
目录
1. Callable接口
1.1 Callable 和 Runnable 的区别
1.2 FutureTask
2. ReentrantLock
2.1 ReentrantLock 和 synchronized 的区别
3. 信号量Semaphore
3.1 PV 操作
3.2 二元信号量
4. CountDownLatch
5. 多线程下使用 ArrayList
5.1 CopyOnWriteArrayList --- 写时拷贝
6. 多线程下使用哈希表 [经典面试题]
6.1 ConcurrentHashMap 相较于 Hashtable 的优势
6.1.1 "锁桶"
6.1.2 size --- 原子类维护
6.1.3 ConcurrentHashMap 的扩容机制
引言:
本篇博客, 就来聊一聊 java.util.concurrent(JUC)中的一些组件.
1. Callable接口
Callable接口, 是一个函数型接口, 里面包含了一个抽象方法 call.
1.1 Callable 和 Runnable 的区别
Callable 和 Runnable 是并列的关系, 都可以表示一个任务, 但不同的是:
- Callable 表示的是一个带有 "返回值" 的任务.
- Runnable 表示的是不带 "返回值" 的任务.
- Callable 注重任务执行的结果, 其核心在于重写 call 方法. 其内部的 call 方法是带有返回值的, 可以返回任务执行的结果
- Runnable 注重任务的执行过程, 其核心在于重写 run 方法. 其内部的 run 方法没有返回值.
此外, Callable 是一个泛型接口, call 方法返回值的类型就是这个指定的泛型参数.

注意, Callable 仅仅代表的是一个带有返回值的任务, 任务真正的执行还有要通过 Thread 创建线程来执行.
1.2 FutureTask
但是, Thread 并没有提供带有 Callable 参数的构造方法, 需要将 Callable 实例借助 FutureTask 来包装一下, 将 FutureTask 的实例传入 Thread 的构造方法中.

同时,通过 FutureTask 的实例调用 get 方法, 来获取 Callable 任务的返回值.
get 也是一个阻塞方法,
- 当任务还没有执行完毕, 也就是说 get 还没有拿到返回值, get 就会进行阻塞.
- 当拿到任务的返回值(任务执行完毕后), get 才会继续往下执行.
![]()
之所以需要通过 FutureTask 间接传送任务, 是为了实现 Thread(线程)和 Callable(任务)的解耦和, 将任务的返回值使用 FutureTask 实例接收, 从而将 Thread 和任务分离开来, 使 Thread(线程) 不用关心任务是否具有返回值(只是执行任务而以).
到目前为止, 我们学习到创建线程共有以下几种写法:
- 继承自 Thread 类(定义单独类/匿名内部类)
- 实现 Runnable接口(定义单独类/匿名内部类)
- lambda
- 实现 Callable 接口(定义单独类/匿名内部类)
- 线程池, ThreadFactory
/*** 使用 Callable */
public class Demo37 {public static void main1(String[] args) throws ExecutionException, InterruptedException {//使用 Callable 定义一个带有 "返回值" 的任务 (并没有真正执行)Callable<Integer> callable = new Callable<Integer>() {int count = 0;@Overridepublic Integer call() throws Exception {for (int i = 1; i <= 100; i++) {count += i;}return count;}};FutureTask<Integer> futureTask = new FutureTask<Integer>(callable);Thread t = new Thread(futureTask);t.start();System.out.println(futureTask.get());}public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask<Integer> futureTask = new FutureTask<>(() -> {int count = 0;for (int i = 0; i <= 100; i++) {count += i;}return count;});Thread t = new Thread(futureTask);t.start();// 当任务还没有执行完毕, 也就是说 get 还没有拿到返回值, get 就会进行阻塞.System.out.println(futureTask.get());}
}2. ReentrantLock
ReentrantLock 和 synchronized 是并列的关系, 也一把具有 "可重入" 特性的锁.
在早期的时候, ReentrantLock 是使用最多的, 但随着后来 synchronized 的出现以及优化, synchronized 就替代了 ReentrantLock 的地位. 目前也都是在使用 synchronized ~~
2.1 ReentrantLock 和 synchronized 的区别
ReentrantLock 和 synchronized 具有以下区别:
- synchronized 是关键字(底层由 C++ 代码实现), ReentrantLock 是 Java 标准库中提供的类(java.util.concurrent)
- synchronized 进代码块加锁, 出代码块就自动解锁. ReentrantLock 需要使用 lock/unlock 进行加锁和解锁操作(需要额外注意 unlock 进行解锁)

- ReentrantLock 还提供了 tryLock 方法.
