
提示:solr9.x版本需要jdk17+,solr8.x版本需要jdk8+
1、Solr 简介
Solr 是Apache 下的一个顶级开源项目,采用 Java 开发,它是基于 Lucene 的全文搜索服务器。Solr 提供了比 Lucene 更为丰富的查询语句,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr 可以独立运行,运行在 Jetty、Tomact 等这些 Servlet 容器中,Solr 索引的实现方式很简答,用Post 方法向 Solr 服务器发送一些描述 Field 及其内容的 XML 文档,Solr 根据XML 文档添加、删除、更新索引。Solr索引只需要发送 HTTP GET 请求,然后对 Solr 返回 xml,json 等格式的查询结果进行解析,组织页面布局。Solr 不提供构建 UI 的功能。Solr 提供一个管理界面,通过管理界面可以查询到 Solr 的配置的和运行情况
1.1、Solr 下载与安装
Solr 下载地址:
链接一:http://archive.apache.org/dist/lucene/solr/
链接二:https://solr.apache.org/downloads.html
2.安装配置
下载完成之后,解压solr文件,解压tomcat
2.1 在tomcat安装solr,并且建立solrCore
- 把solr8.11.4目录下的server/solr-webapp/webapp 重命名为solr,并且放置到tomcat/webapp的目录下。
- 打开tomcat/webapp/solr/WEB-INF/web.xml
- 新建一个文件夹,不要中文目录,用来做solrHome,也就是solrCore的实例存放位置
- 在tomcat/webapp/solr/WEB-INF/web.xml中配置solr的地址

- 在tomcat/webapp/solr/WEB-INF/文件夹中,建立classes目录
- 把solr8.11.4/server/resource/log4j.* 复制到上一步建立的classes目录中
- 把solr8.11.4/server/lib/ext/目录下的所有jar文件复制到tomcat/webapp/solr/WEB-INF/lib/中,这是一些日志用的jar包,不然启动报错;把solr8.11.4/server/lib/下metrics*.jar相关的jar包复制到tomcat/webapp/solr/WEB-INF/lib/中,不然启动会报metrics相关错误。
- 这个时候,可以输入http://127.0.0.1:8080/solr/index.html来访问到solr的控制界面了。
- 接下来就是创建solrCore。
- 目前solrHome目录是空的,我们创建一个空文件夹core1,这个就是我们的一个实例,然后把solr8.11.4/server/solr/configsets/_default/conf/ 这个文件复制到solrHome/core1中。
- 把solr5.5/server/solr/solr.xml复制到solrHome目录下。
- 在solr的管理控制台界面,添加一个core1

- 这下就创建成功了一个实例core1,必须先操作11步确保有文件夹core1此时才能创建实例,实例与文件夹名称要一致。
2.2 安装ik中文分词器
ik中文分词器下载https://central.sonatype.com/artifact/com.github.magese/ik-analyzer
1.准备好ik分词器的jar包,可以自己编译,也可以下载我生成的。然后把它复制到tomcat/webapp/solr/WEB-INF/lib里面。(千万不要复制到tomcat/lib中,这样会找不到lucene的类)
2.打开solrHome/core1/conf/managed-schema文件,在最下方,追加如下配置
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer>
</fieldType><!--自定义字段-->
<!--IKAnalyzer Field-->
<!-- type="text_ik"代表使用了Ik中文分词器。 -->
<!-- indexed="true"代表进行索引操作。 -->
<!-- stored="true"代表将该字段内容进行存储。 -->
<field name="product_name" type="text_ik" indexed="true" stored="true" />
<field name="product_price" type="string" indexed="true" stored="true" />
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_description" type="text_ik" indexed="true" stored="true" />
<field name="product_catalog_name" type="string" indexed="true" stored="false" />
3.启动tomcat,即可看到text_ik分词

2.3 插入的文档必须与域相匹配
域,我个人也称它为字段,它在solr中有特定的含义,就类似数据库中表的列一样,规范着写入的数据,我们先来做个例子。

可以看到,我这次插入的文档,有id,title当然,在solr中,每一条记录都必须有着一个唯一的id,它就类似数据库中的主键,不可重复。这条记录的插入是成功的。
但是,如果我把title改成title1,这就与定义的字段不一样了,就会报错,如下图所示

