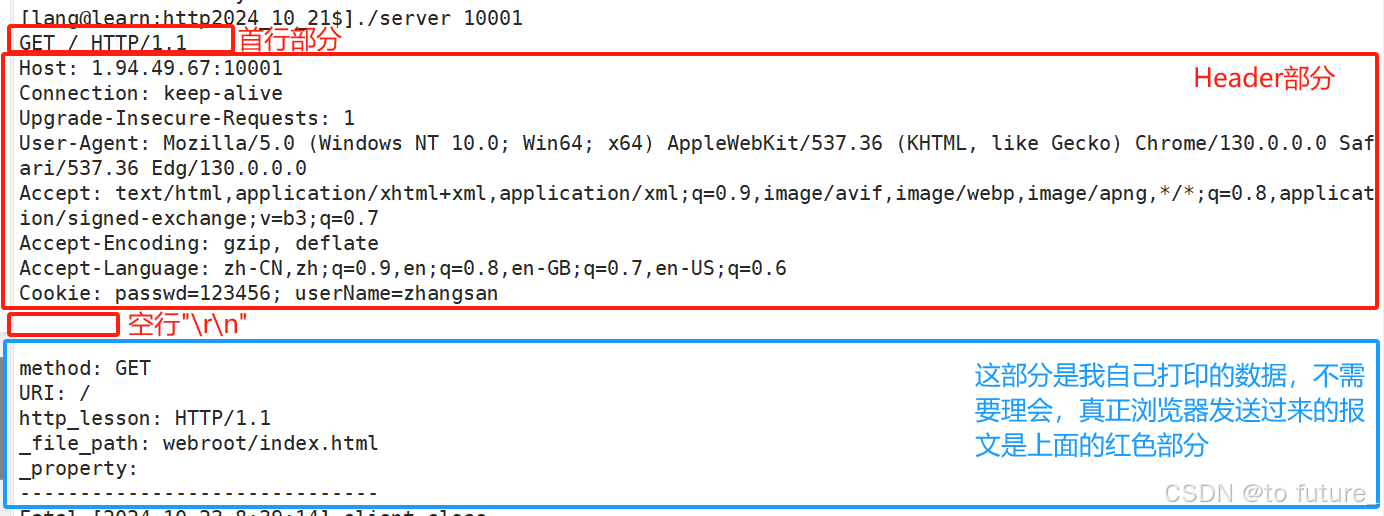
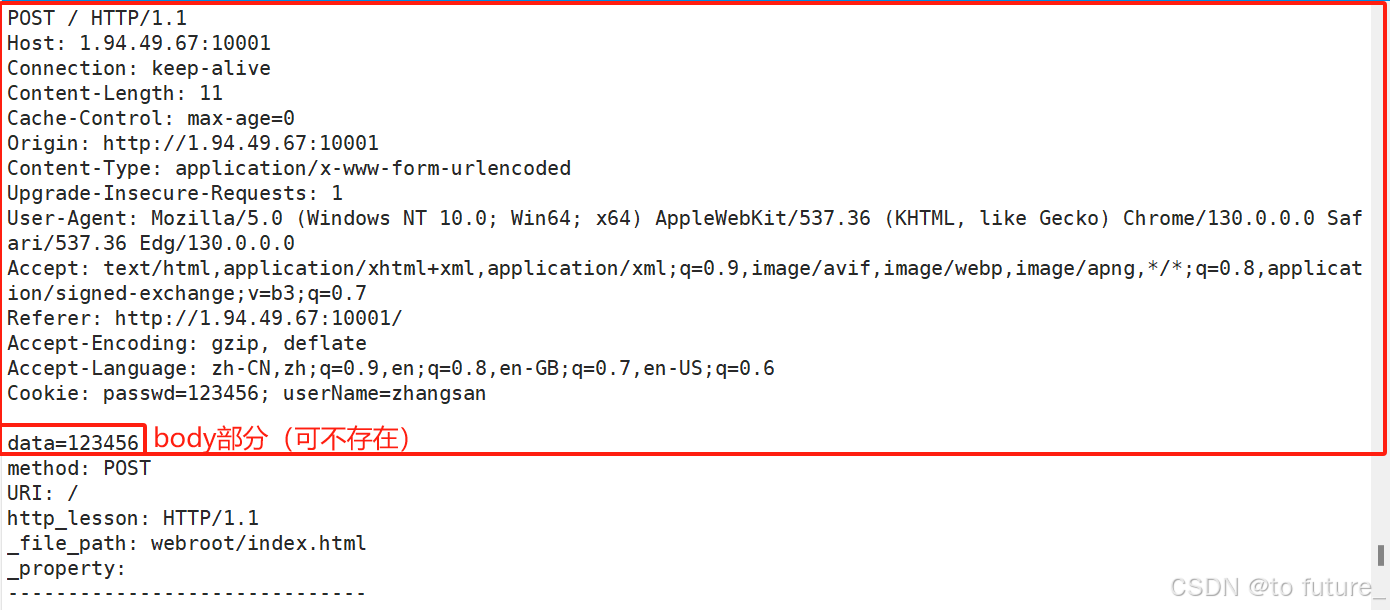
浏览器发送来的请求报文由四部分组成:
首行部分,header部分,空行,body部分
2.1.1 首行部分
首行部分由method+URI+http_version三部分构成,它们之间使用空格进行分隔,最后使用"\r\n"来作为首行的结束符;

method:
method是http协议中约定好的请求方式,有这些方法:

这是从菜鸟教程中截取的讲解如果想详细了解可以通过下面的网址到菜鸟教程中查看:
HTTP 请求方法 | 菜鸟教程
URI:
这里的URI只有 " / " 的原因是浏览器只发送了URI中的path以及path部分之后的数据;
http_version:
下面也是从菜鸟教程中获取的解释,其实就是说,我们的http协议也是在不断发展的,其中的http协议版本支持了这些方法,我们需要标识http协议的版本让服务器也知道,这样服务器返回的响应也会是响应版本或者低版本的;

