
25年2月来自华中科大和地平线的论文“RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning”。
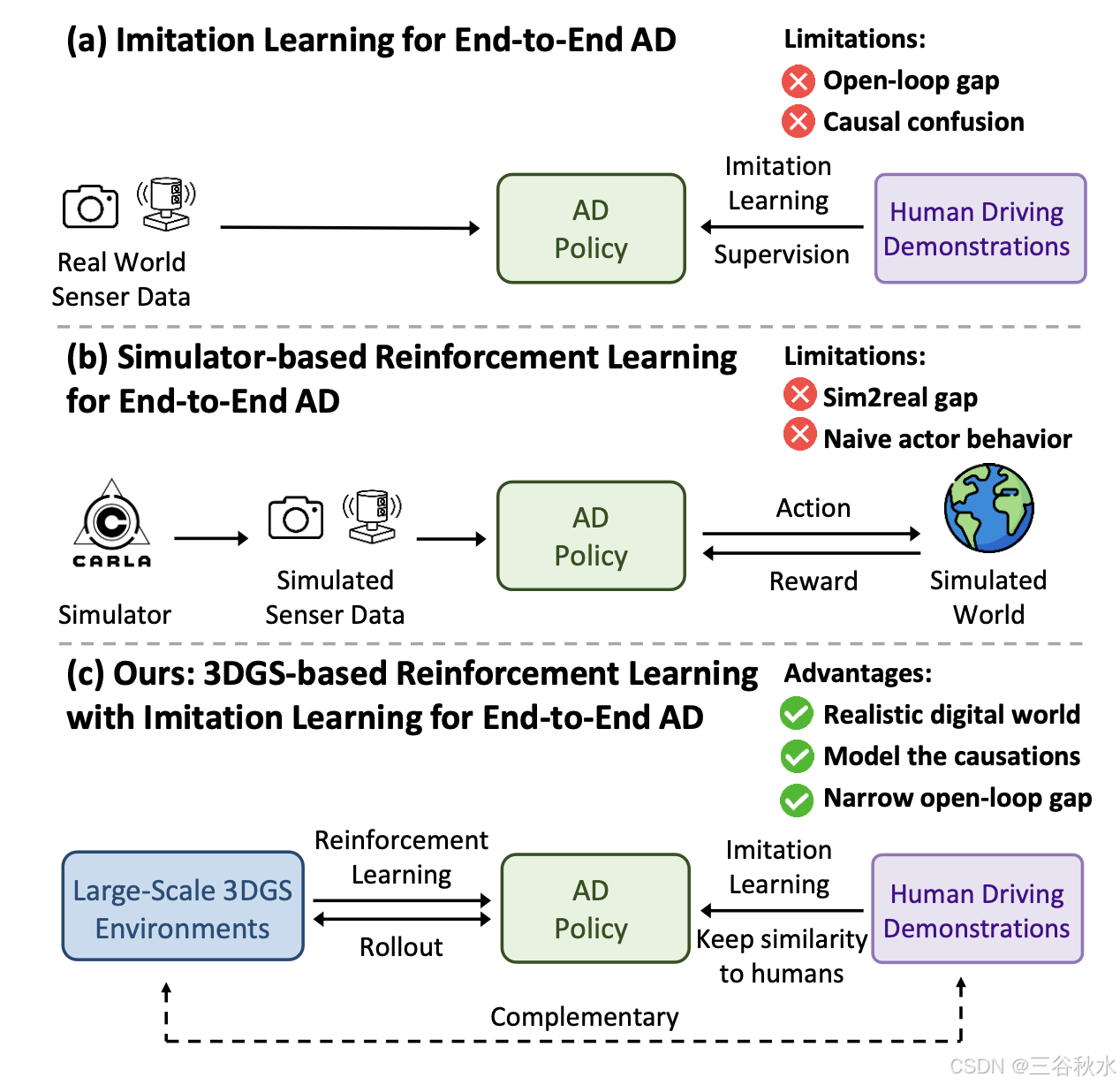
现有的端到端自动驾驶 (AD) 算法通常遵循模仿学习 (IL) 范式,该范式面临着因果混淆和开环间隙等挑战。这项工作建立一个基于 3DGS 的闭环强化学习 (RL) 训练范式。通过利用 3DGS 技术,构建真实物理世界的逼真数字复制,使 AD 策略能够广泛探索状态空间并通过大规模反复试验学习处理分布外(OOD)场景。为了提高安全性,设计专门的奖励,指导策略有效应对安全-紧要事件并理解现实世界的因果关系。为了更好地与人类驾驶行为保持一致,IL 被纳入 RL 训练作为正则化项。其引入一个由各种以前未见过 3DGS 环境组成的闭环评估基准。与基于 IL 的方法相比,RAD 在大多数闭环指标中实现更强的性能,尤其是碰撞率降低 3 倍。
端到端自动驾驶 (AD) 目前是学术界和工业界的热门话题。它通过将感官输入直接映射到驾驶动作,用整体流水线取代模块化流水线,具有系统简单性和泛化能力强的优势。大多数现有的端到端 AD 算法 [2、11、17、22、28、38、43、49] 遵循模仿学习 (IL) 范式,即训练神经网络来模仿人类驾驶行为。然而,尽管基于 IL 的方法很简单,但它们在实际部署中仍面临重大挑战。
一个关键问题是因果混淆。IL 通过从演示中学习来训练网络来复制人类驾驶策略。然而,这种范式主要捕捉的是观察(状态)和动作之间的相关性,而不是因果关系。因此,IL 训练的策略可能难以识别规划决策背后的真正因果因素,从而导致捷径学习 (shortcut learning)[8],例如,仅仅从历史轨迹中推断未来轨迹 [23, 47]。此外,由于 IL 训练数据主要由常见的驾驶行为组成,并且没有充分覆盖长尾分布,因此 IL 训练的策略往往会收敛到平凡的解决方案,对碰撞等安全-紧要事件缺乏足够的敏感性。
