
论文信息
该论文题为《Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation》,由Zhenliang Ni、Xinghao Chen、Yingjie Zhai、Yehui Tang和Yunhe Wang于2024年5月10日发表,主要探讨了一种新的语义分割框架CGRSeg,该框架基于上下文引导的空间特征重建,旨在提高语义分割的效率和准确性。
- 论文链接:https://arxiv.org/pdf/2405.06228
- 代码:https://github.com/nizhenliang/CGRSeg
创新点
-
矩形自校准模块(RCM):
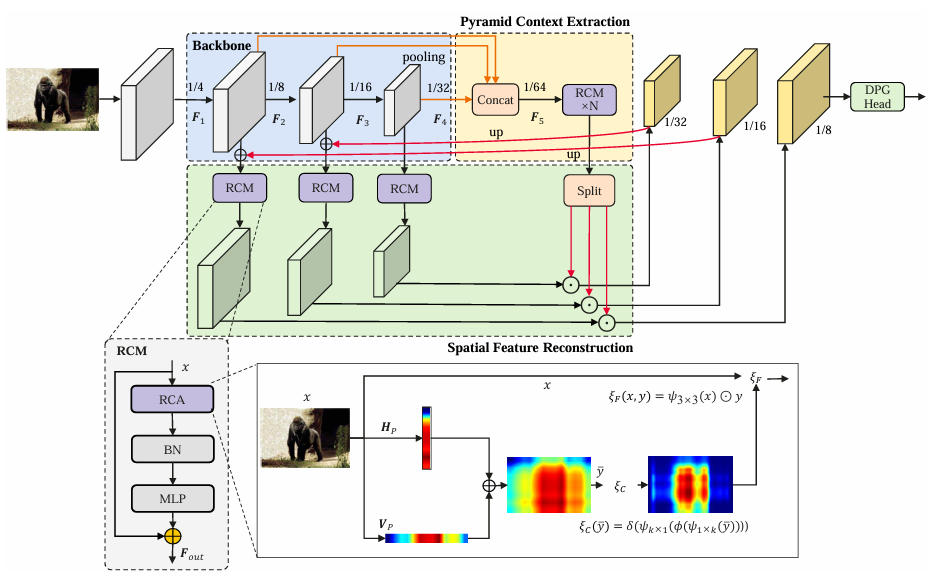
- 该模块用于空间特征重建和金字塔上下文提取,能够在水平和垂直方向上捕获全局上下文,明确建模矩形关键区域。
- 设计了形状自校准函数,使得关键区域更接近前景对象,从而提高分割精度。
-
动态原型引导头(DPG Head):
- 通过显式类嵌入来改善前景对象的分类,增强了模型对不同类别的区分能力。
- 该头部设计轻量,能够在保持较低计算成本的同时,显著提升分类性能。
方法
-
空间特征重建:
- CGRSeg结合了低级空间特征和高级特征,通过RCM进行重建,确保模型能够更好地关注前景对象。
- RCM通过捕获轴向全局上下文来建模矩形区域,并利用形状自校准函数调整注意力区域,使其更贴近前景。
-
金字塔上下文提取:
- 采用金字塔特征来指导空间特征重建,使得重建的特征能够感知多尺度信息。
- 采用金字塔特征来指导空间特征重建,使得重建的特征能够感知多尺度信息。
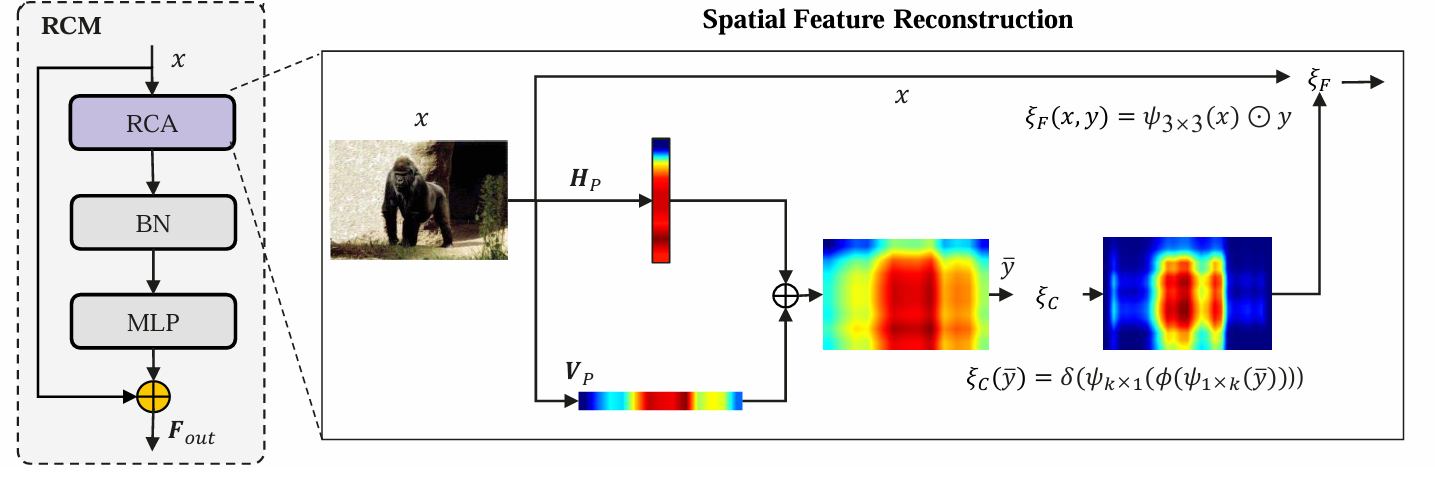
矩形自校准模块(RCM)在空间特征重建中的实现
RCM的设计目的
矩形自校准模块(Rectangular Self-Calibration Module, RCM)旨在提高语义分割模型对前景对象的关注能力,通过有效的空间特征重建来增强模型的表现。RCM通过捕获全局上下文信息,帮助模型更好地定位和识别图像中的关键区域。
实现机制
-
全局上下文捕获:
- RCM能够在水平和垂直方向上捕获全局上下文信息。这种双向的上下文捕获使得模型能够更全面地理解图像中的空间关系,从而更准确地重建特征。
-
矩形关键区域建模:
- RCM明确建模矩形关键区域,通过对特征进行重构,使得模型能够专注于前景对象。具体来说,RCM使用了形状自校准函数来调整注意力区域,使其更接近前景对象的实际形状。
-
特征融合:
- 在空间特征重建过程中,RCM将低级空间特征与高级特征进行融合。通过这种融合,模型能够结合不同层次的信息,从而提高特征的表达能力。
-
金字塔上下文提取:
- RCM还负责金字塔上下文的提取,利用多尺度特征来增强模型对不同尺度前景对象的识别能力。通过对不同尺度的特征进行交互,RCM能够提取出更具语义信息的特征。
-
形状自校准函数:
- 该函数的设计使得关键区域的形状能够动态调整,以更好地适应前景对象的实际形态。这一过程通过对特征进行大核条带卷积来实现,确保模型能够灵活应对不同形状的前景对象。
效果
- CGRSeg在多个基准数据集上进行了广泛评估,包括ADE20K、COCO-Stuff和Pascal Context,取得了最先进的语义性能。
- 在ADE20K数据集上,CGRSeg达到了43.6%的mIoU(平均交并比),仅使用4.0 GFLOPs的计算量,相比于SeaFormer和SegNeXt分别提高了0.9%和2.5%的mIoU,同时计算量减少了约38.0%[6][9]。
实验结果
- 论文中详细列出了与其他先进方法的比较,展示了CGRSeg在mIoU和计算效率上的优势。具体实验结果如下:
| 方法 | mIoU (%) | FLOPs (G) | 参数 (M) |
|---|---|---|---|
| CGRSeg-T | 54.1 | 4.0 | 9.4 |
| CGRSeg-B | 56.5 | 7.6 | 18.1 |
| CGRSeg-L | 58.5 | 14.9 | 35.7 |
- 通过对RCM和DPG头的消融实验,验证了各个组件对整体性能的贡献。
总结
CGRSeg框架通过引入上下文引导的空间特征重建和轻量级的动态原型引导头,显著提升了语义分割的效率和准确性。该方法在多个标准数据集上表现出色,展示了在有限计算资源下实现高性能语义分割的潜力。未来的研究可以进一步探索如何优化模型结构,以适应更复杂的场景和应用需求。
代码
from functools import partialimport torch
import torch.nn as nnfrom timm.layers import DropPath
