
1. 概述
DeepLab 模型首次亮相于 ICLR '14,是一系列旨在解决语义分割问题的深度学习架构。经过多年的迭代改进,同一组 Google 研究者于 2017 年底发布了广受欢迎的 “DeepLabv3”。当时,DeepLabv3 在 Pascal VOC 2012 测试集上取得了最佳 (SOTA) 性能,在著名的 Cityscapes 数据集上以及使用 Google 内部 JFT 数据集进行训练时也取得了相当不错的结果。
DeepLabV1:使用空洞卷积(Atrous Convolution)和全连接条件随机场(CRF)来控制计算图像特征的分辨率。
DeepLabV2:使用空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)来考虑不同尺度的物体,并以更高的准确度进行分割。
DeepLabV3:除了使用 Atrous 卷积外,DeepLabV3 还通过包含批量归一化和图像级特征,使用了改进的 ASPP 模块。它摆脱了 V1 和 V2 中使用的 CRF(条件随机场)。
在 ECCV '18 上发布的DeepLabv3+是 DeepLabv3 的增量更新。它在 DeepLabv3 语义分割模型的基础上进行了根本性的架构变革。

2. DeepLabv3
DeepLabv3 是一个完全卷积神经网络 (CNN) 模型,由 Google 研究人员团队设计,旨在解决语义分割问题。DeepLabv3 是对之前版本 (v1 和 v2) DeepLab 系统的增量更新,其性能远超其前身。
前几代 DeepLab 系统在后处理中使用不可训练模块“ DenseCRF”来提高准确率。此后,DeepLabv3 彻底放弃了后处理模块,成为一个端到端可训练的深度学习系统。
2.1 模型架构
从主干网络(VGG、DenseNet、ResNet)中提取特征。
为了控制特征图的大小,在主干的最后几个块中使用了空洞卷积。
在从主干网络提取的特征之上,添加了一个 ASPP 网络来对每个像素进行与其类别相对应的分类。
ASPP 网络的输出经过 1 x 1 卷积以获得图像的实际大小,这将是图像的最终分割蒙版。
2.2 解决的问题