另一个主要挑战是开环训练和闭环部署之间的间隙。IL 策略以开环方式训练,使用分布良好的驾驶演示。然而,现实世界的驾驶是一个闭环过程,其中每一步的微小轨迹误差都会随着时间的推移而累积,从而导致复合误差和分布不均的情况。IL 训练的策略在这些未见过的情况下经常会挣扎,这引发人们对其稳健性的担忧。
解决这些问题的一个直接方法,是进行闭环强化学习 (RL) 训练,这需要一个可以与 AD 策略交互的驾驶环境。然而,使用真实世界的驾驶环境进行闭环训练,会带来过高的安全风险和运营成本。具有传感器数据模拟功能 [6, 14](端到端 AD 所必需的)的模拟驾驶环境通常建立在游戏引擎 [7, 39] 上,但无法提供真实的传感器模拟结果。
这项工作建立一个基于 3DGS [18] 的闭环 RL 训练范式, 叫RAD。利用 3DGS 技术,构建现实世界的逼真数字复制,其中 AD 策略可以广泛探索状态空间,并通过大规模反复试验来学习处理分布不均的情况。为了确保有效应对安全-紧要事件并更好地理解现实世界的因果关系,设计专门的安全相关奖励。
如图所示:三种不同端到端自动驾驶训练的范式
端到端驾驶策略
RAD 的整体框架如图所示。RAD 将多视角图像序列作为输入,将传感器数据转换为场景 token 嵌入,输出动作的概率分布,并采样一个动作来控制车辆。
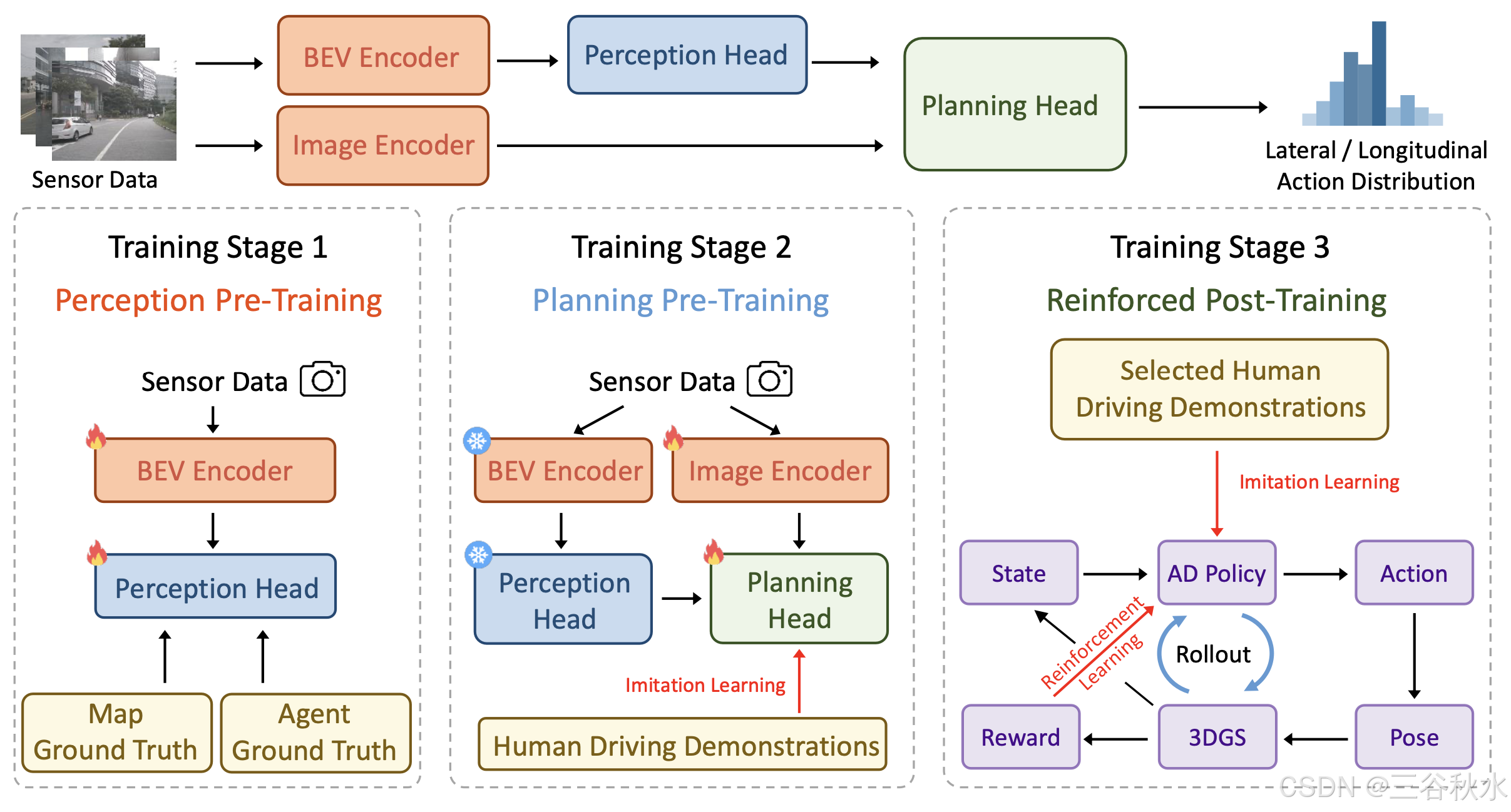
BEV 编码器。首先使用 BEV 编码器 [21] 将多视角图像特征从透视图转换为鸟瞰图 (BEV),从而获得 BEV 空间中的特征图。然后使用此特征图来学习实例级地图特征和智体特征。