from timm.layers.helpers import to_2tupleclass ConvMlp(nn.Module):""" MLP using 1x1 convs that keeps spatial dimscopied from timm: https://github.com/huggingface/pytorch-image-models/blob/v0.6.11/timm/models/layers/mlp.py"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU,norm_layer=None, bias=True, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresbias = to_2tuple(bias)self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, bias=bias[0])self.norm = norm_layer(hidden_features) if norm_layer else nn.Identity()self.act = act_layer()self.drop = nn.Dropout(drop)self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1, bias=bias[1])def forward(self, x):x = self.fc1(x)x = self.norm(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)return xclass RCA(nn.Module):def __init__(self, inp, kernel_size=1, ratio=1, band_kernel_size=11, dw_size=(1, 1), padding=(0, 0), stride=1,square_kernel_size=2, relu=True):super(RCA, self).__init__()self.dwconv_hw = nn.Conv2d(inp, inp, square_kernel_size, padding=square_kernel_size // 2, groups=inp)self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))gc = inp // ratioself.excite = nn.Sequential(nn.Conv2d(inp, gc, kernel_size=(1, band_kernel_size), padding=(0, band_kernel_size // 2), groups=gc),nn.BatchNorm2d(gc),nn.ReLU(inplace=True),nn.Conv2d(gc, inp, kernel_size=(band_kernel_size, 1), padding=(band_kernel_size // 2, 0), groups=gc),nn.Sigmoid())def sge(self, x):# [N, D, C, 1]x_h = self.pool_h(x)x_w = self.pool_w(x)x_gather = x_h + x_w # .repeat(1,1,1,x_w.shape[-1])ge = self.excite(x_gather) # [N, 1, C, 1]return gedef forward(self, x):loc = self.dwconv_hw(x)att = self.sge(x)out = att * locreturn outclass RCM(nn.Module):""" MetaNeXtBlock BlockArgs:dim (int): Number of input channels.drop_path (float): Stochastic depth rate. Default: 0.0ls_init_value (float): Init value for Layer Scale. Default: 1e-6."""def __init__(self,dim,token_mixer=RCA,norm_layer=nn.BatchNorm2d,mlp_layer=ConvMlp,mlp_ratio=2,act_layer=nn.GELU,ls_init_value=1e-6,drop_path=0.,dw_size=11,square_kernel_size=3,ratio=1,):super().