


深度学习中的模型架构详解:RNN、LSTM、TextCNN和Transformer
文章目录
- 深度学习中的模型架构详解:RNN、LSTM、TextCNN和Transformer
- 循环神经网络 (RNN)
- RNN的优点
- RNN的缺点
- RNN的代码实现
- 长短期记忆网络 (LSTM)
- LSTM的优点
- LSTM的缺点
- LSTM的代码实现
- TextCNN
- TextCNN的优点
- TextCNN的缺点
- TextCNN的代码实现
- Transformer
- Transformer的优点
- Transformer的缺点
- Transformer的代码实现
- 结论
在自然语言处理(NLP)领域,模型架构的不断发展极大地推动了技术的进步。从早期的循环神经网络(RNN)到长短期记忆网络(LSTM)、再到卷积神经网络(TextCNN)和Transformer,每一种架构都带来了不同的突破和应用。本文将详细介绍这些经典的模型架构及其在PyTorch中的实现。
循环神经网络 (RNN)
循环神经网络(RNN)是一种适合处理序列数据的神经网络架构。与传统的前馈神经网络不同,RNN具有循环连接,能够在序列数据的处理过程中保留和利用之前的状态信息。
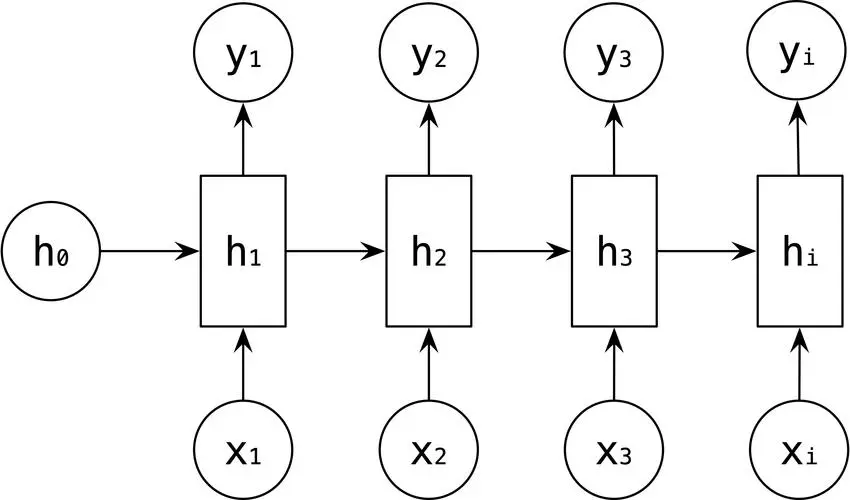
RNN的优点
- 处理序列数据:可以处理任意长度的序列数据,并能够记住序列中的上下文信息。
- 参数共享:在不同时间步之间共享参数,使得模型在处理不同长度的序列时更加高效。
RNN的缺点
- 梯度消失和爆炸:在训练过程中,RNN会遇到梯度消失和梯度爆炸的问题。
- 长距离依赖问题:难以捕捉长距离依赖关系。
RNN的代码实现
import torch
import torch.nn as nnclass TextRNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):super(TextRNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)self.fc = nn.Linear(hidden_dim, num_classes)self.dropout = nn.Dropout(dropout)def forward(self, x):x = self.embedding(x)rnn_out, hidden = self.rnn(x)x = self.dropout(rnn_out[:, -1, :])x = self.fc(x)return x
长短期记忆网络 (LSTM)
LSTM是一种特殊的RNN,旨在解决传统RNN在处理长序列数据时的梯度消失和梯度爆炸问题。LSTM通过引入记忆单元和门控机制,能够更好地捕捉和保留长距离依赖关系。