地图头。然后,利用一组地图 token [25–27] 从 BEV 特征图中学习驾驶场景的矢量化地图元素,包括车道中心线、车道分隔线、道路边界、箭头、交通信号灯等。
智体头。此外,还采用一组智体 token [15]来预测其他交通参与者的运动信息,包括位置、方向、大小、速度和多模式未来轨迹。
图像编码器。除了上述实例级地图和智体 token 外,还使用单独的图像编码器[5,10]将原始图像转换为图像 token。这些图像 token 为规划提供密集而丰富的场景信息,与实例级 token 相辅相成。
动作空间。为了加速 RL 训练的收敛,设计一个解耦的离散动作表示。将动作分为两个独立的部分:横向动作和纵向动作。动作空间是在0.5秒的短时间范围内构建的,在此期间,通过假设恒定的线速度和角速度来近似车辆的运动。在此假设下,可以根据当前的线速度和角速度直接计算横向动作 ax 和纵向动作 a^y。通过将解耦与有限的时间范围和简化的运动模型相结合,该方法有效地降低动作空间的维数,从而加速训练收敛。
规划头。用 E_scene 表示场景表示,它由地图 token、智体 token 和图像 token 组成。初始化一个表示为 E_plan 的规划嵌入。级联 Transformer 解码器 φ 将规划嵌入 E_plan 作为 Q,将场景表示 E_scene 作为 K 和 V。
然后将解码器 φ 的输出与导航信息 E_navi 和自我状态 E_state 相结合,输出横向动作 ax 和纵向动作 a^y 的概率分布。规划头还输出价值函数 V_x(s) 和 V_y (s),分别估计横向和纵向动作的预期累积奖励。这些价值函数将用于 RL 训练。
训练范式
采用三阶段训练范式:感知预训练、规划预训练和强化后训练,如上图所示。