2.1.2 Header部分
这部分存储的是请求的各个属性,这些属性是提供给服务器,让服务器根据这些属性做相应的处理的;Header部分由属性名+属性+" \r\n "构成,属性可以有很多条,每条的结束符都是"\r\n",header部分是以键值对的形式出现的;
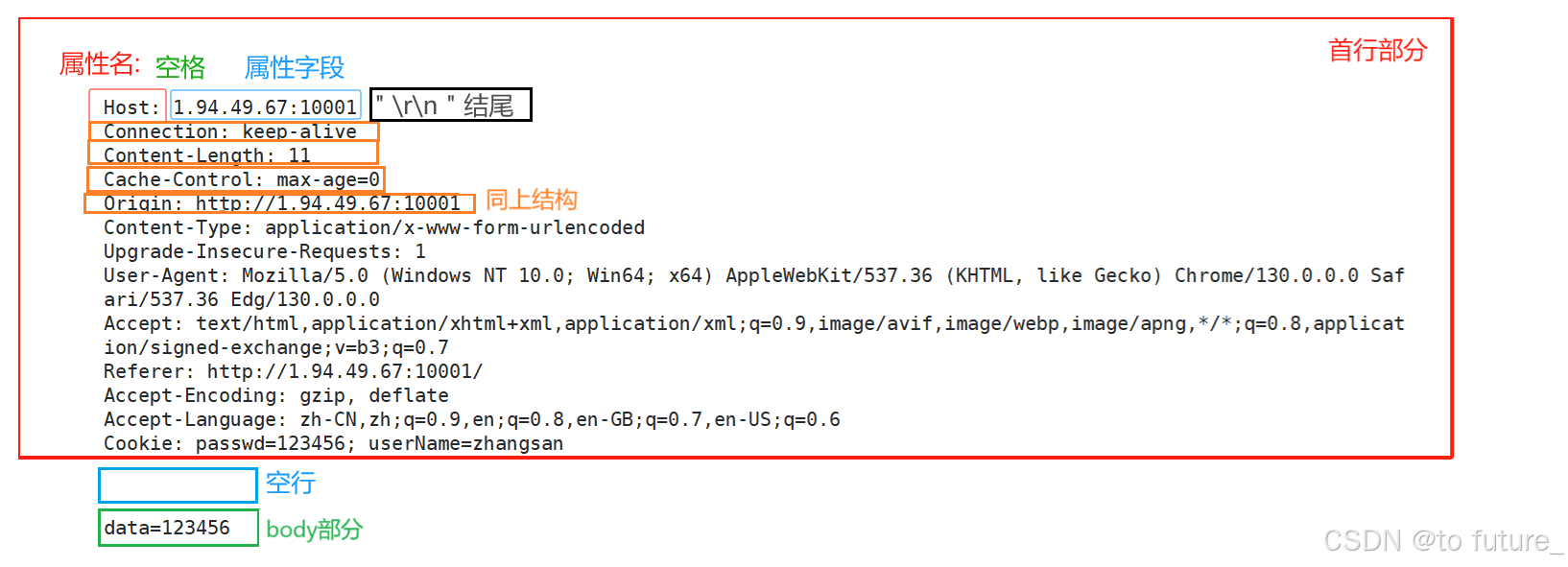
2.1.3 空行和body部分
从上图,我们就可以看到空行和body部分,我们可以理解为空行是用来作为header部分的结束符的,body部分有些请求是没有的,如GET方法的请求,所以有时候会出现这样的情况:
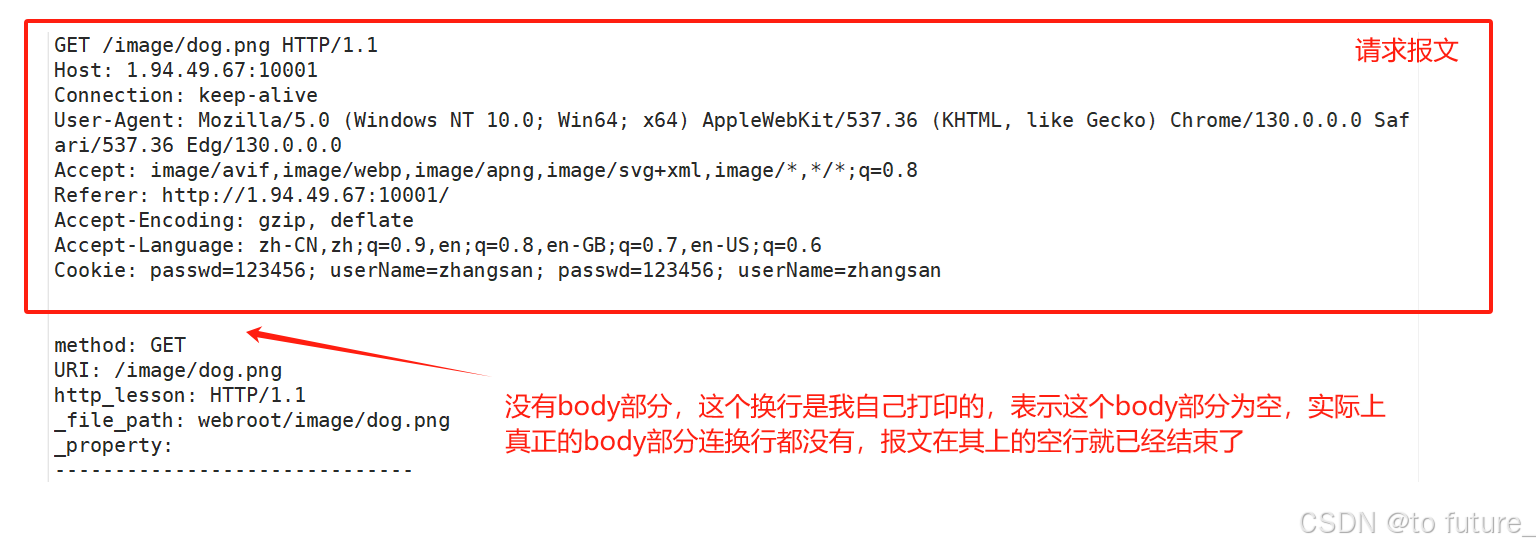
2.2 响应格式
我们还是一样,用我们自己写的服务器向浏览器返回我们的响应,这个响应的字符串是我们自己编写的,可能编写的不够全面,但是可以辅助我们理解;
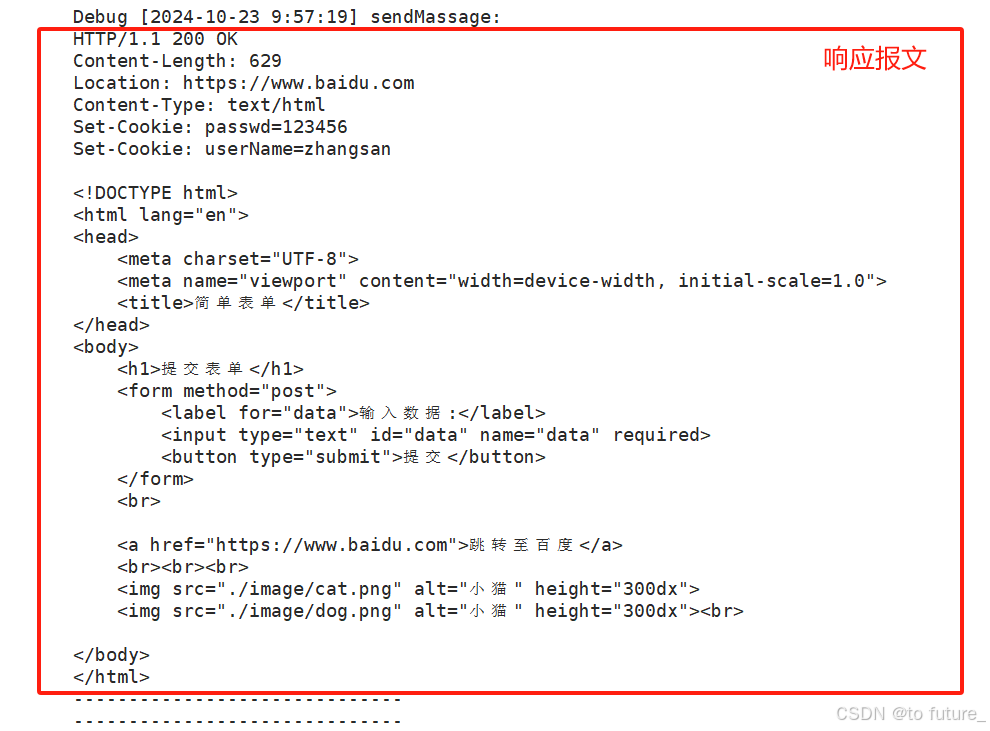
响应的页面:
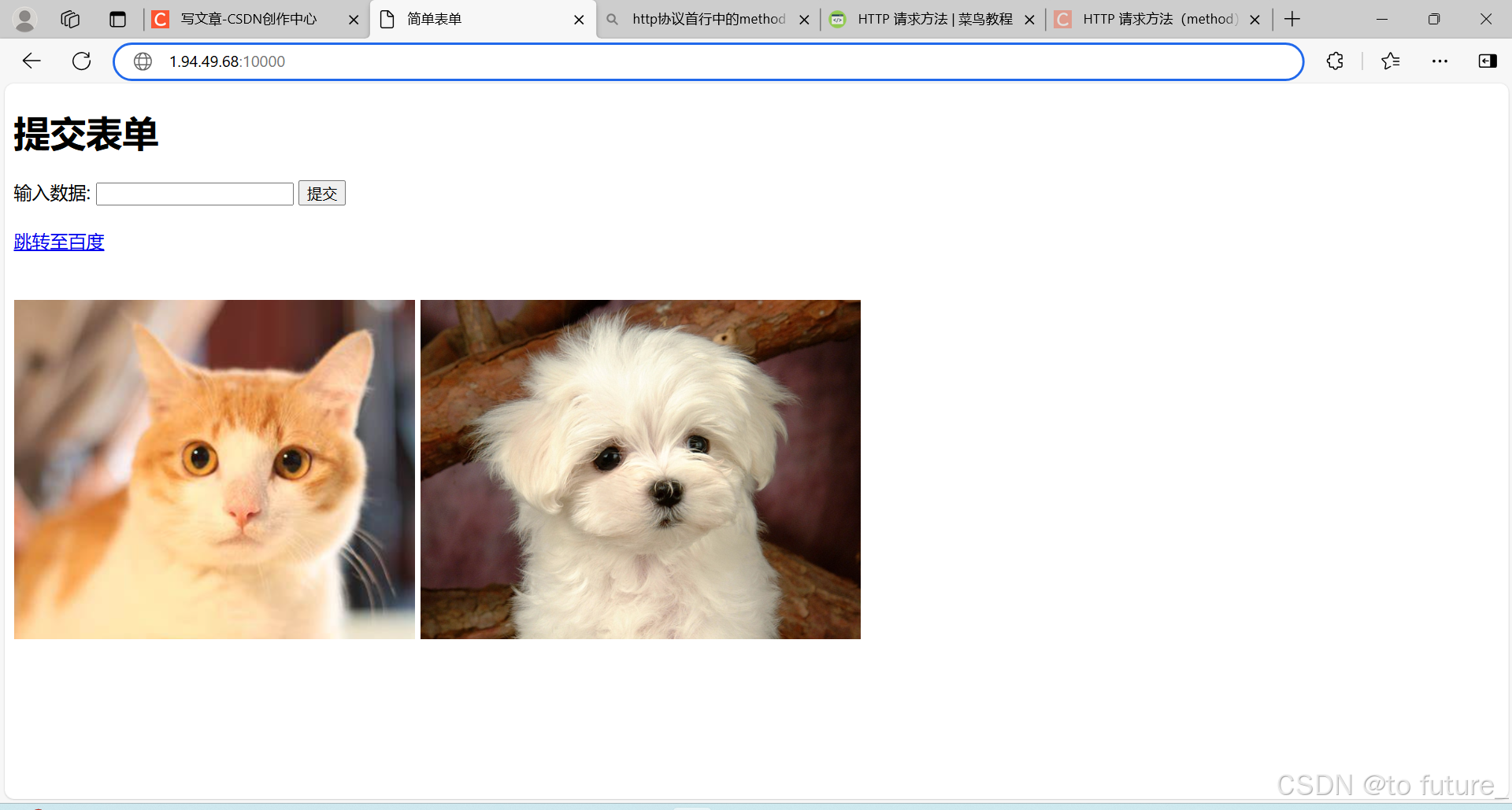
这只是一个很简单的html页面,因为我没有好好学前端,所以这里只是展示一下我们可以返回形成让浏览器理解的html数据,让浏览器解析成网页;
接下来,我们也介绍一下响应的组成:
首行部分+header部分+空行+body部分
其实响应和请求的结构其实差不多,只是里面的内容有些许不同:
2.2.1 首行部分
响应的首行部分:

http_version+返回状态码+状态码描述
响应的其他部分header,空行,body部分都是和请求一样的;
3.服务器响应过程
我们上面了解了请求和响应的格式,那么接下来,我们实现一个用来测试的服务器,让这个服务器可以处理浏览器的访问,并返回响应给浏览器,还可以让我们看到网页的现象;
下面是我完整的代码实现:
network_code/http2024_10_21 · future/Linux - 码云 - 开源中国
3.1 实现tcp服务器
我们通过实现服务器来了解响应的过程,所以我们先得有一个tcp服务器提供通信,我们首先像前面实现tcp服务器一样实现一个tcp服务器:
class server
{
public:server(uint16_t port): _port(port){init();}void init(){_sck.Bind(_port);_sck.Listen();// 下面的代码用来让服务器重启不需要等待时间,暂时不知道原理,先用着int opt = 1;setsockopt(_sck.getsock(), SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));}void run(){signal(SIGPIPE, SIG_IGN);signal(SIGCHLD, SIG_IGN); // 让让主进程不要阻塞等待while (true){std::string clientIp;uint16_t clientPort;int serverFd = _sck.Accept(clientIp, &clientPort);if (fork() == 0){服务器创建的子进程进行对请求的响应工作。。。。。。_sck.Close();exit(-1);}close(serverFd);}}private:uint16_t _port;Socket _sck;
};其实不管是在前面实现tcp服务器,还是在后面实现应用层协议,我们都实现了很多次基本的通信服务器,所以我们这里只是展示部分代码,帮助以后的我进行回忆;
3.2 处理请求
当我们的服务器可以和浏览器进行通信后,我们就需要开始处理浏览器发送过来的请求了;我们创建一个处理请求的request类来处理:
class httpRequest
{
public:httpRequest(){}~httpRequest(){}bool deserialization(std::string &massage){反序列化操作,将请求中的报文处理出来}bool analysis(){}void print(){}std::string getPath(){}std::string getContent(){}private:std::vector<std::string> _req;std::string _body;// 首行数据std::string _method;std::string _URI;std::string _http_verson;std::string _file_path; // 客户端想要访问的文件std::string _property; // URI中的属性数据// header中的属性(我们暂时不需要所以不分析出来)
};其实这里和前面的自定义应用层协议编写一样,不过呢,这里的协议是已经规定好的,不是我们自己定义的;
我们可以通过这个类处理出来请求中的信息,接下来我们需要对请求做处理,再将处理好的响应返回给浏览器;
3.3 处理与返回响应
一样我们写一个响应的类:
class response
{
public:response(const std::string &http_verson, int stat_code, const std::string &stat_describe): _http_verson(http_verson), _stat_code(stat_code), _stat_describe(stat_describe){}~response(){}bool serialize(std::string &sendMassage, const std::string file_path, std::string Content = "text/plain"){// 获取bodystd::string text;std::ifstream in(file_path.c_str(), std::ios_base::binary); // 这里一定要显式的使用二进制打开if (!in.is_open()){lg(WARNING, "open sendText fail");return false;}char buffer[1024];in.seekg(0, std::ios_base::end);auto len = in.tellg();in.seekg(0, std::ios_base::beg);text.resize(len);in.read((char *)text.c_str(), len);in.close();// 首行内容sendMassage = _http_verson;sendMassage += blank_sep;sendMassage += std::to_string(_stat_code);sendMassage += blank_sep;sendMassage += _stat_describe;sendMassage += sep;// header内容sendMassage += "Content-Length: ";sendMassage += std::to_string(text.size());sendMassage += sep;sendMassage += "Location: https://www.baidu.com"; // 这里是302状态时重定向的网址sendMassage += sep;sendMassage += "Content-Type: "; // Content-Type属性sendMassage += Content;sendMassage += sep;sendMassage += "Set-Cookie: passwd=123456"; // Set-Cookie属性sendMassage += sep;sendMassage += "Set-Cookie: userName=zhangsan";sendMassage += sep;// 空行sendMassage += sep;// body内容sendMassage += text;// sendMassage += sep;//不需要在body部分加"\r\n"了因为,Content-Length属性已经标识了body部分的长度return true;}private:std::string _http_verson;int _stat_code;std::string _stat_describe;
};我们如何进行响应的呢?
1.我们首先将请求中获得的想要访问的文件打开(这个文件路径是在请求中已经处理好的,一定存在的),再读取出文件中的数据;我们获取数据时还要注意我们要二进制读取文件数据,如图片视频音频,这些如果不二进制读取会发生很多错误;
2.通过调用传来的数据,将首行,header数据,空行以及刚刚获取出的文件数据作为body一起写入到发送的字符串中;
3.4 接收请求和返回响应
我们最后将响应返回给浏览器,浏览器会自己解析我们响应中的内容,body部分如果是html会被浏览器解析成显式的网页;
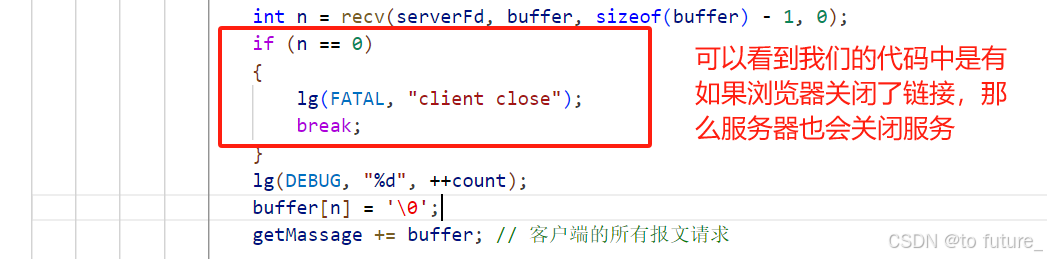
std::string getMassage; // 获取客户端报文while (true){//获取请求char buffer[1024] = {0};int n = recv(serverFd, buffer, sizeof(buffer) - 1, 0);if (n == 0){lg(FATAL, "client close");break;}buffer[n] = '\0';getMassage += buffer; // 客户端的所有报文请求// 这里假设每次都能读取到完整的报文,否则我们还要对报文是否完整进行检查和处理。。。。。处理请求,反序列化std::string sendMassage;。。。。。。根据请求做相应的处理,并制作好响应// 将处理好的响应发送回客户端(浏览器)send(serverFd, sendMassage.c_str(), sendMassage.size(), 0);} 上面就是我们服务器的大致工作过程,接下来,我们来讲解一下这其中的细节;
4.服务器处理与HTTP细节
4.1 动态变化的网页
我们通过上面的过程可以知道,我们返回的响应的body部分是从文件中读取的数据,文件是在我们的服务器主机上的,不是在进程中的,所以我们可以在进程运行时修改html网页,网页修改了,浏览器重新请求,服务器进程不需要重启就可以实现网页更新;
这其实也是前后端分离的一个表现,在我们以后的工作中,我们作为后端开发的程序员,只需要将前端写的网页进行获取写入我们的报文中即可
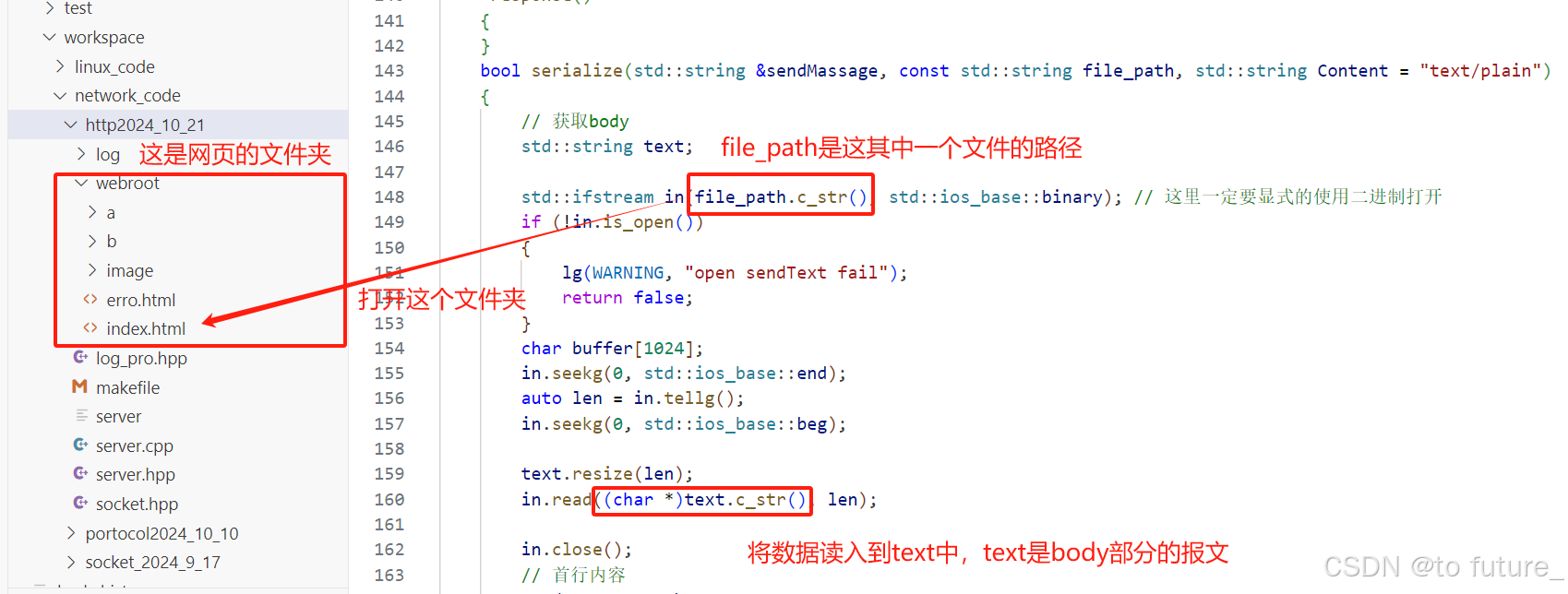
4.2 web根目录概念
我们使用域名访问网站时,一开始是这样的:

接下来,我们搜索或者点击某个链接:

我们再用我们自己的服务器演示一下:


这里的/是网络根目录的意思,我们需要自定义这个/所在的文件,当我们访问/下的文件时,就是访问我们自定义目录下的某个文件:
bool analysis(){std::stringstream s(_req[0]);s >> _method >> _URI >> _http_verson;// 处理URI把属性数据获取出来std::string tmp = _URI;int pos = tmp.find('?');if (pos != std::string::npos){lg(DEBUG, "%s,%d", tmp.c_str(), pos);_property = tmp.substr(pos + 1);tmp.erase(pos, std::string::npos);}pos = tmp.find('#');if (pos != std::string::npos){tmp.erase(pos, std::string::npos);}_file_path = home_path;if (tmp == "/" || tmp == "/index.html"){_file_path += "/index.html";}else{_file_path += tmp;}return true;}这是我们的请求中的对请求中URI中的访问文件路径处理的函数,将相应的文件路径分析出来,通过这样的处理:
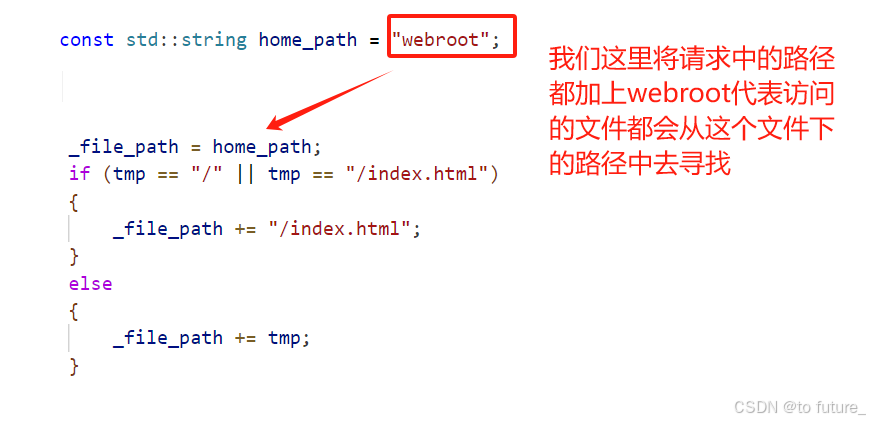
所以我们浏览器访问我们文件时都是会进入这个webroot根目录下去访问的,这就是网络根目录,一个我们自定义的行为的概念;
4.3 分割字符串的方式
1.使用string的find搭配substr和erase
#include <iostream>
#include <string>
#include <sstream>void useString(std::string str, const std::string op = " ")
{while (true){int pos = str.find(op);if (pos == std::string::npos){break;}std::cout << str.substr(0, pos) << " ";str.erase(0, pos + 1);}if (!str.empty())std::cout << str;std::cout << std::endl;
}2.使用stringstream
void useStrstream(std::string str, const char op = ' ')
{std::stringstream s(str);std::string tmp;while (std::getline(s, tmp, op)){std::cout << tmp << " ";}std::cout << std::endl;
}
测试代码:
int main()
