用到的库:BeautifulSoup
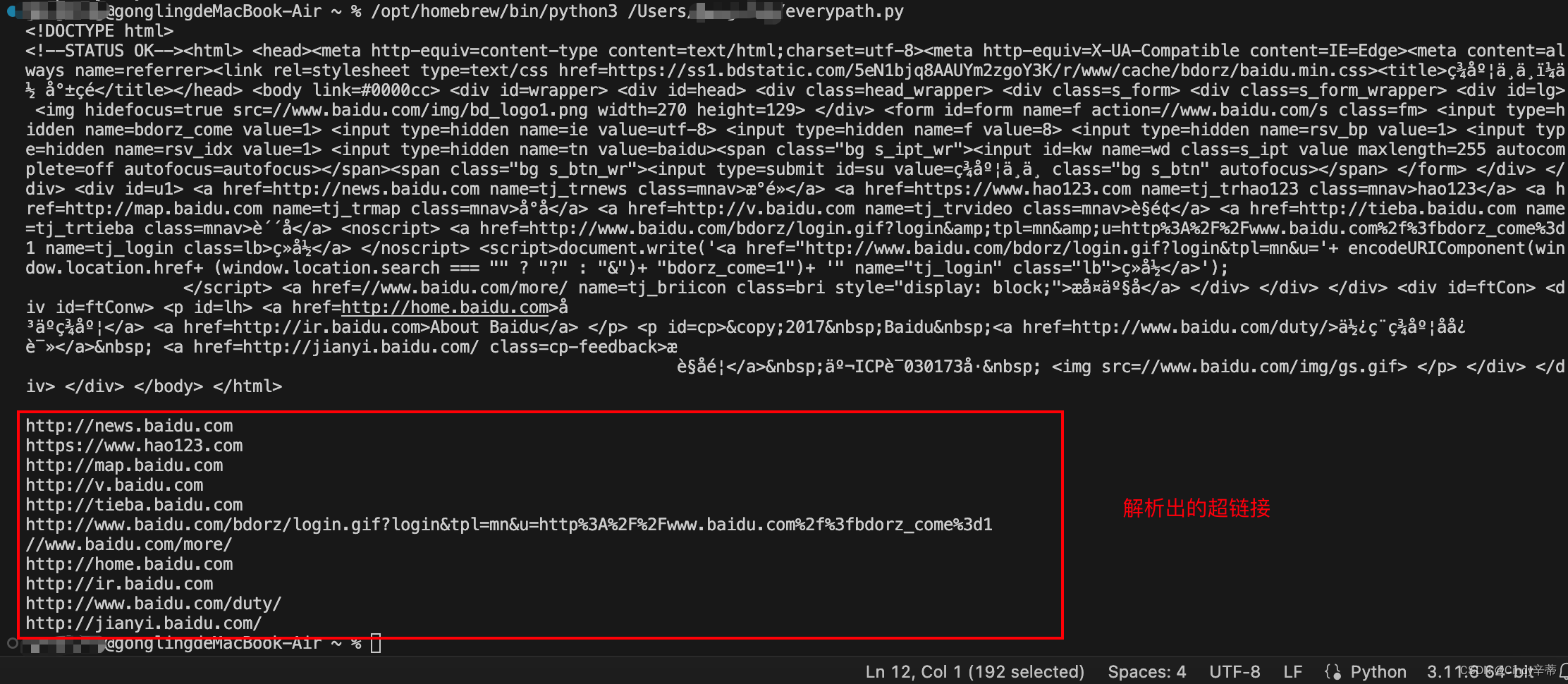
实现效果:爬取网站内容,拿到html文本并解析html文本
代码:
先爬取
# 先导入requests包
import requests
url='https://www.baidu.com'
response=requests.get(url)
# 做1个断言,如果执行成功,拿到html文本
if response.status_code==200:html_content=response.textprint(html_content)
else:print(f'访问失败,状态码是{response.status_code}')
再解析(需要和前面的代码一起执行)
# 导入BeautifulSoup包
from bs4 import BeautifulSoup
# 解析html内容
soup=BeautifulSoup(html_content,'html.parser')
# 提取网页里面的超链接
links=soup.find_all('a')
for link in links:print(link.get('href'))代码效果