
为了先填充好数据在上线,在本地搭建了一个网站,并用火车头采集数据填充到里面。
开始很上手,因为找的网站的分类中是有分页的。很快捷的找到页面标识。
但是问题来了,如今很多网站都是采用的Ajax加载数据,根本没有分页的URL。比如:CSDN,IT168等等,都是采用下拉到一定程度,自动加载数据出来。
在没有页码的情况下,直接采集当前首页的20-30篇文章,后面的都无法采集到。
经过在网上查找教程,总算有了方法,但是相对直接加入页码采集,多了一个步骤。
应该如何做?
1. 获取目标站API地址
在目标页面按F12或Ctrl+Shift+C打开审查元素,然后点Network选项卡,通过下滑的操作实时监控Network中出现的链接。
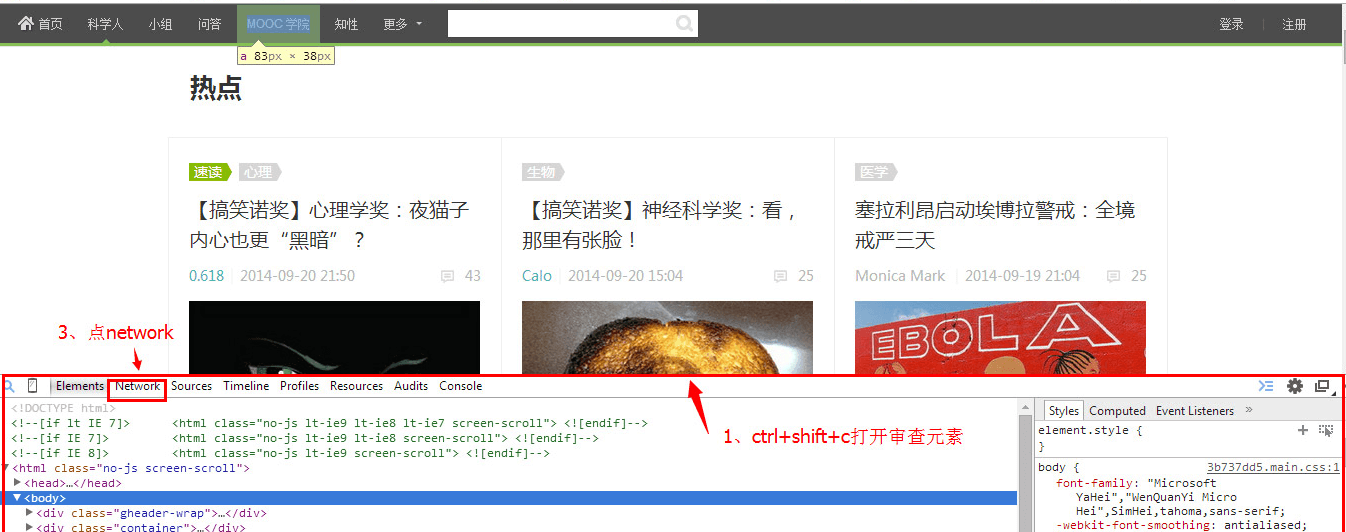
首先进入Network查看
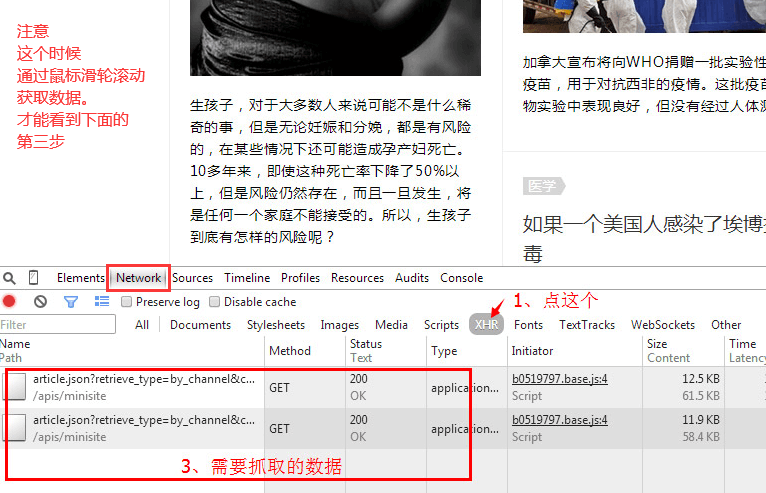
GET到json数据
然后点击这个链接,查看规律后将他复制下来。

将这段链接复制下来
2.利用火车头采集这个API中的文章链接
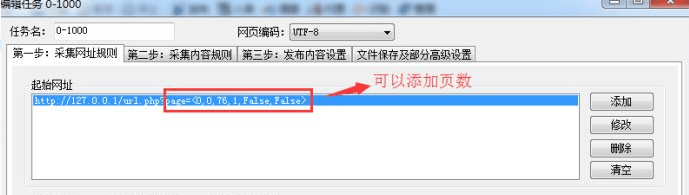
这里做一个假设,实际填写的是上面的API地址。
采集内容规则的设置