{std::string s("apple banana cat dog");std::string s1("apple?banana?cat?dog");std::string s2("applebananacatdog");useString(s, " ");useStrstream(s, ' ');useString(s1, "?");useStrstream(s1, '?');//测试一下stringstream在没有遇到分隔符时是否还会读取useStrstream(s2, '?');return 0;
}现象:
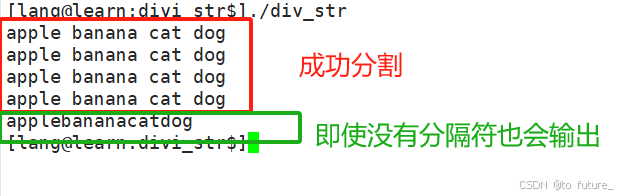
1.我们需要注意的时stringstream的getline在遇到结尾符时还是会返回true,最后将末尾字符传给buffer,而第一种方式我们要自己处理结尾的字符串;
比如:aaa?bbb?ccc 第一种方式要多处理一次最后的ccc,但第二种方式自动处理了
2.getline这个函数只能分割字符分隔符不能分割字符串分隔符;如果遇到分隔符是很长的字符串的时候,我们只能使用上面的第一种方式来处理;
比如:aaa??bbb??ccc第一种方式可以直接处理,第二种方式无法处理
4.4 请求方法
请求方法使用最多的是POST和GET方法
浏览器的请求一般是GET方法,只是单纯的向服务器发起请求,所以这个GET方法一般是没有body部分的;而POST方法在请求时会发送一些格外的数据给服务器,这些格外的数据会被放在报文的body部分一起发送给服务器;
GET:
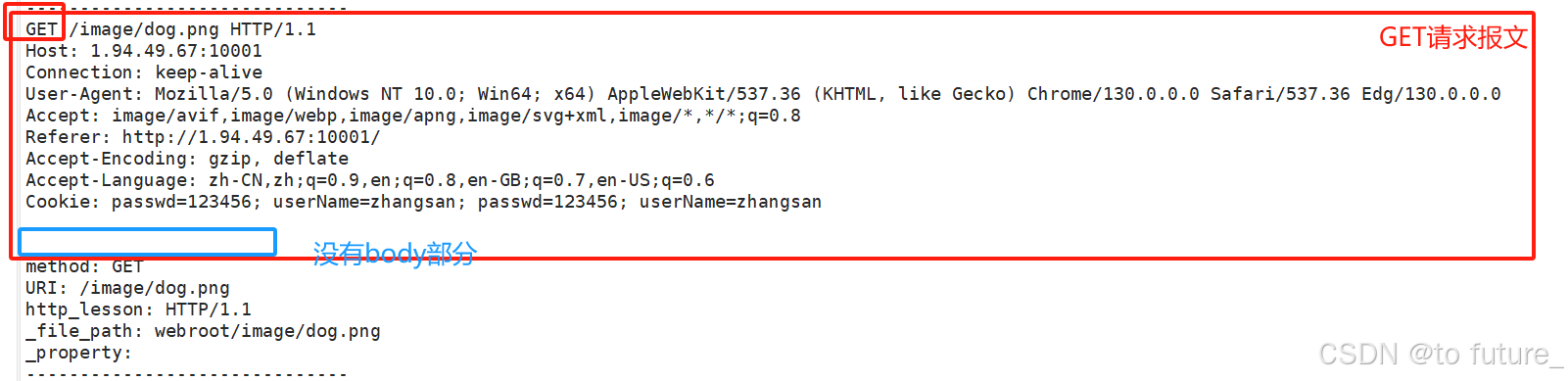
POST:
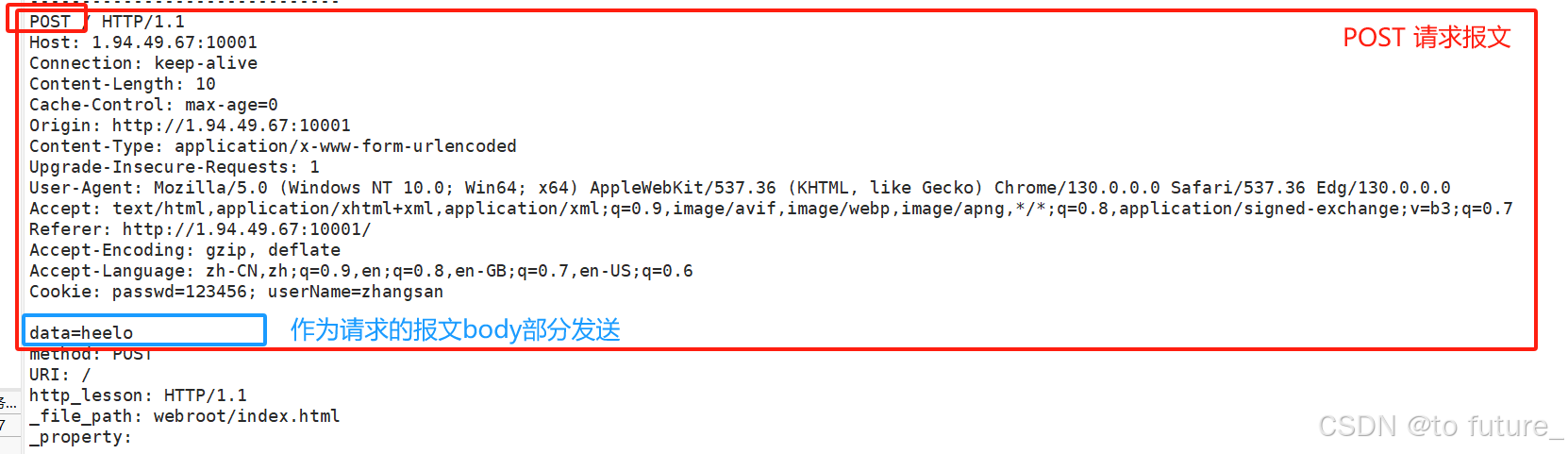
这其中如果GET也需要发送数据给服务器,会将要发送的数据接在在URI之后,就比如:

而POST方法会将这些要发送的数据放入报文的body正文部分,在外部不会被看到,更安全;POST方法一般是像表单这样的网页功能发送的请求;
其他请求方法:

图片来自于菜鸟教程:
HTTP 请求方法 | 菜鸟教程
4.5 header部分常见属性
较为全面的header属性可以从下面的链接观看:
HTTP 响应头信息 | 菜鸟教程

我们主要介绍请求和响应报文中的这些红色框框中的属性;
4.5.1 Connection属性
这个属性是有关长短链接概念的,当这个属性为keep-alive时表示这个链接是以长链接的形式和服务器连接的,浏览器会和服务器保持一段时间的链接,当这段时间中的浏览器请求全部处理完的时候,服务器才会close关闭服务套接字,我们可以看到浏览器发送多次请求的情况,并且保持一直连接的情况:

下面服务端出现了这些请求:
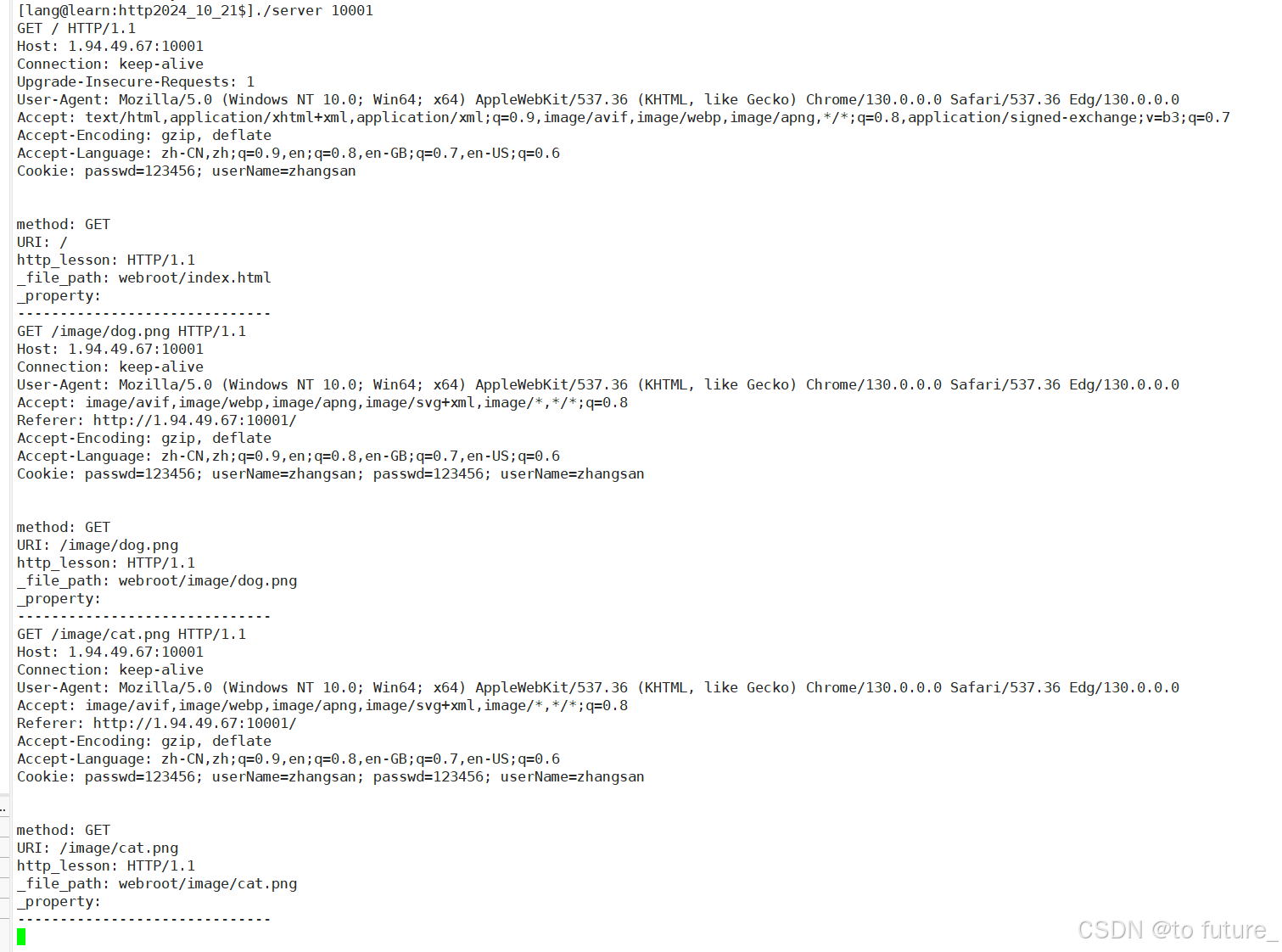
我们可以看到,浏览器在解析服务器响应的html页面时,发现html还请求了图片,所以浏览器又会自动的去请求两张图片,这就是一段时间内有多个申请的原因,根本原因是因为html文件中还有请求;并且上面的现象中也没有出现client close的warning,所以说明浏览器的请求确实与服务器建立了长连接;
我们使用ps指令也可以查看到服务进程的存在:

4.5.2 Content-Length
这个属性是用来表示我们的报文的body部分的长度的,可以用这个属性来分隔开我们的报文,这也是为什么我们的body部分不需要使用"\r\n"作为结束符的原因;
4.5.3 User-Agent
这个属性是用来标识请求的用户主机操作系统,浏览器信息的
4.5.4 Referer
这个属性是用来标识请求的页面是来自与哪个页面的,也就是说从哪个页面跳转过来的,存储了这个属性就可以实现像网页访问的回退功能:

4.5.5 Content-Type
这个属性是用来标识报文的body部分的内容是什么类型的,如果是响应报文,浏览器会根据你响应的这个属性来识别你的body内容,图片识别为图片内容,html网页被识别为网内容;
具体Content-Type不同数据对应的属性可以通过下面的连接查看:
HTTP content-type | 菜鸟教程
我们写的服务器中其实也有这样的body数据类型判断:
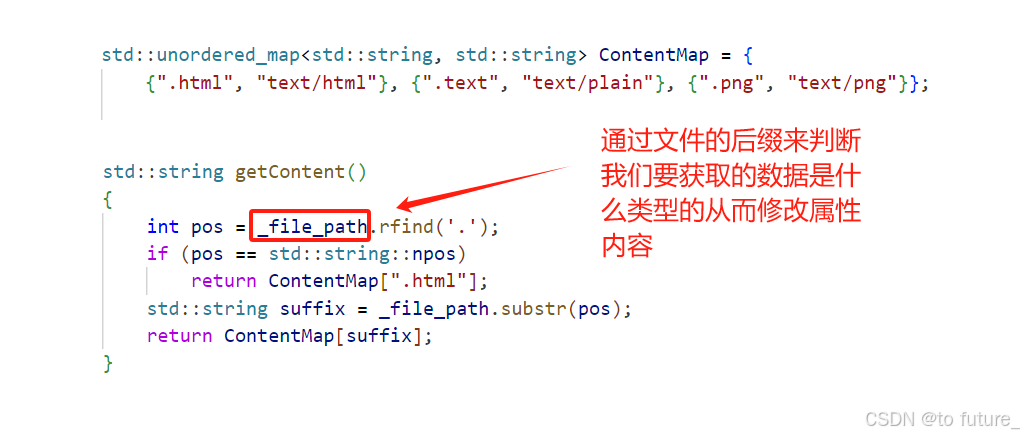
还有两个常见的header属性,我们通过下面的内容来讲解:
4.6 Http状态码
下面是详细讲解的链接:
HTTP 状态码 | 菜鸟教程
下面的图片是来自菜鸟教程的链接:
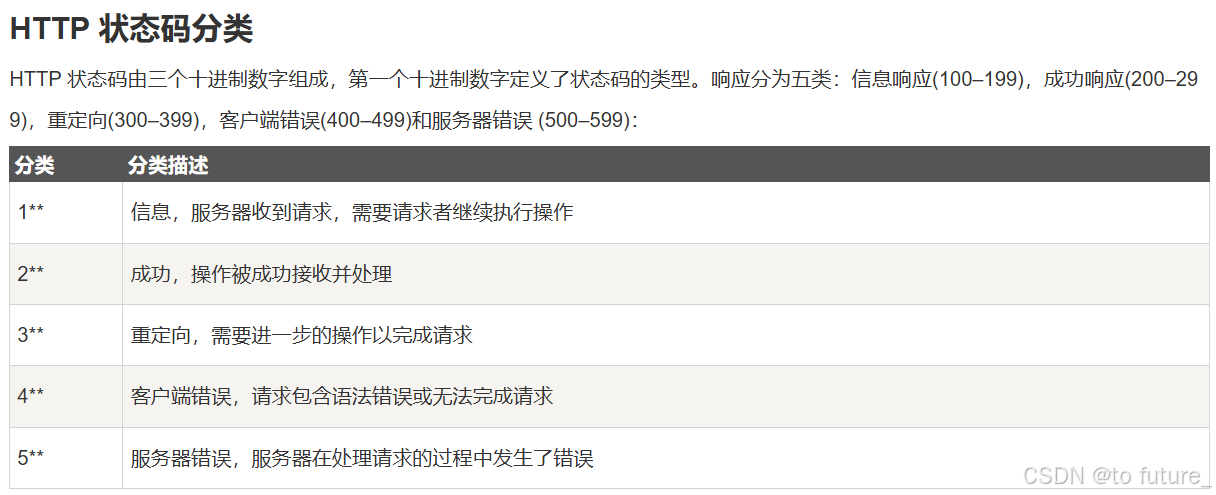 我们只需要知道不同的响应需要有不同的状态码返回;我们一般需要记住的是:
我们只需要知道不同的响应需要有不同的状态码返回;我们一般需要记住的是:
200 OK成功返回
301永久重定向 302 FOUND 307临时重定向
404 NOT FOUND 客户端错误
5** 这一般是服务器内部发生了错误比如服务器段错误或者是内存不够发生的错误
根据具体情况返回不同状态码;
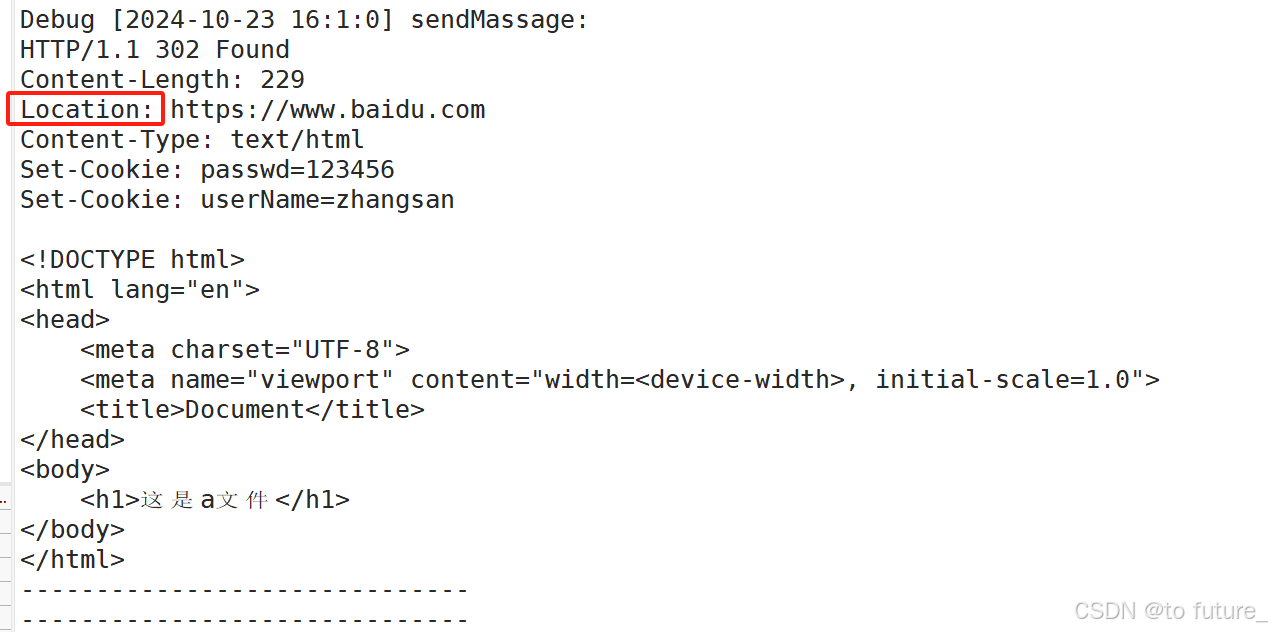
4.6.1 Header属性Location
我们的Location属性需要搭配我们的3**状态码使用,当返回的响应状态码是302状态描述符是FOUND时,我们的网页会被重定向到Location属性所指向的域名;
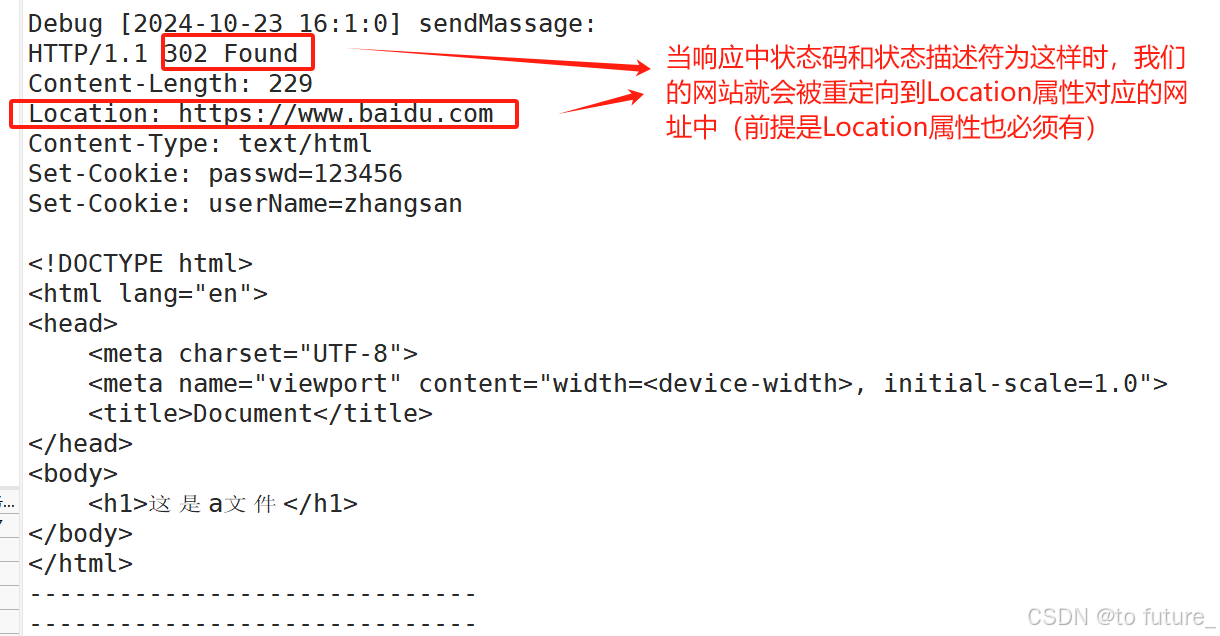

