
效果展示
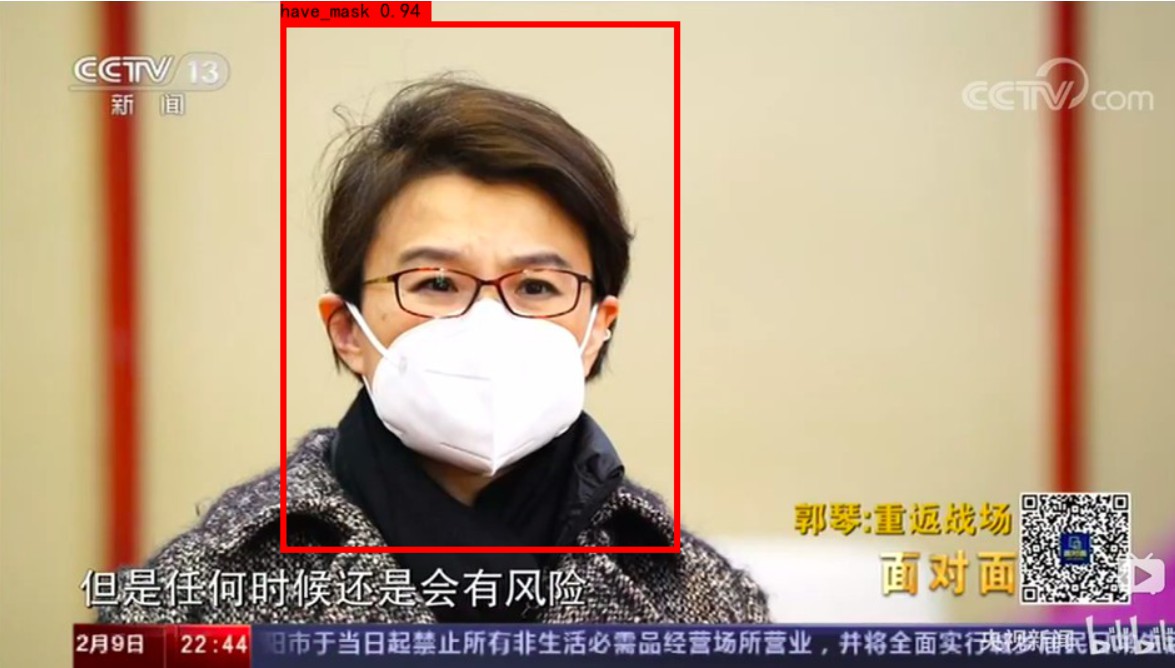
项目介绍:
基于YOLOv3(You Only Look Once version 3)的人体口罩佩戴检测项目是利用先进的计算机视觉技术来自动识别和判断在公共场所中人们是否正确佩戴口罩的一种应用。这种检测系统在COVID-19大流行期间变得尤为重要,因为口罩佩戴成为预防病毒传播的关键措施之一。
项目概述
YOLOv3是一种实时的目标检测系统,它通过单次通过图像就能同时预测物体的位置和类别。相比于其他目标检测算法,如R-CNN系列或SSD,YOLOv3具有更快的检测速度和较高的准确率,尤其是在小物体检测方面表现良好。
项目流程
-
数据集准备:
- 收集大量包含戴口罩和不戴口罩人脸的图片,并对这些图片进行标注。
- 标注工作通常涉及使用工具(如LabelImg)标记每个图像中人脸的位置以及是否戴有口罩。
-
模型配置与训练:
- 修改YOLOv3的配置文件,以适应新任务,包括定义类别数量(通常是两类:戴口罩和不戴口罩)。
- 使用准备好的数据集训练YOLOv3模型,调整超参数以获得最佳性能。
- 训练过程可能需要大量计算资源和时间,尤其是对于复杂的模型和大规模数据集。
-
模型测试与优化:
- 在独立的测试集上评估模型的性能,如准确率、召回率和F1分数。
- 可能需要进行多次迭代,调整模型结构或训练策略以提高性能。
-
部署:
- 将训练好的模型部署到实际环境中,例如安装在摄像头系统中,实现实时监控。
- 部署可能涉及到模型的量化、剪枝等优化操作,以降低资源消耗。
-
持续监控与维护:
- 在实际应用中持续监控模型的性能,确保其有效性。
- 随着时间和环境的变化,可能需要重新训练模型以保持准确性。
技术细节
- 模型架构:YOLOv3基于一个深度卷积神经网络(CNN),它通过多个卷积层和残差块来提取图像特征。
- 损失函数:YOLOv3使用一种组合了分类和定位损失的多任务损失函数,以确保模型能够同时准确预测物体的位置和类别。
- 后处理:检测结果通过非极大值抑制(Non-Maximum Suppression, NMS)进一步筛选,去除重叠的边界框。
实际应用
- 在机场、车站、学校、商场等人流密集场所,用于自动化监控和合规性检查。
- 在企业内部,用于员工健康管理和安全规范执行。
- 作为智能安全系统的一部分,用于识别潜在的健康风险。
基于YOLOv3的人体口罩佩戴检测项目是一个综合性的工程挑战,涉及机器学习、计算机视觉和系统集成等多个领域。
环境
工欲善其事必先利其器
- Python: 3.7.4
- Tensorflow-GPU 1.14.0
- Keras: 2.2.4
训练
准备数据集
按照VOC数据集的格式来准备数据集,及图片以及xml标签
VOCdevkit-VOC2007├─ImageSets # 存放数据集列表文件,由voc2yolo3.py文件生成├─Annotations # 存放图片标签,xml 格式├─JPEGImages # 存放数据集中图片文件└─voc2yolo3.py # 用来生成数据集列表文件将你准备的数据集文件放入JPEGImages以及ImageSets文件中,然后运行python voc2yolo3.py来生成ImageSets中的数据列表文件。
关键代码部分:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/13 21:46
# @Author : codingchaozhang
from nets.yolo3 import yolo_body
from keras.layers import Input
from yolo import YOLO,detect_video
from PIL import Imageyolo = YOLO()while True:try:detect_video(yolo)except:print('Open Error! Try again!')continueyolo.close_session()生成YOLOV3所需数据
在根目录下,运行 python voc_annotation.py,程序将在根目录下生成用于训练所需的数据列表,运行前记得修改voc_annotation.py中的classes。
YOLOv3训练
训练步骤
-
1.下载yolov3的权重文件
-
2.执行如下命令将darknet下的yolov3配置文件转换成keras适用的h5文件。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5 -
3.在根目录下,运行
train.py进行训练。可以根据情况修改train.py中的参数。
测试
-
1.单张图片测试,需修改yolo.py文件中模型的位置,替换成你训练好的模型。然后在根目录下,运行
python predict_img.py进行测试。 -
2.自己电脑摄像头实时检测,在根目录下运行
python predict_video.py