可以看到,这里提示,未知的字段 title1.
2.4 域的定义 field
先拿出一条配置来看一下
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> 认识一下这些属性
name:域名
type:域的类型,必须匹配类型,不然会报错
indexed:是否要作索引
stored:是否要存储
required:是否必填,一般只有id才会设置
multiValued:是否有多个值,如果设置为多值,里面的值就采用数组的方式来存储,比如商品图片地址(大图,中图,小图等)
2.5 配置动态域 dynamicField
同样的,也先拿出一条来看看
<dynamicField name="*_i" type="string" indexed="true" stored="true" multiValued="true" />何谓动态域呢?就是这个域的名称,是由表达式组成的,只要名称满足了这个 表达式,就可以用这个域
同样的认识一下这些属性
name:域的名称,该域的名称是通过一个表达式来指定的,只要符合这这个规则,就可以使用这个域。比如 aa_i,bb_i,13_i等等,只要满足这个表达式皆可
type:对应的值类型,相应的值必须满足这个类型,不然就会报错
indexed:是否要索引
stored:是否要存储
...其它的属性与普通的域一至
2.6 主键域 uniqueKey
给出一条配置
<uniqueKey>id</uniqueKey>指定一个唯一的主键,每一个文档中,都应该有一个唯一的主键,这个值不要随便改
2.7 复制域 copyField
给出一条配置
<copyField source="cat" dest="text"/>说明一下相应的属性
source:源域
dest:目标域
复制域,将源域的内容复制到目标域中
注意:目标域必须是允许多值的,如下,nultiValued必须为true,因为可能多个源域对应一个目标域,所以它需要以数组来存储
<field name="text" type="string" indexed="true" stored="true" multiValued="true"/>2.8 域的类型 fieldType
同样的给出一段配置,这段稍微有点复杂
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"><analyzer type="index"><tokenizer class="solr.StandardTokenizerFactory"/><filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /><!-- in this example, we will only use synonyms at query time<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>--><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="solr.StandardTokenizerFactory"/><filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /><filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>给出相应属性的说明
name:域的名称
class:指定solr的类型
analyzer:分词器的配置
type: index(索引分词器),query(查询分词器)
tokenizer:配置分词器
filter:过滤器
2.9 业务字段的实际配置
经过上面的学习,差不多了解了一些常用的配置,如今我们用field来配置实际的业务字段,有属性如下
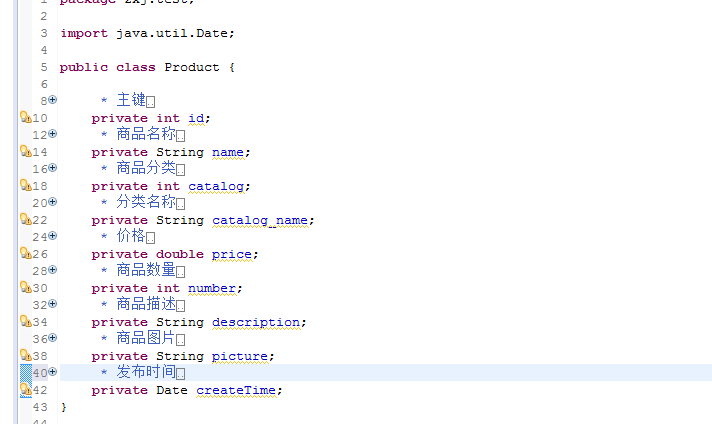
当然,中文分词还是要用的,因为我们在前面的 1.2 章节中,已经配置了一个fieldType的中文分词,所以我们现在一律用中文分词的域类型
主键的id就不需要配置了,默认已经把id配置为主键了,默认的配置如下
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> 商品名称(需要分词,需要存储)
<field name="name" type="text_ik" indexed="true" stored="true" /> 商品分类(不需要分词,需要存储)
<field name="catalog" type="int" indexed="false" stored="true" /> 商品分类名称(需要分词,需要存储)
<field name="catalog_name" type="text_ik" indexed="true" stored="true" /> 商品价格(不分词,需要存储)
<field name="price" type="double" indexed="false" stored="true" /> 商品描述(需要分词,不需要存储)
<field name="description" type="text_ik" indexed="true" stored="false" /> 商品图片(不需要分词,需要存储)
<field name="picture" type="string" indexed="false" stored="true" /> 复制域的应用
前面我们了解了复制域,但是却不知道它的应用场景,现在我们结合实际情况来讲一下复制域
用户在搜索框搜索的时候,有可能输入的是商品名称,也有可能输入的是商品描述,也有可能输入的是一个商品类型,那么这些值的搜索,肯定在后台是对应一个域的,那么既然如此,我们就可以把这些域合并成一个,这样在后台只需要单独的对这一个域进行搜索就可以了
先定义一个目标域
<field name="keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> 复制域,把商品名称,商品描述,商品类型名称复制到上面的这个域中
<copyField source="name" dest="keywords"/>
<copyField source="catalog_name" dest="keywords"/>
<copyField source="description" dest="keywords"/>











