一.课程介绍
NumPY(Numerical Python)是python的一种开源数值计算扩展。提供多维数组对象,各种派生对象(如掩码数组和矩阵),这种工具可用于存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
- 几乎所有从事python工作的数据分析师都利用NumPy的强大功能。
- 强大的N维数组
- 成熟的广播功能
- 用于整合C/C++和Fortran代码的工具包
- NumPy提供了全面的数学功能、随机生成器和线性代数功能
二.查看:
1.查看类型:
2.查看帮组文档:
3.数组查看操作:
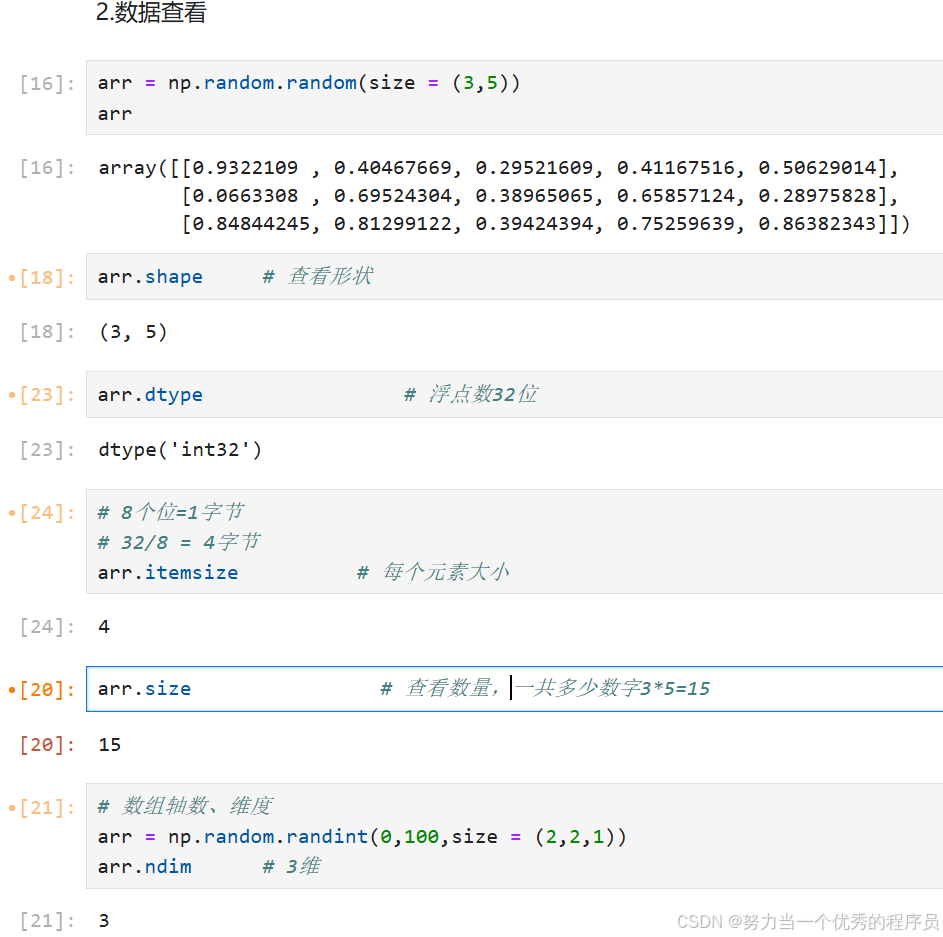
- 数组.shape:查看数组尺寸形状;
- 数组.dtype:查看数据类型;
- 数组.itemsize:查看每个元素的大小(以字节为单位);
- 数组.size:查看元素总数;
- 数组.ndim:查看数组维度/轴数;
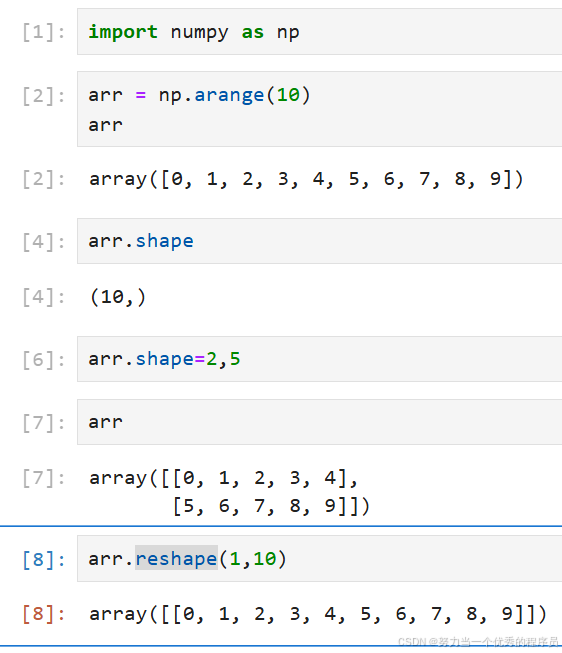
3.1.shape和reshape区别:
-
shape是一个数组属性,它返回一个元组,这个元组描述了数组每一维的大小; -
reshape是一个数组方法,它用于改变数组的形状,但是不改变数组的数据内容。
【注意事项】:
- 当使用
reshape时,新形状的元素个数必须与原数组的元素个数相同。例如,不能将一个包含 6 个元素的数组reshape成形状为(3, 3)的数组,因为3*3 = 9,元素个数不匹配。 reshape方法返回一个新的数组,原数组本身的形状不会改变。如果想要在原数组上进行形状改变(如果可能的话),可以使用resize方法,不过resize方法的行为略有不同,它可能会根据新形状的要求对数据进行截断或填充。
三.数组创建:
- 查看方法的参数:shift + tab
1.数组创建:
创建数组的最简单的方法就是使用array函数,将python下的list转换为ndarray。
- 创建numpy数组:np.array(参数)
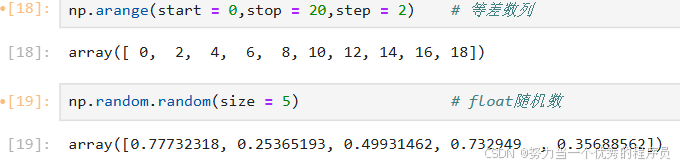
- 快速创建一维数组:np.arange(参数)

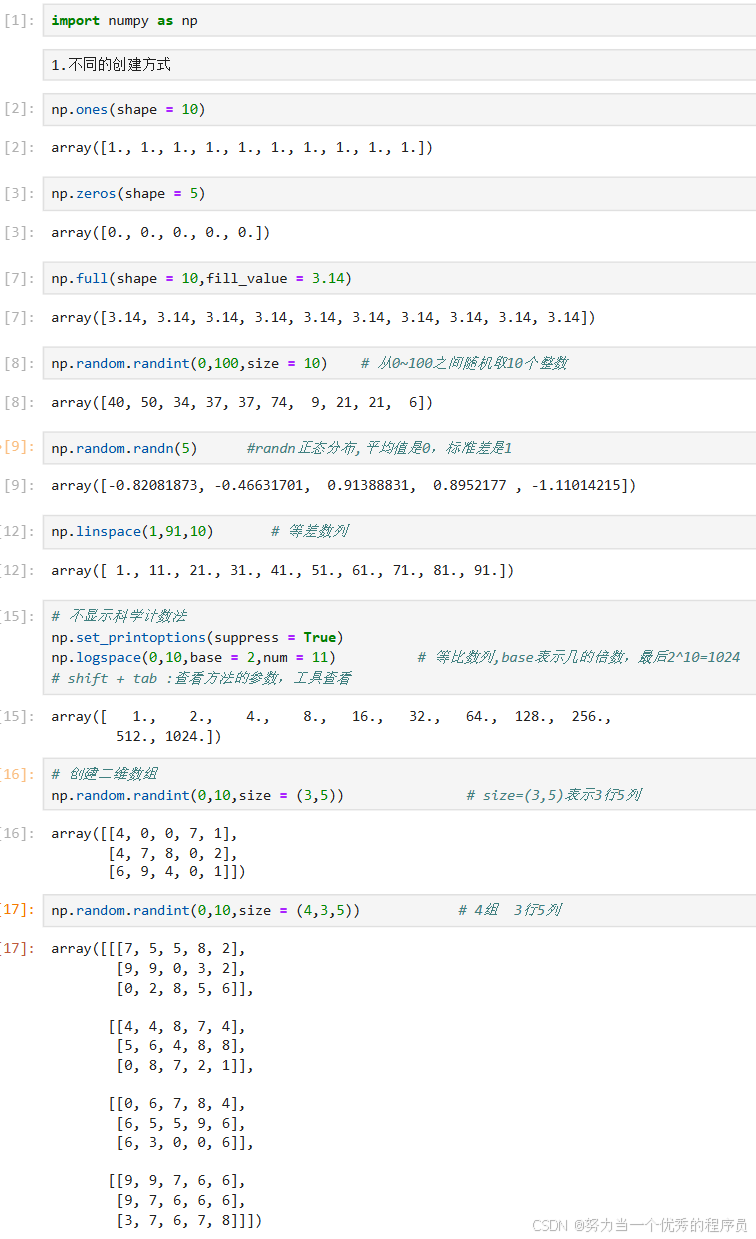
1.1.不同的创建方式:
- np.ones(参数):数组全是1,shape定义数组大小;
- np.zeros(参数):数组全是0;
- np.full(shape = 参数1,fill_value = 参数2):参数2指定数组内容值
- np.lispace():等差数列
- np.arange(start,stop,step):等差数列(step:相当于差值)
- np.logspace():等比数列(默认以10为底)
- np.set_printoptions(suppress = True):不显示科学计数法
【注意】对于ndarray结构来说,里面所有元素必须是统一类型的;若不是,则会自动向下转换。
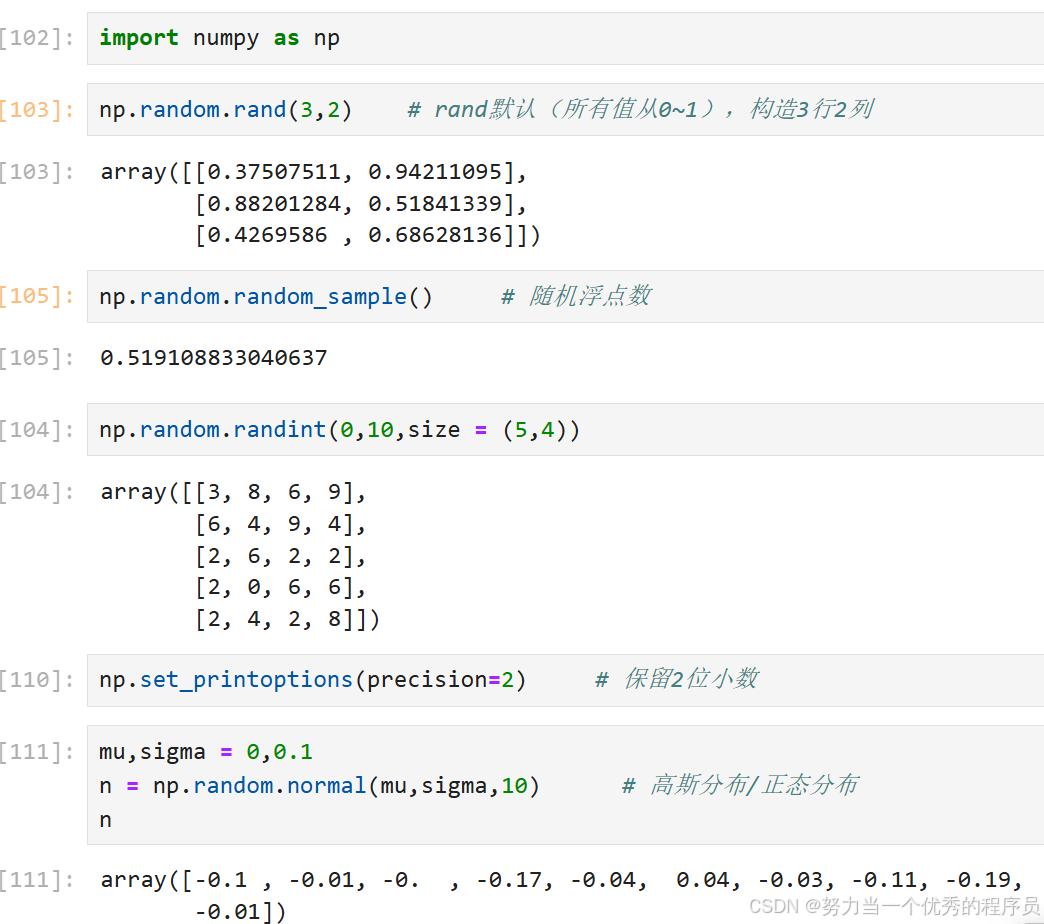
2.随机模块:
- np.random.randint():随机取整数;
- np.random.randn():正态分布
- np.random.normal():正态分布
3.shuffle洗牌操作:

4.seed随机种子:

5.fill()填充内容:
-
数组.fill(参数):参数填充内容

四.数组形状操作:
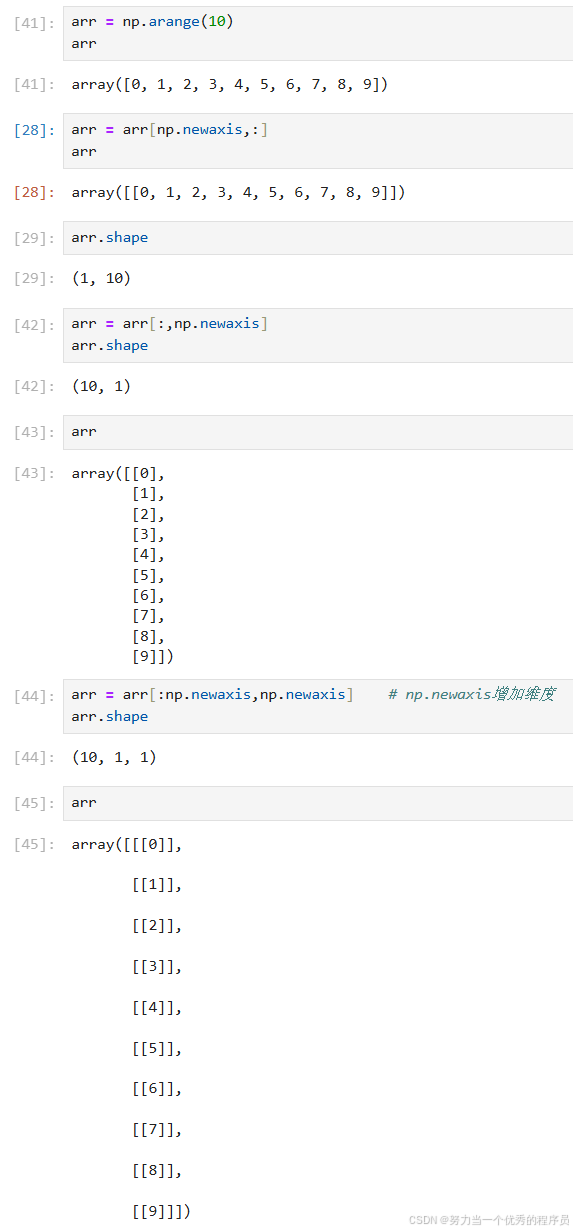
1.np.newaxis增加维度:
2.squeeze去掉多余维度:

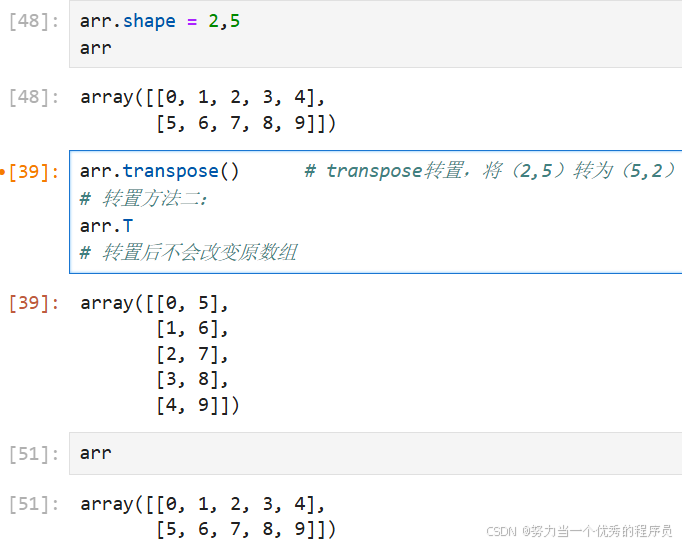
3.transpose转置:
 4.concatenate/vstack、hstack拼接:
4.concatenate/vstack、hstack拼接:
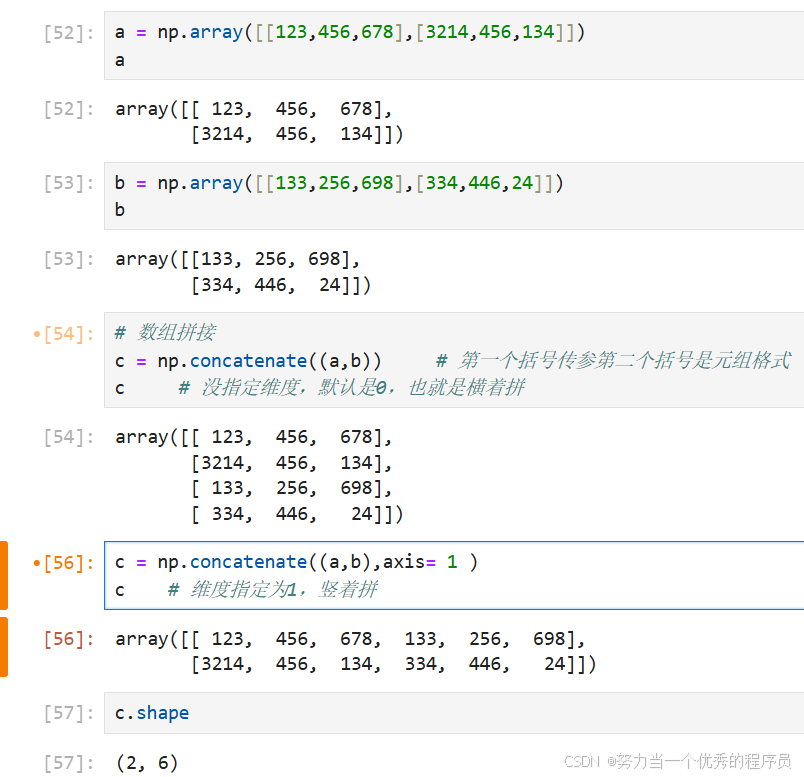
 5.flatten/ravel拉平
5.flatten/ravel拉平

五.文件IO操作:
1.保存、读取数组:
- 保存:
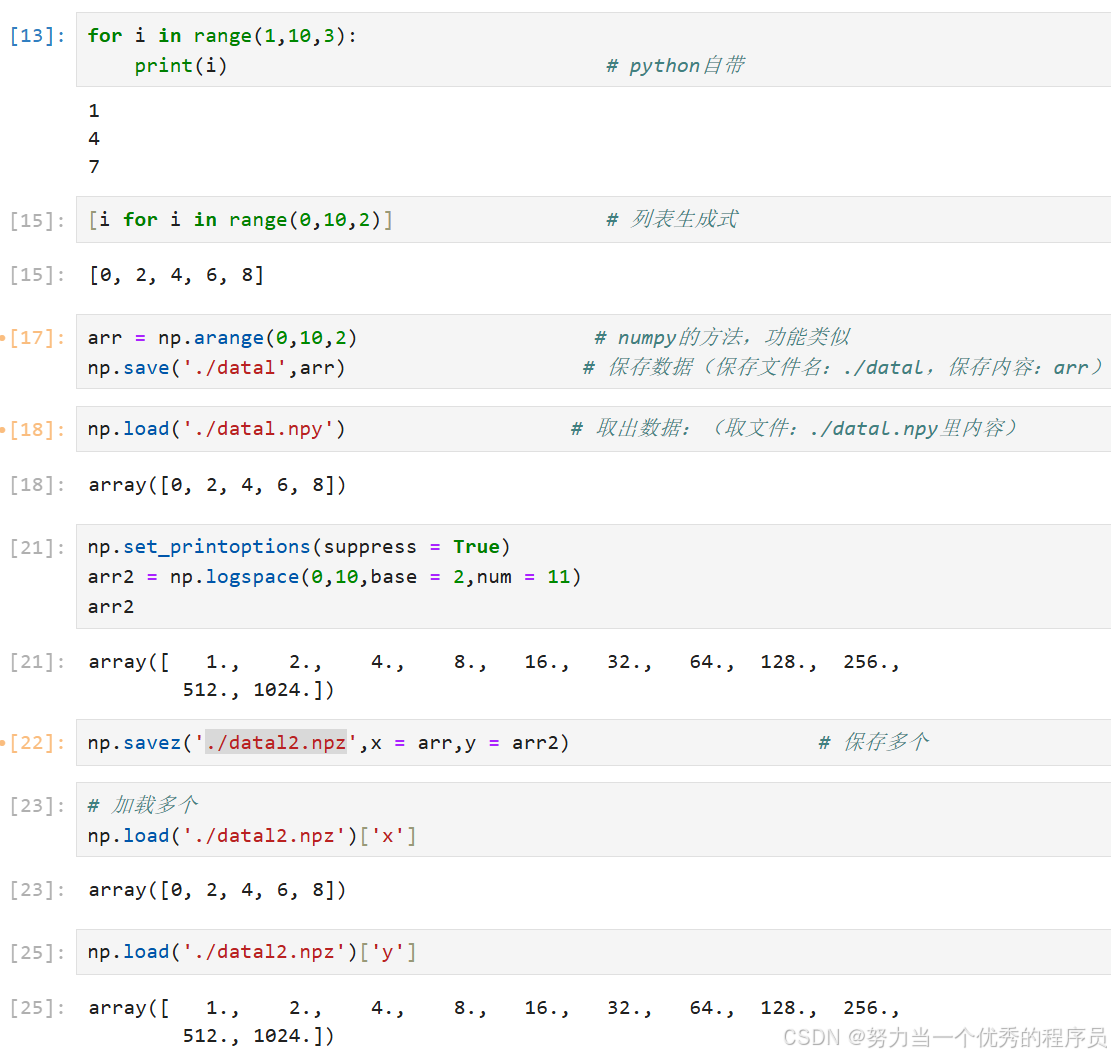
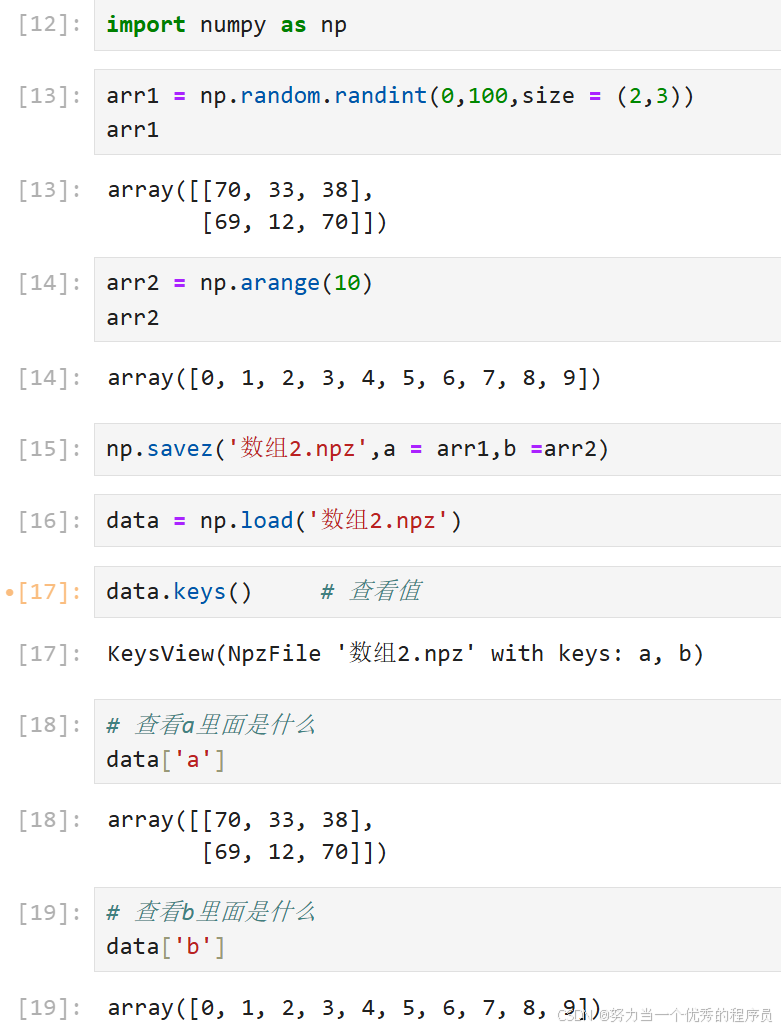
- save('文件名',数组):保存一个npy文件;
- savez('文件名',名 = 数组,名 = 数组,……):保存多个到一个.npz文件中。
- 读取:
- load('文件名.后缀'):读取存储的数组
- load('文件名.后缀')[名]:读取.npz文件的内容,读取之后相当于形成一个key-value类型的变量,通过保存时定义的key来获取相应的array。
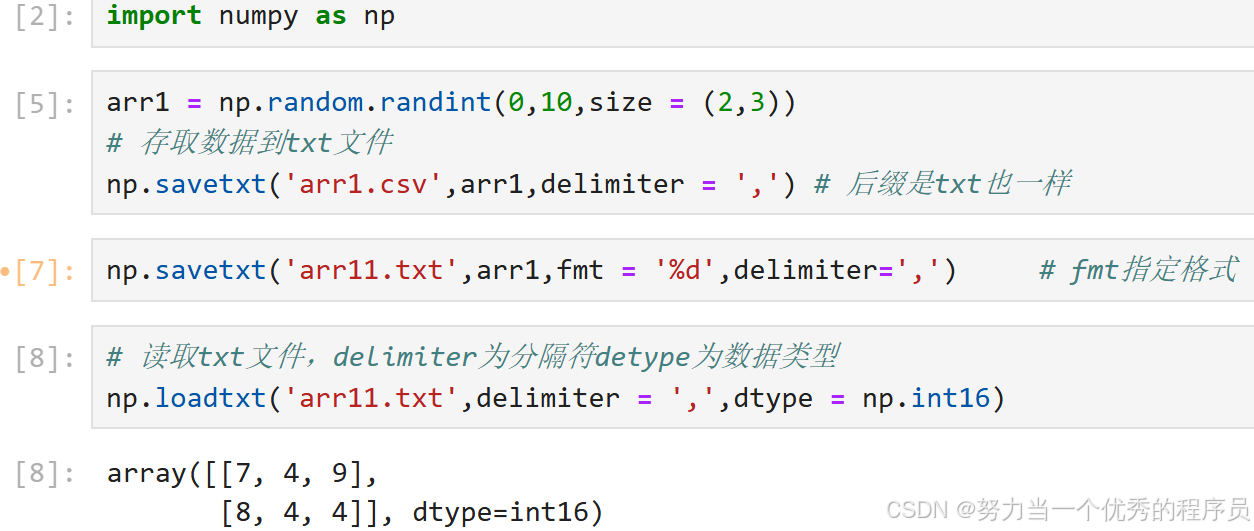
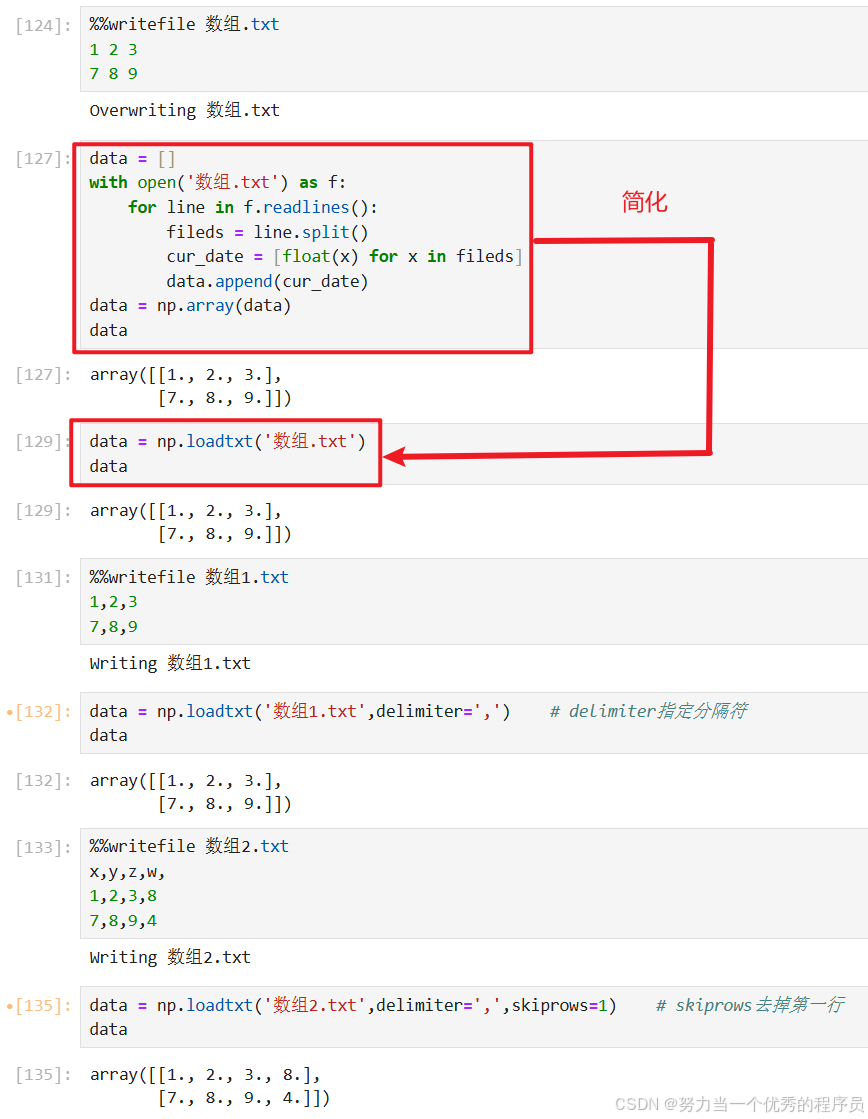
2.读写csv、txt文件:
- np.savetxt('文件名',数组,delimiter = '分隔符');
- np.loadtxt('文件名',数组,delimiter = '分隔符' );
- 括号内的参数:
- delimiter指定分隔符
- skiprows去掉第几行
- usecols=(列数):指定使用列数
- 括号内的参数:
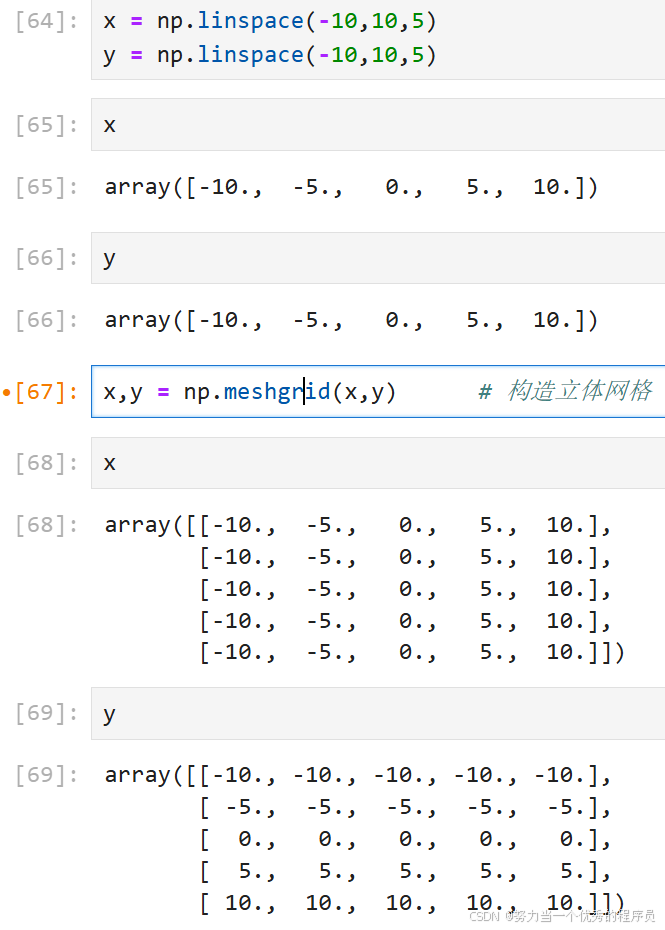
六.网格、向量、初始化:
1.meshgrid构造网格:
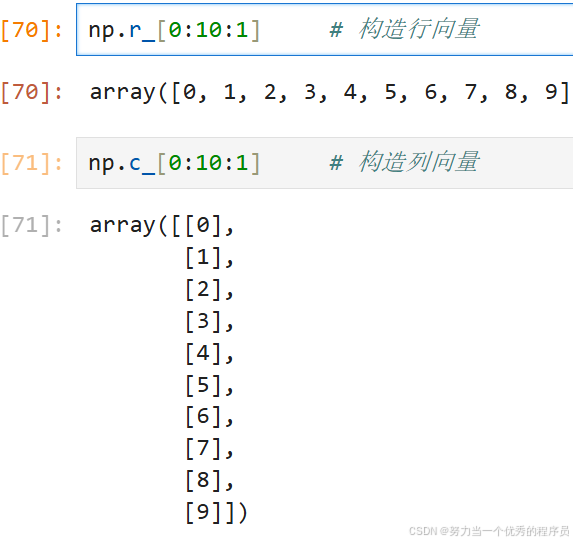
2.构造行r、列c向量
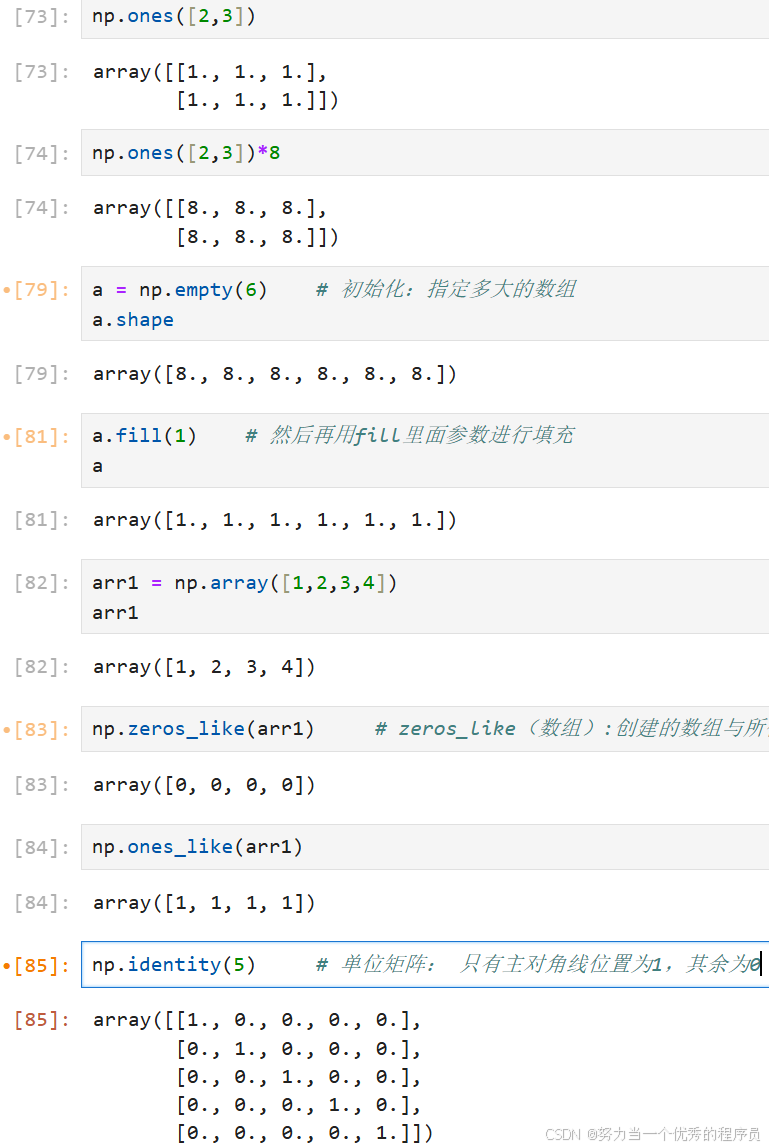
3.初始化:
- zeros_like(数组):创建的数组与所传入的数组(括号里的数组)类型一样;
- identity:单位矩阵: 只有主对角线位置为1,其余为0;
 七.数据类型:
七.数据类型:
1.ndarray的数据类型:
- int:int8、uint8、int16、int32、int64
- float:float16、float32、float64
- str
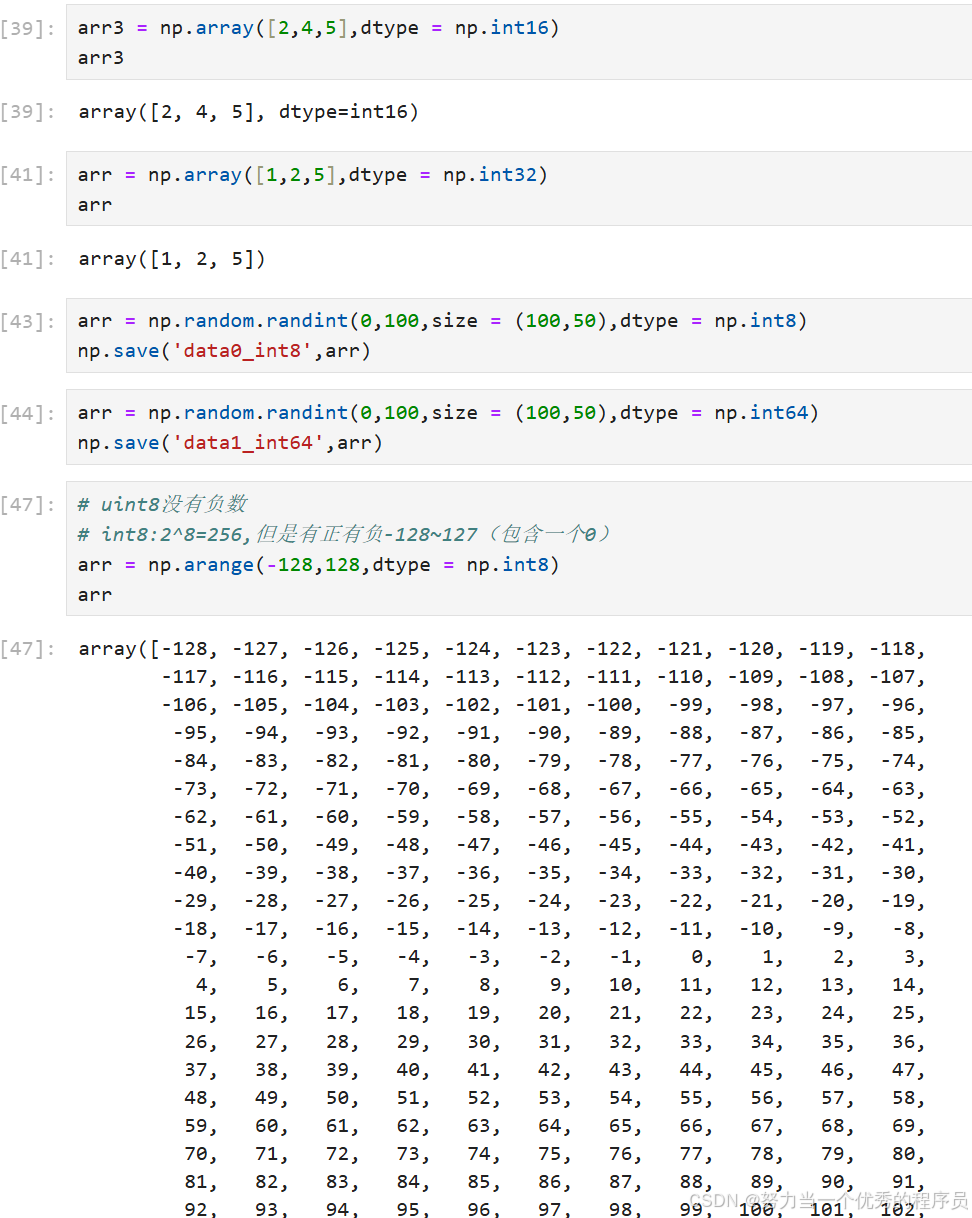


2.转换:
2.1.array创建时指定:
- np.array(数组,dtype = '类型')
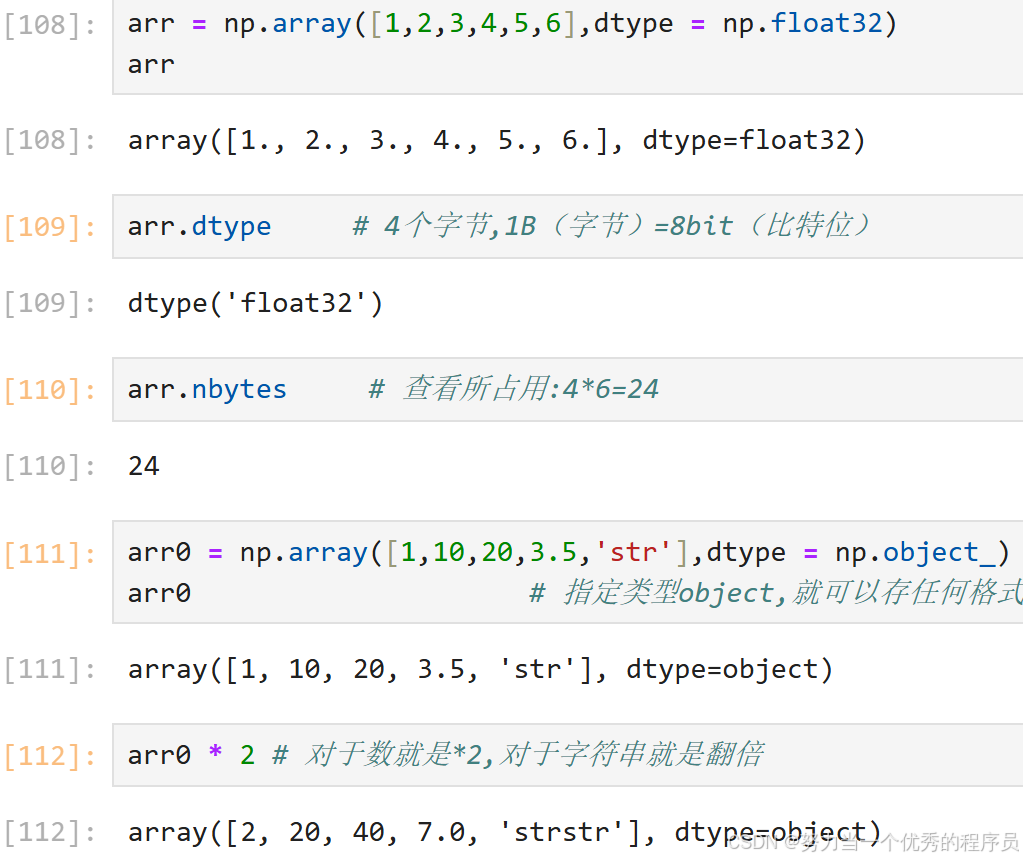
2.2.asarray转换时指定:
- np.asarray(数组,dtype = '类型')

【注意】不会改变原始的数组内容,创建了一个新数组。
2.3.结果时指定astype:
- 数组.astype('类型')

【注意】转换其数据类型为我们生成新的数组
八.数组运算:
1.加减乘除幂:
arr1 - arr2 # array([0, 2, 1, 1, 0])arr1 * arr2 # array([ 1, 0, 6, 12, 25])arr1 = np.array([2,4,6,9])
arr2 = np.array([1,2,3,3])
arr1 / arr2 # array([2., 2., 2., 3.])# 幂运算
arr1 ** arr2 # array([ 2, 16, 216, 729])arr1 = np.array([2,4,6,9])