第一个问题: 随着网络的深入,由于连续池化或步幅卷积用于下采样,会导致特征分辨率的降低。下采样块在深度卷积神经网络中被广泛采用,因为它们有助于减少内存消耗,同时保持变换不变性。这种行为有利于图像分类,但对于需要空间信息的分割任务来说却很麻烦。随着我们深入网络,特征图越来越擅长编码“图像中有什么? ”,但有关“图像中哪里?”的信息却丢失了。
为了缓解第一个问题,Deeplabv3 使用了“Atrous Convolution”并对主干的池化和卷积步幅组件进行了一些改变。
第二个问题: 物体在多个尺度上的存在。 例如,人类可以在图像中以多种分辨率出现。随着我们深入网络,感受域会增加,越来越擅长检测大型物体。然而,在这个过程中,较小尺寸的物体会受到影响。
为了缓解第二个问题,Deeplabv3 采用改进的“Atrous Spatial Pyramid Pooling”模块进行多尺度特征提取。
2.3 基本组件
2.3.1 空洞卷积
空洞卷积,也叫“扩张卷积”,可以在不增加计算量的情况下扩大感受野,有助于捕捉更丰富的上下文信息。它允许我们控制深度卷积神经网络(Deep Convolutional Neural Network,DCNN)计算特征的分辨率,并调整过滤器的感受野(Receptive Field)以捕获远距离信息。它的核心思想是在卷积核中的元素之间引入空洞(间隔),也就是说使用一个名为“带孔/扩张率”的参数来调整视野。
空洞卷积与传统卷积类似,不同之处在于,过滤器通过在每个空间维度上的两个连续过滤器值之间插入零来进行上采样。插入 r - 1 个零,其中 r 是带孔/扩张率。这相当于在每个空间维度上的两个连续过滤器值之间创建 r - 1 个孔。
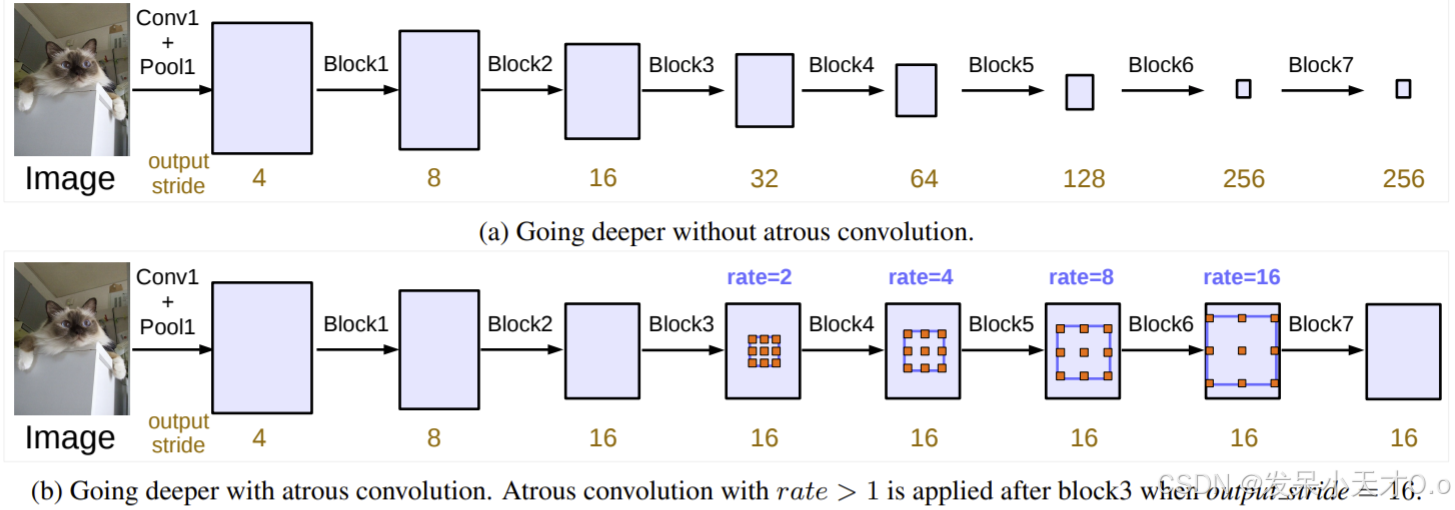
在下图中,使用大小为 3 且扩张率为 2 的过滤器来计算输出。我们可以想象,由于扩张率为 2,过滤器值之间相隔一个洞。如果扩张率 r 为 1,则它将是标准卷积。


如下所示,图 (a) 表示不带空洞卷积的 DCNN。该网络由标准卷积和池化操作构建,这使得输出特征图在每个块操作之后变小。这种类型的网络在捕获长距离信息方面非常有用。例如在图 (a) 中,具有非常小分辨率特征图(比原始图像小 256 倍)的块 7 的最终输出总结了整个图像特征。然而,这种较小分辨率的特征图对于需要详细空间信息的语义分割任务没有用处。