感知预训练。图像中的信息稀疏且低级。在第一阶段,地图头和智体头显式输出地图元素和智体运动信息,这些信息由真值标签监督。因此,地图token和智体token隐式编码相应的高级信息。在此阶段,仅更新 BEV 编码器、地图头和智体头的参数。
规划预训练。在第二阶段,为防止 RL 训练的不稳定冷启动,首先执行 IL,根据来自专业驾驶员的大规模真实驾驶演示,初始化动作的概率分布。在此阶段,仅更新图像编码器和规划头的参数,而 BEV 编码器、地图头和智体头的参数被冻结。感知任务和规划任务的优化目标可能会相互冲突。然而,随着训练阶段和参数的解耦,这种冲突大多可以避免。
强化后训练。在强化后训练中,RL 和 IL 协同微调分布。RL 旨在引导策略对紧要风险事件敏感并适应分布外的情况。IL 作为正则化项,使策略的行为与人类相似。
从收集的驾驶演示中选择大量有风险的密集交通剪辑。对于每个剪辑,训练一个独立的 3DGS 模型,该模型重建剪辑并作为数字驾驶环境。如图所示,设置 N 个并行 worker。每 worker 随机采样一个 3DGS 环境并开始展开(roll-out),即 AD 策略控制自车移动并与 3DGS 环境进行迭代交互。该 3DGS 环境的展开过程结束后,生成的展开数据(s_t、a_t、r_t+1、s_t+1,…)将记录在展开缓冲区中,然后 worker 将对新的 3DGS 环境进行采样以进行另一轮展开。
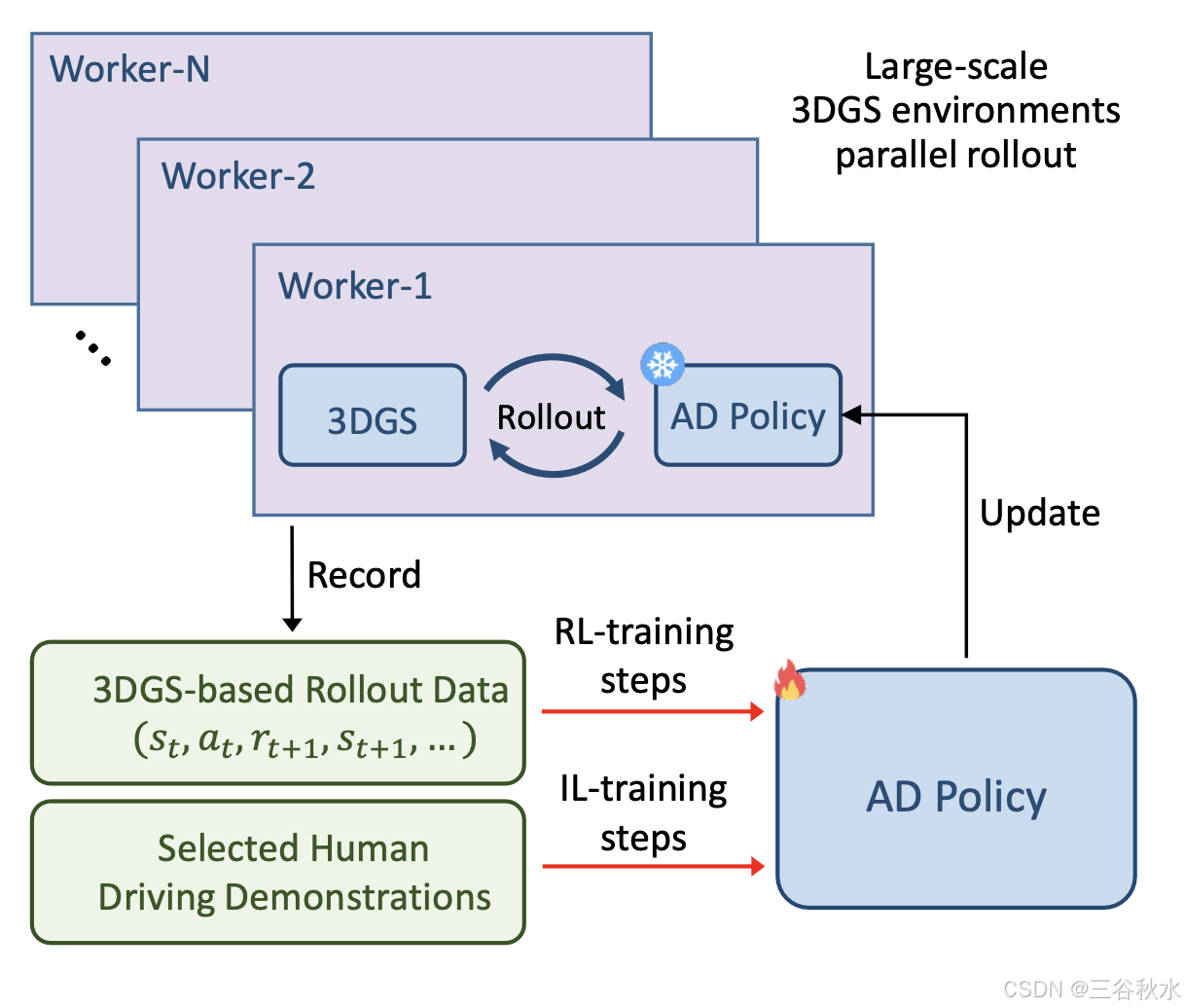
对于策略优化,迭代执行 RL 训练步骤和 IL 训练步骤。对于 RL 训练步骤,从展开缓冲区中采样数据,并遵循近端策略优化 (PPO) 框架 [35] 来更新 AD 策略。对于 IL 训练步骤,使用真实世界的驾驶演示来更新策略。经过固定数量的训练步骤后,更新后的 AD 策略将发送给每个 worker 以替换旧策略,避免数据收集和优化之间的分布偏移。只更新图像编码器和规划头的参数。BEV 编码器、地图头和智体头的参数被冻结。