arr2 = np.array([1,2,3,3])
arr1 // arr2 # array([2, 2, 2, 3])arr1 = np.array([1,2,3,4,5])
arr2 = np.array([1,1,2,3,5])
arr1 % arr2 # array([0, 0, 1, 1, 0])2.逻辑:
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([1,0,2,3,5])
arr1 < 5 # array([ True, True, True, True, False])
arr1 >= 5 # array([False, False, False, False, True])
arr1 == 5 # array([False, False, False, False, True])
arr1 == arr2 # array([ True, False, False, False, True])
arr1 > arr2 # array([False, True, True, True, False])3.数组与标量:
arr = np.arange(1,10) # array([1, 2, 3, 4, 5, 6, 7, 8, 9])
arr1/arr # array([1. , 0.5 , 0.33333333, 0.25 , 0.2 , 0.16666667, 0.14285714, 0.125 , 0.11111111])
arr+5 # array([ 6, 7, 8, 9, 10, 11, 12, 13, 14])
arr * 5 # array([ 5, 10, 15, 20, 25, 30, 35, 40, 45])4.+=、-=、*=:
【注意】只会修改现有数组,而不是创建一个新数组。
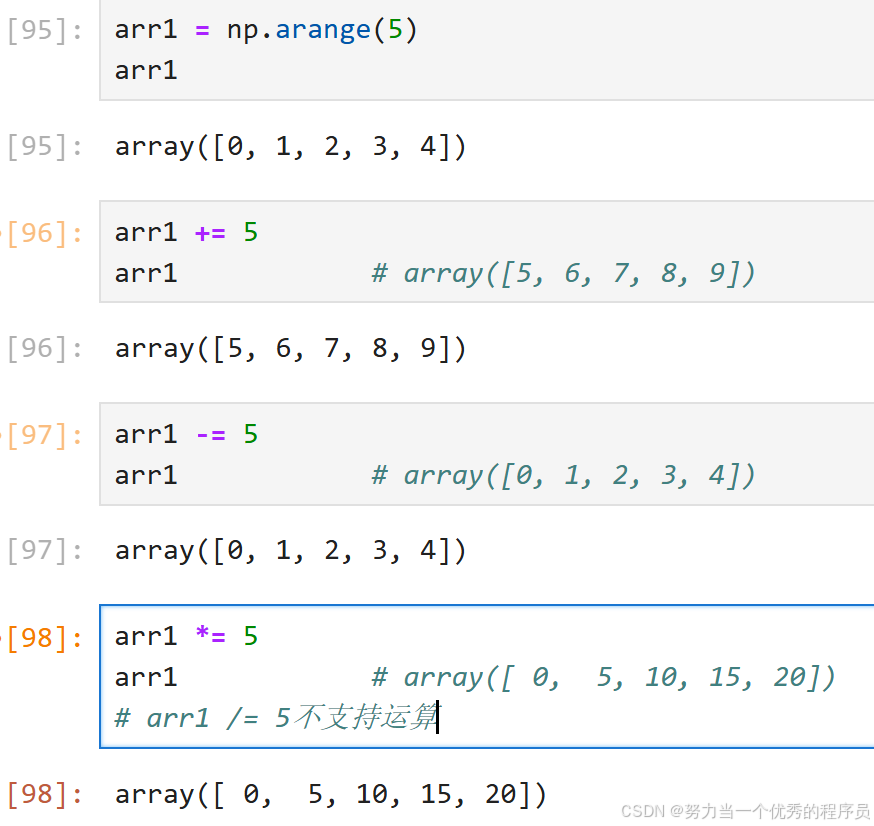
【注意】不支持/=,支持//=。
九.四则运算:
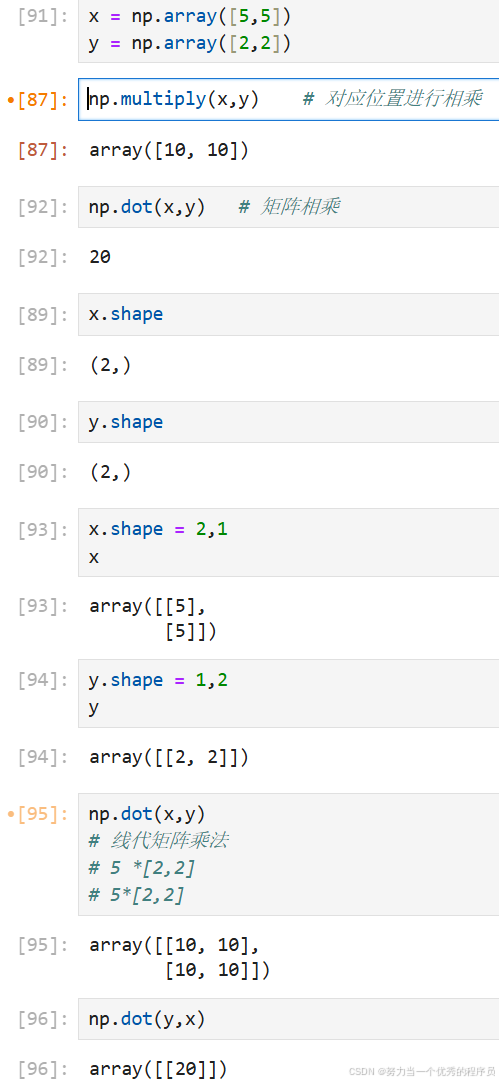
1.multiply、dot乘:
- multiply:对应位置进行相乘
- dot:矩阵乘法
2.与、或、非:
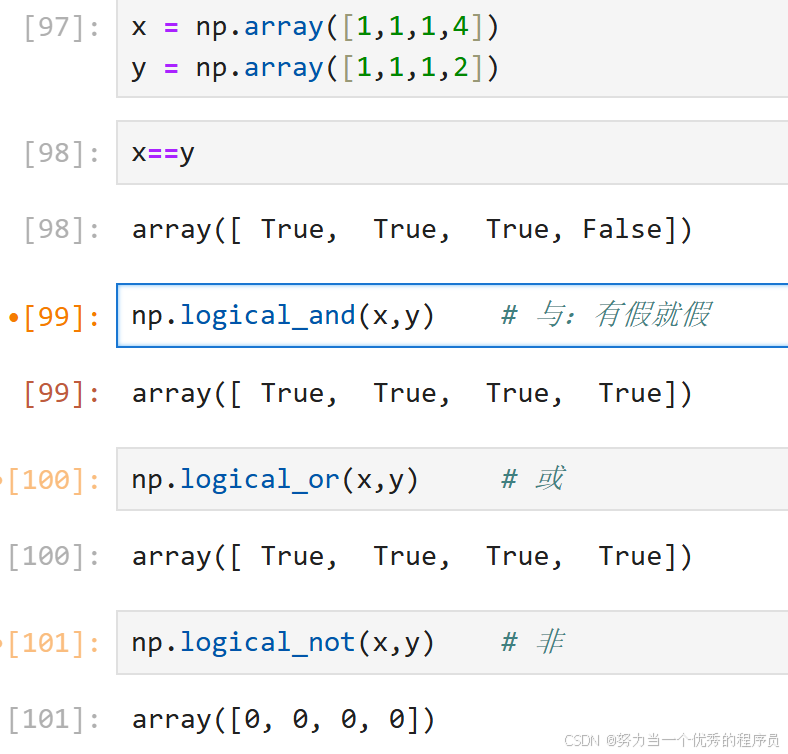
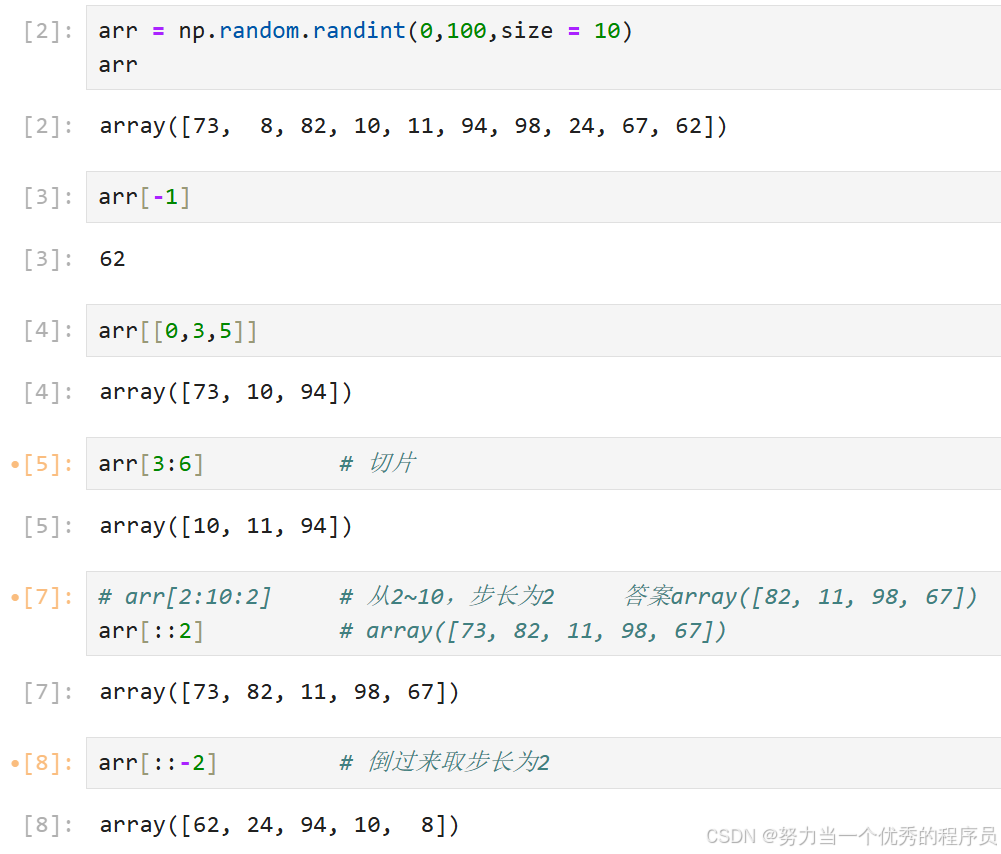
十.索引、切片和迭代:
1.基本索引、切片:
1.1.一维数组:
1.2.二维数组:
【注意】遵循规则:先行后列,先一维后二维……

2.‘花式’索引:

十一.函数应用:
1.函数求和、积:
<1>sum+和:
- sum(参数)
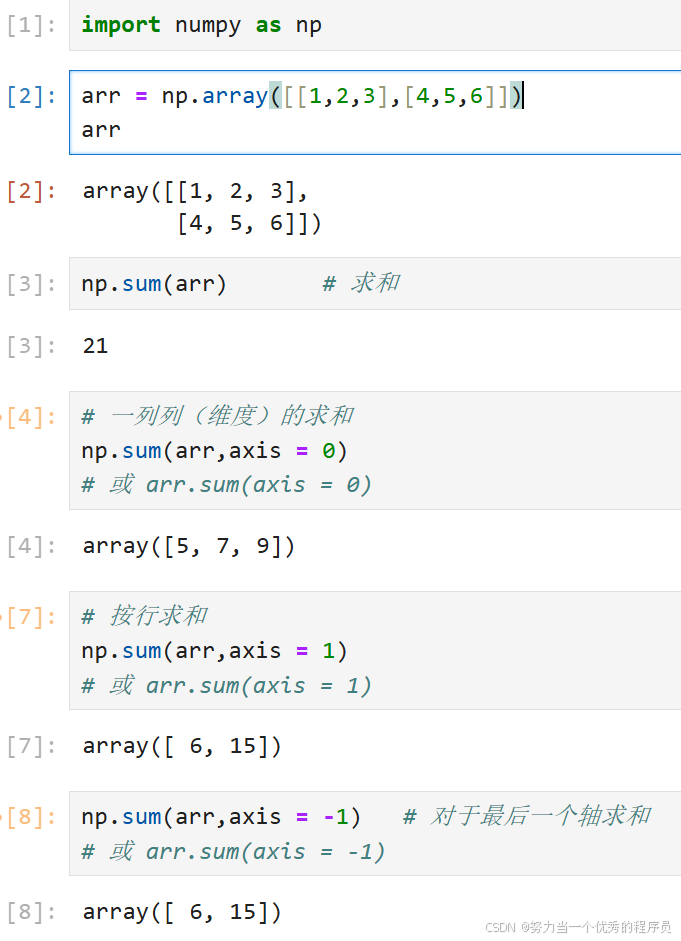
【注意】axis值对应的是大括号 。
【解释】axis = 0也就是[[1,2,3],[4,5,6]]里面的大括号,最终变成单位块求和[1,2,3]+[4,5,6] =[5,7,9];axis=1也就是内嵌的小括号:[1,2,3]的括号和[4,5,6]的括号去掉,[1+2+3,4+5+6],块的相加:1+2+3=6……
<2>prod积:
- .prod()

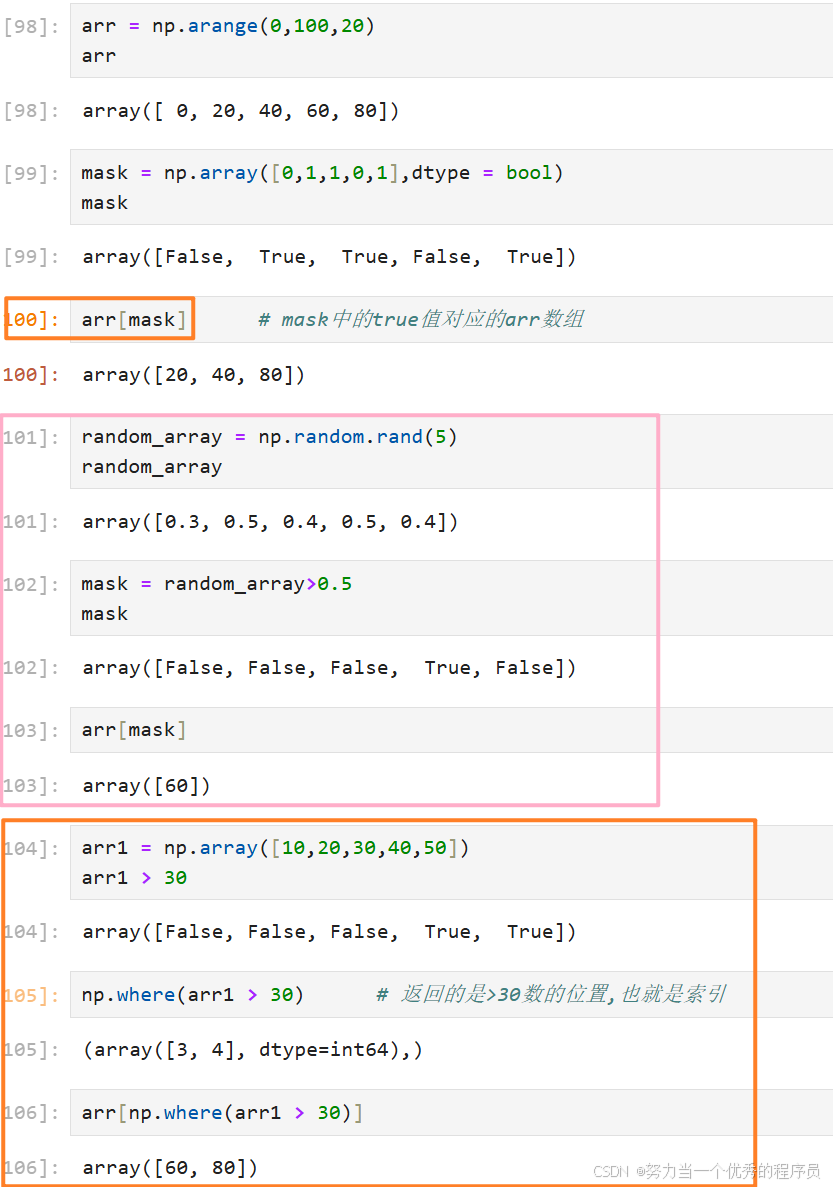
2.最大/小值:
<1>求值:
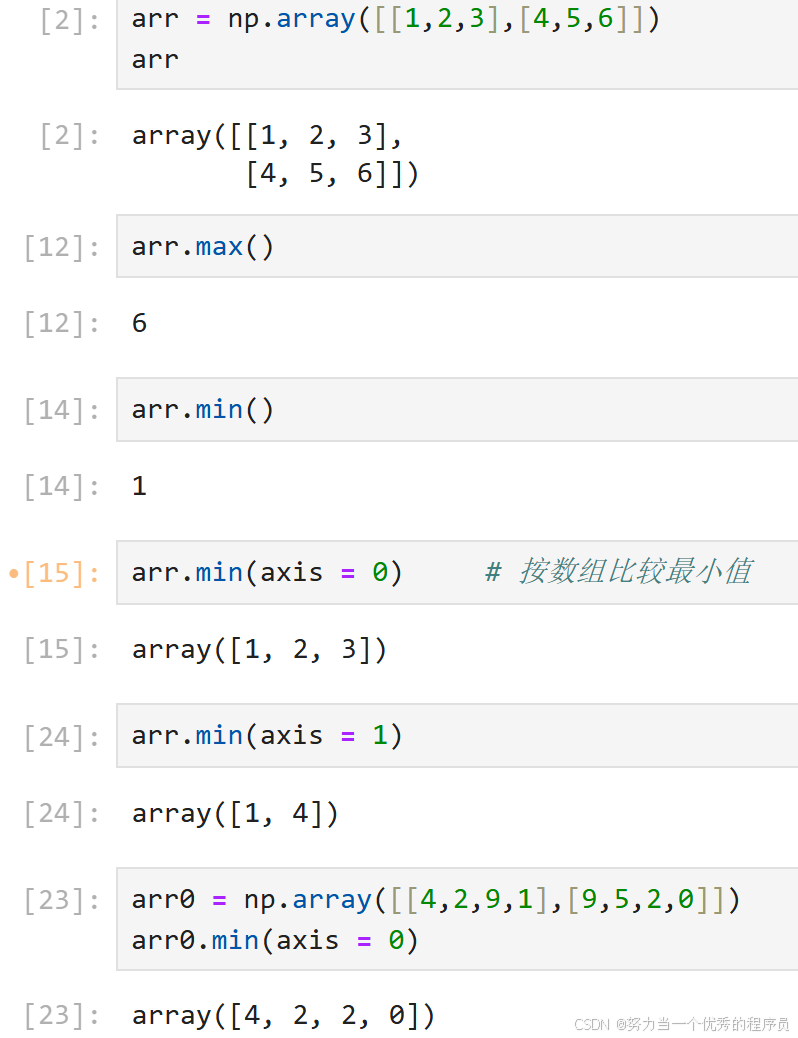
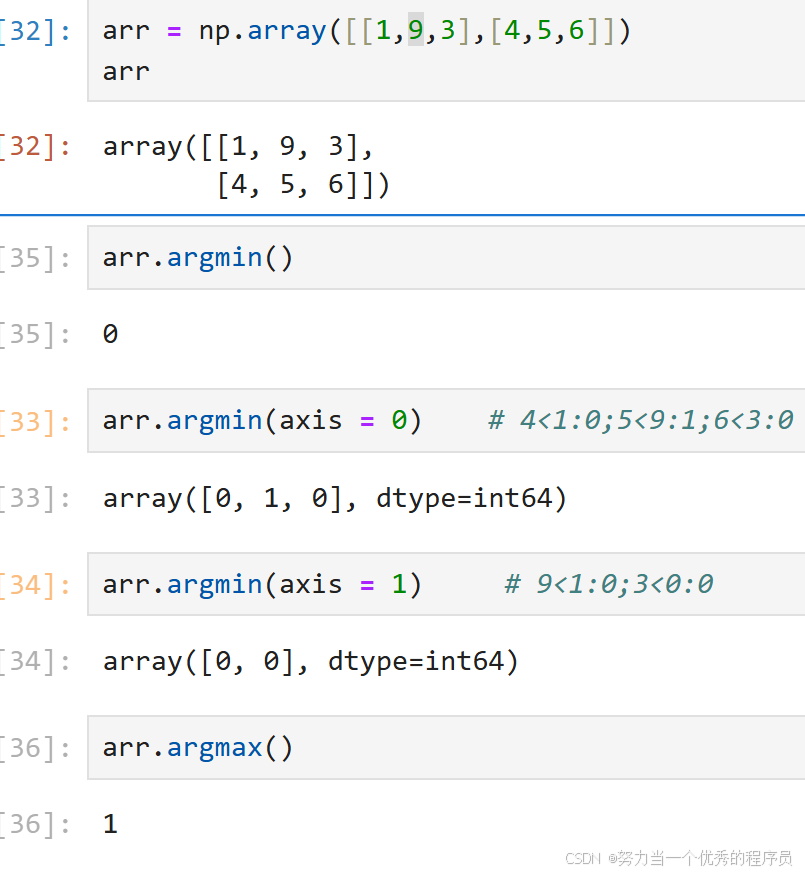
<2>argmin求最大/小值索引 :
- argmin():求最小值索引
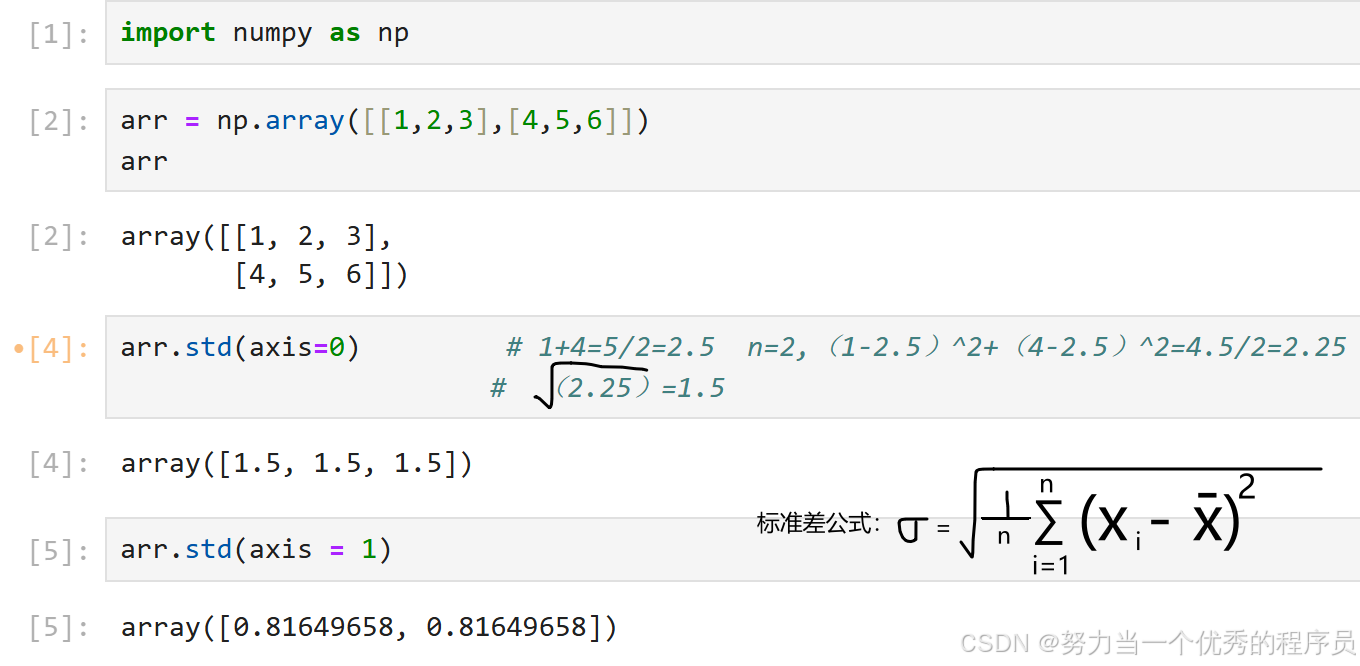
3.均值、标准差、方差:
<1>mean均值:
- .mean()

<2>std标准差:
- std()
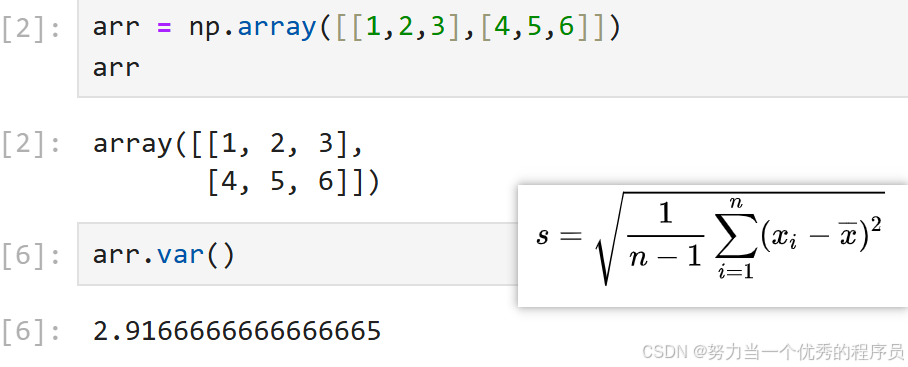
<3>var方差 :
- var()
4.round 四舍五入:
- round()
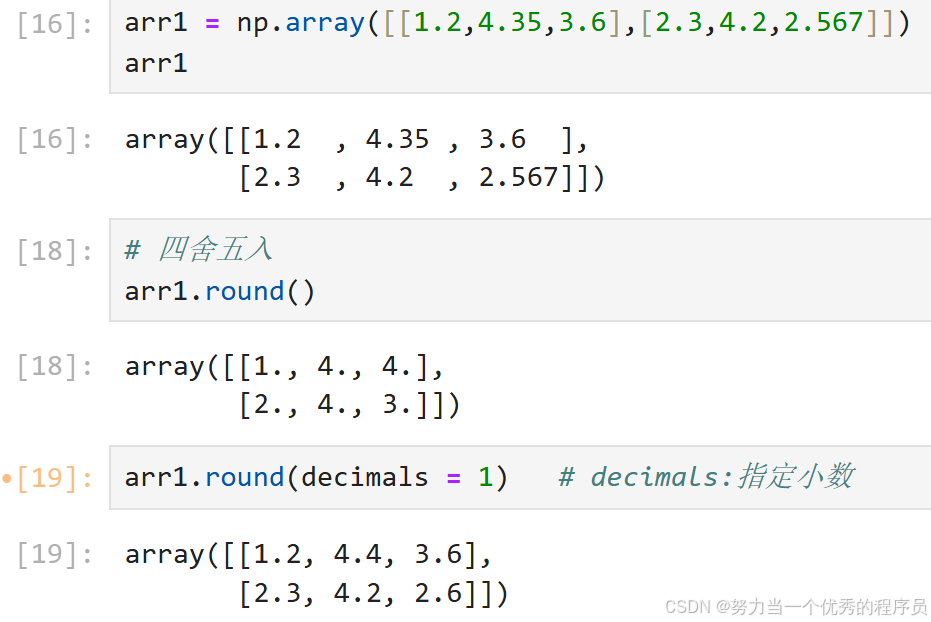
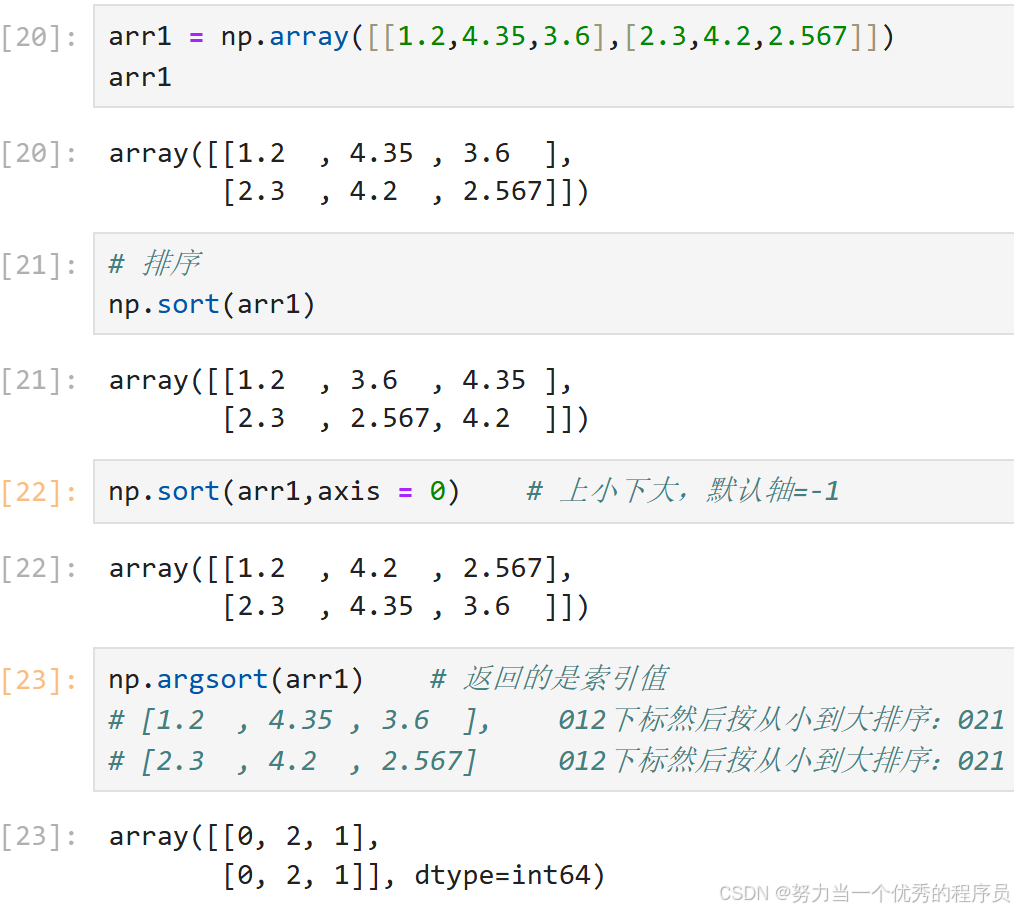
5.sort()排序:
- sort()
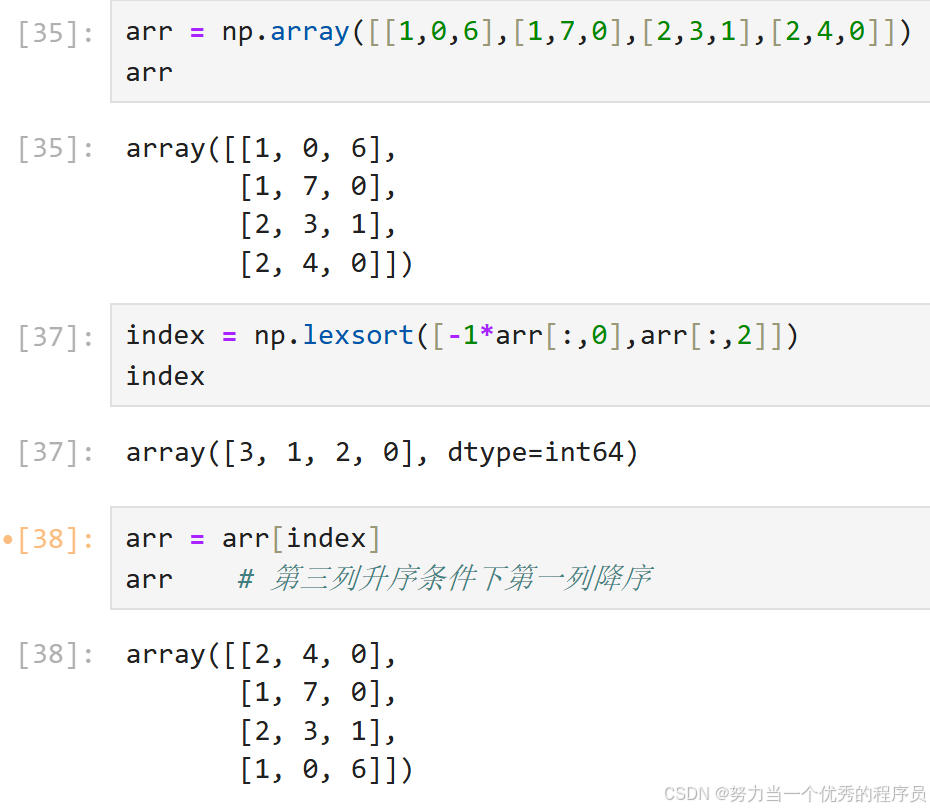
<1>lexsort()升序降序:
- lexsort()
6.linspace(),searchsort()插入:
- linspace():所要排序的数组;
- searchsort():所要插的位置索引
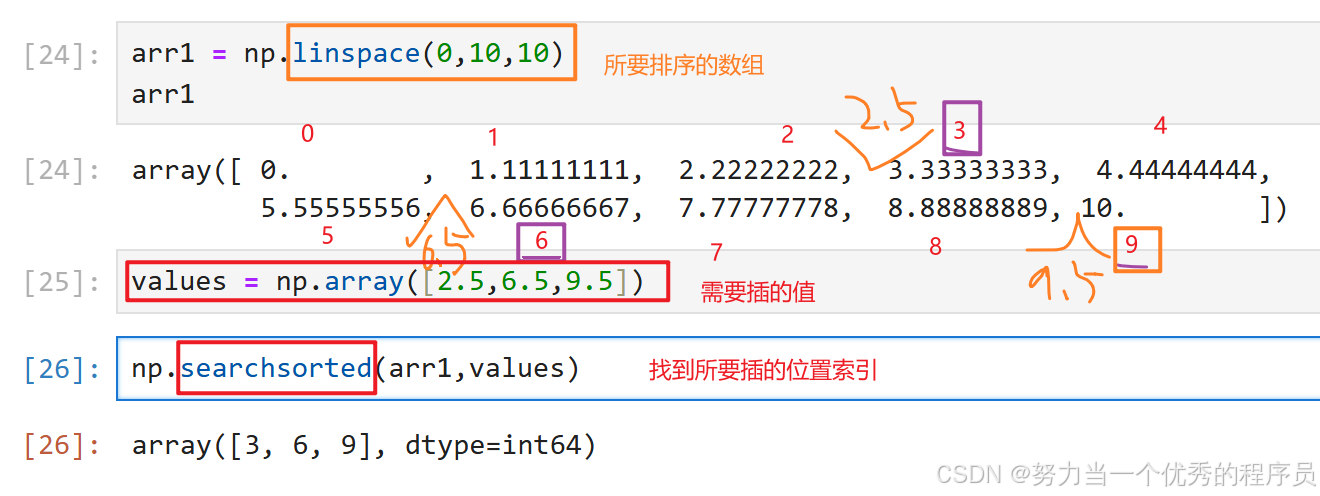
【注意】searchsort()中传入的数组必须是排好序的。
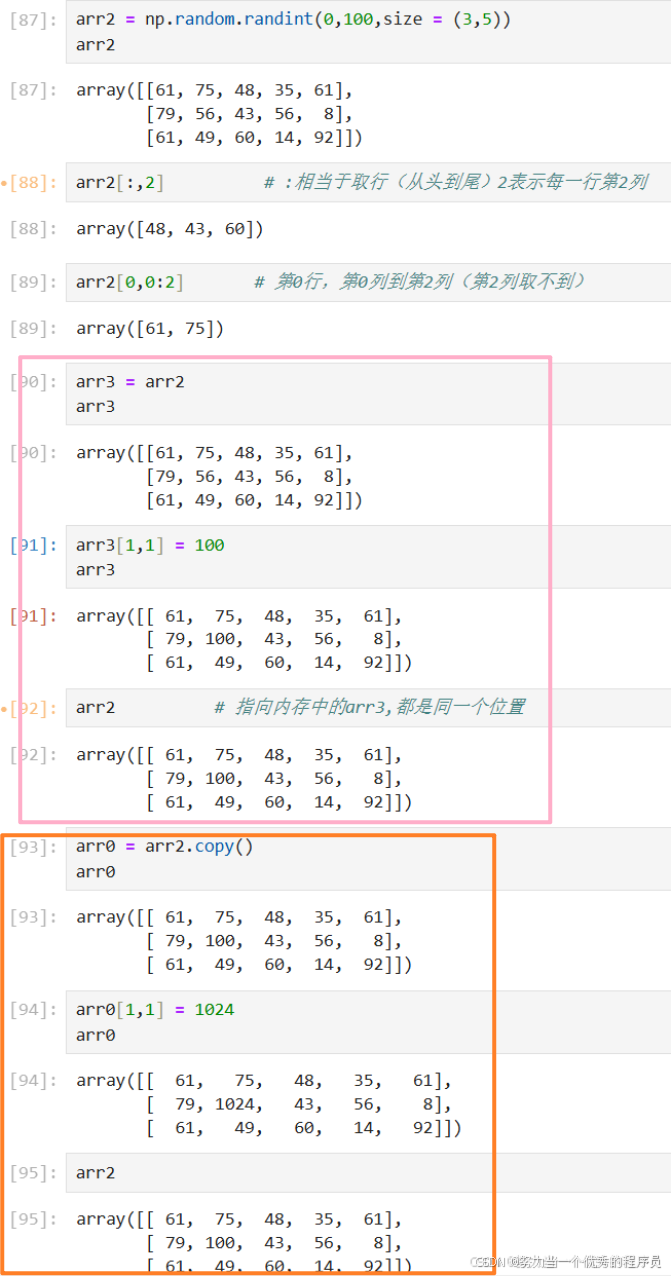
十二.复制和视图(了解):
1.没有复制:
a = np.random.randint(0,100,size = (2,3))
b = a
b # array([[27, 39, 33], [92, 46, 63]])# a is b # True对应的是同一个内存对象
b[0,0] = 1024
display(a,b)
#结果是: array([[1024, 39, 33],[ 92, 46, 63]]) array([[1024, 39, 33], [ 92, 46, 63]])2.查看/浅拷贝:
- view():创建一个查看相同数据的新数组对象;
a = np.random.randint(0,100,size = (2,3))