这就是重定向的功能;其中重定向还有永久和临时的区分,如301永久和302临时;
4.7 cookie数据与session会话
4.7.1 cookie数据
我们在访问某些网页的时候,往往都需要注册相应网页的账号,登录这个账号时才能享受网页的更好的服务,就比如说B站我们想要看更高清的视频,我们就得登录账户;而我们登录账户后关闭浏览器下一次继续访问网页就不需要我们再手动登录了,我们访问网站可以发现我们自动就是登录状态了;这是如何做到的呢?
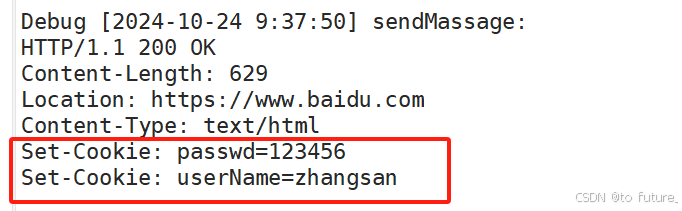
我们在第一次登录时,将用户信息发送给了服务器,服务器接收到验证之后,将这些数据通过Set-cookie属性发回浏览器,浏览器将这数据设置为cookie数据,cookie数据被存入内存或者是磁盘中,下一次访问网站时从磁盘或者内存中拿出cookie数据一起访问服务器,服务器就可以直接识别用户返回用户已经登录的响应;
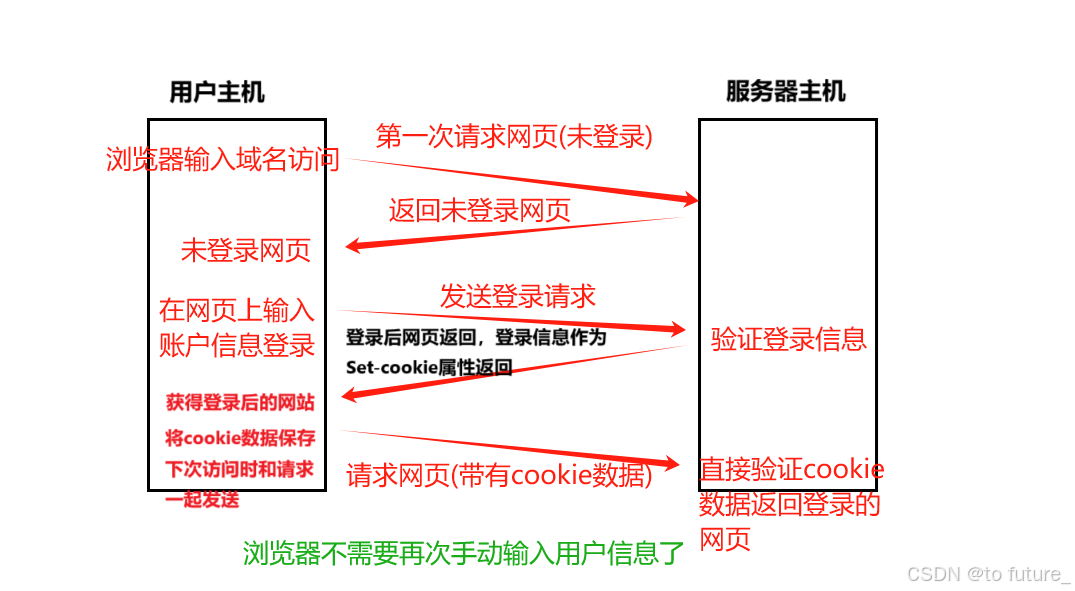
我们模拟服务器通过Set-cookie属性向浏览器发送请求,验证浏览器会保存cookie数据,且下一次请求会将cookie数据一起作为请求发送;
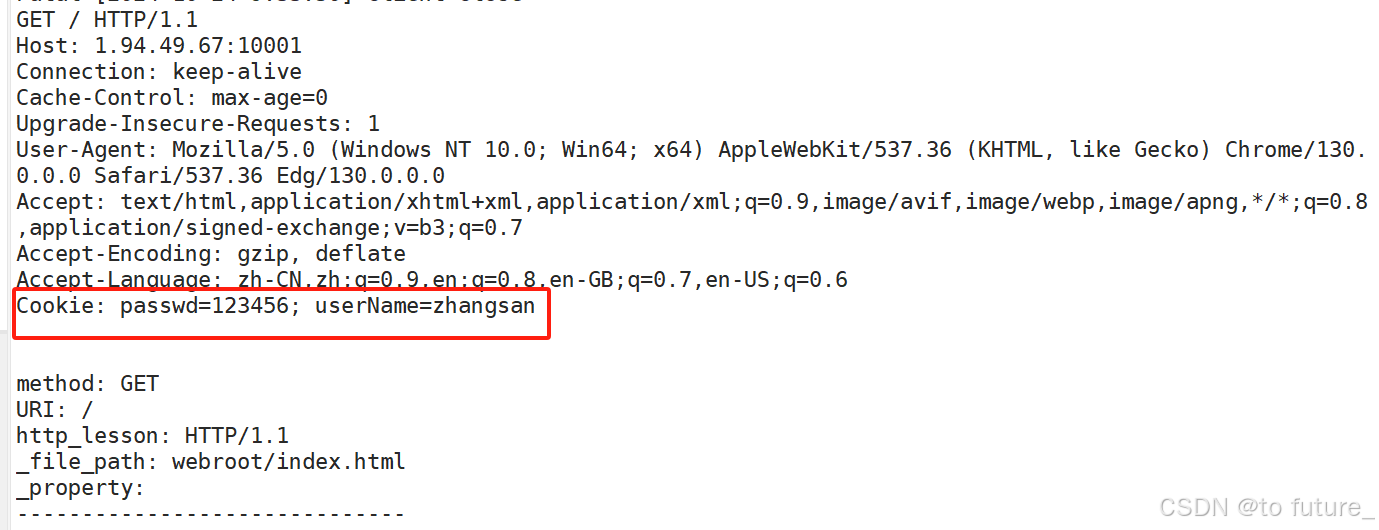
我们可以看到确实浏览器已经将cookie数据也发送回服务器了;我们再通过查看网页上的现象也可以看到cookie的保存:
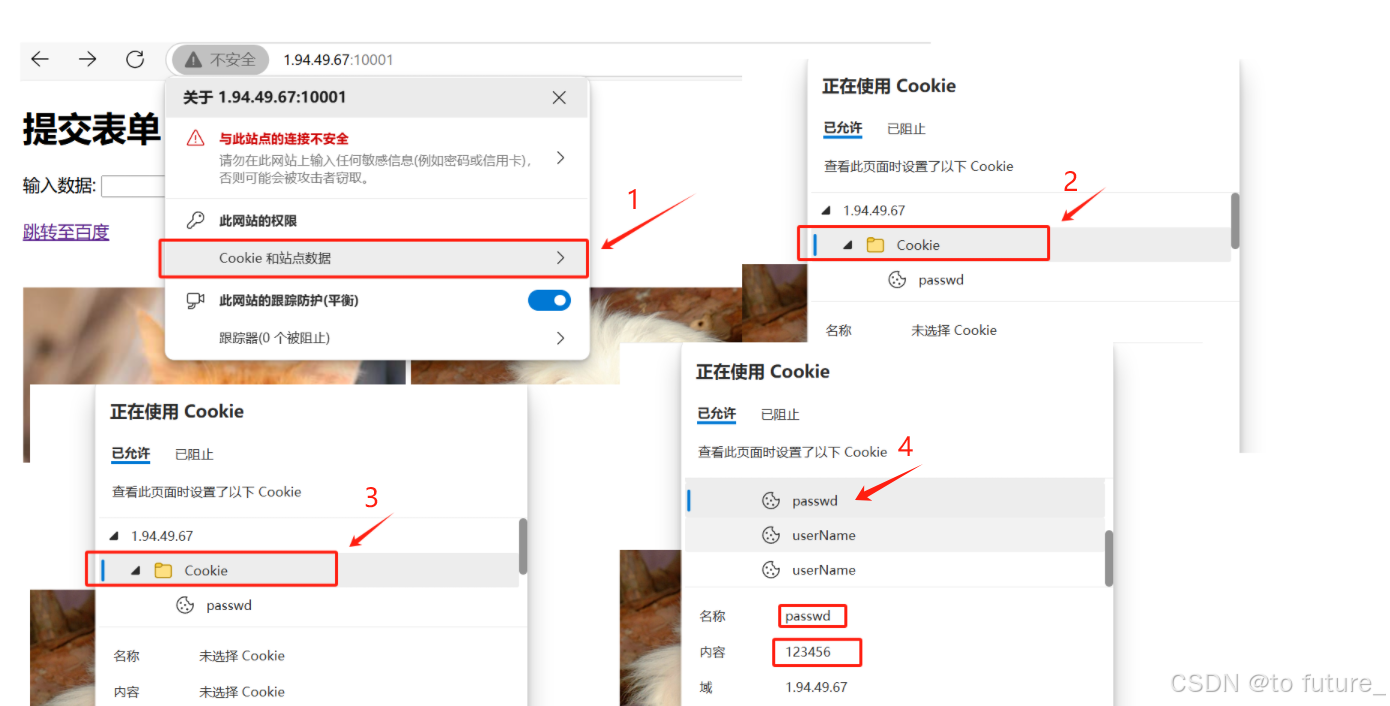
4.7.2 session会话