详细的 RL 设计如下。
AD 策略与 3DGS 环境之间的交互机制
在 3DGS 环境中,自车根据 AD 策略行事。其他交通参与者以日志重放的方式根据真实世界数据行事。采用简化的运动学自行车模型,每 ∆t 秒迭代更新一次自车的姿势,即
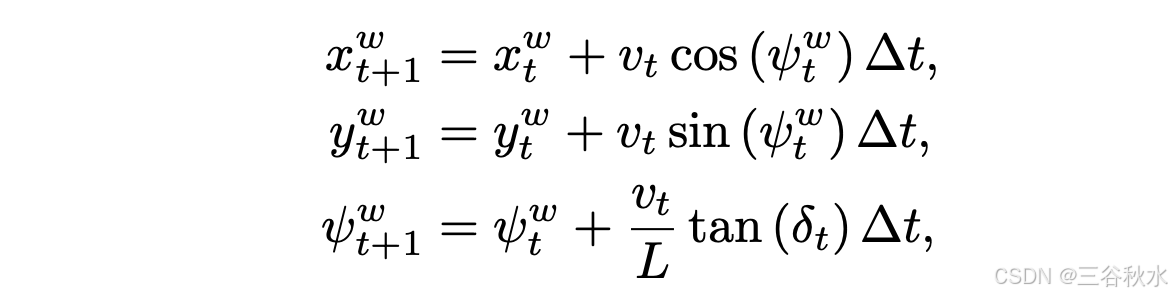
在展开过程中,AD 策略在时间步长 t 处输出 0.5 秒时间范围内的动作 (ax_t , ay_t )。根据 (ax_t , ay_t)得出线速度 v_t 和转向角 δ_t。基于(自行车)运动学模型,自车在世界坐标系中的姿势从 p_t = (xw_t, yw_t, ψw_t) 更新为 p_t+1 = (xw_t+1, yw_t+1, ψ^w_t+1)。
基于更新后的 p_t+1,3DGS 环境计算新的自车状态 s_t+1。更新后的姿态 p_t+1 和状态 s_t+1 作为推理过程下一次迭代的输入。
3DGS 环境还根据多源信息(包括其他智体的轨迹、地图信息、自车的专家轨迹和高斯参数)生成奖励 R,用于优化 AD 策略。
奖励建模
奖励是训练信号的来源,它决定 RL 的优化方向。奖励函数旨在通过惩罚不安全行为和鼓励与专家轨迹保持一致来指导自车的行为。它由四个奖励部分组成:(1)与动态障碍物碰撞,(2)与静态障碍物碰撞,(3)与专家轨迹的位置偏差,以及(4)与专家轨迹的航向偏差:R = {r_dc, r_sc, r_pd, r_hd}。