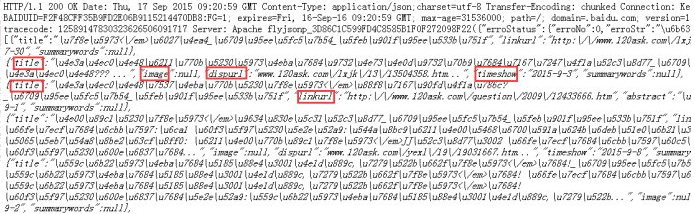
从上图可以指导链接地址在:linkurl:"" 里,然后进入第二部采集内容
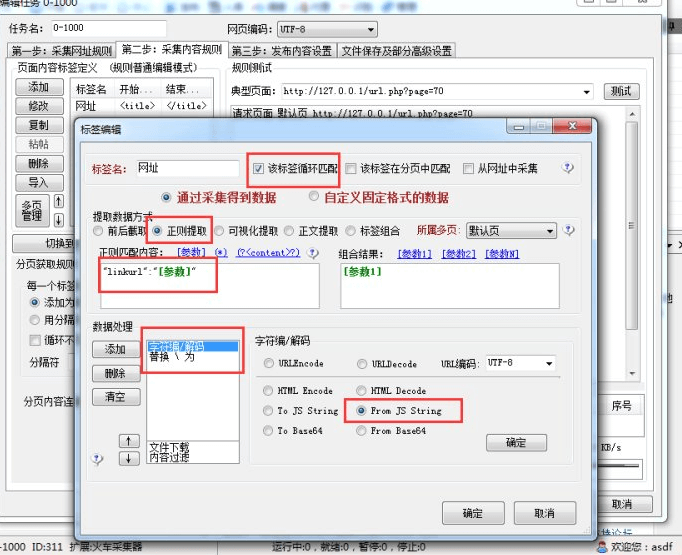
这里选择循环匹配,不然只会采集到一个链接。
数据处理一下编码和斜杠(因为采集的url有很多 \ 的转义,直接将这个剔除)
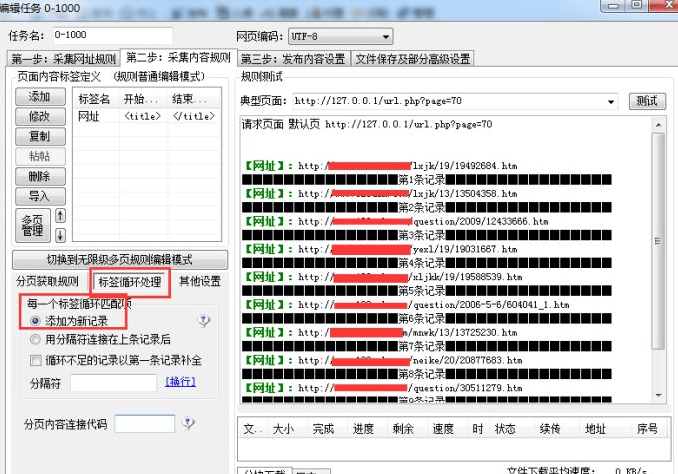
测试一下页面就可以获取到文章的URL链接。
获取到文章的链接后,如何采集它们?
当采集到这些文章的URL后,我们先要在 第三步:发布内容设置 ,将连接保存在桌面处理。
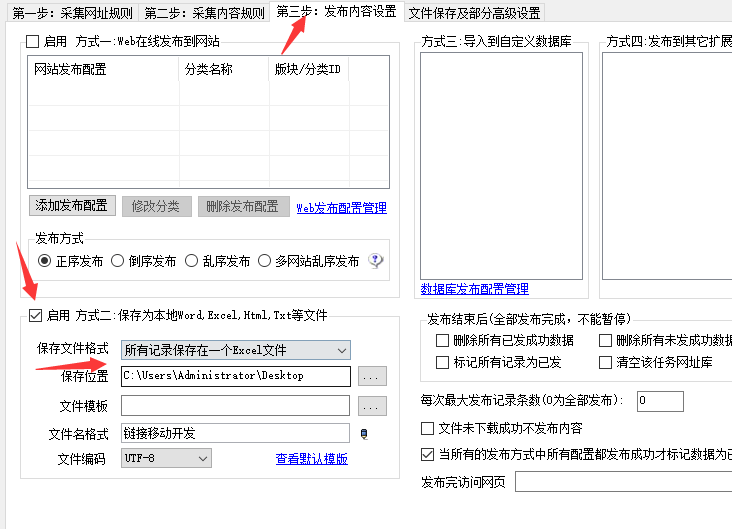
我将他保存在Excel文件(主要是我导出的TXT不完整),然后在Excel中处理好在复制到TXT中。
这个时候我们就要采集这些文字的链接了。
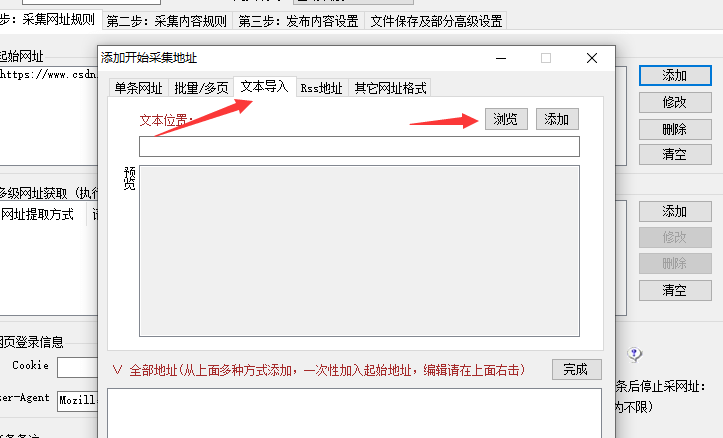
新建一个采集任务,然后将保存的TXT导入,然后依次进行采集,后面的工序就不说了,和分页采集的步骤是一样的。
本文由2号站长网,五车二原创,原文链接:https://www.zz2zz.com/19852.html,转载请注明出处。