- ReentrantLock 提供了公平锁的实现, 默认是非公平的 (构造方法传入 true 指定为公平锁; 构造方法传入 false 指定为非公平锁.)

- ReentrantLock 搭配 Condition 来实现 等待/通知 机制, 比 wait/notify 功能更强大.
虽然, synchronized 被广泛使用, 但是上文 ReentrantLock 3.4.5. 的优点, 也使其保存了下来.
tryLock 功能如下:
- 加锁成功 => 返回 true
- 加锁失败 => 返回 false (若锁被其他线程占用时, 不会进行阻塞)
- 可以设置超时时间, 等待时间达到超时时间后, 再返回 true/false
tryLock 返回 true/false 的机制, 可以给调用者更大的自由度, 由调用者决定下一步的计划(如果有我竞争失败, 那我可以直接放弃这把锁, 转头去竞争其他锁~)
/*** 使用 ReentrantLock*/
public class Demo38 {// ReentrantLock locker = new ReentrantLock(true); // 指定为公平锁private static ReentrantLock locker = new ReentrantLock(); // 默认是非公平锁private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {locker.lock(); // 加锁count++;locker.unlock(); // 解锁}});Thread t2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {locker.lock(); // 加锁count++;locker.unlock(); // 解锁}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}
}3. 信号量Semaphore
信号量, 能够协调多个 进程/线程 之间资源的分配, 本质上就是一个计数器, 描述了 "可用资源的个数".
Java 标准库提供的 Semaphore 就是信号量, 构造实例时, 在构造方法中传入的数字是几, 就代表有几个可用资源.

3.1 PV 操作
上文说到, 信号量表示的是可用资源的个数, 而我们可以进行申请资源和释放资源的操作:
- P操作(Semaphore 中的 acquire 方法), 就是申请资源, 会使可用资源 -1
- V操作(Semaphore 中的 release 方法), 就是释放资源, 会使可用资源 +1
- 当计数器为 0 时, 继续申请资源, 就会阻塞等待
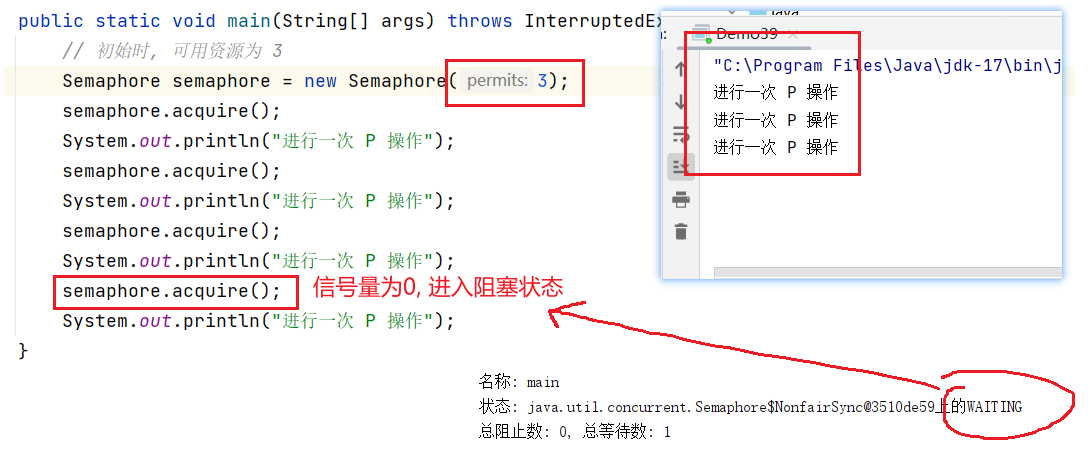
3.2 二元信号量
二元信号量是信号量的一种特殊情况: 即初始容量为 1 的信号量.
此时, 信号量的取值要么是 0 要么是 1. 此时就相当于 "锁".