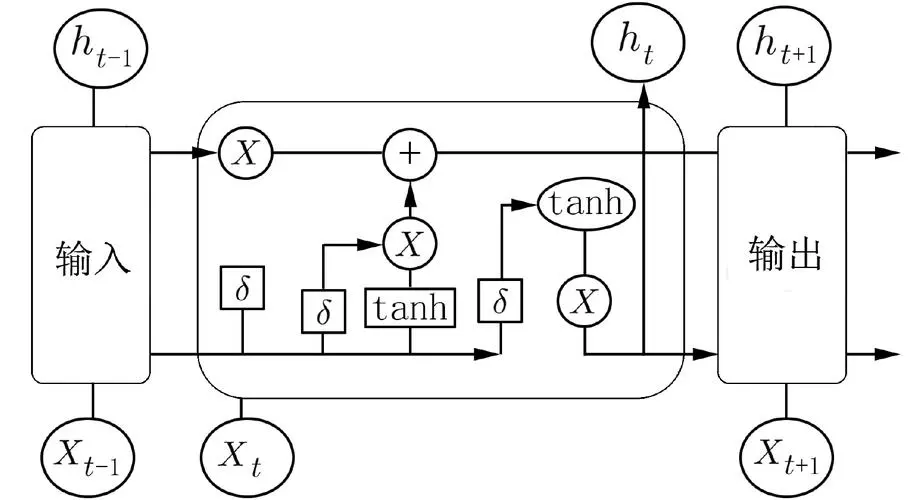
LSTM的优点
解决长距离依赖问题:能够记住长时间跨度内的重要信息。
缓解梯度消失和爆炸问题:通过门控机制,能够更稳定地传递梯度。
LSTM的缺点
计算复杂度高:结构复杂,计算成本高。
难以并行化:顺序计算特性限制了并行化的能力。
LSTM的代码实现
import torch
import torch.nn as nnclass TextLSTM(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):super(TextLSTM, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)batch_size, seq_len, _ = x.shapeh_0 = torch.zeros(self.lstm.num_layers, batch_size, self.lstm.hidden_size).to(x.device)c_0 = torch.zeros(self.lstm.num_layers, batch_size, self.lstm.hidden_size).to(x.device)x, (h_n, c_n) = self.lstm(x, (h_0, c_0))x = self.dropout(h_n[-1])x = self.fc(x)return x
TextCNN
TextCNN是一种应用于NLP任务的卷积神经网络模型,主要用于文本分类任务。TextCNN通过卷积操作提取文本的局部特征,再通过池化操作获取全局特征。
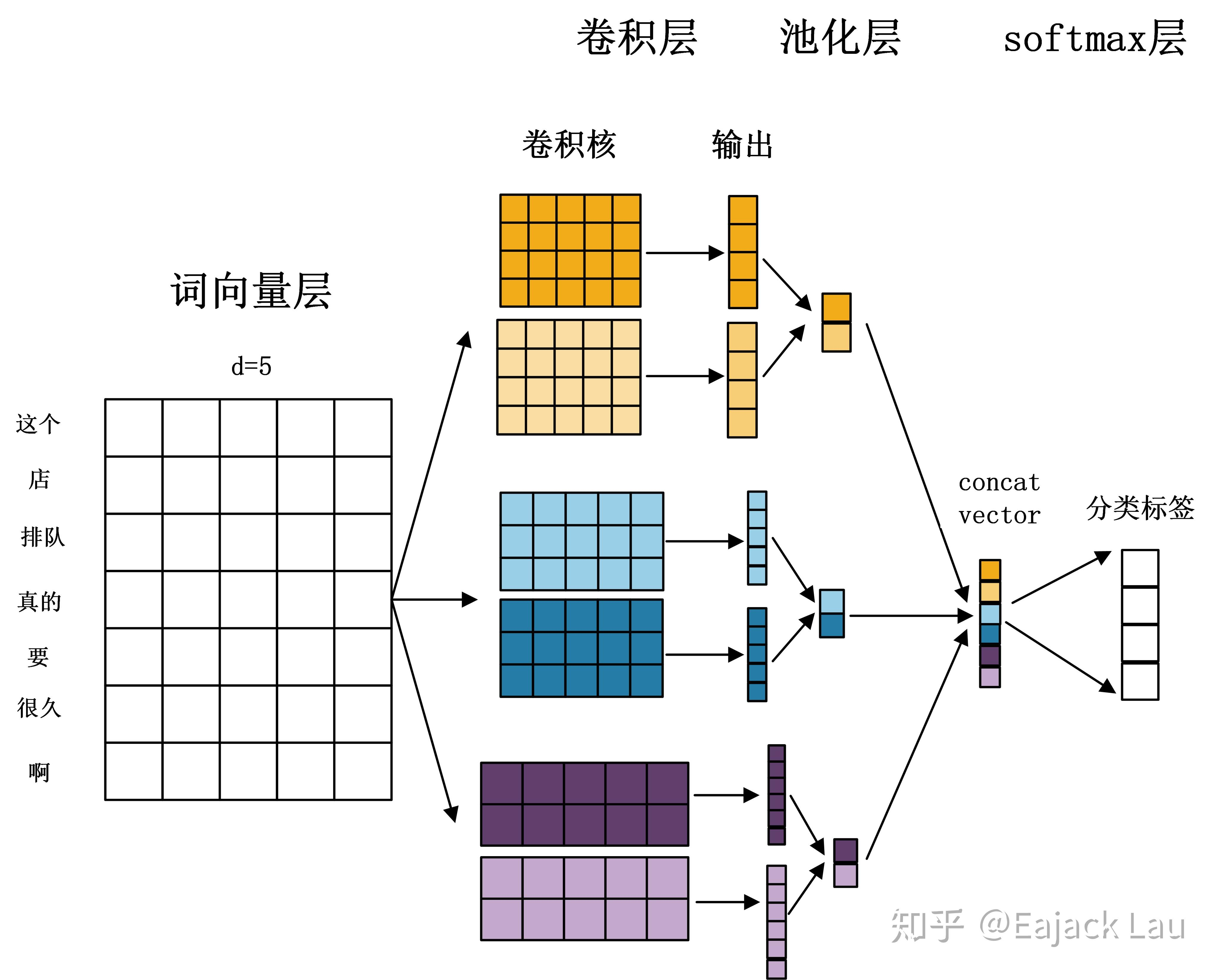
TextCNN的优点
高效提取局部特征:卷积操作能够有效提取不同n-gram范围内的局部特征。
并行计算:卷积操作和池化操作可以并行计算,训练和推理速度快。
TextCNN的缺点
缺乏长距离依赖:在捕捉长距离依赖方面不如LSTM等序列模型。
固定大小的卷积核:对于变长依赖的建模能力有限。
TextCNN的代码实现
import torch
import torch.nn as nnclass TextCNN(nn.Module):def __init__(self, vocab_size, embedding_dim, num_filters, kernel_sizes, dropout, num_classes):super(TextCNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.convs = nn.ModuleList([nn.Conv2d(1, num_filters, (k, embedding_dim)) for k in