
慢查询指在Redis中执行时间超过预设阈值的命令,其日志记录是排查性能瓶颈的核心工具。Redis采用单线程模型,任何耗时操作都可能阻塞后续请求,导致整体性能下降。
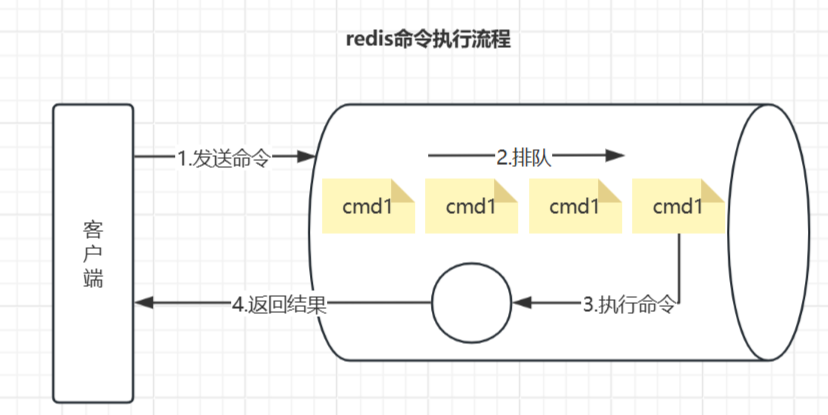
命令的执行流程
根据Redis的核心机制,命令执行流程可分为以下步骤:
- 客户端发送命令
客户端将用户输入的命令(如 SET key value)序列化为Redis协议格式(RESP),通过Socket发送到服务器。
关键耗时点:网络传输时间(RTT)、序列化时间(取决于命令复杂度)。
- 服务端接收与解析
服务器读取Socket数据到客户端的输入缓冲区(querybuf),解析出命令参数(argv和argc),然后放入命令的执行队列。
关键步骤:命令合法性校验(如参数个数、权限检查)和查找命令表(redisCommand 结构)。
- 命令执行
根据命令在命令表中找到对应的实现函数(如setCommand),执行核心逻辑(如数据读写)。
唯一被慢查询记录的耗时阶段:此阶段的执行时间(微秒级)会被记录到慢查询日志。
- 返回结果与清理
将执行结果写入客户端输出缓冲区,通过Socket返回给客户端,并清理缓冲区和连接状态。
关键耗时点:结果反序列化、网络传输时间(不包含在慢查询日志中)。
核心配置参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
slowlog-log-slower-than | 10ms | 执行时间阈值(微秒),设为0记录所有命令,负数则关闭记录 |
slowlog-max-len | 128 | 日志最大存储条数,采用 FIFO 机制淘汰旧日志 |
$ cat /etc/redis/redis.conf | grep slowlog
slowlog-log-slower-than 10000
slowlog-max-len 128
生产建议:阈值设为1ms(1000μs),日志长度≥512条以覆盖更多历史记录。
动态修改配置参数
上面的参数可以直接修改/etc/redis/redis.conf配置文件,然后重启redis服务。
同时redis提供了一种不重启服务动态修改配置参数的方式。
127.0.0.1:6379> config set slowlog-log-slower-than 1000
OK127.0.0.1:6379> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "1000"127.0.0.1:6379> config set slowlog-max-len 512
OK127.0.0.1:6379> config get slowlog-max-len
1) "slowlog-max-len"
2) "512"
最后需要将配置持久化到配置文件中,否则重启就恢复成默认配置参数了。
127.0.0.1:6379> config rewrite
OK
然后去配置文件中查看,发现修改成功了。
$ cat /etc/redis/redis.conf | grep slow
slowlog-log-slower-than 1000
slowlog-max-len 512
慢查询日志查看与分析
127.0.0.1:6379> slowlog help1) SLOWLOG <subcommand> [<arg> [value] [opt] ...]. Subcommands are:2) GET [<count>]3) Return top <count> entries from the slowlog (default: 10). Entries are4) made of:5) id, timestamp, time in microseconds, arguments array, client IP and port,6) client name7) LEN8) Return the length of the slowlog.9) RESET
10) Reset the slowlog.
11) HELP
12) Prints this help.