__init__()self.token_mixer = token_mixer(dim, band_kernel_size=dw_size, square_kernel_size=square_kernel_size,ratio=ratio)self.norm = norm_layer(dim)self.mlp = mlp_layer(dim, int(mlp_ratio * dim), act_layer=act_layer)self.gamma = nn.Parameter(ls_init_value * torch.ones(dim)) if ls_init_value else Noneself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):shortcut = xx = self.token_mixer(x)x = self.norm(x)x = self.mlp(x)if self.gamma is not None:x = x.mul(self.gamma.reshape(1, -1, 1, 1))x = self.drop_path(x) + shortcutreturn xif __name__ == "__main__":# 定义输入张量大小(Batch、Channel、Height、Wight)B, C, H, W = 2, 64, 40, 40input_tensor = torch.randn(B, C, H, W) # 随机生成输入张量# 初始化 SAFMdim = C # 输入和输出通道数# 创建 SAFM 实例block = RCM(dim=dim)# 如果GPU可用将模块移动到 GPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")sablock = block.to(device)print(sablock)input_tensor = input_tensor.to(device)# 执行前向传播output = sablock(input_tensor)# 打印输入和输出的形状print(f"Input: {input_tensor.shape}")print(f"Output: {output.shape}")
代码详解:
这段代码定义了两个主要的神经网络模块:RCA(Regional Context Aggregation)和RCM。这些模块可能用于图像识别或其他视觉任务中,旨在通过特定的注意力机制和混合操作增强模型的特征提取能力。下面是对这两个模块的详细解析:
RCA 模块
RCA模块旨在通过聚合区域上下文信息来增强特征表示。它主要包括以下几个部分:
-
深度可分离卷积(Depthwise Separable Convolution):使用
nn.Conv2d实现,其中groups=inp表示每个输入通道独立进行卷积操作,这有助于减少计算量同时保持特征多样性。square_kernel_size定义了卷积核的大小。 -
自适应平均池化(Adaptive Average Pooling):分别沿高度和宽度方向进行自适应平均池化,以提取水平和垂直方向上的全局上下文信息。
-
激励(Excitation)机制:通过两个
nn.Conv2d层,分别对高度和宽度方向的特征进行加权处理,模拟SE(Squeeze-and-Excitation)模块的功能,但采用了非对称的卷积核大小(kernel_size=(1, band_kernel_size)和kernel_size=(band_kernel_size, 1)),以捕捉不同方向上的特征重要性。 -
Sigmoid激活函数:用于将激励机制的输出归一化到0到1之间,作为注意力权重。
RCM 模块
RCM模块可能是一个结合了RCA模块和其他组件的复合模块,用于构建更复杂的神经网络架构。它包含以下部分:
-
Token Mixer(使用RCA):通过
RCA模块进行区域上下文聚合,增强特征表示。 -
归一化层:使用
norm_layer(默认为nn.BatchNorm2d)对特征进行归一化处理,有助于加速训练过程并提高模型稳定性。 -
MLP(Multi-Layer Perceptron)层:一个可选的多层感知机模块,用于进一步处理特征。这里使用了一个自定义的
ConvMlp类(未在代码中定义),它可能结合了卷积层和全连接层的特性。 -
Layer Scale:一个可选的层缩放机制,通过引入一个可学习的参数
gamma来调整特征的尺度,有助于训练深层网络。 -
DropPath:一个随机丢弃路径的正则化方法,用于减少过拟合。当
drop_path参数大于0时启用。 -
残差连接:将输入
x与经过Token Mixer、归一化、MLP处理和Layer Scale调整后的输出相加,形成残差连接,有助于梯度反向传播和深层网络的训练。