如图所示,这些奖励组件在特定条件下触发。在 3DGS 环境中,如果自车的边框与动态障碍物的注释边框重叠,则会检测到动态碰撞,从而触发负奖励 r_dc。类似地,当自车辆的边框与静态障碍物的高斯分布重叠时,可识别为静态碰撞,从而产生负奖励 r_sc。位置偏差以自车当前位置与专家轨迹上最近点之间的欧几里得距离来衡量。超过预定义阈值 d_max 的偏差会导致负奖励 r_pd。航向偏差计算为自车辆当前航向角 ψ_t 与专家轨迹匹配的航向角 ψ_expert 之间的角度差。超过阈值 ψ_max 的偏差会导致负奖励 r_hd。

任何这些事件,包括动态碰撞、静态碰撞、过大的位置偏差或过度的航向偏差,都会触发立即终止情节。因为在发生此类事件后,3DGS 环境通常会生成嘈杂的传感器数据,这对 RL 训练是不利的。
策略优化
在闭环环境中,每个步骤中的错误都会随着时间的推移而累积。上述奖励不仅是由当前动作引起的,还由前几步的动作引起。奖励通过广义优势估计 (GAE) [34] 向前传播,以优化前几步的动作分布。
具体来说,对于每个时间步 t,存储当前状态 s_t、动作 a_t、奖励 r_t 和值 V (s_t) 的估计。基于解耦的动作空间,并考虑到不同的奖励与横向和纵向动作具有不同的相关性,奖励r_t分为横向奖励r_tx和纵向奖励r_t^y。
类似地,价值函数V(s_t)被解耦为两个分量:横向维度的V_x(s_t)和纵向维度的V_y(s_t)。这些价值函数分别估计横向和纵向动作的预期累积奖励。然后计算优势估计Aˆ_tx和Aˆ_t^y:
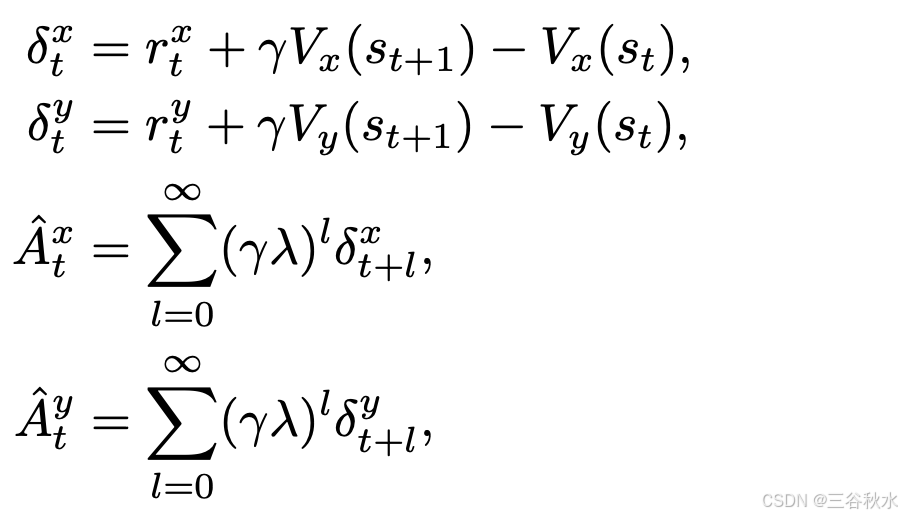
为了进一步阐明优势估计与奖励成分之间的关系,根据奖励分解和优势估计分解Aˆ_tx和Aˆ_ty。 具体来说,推导出以下分解:Aˆ_tx = Aˆ_tsc + Aˆ_tpd + Aˆ_thd, Aˆ_ty = Aˆ_tdc, 其中 Aˆ_tsc 是避免静态碰撞的优势估计,Aˆ_tpd 是最小化位置偏差的优势估计,Aˆ_thd是最小化航向偏差的优势估计,Aˆ_t^dc 是避免动态碰撞的优势估计。