通过使用图 (b) 所示的空洞卷积,我们可以保留空间分辨率并通过捕获每个尺度的特征来构建更深的网络。这是通过增加每个块的膨胀来实现的。因此,过滤器的视野变得更宽,这是获得更好的语义分割结果所必需的。具有不同的扩张率 r,滤波器将具有不同的视野。因此,我们可以在全卷积网络中为多个尺度对象计算特征,而无需减小特征图的大小。这是通过在标准深度卷积网络中应用步幅卷积或池化操作来实现的。
注意:DeepLabV3 使用率分别为 6、12 和 18 的空洞卷积。
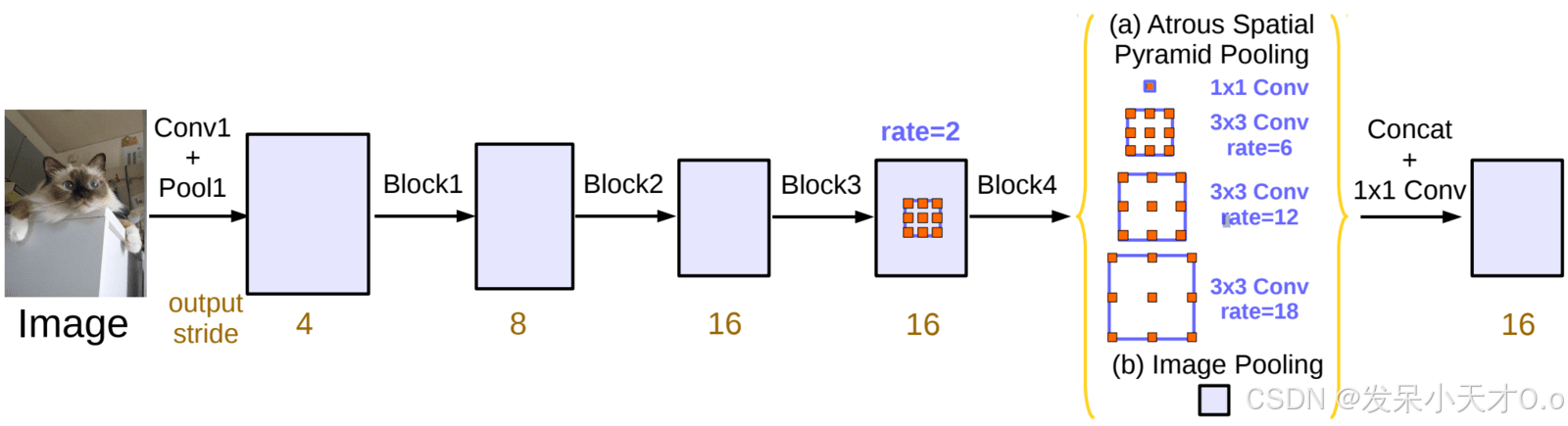
2.3.2 空洞空间金字塔池化
顾名思义,ASPP 就是简单的 SPP,但是带有空洞卷积。 SPP 被提出作为池化层的替代品,以消除分类模型的固定大小限制。SPP 中使用的技术证明了对不同尺度的特征进行重新采样对于准确有效地对任意尺度的区域进行分类是有效的。
鉴于 SPP 在图像分类和物体检测方面的成功,作者在 DeepLabv2 中提出了用于语义分割的 ASPP 模块。v2 和 v3 模型均使用 SPP 中的空洞卷积作为上下文模块,以结合多尺度上下文来细化特征图。ASPP 方案并行采用四个空洞卷积层。在从骨干提取的特征图之上,使用不同的空洞率相当于使用具有互补有效视场的多个过滤器探测原始图像,从而以多个尺度捕获物体和有价值的图像背景。 每个提取的特征在单独的分支中进一步处理并融合以生成最终结果。
DeepLabv3 中使用的 ASPP 模块所做的修改如下:
- 添加了“图像池化”模块,该模块使用全局平均池化操作来编码全局上下文信息。
- 在 ASPP 中使用批量标准化。
- 使用一个 1×1 和三个 3×3 卷积。对于 3×3 核,当输出步长为 16 时,扩张率设置为 (6, 12, 18)。对于输出步长为 8 时,扩张率加倍。
- 每个卷积层使用 256 个输出通道。即使是图像池化的输出也首先经过 1×1 卷积层以减少通道数量。
- 所有分支产生的特征图被连接起来并通过另一个(1×1,256)卷积(和批量标准化),然后生成最终的输出。