- 当信号量为 1 时, 可以有线程获取这把锁(P操作, 申请资源).
- 当信号量为 0 时, 其他线程再进行获取锁(P操作, 申请资源)的操作, 就会阻塞等待, 必须等上一个线程释放锁后(V操作, 释放资源), 才能获取.
/*** Semaphore 用作锁*/
public class Demo39 {private static int count;public static void main(String[] args) throws InterruptedException {Semaphore semaphore = new Semaphore(1);Thread t1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {try {semaphore.acquire();count++;semaphore.release();} catch (InterruptedException e) {throw new RuntimeException(e);}}});Thread t2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {try {semaphore.acquire();count++;semaphore.release();} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}4. CountDownLatch
大家都知道, 为了充分利用多核操作系统, 引入多线程编程, 将一个大任务分为多个子任务, 再将每个子任务交给多个线程去执行, 通过并发执行, 提高了工作效率.
而 CountDownLatch 就可以来衡量子任务的完成情况, 判断整个任务是否完成.
- 对 CountDownLatch 的构造方法指定参数, 描述一共拆分成了几个子任务.
- 每个子任务执行完毕后, 调用一次 countDown 方法, 代表该子任务完成
- 在主线程中调用 await 方法, 若存在子任务还没有完成, 则会阻塞等待, 只有当所有的子任务都执行完毕后, 才会继续向下执行.
比如:
学校 400m 跑步比赛时, 每有一个选手跑过终点线(就相当于调用一次 countDown ), 只有所有的选手都跑过终点线后, 比赛才会结束(await 继续往下执行).
public class Demo40 {public static void main(String[] args) throws InterruptedException {CountDownLatch count = new CountDownLatch(10);ExecutorService executorService = Executors.newFixedThreadPool(4);for (int i = 0; i < 10; i++) {int id = i;executorService.submit(() -> {System.out.println("开始执行子任务 " + id);try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("子任务执行完毕 " + id);count.countDown();});}// 这个方法阻塞等待所有的任务结束// await => all waitcount.await();System.out.println("任务全部执行完毕");executorService.shutdown();}
}5. 多线程下使用 ArrayList
我们知道 ArrayList 本身是线程不安全的, 要想在多线程环境下使用, 我们就需要通过一些方法来确保线程安全:
- 自行使用 synchronized 对涉及线程安全问题的代码进行加锁, 打包成"原子". (推荐, 这种是比较通用的方法, 具体问题具体分析, 在该加锁的地方加锁, 不用加锁的地方就不加锁)
- Collections.synchronizedList(new ArrayList); 使用 Java 标准库提供的方法, 所返回的 List 的所有 public 方法都带有 synchronized , 意味着 this 成为所有方法的锁对象, 锁竞争的概率大大增大.
- 使用 CopyOnWriteArrayList. 下文细讲
5.1 CopyOnWriteArrayList --- 写时拷贝
CopyOnWriteArrayList 解决线程安全问题的方案, 不是去加锁(不会产生阻塞), 而是通过编程中一种常见的思想方法来解决问题 --- 写时拷贝.
我们知道, 线程安全问题的产生主要是因为多个线程同时修改同一份变量引发的, 这样就会导致其他线程读取到的数据可能是只 "改了一半" 的数据.
而, CopyOnWriteArrayList 的解决策略是:
- 如果有线程进行修改操作时, 会对这个变量进行 复制 操作.
- 复制操作不是原子的, 会耗费一定的时间, 可能有其他线程在复制期间进行了读操作
- 如果在复制的过程中, 有其他的线程进行了读操作, 那直接从旧的变量中去读, 保证读到的数据是修改前, 而不是只"修改了一半"的数据.
- 等到复制完成后, 再抛弃掉旧版本的数据, 将新版本的数据赋值给引用(赋值操作是原子的)
综上, CopyOnWriteArrayList 的 "写时拷贝" 的策略, 确保线程读取到的数据要么是 "修改前的数据" 要么是 "修改后的数据", 而肯定不是 "只修改了一半的数据".(并且上述过程没有进行加锁操作, 不会产生阻塞)
(读取的不管是 "改之前" 或者 "改完后" 的数据都是线程安全的, 只要不是 "只改了一半" 就是安全的)
虽然 "写时拷贝" 具有一定的优势, 但是其缺陷也是很明显的:
- 当数组非常大时, 拷贝将会花费很多的时间, 非常低效.