这些优势估计用于指导 AD 策略 π_θ 的更新,遵循 PPO 框架 [35]。通过利用分解的优势估计 Aˆ_tx 和 Aˆ_ty,可以独立优化策略的横向和纵向维度。这是通过为每个维度定义单独的目标函数 L_xCLIP(θ) 和 L_y^CLIP(θ) 来实现的:
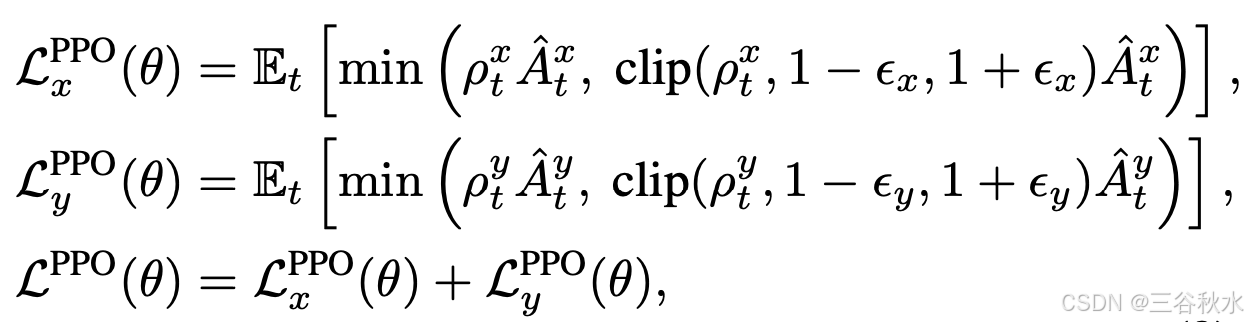
裁剪的目标函数 L^PPO(θ) 可防止对策略参数 θ 进行过大的更新,从而保持训练稳定性。
辅助目标
RL 通常面临稀疏奖励的挑战,这使得收敛过程不稳定且缓慢。为了加快收敛速度,引入辅助目标,为整个动作分布提供密集指导。
辅助目标旨在通过结合特定的奖励源来惩罚不良行为,包括动态碰撞、静态碰撞、位置偏差和航向偏差。这些目标是根据旧的 AD 策略 π_θ_old 在时间步 t 选择的动作 a_t^x,old 和 a_t^y,old 计算的。为了便于评估这些动作,将动作的概率分布分为四个部分:
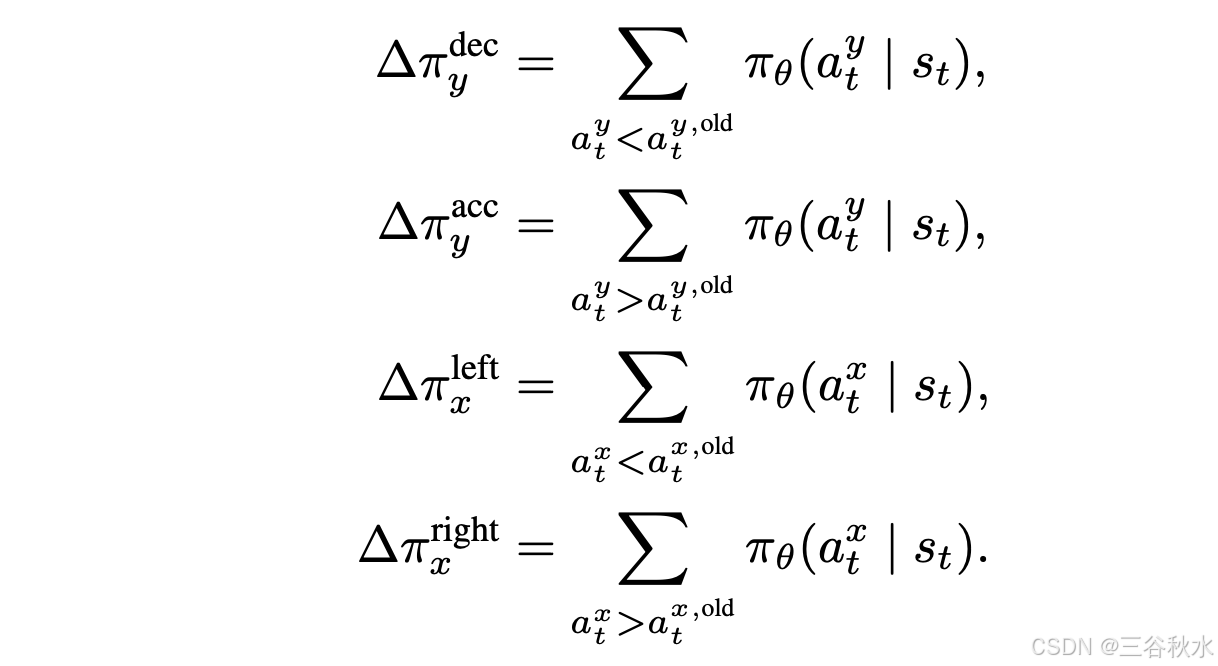
动态碰撞辅助目标。动态碰撞辅助目标,根据潜在碰撞相对于自车的位置,调整纵向控制动作 a_ty。如果在前方检测到碰撞,策略会优先考虑减速动作 (a_ty < a_ty,old);如果在后方检测到碰撞,则鼓励加速动作 (a_ty > a_t^y,old)。为了形式化这种行为,定义一个方向因子 f_dc。这样定义动态碰撞避免的辅助目标 L_dc(θ_y) 。
静态碰撞辅助目标。静态碰撞辅助目标,根据与静态障碍物的接近程度,调整转向控制动作 a_tx。如果在左侧检测到静态障碍物,策略会促进向右转向动作 (a_tx > a_tx,old);如果在右侧检测到静态障碍物,则它会促进向左转向动作(a_tx < a_t^x,old)。为了形式化此行为,定义一个方向因子 f_sc,这样定义静态防撞辅助目标 L_sc(θ_x) 。