kernel_sizes])self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(num_filters * len(kernel_sizes), num_classes)def forward(self, x):x = self.embedding(x).unsqueeze(1)x = [torch.relu(conv(x)).squeeze(3) for conv in self.convs]x = [torch.max_pool1d(i, i.size(2)).squeeze(2) for i in x]x = torch.cat(x, 1)x = self.dropout(x)x = self.fc(x)return xTransformer
Transformer是一种基于注意力机制的模型架构,能够更好地处理长距离依赖关系。Transformer由编码器和解码器组成,每个编码器和解码器包含多个自注意力层和前馈神经网络层。

Transformer的优点
捕捉长距离依赖:通过自注意力机制,能够有效捕捉长距离依赖关系。
并行计算:没有RNN的顺序计算限制,能够并行处理序列数据。
Transformer的缺点
计算复杂度高:自注意力机制的计算复杂度较高,特别是对于长序列数据。
需要大量数据:Transformer通常需要大量数据进行训练,以充分发挥其性能。
Transformer的代码实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TransformerModel(nn.Module):def __init__(self, vocab_size, embedding_dim, num_heads, num_layers, dropout, num_classes):super(TransformerModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.transformer = nn.Transformer(embedding_dim, num_heads, num_layers, num_layers, dropout=dropout)self.fc = nn.Linear(embedding_dim, num_classes)def forward(self, x):x = self.embedding(x).permute(1, 0, 2)x = self.transformer(x)x = x.mean(dim=0)x = self.fc(x)return x结论
本文详细介绍了RNN、LSTM、TextCNN和Transformer的基本原理、优缺点及其在PyTorch中的实现。这些模型在自然语言处理任务中各有优势,选择合适的模型架构可以显著提升任务的性能。