- 当同时有多个线程进行修改操作时, 就会出现 bug.
所以, "写时拷贝" 只适用于一些特定的场景, 例如 : 服务器配置重加载(reload)时, 可以避免服务器重启带来的影响, 而是可以在运行的过程中, 加载新配置, 实现新配置替代旧配置的操作.
6. 多线程下使用哈希表 [经典面试题]
我们知道, HashMap 是线程不安全的, 只适用于单线程的环境下.
而 Hashtable 虽然是线程安全的, 但是它是将所有的 public 方法进行了 synchronized 加锁, 大大增加了 锁冲突 的概率, 效率低下.
而 ConcurrentHashMap 是 Hashtable 的进一步优化, 效率也大大提高.
6.1 ConcurrentHashMap 相较于 Hashtable 的优势
6.1.1 "锁桶"
ConcurrentHashMap 是按照桶级别进行的加锁, 而不是给整个哈希表加的全局锁, 这样以来, 大大降低了锁冲突的概率, 提高了性能.
提到哈希, 就不得不提 哈希冲突, 解决哈希冲突有以下两种方式:
- 闭散列(线性探测)
- 闭散列/哈希桶(链表)
由于线性探测效率太低, Java 标准库提供的哈希表采用的是开散列哈希桶的方式解决的哈希冲突.
而在多线程的环境下, 当多个线程修改不同变量时, 当被修改的变量在不同的桶中时, 是不涉及线程安全问题的, 如果采用加全局锁的形式, 那将大大增加锁冲突的概率.
- Hashtable 采用 "全局锁" 的形式, 对所有的 public 方法进行了 synchronized 加锁(统一对 this 加锁), 大大增加了锁竞争的概率. 所以两个线程, 使用 Hashtable 任意访问两个元素, 就会发生锁竞争.
- 而 ConcurrentHashMap 采用 "锁桶" 的形式, 使用每个桶(链表)的头结点当做 synchronized 的锁对象, 当修改的是不同链表上的节点时, 就不会发生阻塞.
- 并且, 在实际开发中, 哈希表可能是非常大, 即使有多个线程在访问这个哈希表, 那他们同一时刻访问到同一条链表上的概率也是很低的, 也就是说 ConcurrentHashMap 发生锁竞争的概率很低. (锁开销最大的地方就是阻塞, 其他的地方如偏向锁就还好, 并且如果要保证线程安全, 偏向锁加标记啥的也无法避免~).
上述的 "锁桶" 策略是 Java8 引入的, 之前 ConcurrentHashMap 采用的是 "分段锁" (将链表分组, 每个组使用一把锁)
6.1.2 size --- 原子类维护
虽然 锁桶 解决了多线程下哈希表中元素修改的效率问题, 那么 ConcurrentHashMap 是怎么保证全局变量 size 的线程安全呢??
--- 使用原子类对 size 进行维护.
6.1.3 ConcurrentHashMap 的扩容机制
当哈希表很长大时, 扩容操作, 就需要将旧数组中的所有元素搬运到新数组中.
如果一次完成所有元素的搬运, 是很耗时, 在多线程的环境下, 这必然需要进行长时间的加锁, 这样就导致多个线程阻塞等待.
(HashMap 本来就是单线程下使用, 耗时就耗时吧, 没办法~~)
对此, ConcurrentHashMap 采取的策略是 "化整为零".
- 并非一口气完成数组的搬运工作, 而是拆分成多个小任务. 比如, 触发扩容操作后, 每进行一次 put, 只搬运 n% 的数据, 直到全部搬运完成后, 再进行哈希数组的更新.
- 期间若进行数据读取, 从旧数组中读. 若进行数据插入, 则插入到新数组中.
这样以来, 就可以保证每次 "搬运" 加锁的时间不会太长.
综上, ConcurrentHashMap 的核心优化如下:
- 将 锁全局 优化为 锁桶
- 将 size 使用原子类维护
- 扩容时采用 "化整为零", 降低扩容时的加锁时间
END










 "python爬虫篇(项目案列讲解-爬取小说)")