位置偏差辅助目标。位置偏差辅助目标,根据自车与专家轨迹的横向偏差,调整转向控制动作 a_tx。如果自车向左偏离,则策略会促进向右修正(a_tx^ > a_tx,old);如果它向右偏离,则它会促进向左修正(a_tx < a_t^x,old)。用方向因子 f_pd 将其形式化,这样定义位置偏差校正辅助目标 L_pd(θ_x) 。
航向偏差辅助目标。航向偏差辅助目标,根据自车当前航向与专家参考航向之间的角度差,调整转向控制动作 a_tx。如果自车逆时针偏离,则策略会促进顺时针修正(a_tx > a_tx,old);如果自车顺时针偏离,则策略会促进逆时针修正(a_tx < a_t^x,old)。为了形式化这种行为,定义一个方向因子 f_hd,然后定义航向偏差校正的辅助目标 L_hd(θ_x)。
总体辅助目标 L_aux(θ) 是各个目标的加权和:L_aux(θ) = λ_1 L_dc(θ_y) + λ_2 L_sc(θ_x) + λ_3 L_pd(θ_x) + λ_4 L_hd(θ_x)。
最终优化目标将裁剪后的 PPO 目标与辅助目标相结合:L(θ) = L^PPO(θ) + L_aux(θ)。
在现实世界中收集 2000 小时的专业人类驾驶演示。通过低成本的自动注释流水线在这些驾驶演示中获得地图和智体的真实信息。使用地图和智体标签作为第一阶段感知预训练的监督。对于第二阶段规划预训练,使用自车的里程表信息作为监督。对于第三阶段强化后训练,从收集的驾驶演示中选择 4305 个具有高碰撞风险的关键密集交通剪辑,并将这些剪辑重建为 3DGS 环境。其中,3968 个 3DGS 环境用于 RL 训练,另外 337 个 3DGS 环境用作闭环评估基准。