为什么 ASPP 有用?
- 多尺度信息融合:有的物体很大(比如建筑),有的很小(比如路灯),用不同空洞率可以同时关注它们。
- 保持空间分辨率:空洞卷积不会像池化那样丢掉空间信息。
- 上下文理解更强:全局平均池化能捕捉整张图的语义背景(比如“这是一张城市街景图”)。
3. DeepLabv3+
DeepLabv3+ 是 DeepLabv3 的增强版,增加了一个 解码器模块(Decoder) 来更好地还原边界细节,使得分割更加精细,尤其适用于复杂背景下的小物体。
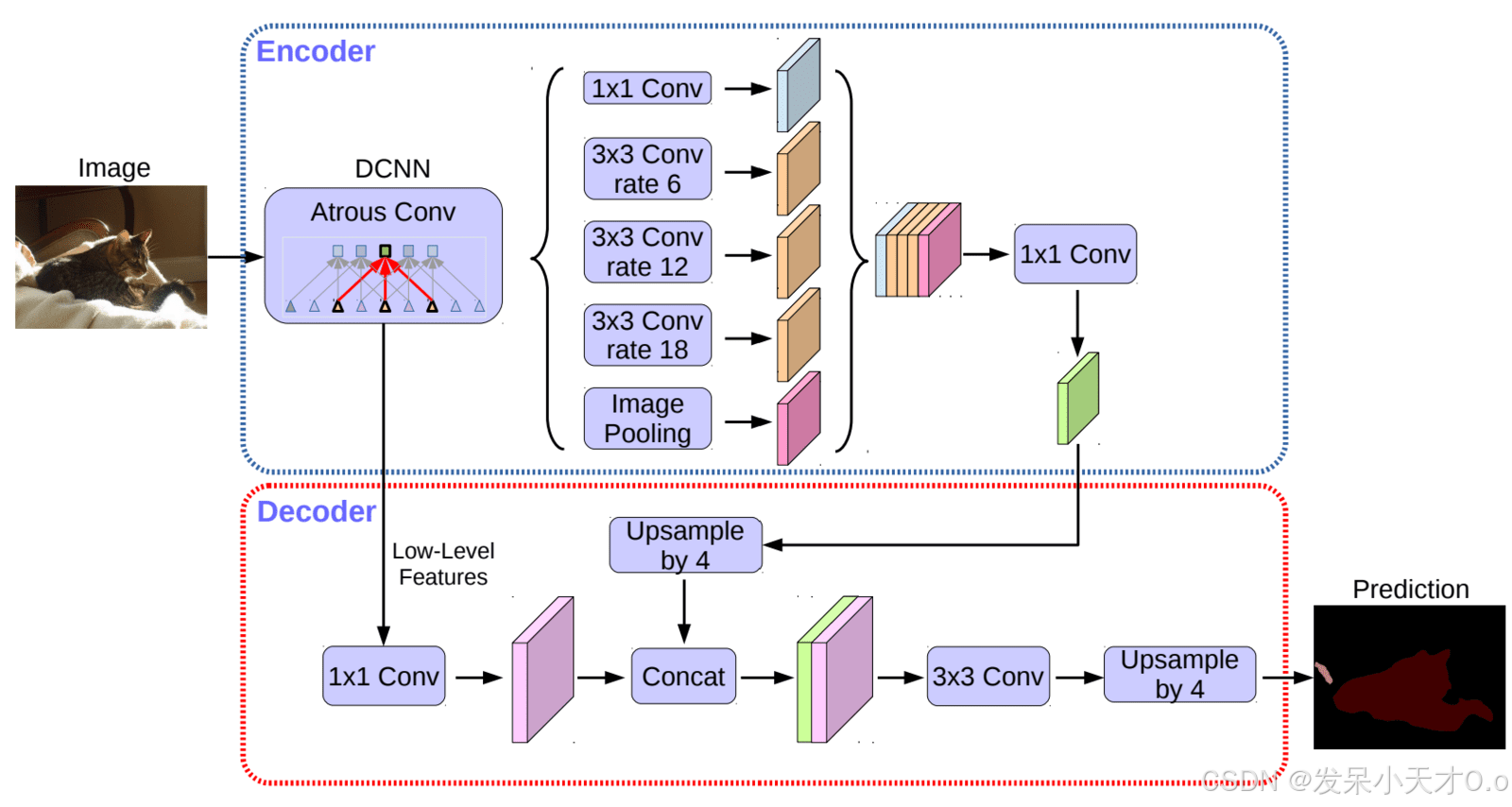
骨干
- DeepLabv3+ 用的是经过改进的 Xception 网络,叫 Aligned Xception,作为骨干网络,用来提取特征。它比原始 Xception 计算更快,同时保持或提高了准确性。
- 原版 Xception 网络里有一个叫 Entry Flow(入口流) 的部分,它负责初步提取图像特征。DeepLabv3+ 并没有对这个部分做和原始 Xception 一样的更新。并且所有下采样(最大池化)块都被深度可分离卷积取代。这允许使用建议的“空洞可分离卷积”,它有助于以任意分辨率提取特征图。
- 每个 3×3 深度可分离卷积之后都有批量标准化和 ReLU 激活层。
编码器
DeepLabv3+ 使用 DeepLabv3 模型作为编码器。最后一个特征图(logits 之前)的输出用作编码器-解码器结构的输入。
解码器
- DeepLabv3 通常以输出特征图 OS=16,该特征图具有丰富的语义信息。
- 从主干的浅层(靠近输入)中取出另一个特征图,并对其进行 1×1 卷积以减少通道数。这个低级特征图具有丰富的空间信息。
- 编码器的输出首先以 4 倍的倍数进行双线性上采样。
- 来自 (1) 和 (2) 的两个特征图被连接起来并通过两个 3×3 卷积块。
- 合并允许使用高空间信息(对象边界)来细化编码器特征图。
- 最后,为了生成预测,对细化的特征图进行 4 倍双线性上采样。
这就是与 DeepLabv3+ 所做的架构更改相关的所有细节。












