
通过循环和迭代数据,我们可以对数据集整体进行操作,也就是可以对数据集中的每一个值,实现我们想要的各种类型的操控。
循环和迭代,简单来说,是同一个意思。也就是运用python的循环控制语句,来对我们的原始数据集,进行全量的操控。这可以实现对每一行,每一列的每一个值,进行灵活的操作处理。
所以,掌握好循环和迭代的编程语句,可以让我们灵活自由的对整个数据集,进行所需的各种操作,是精确控制数据集的基础。
在python语言中,主要是通过for循环语句,以及dataframe的items()函数,iterrows()函数,来对我们需要处理的数据集,实现循环和迭代操作。
生成dataframe原始数据集
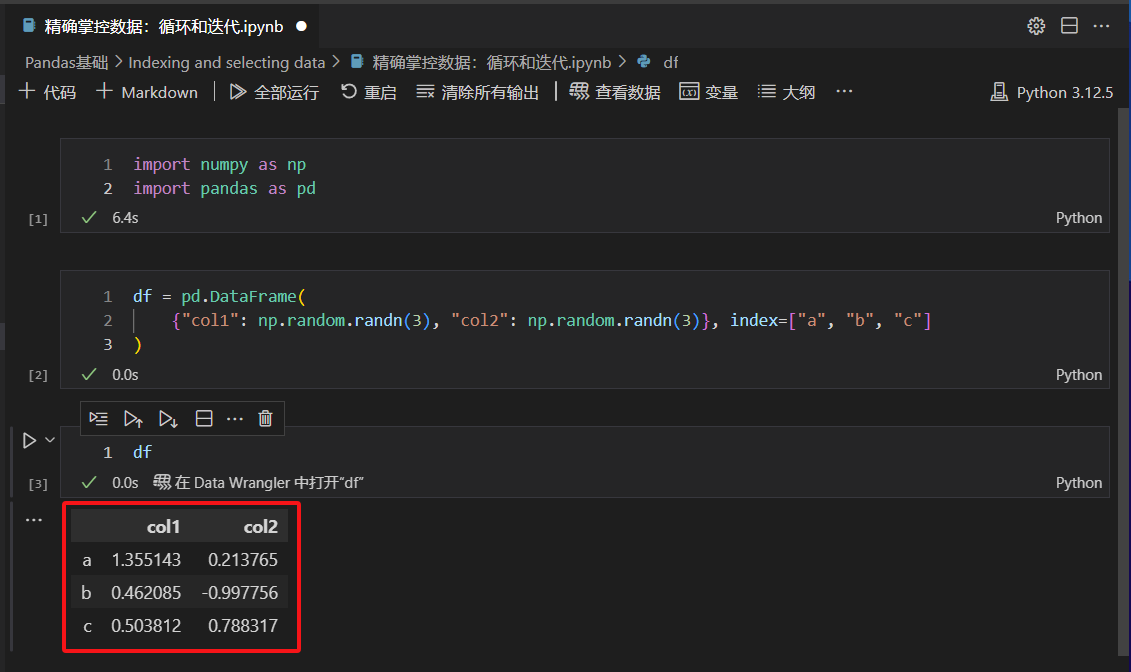
注意数据集的行和列的结构
使用for语句
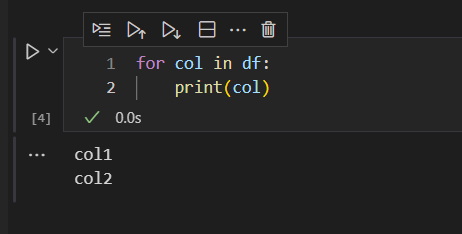
这里要注意两个地方:
首先,for语句循环显示的是列名称。也就是说,使用for语句对dataframe数据集进行循环的话,我们可以拿到数据集的列名称。
其次,要注意for语句冒号后面,第二行程序的缩进。一般来说,是通过4个空格实现for语句的缩进,不能使用Tab制表键。
使用iterrows()函数
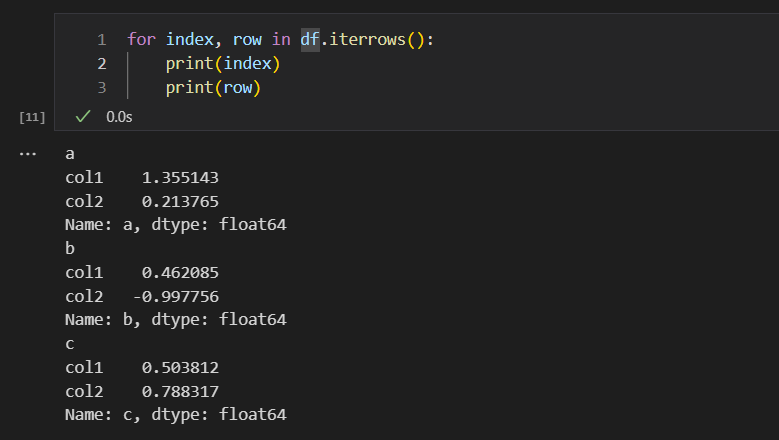