慢查询的日志可以通过如下命令:
SLOWLOG GET [n] # 查看最近n条慢日志(不指定n则返回全部)
日志字段说明:
- timestamp:命令执行时间戳
- duration:耗时(微秒)
- command:完整命令及参数
为了看到慢查询日志的效果,我们这里先将slowlog-log-slower-than文件参数改为0,这样所有的命令都会记录到慢查询中。
# 改为0,记录所有命令
127.0.0.1:6379> config set slowlog-log-slower-than 0
OK# 将日志重置
127.0.0.1:6379> slowlog reset
OK127.0.0.1:6379> set k1 v1
OK127.0.0.1:6379> set k2 v2
OK# 查询慢查询日志
127.0.0.1:6379> slowlog get
1) 1) (integer) 122) (integer) 17414932153) (integer) 74) 1) "set"2) "k2"3) "v2"5) "127.0.0.1:55264"6) ""
2) 1) (integer) 112) (integer) 17414932103) (integer) 64) 1) "set"2) "k1"3) "v1"5) "127.0.0.1:55264"6) ""
3) 1) (integer) 102) (integer) 17414932053) (integer) 34) 1) "slowlog"2) "reset"5) "127.0.0.1:55264"6) ""# 慢查询的数量
127.0.0.1:6379> slowlog len
(integer) 4
慢查询的常见原因
- 高复杂度命令
-
问题:使用时间复杂度为O(N)或更高的命令(如
KEYS *、SORT、SUNION、ZUNIONSTORE),尤其当数据量较大时,会导致CPU资源消耗过高,执行时间显著增加。 -
示例:
KEYS *遍历所有键,时间复杂度 O(N),可能阻塞Redis服务。
- BigKey操作
-
问题:对存储大量数据的Key(如百万级列表、哈希表)进行读写或删除操作(如
DEL、GET),会因内存分配/释放耗时过长而阻塞主线程,BigKey可以通过命令redis-cli --bigkeys -i 0.01查找。 -
示例:删除一个存储100万条数据的列表时,直接使用
DEL可能导致服务暂停。
- 集中过期Key
-
问题:大量Key在同一时间段过期,触发Redis主动删除机制(默认每100ms随机扫描20个Key),若过期比例超过25%,会循环扫描直至完成,导致主线程阻塞。
-
表现:周期性延迟突增,尤其在业务高峰期。
- 持久化与后台进程影响
-
AOF刷盘:若配置
appendfsync always或everysec,频繁刷盘可能导致磁盘I/O压力增大,影响主线程性能。 -
Fork操作:执行RDB快照或AOF重写时,fork子进程拷贝内存页表,若实例内存过大(如超过10GB),会导致主线程阻塞(耗时可能达秒级)。
- 外部环境问题
-
网络延迟:客户端与Redis服务器间的网络不稳定,导致请求响应时间变长。
-
资源竞争:CPU被其他进程占用(Redis单线程依赖CPU),或物理内存不足触发Swap交换,降低性能。
慢查询的优化策略
- 命令与数据结构优化
-
避免高复杂度命令:用
SCAN替代KEYS,客户端聚合数据替代SORT,分页处理大数据(如LRANGE分页读取)。 -
拆分BigKey:将大Key拆分为多个小Key(如分片列表),或使用渐进式删除(通过Lua脚本分批次删除)。
-
批量操作:使用
MGET、MSET减少网络往返,或通过管道(Pipeline)合并多个命令。
- 配置调优
-
慢查询日志:调整
slowlog-log-slower-than(建议 1ms)和slowlog-max-len(建议 512),定期分析日志定位瓶颈。 -
内存与持久化:
-
开启
lazy-free机制(lazyfree-lazy-expire yes),后台异步释放BigKey内存。 -
根据业务需求选择AOF刷盘策略(如
everysec平衡性能与安全),避免与RDB同时运行。
-
- 资源与环境优化
-
分散Key过期时间:为Key的过期时间添加随机偏移,避免集中过期(例如
expireat key (base_time + random(500)))。 -
集群与分片:使用Redis Cluster或代理分片(如 Codis)分散负载,降低单节点压力。
-
监控与告警:通过
INFO命令、SLOWLOG GET或Prometheus+Grafana监控内存、CPU、命令耗时等指标。
- 运维最佳实践
-
控制实例内存:单实例内存建议不超过10GB,减少fork耗时。
-
预热缓存:在业务高峰前预加载热点数据,避免缓存穿透/击穿。
-
使用连接池:减少频繁建立连接的开销,提升吞吐量。