我们知道http是明文传输的,就是说任何机器只要捕捉到了我们的报文就可以获取我们的信息,那如果我们的cookie数据中有我们的登录信息是不是就会存在账号被盗取的风险呢?这个风险是真真正正存在的;但是我们的服务器厂商做了防范,厂商们会将用户第一次登录时所发送的用户信息存入到服务器所维护的session会话中,下次通过Set-session返回给用户的就不是原本的用户信息了,发送的是用户的sessionID,用户将sessionID存入到它的cookie数据中,之后的请求中属性cookie存放的就都是sessionID而不是明晃晃的用户信息,用户下一次请求时将cookie中的sessionID存入请求报文一起发送给服务器,服务器通过sessionID找到session中存储的用户信息,服务器直接比对session中的数据即可;这样就解决了用户信息直接暴露的问题;
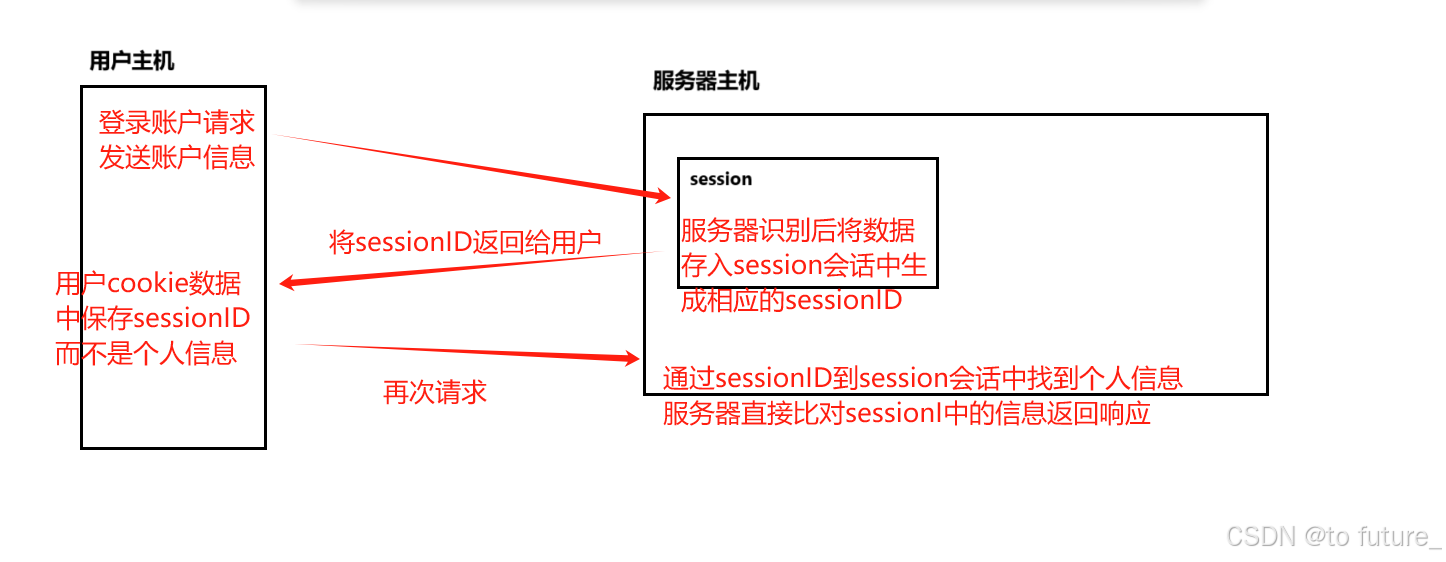
但这仅仅只是解决了用户信息直接暴露的问题,cookie数据还是可以被捕获拦截,被非法分子盗取,这是无法避免的问题;并且如果我们第一次发送用户信息给服务器时个人信息就被捕获了,那么这个session会话也起不到保护个人信息的作用;
用户个人信息暴露 (基本可以解决)
cookie数据被盗取 (无法解决)
所以http的明文传输是非常不安全的,我们一定得对传输的报文进行加密处理;接下来的博客我们将讲解https协议,让我们来看看https是如何解决这样的传输安全问题的;






_web前端开发设计_荆州百度推广_百度一下首页手机版)