通过iterrows()函数,我们可以拿到dataframe数据集的行索引,以及每行的值。也就是说,我们可以实现对每一行,以及每一行里面的数值,进行循环处理。
这里要注意一下,iterrows()函数循环拿到的index,是字符类型。而row的话,则是series类型,表示一行的数值。
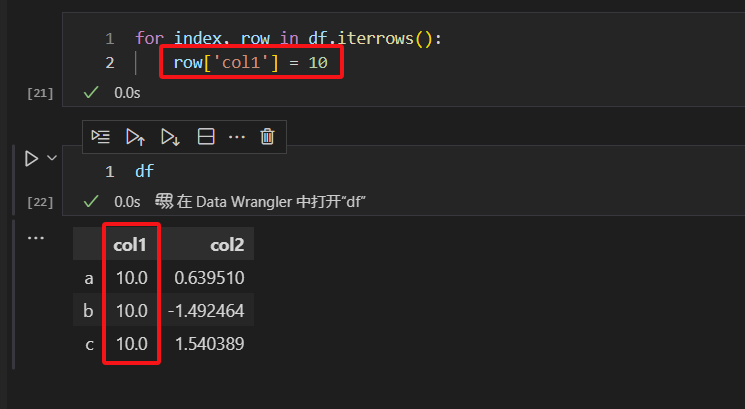
我们看下图中的程序语句
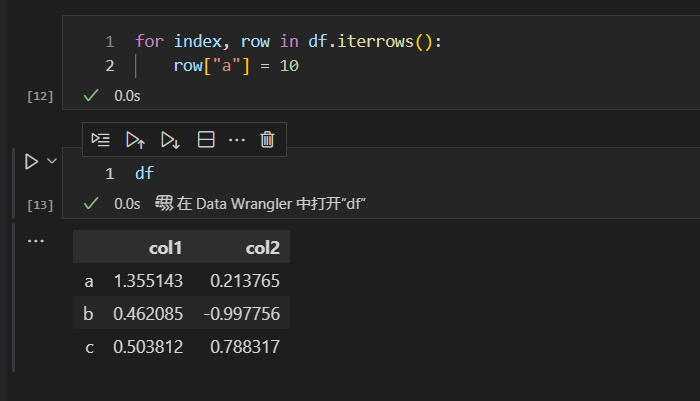
这里有个重点,iterrows()函数循环拿到的row,是原始数据集的一个拷贝。也就是说,改变row的话,不会改变原始数据集中的值。
但是,我们通过row的列索引,改变行和列对应的数值的话,是会改变原始数据集中的数据。
使用items()函数
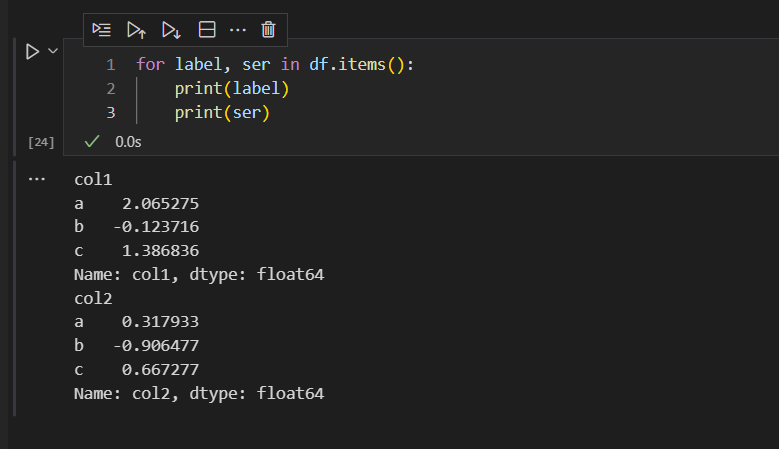
items()函数和iterrows()函数,正好是反转过来。iterrows()函数的index是行索引,row是每一行对应的列索引和值。而items()函数的label,是列索引,ser是每一列的行索引,对应的值。
简单来说,iterrows()函数是对行进行操作的,items()函数是对列进行操作的。
总结
循环和迭代,是对数据集操作的重要方式,可以使我们灵活的处理数据集。我们对数据集的绝大部分处理,都需要借助循环和迭代来实现。
所以,掌握好循环和迭代的语句和函数,是后续处理复杂数据集的基础,也是数据分析的重点。