b = a.view() # 使用a中数据创建一个新数组对象
a # array([[64, 34, 35],[92, 33, 84]])
b # array([[64, 34, 35],[92, 33, 84]])a is b # False不同名,但是对应同一个内存对象b.flags.owndata # False,b中数据不是自己的
a.flags.owndata # Trueb.base is a # True,b视图的根数据和a一样 b[0,0] = 1024
display(a,b) # 结果是array([[1024, 34, 35], [ 92, 33, 84]]) 换行 array([[1024, 34, 35], [ 92, 33, 84]])【注意】不同数组对象可以共享相同的数据。
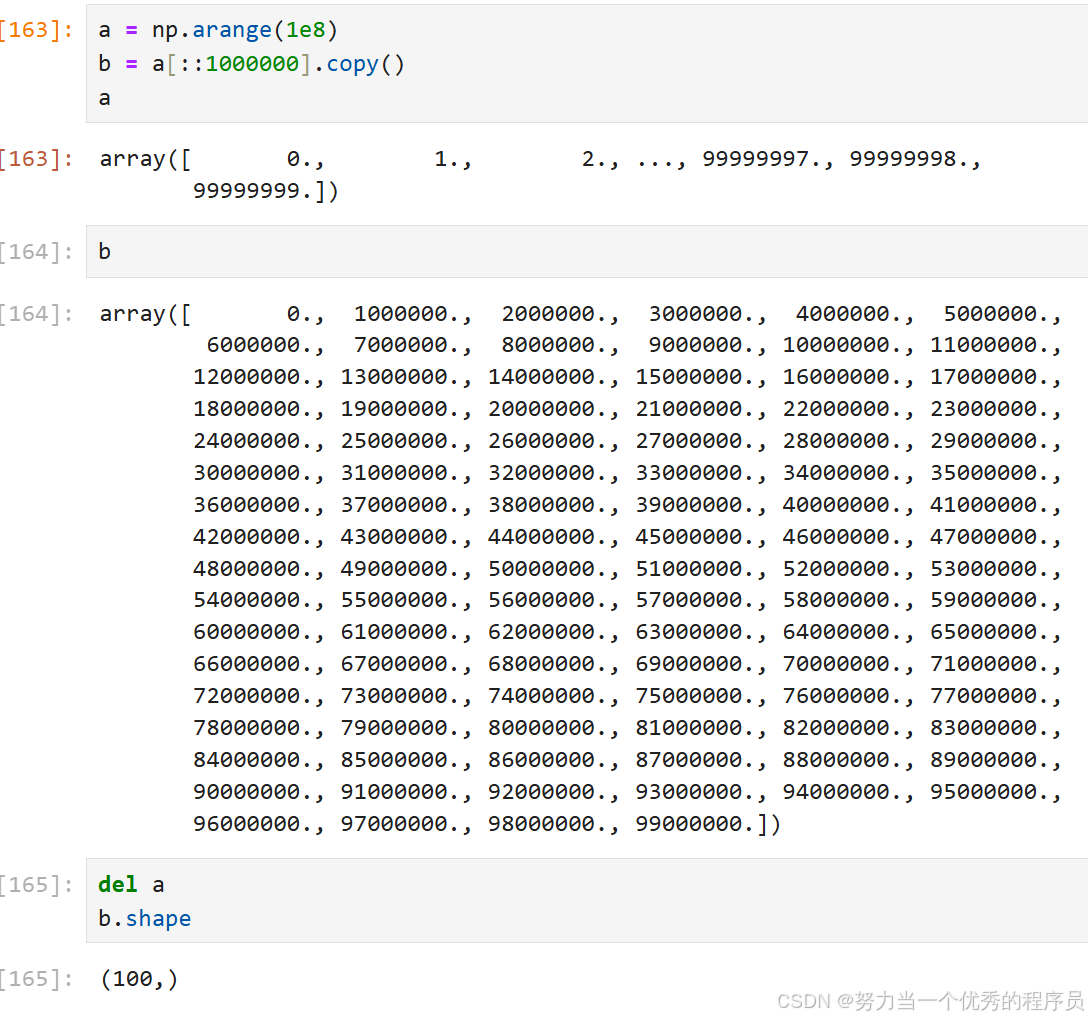
3.深拷贝:
a = np.random.randint(0,100,size = (2,3))
b = a.copy() # 复制a中数据创给一个新数组对象b
b # array([[38, 85, 68], [90, 26, 57]])a is b # False不同名,也不是同一个内存对象b.flags.owndata # True
a.flags.owndata # Trueb.base is a # Falseb[0,0] = 1024 # b变a不变
display(a,b) # 结果是array([[38, 85, 68], [90, 26, 57]]) array([[1024, 85, 68], [ 90, 26, 57]])- copy():应该在不需要原来数组的情况下,切片后调用。
- 例:假设a是一个巨大的中间结果,而最终结果b仅包含一小部分a,则在b使用切片进行构造时,应该制作一个深拷贝。