
目录
一、缓存穿透
二、布隆过滤器
三、缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?
四、缓存预热你是怎么做到的?
五、如何避免或者减少缓存雪崩(缓存击穿的升级版)?
六、穿透和击穿有什么区别?它俩一个意思还是截然不同?
七、穿透和击穿你有什么解决方案?如何避免?
八、假如出现了缓存不一致,你有哪些修补方案?
九、缓存击穿
十、缓存雪崩
十一、延迟双删
十二、共享锁与排他锁
十三、redis分布式锁,是如何实现的?
十四、Redisson实现分布式锁如何合理的控制锁的有效时长?
十五、Redisson的这个锁,可以重入吗?
十六、Redisson锁能解决主从数据一致的问题吗
十七、Redis集群有哪些方案,知道嘛
十八、redis主从数据同步的流程是什么?
十九、主从同步流程(全量+增量)
二十、你们使用redis是单点还是集群,哪种集群?
二十一、Redis分片集群中数据是怎么存储和读取的?
二十二、Redis集群脑裂,该怎么解决呢?
二十三、Redis集群的最大槽数为什么是16384个?
二十五、介绍一下redis的主从同步
二十六、Redis哨兵领导者选举机制?
二十七、Redis脑裂
二十八、哨兵结点的数量应该为奇数,这是为什么?
二十九、怎么保证Redis的高并发高可用
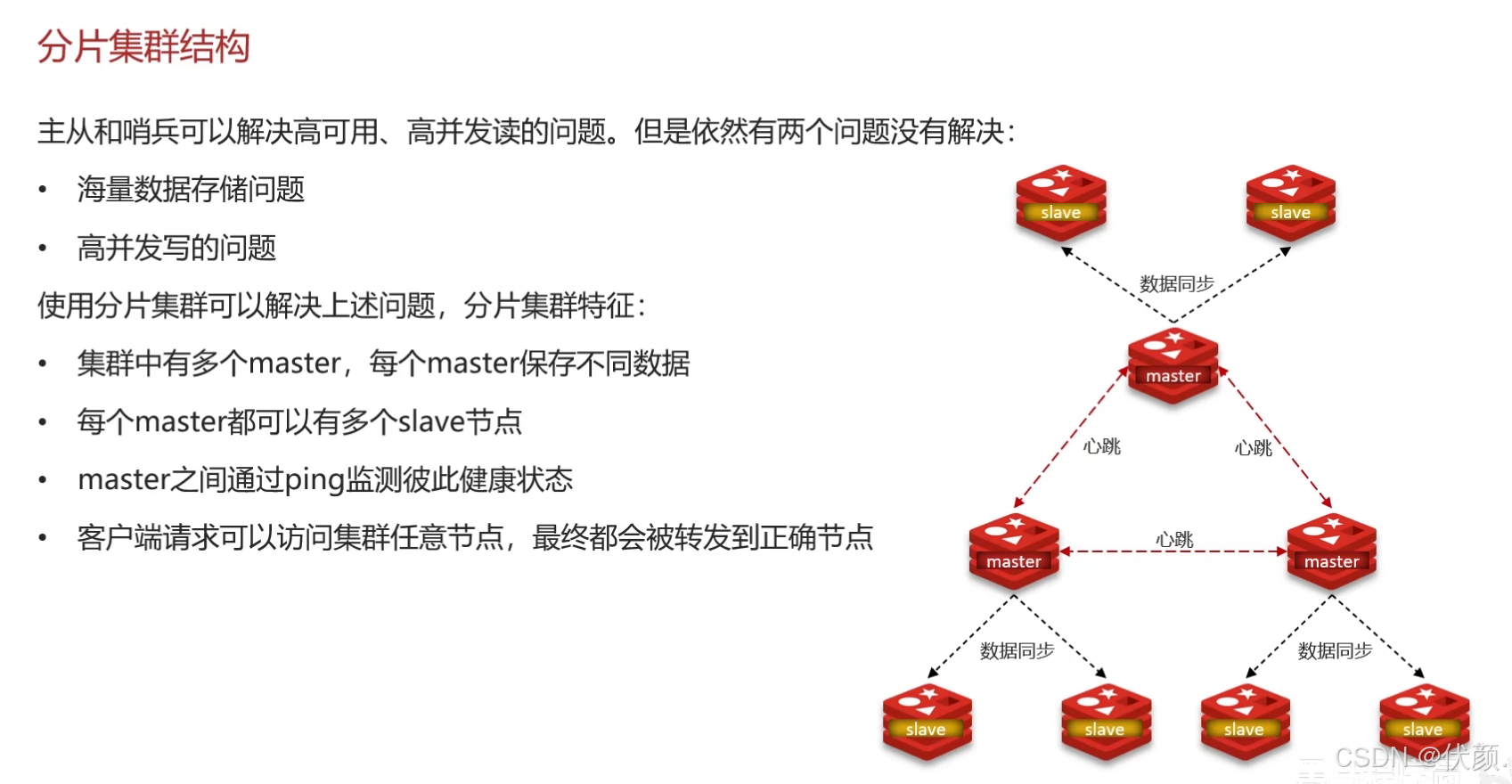
三十、Redis分片集群。解决海量数据存储问题以及高并发写的问题。
三十一、Redis的分片集群有什么作用?
三十二、Redis分片集群中数据是怎么存储和读取的?
三十三、Redis是单线程的,但是为什么还那么快?
三十四、I/O多路复用模型
三十五、Redis网络模型
三十六、能解释一下I/O多路复用模型?
-
缓存 -- 缓存三兄弟(穿透、击穿、雪崩)、双写一致性、持久化、数据过期策略、数据淘汰策略
-
分布式锁 -- setnx redisson
-
消息队列,延迟队列 -- 数据类型
一、缓存穿透

比如:疯狂,大量请求查一个不在redis中也不在db中的数据,导致每次请求都会区查数据库---宕机
一般情况下,先查询缓存Redis是否有该条数据,缓存中没有时,再查询数据库
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透
缓存穿透带来的问题就是,当有大量请求查村数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库
解决:
-
redis缓存一个空数据,下次查反空 -- 内存消耗,可能还有数据不一致的情况
-
加一层布隆过滤器 -- 缓存预热,添加到缓存的时候也加到布隆里里

二、布隆过滤器
--依赖bitmap(位图) --应用 黑名单 垃圾邮箱

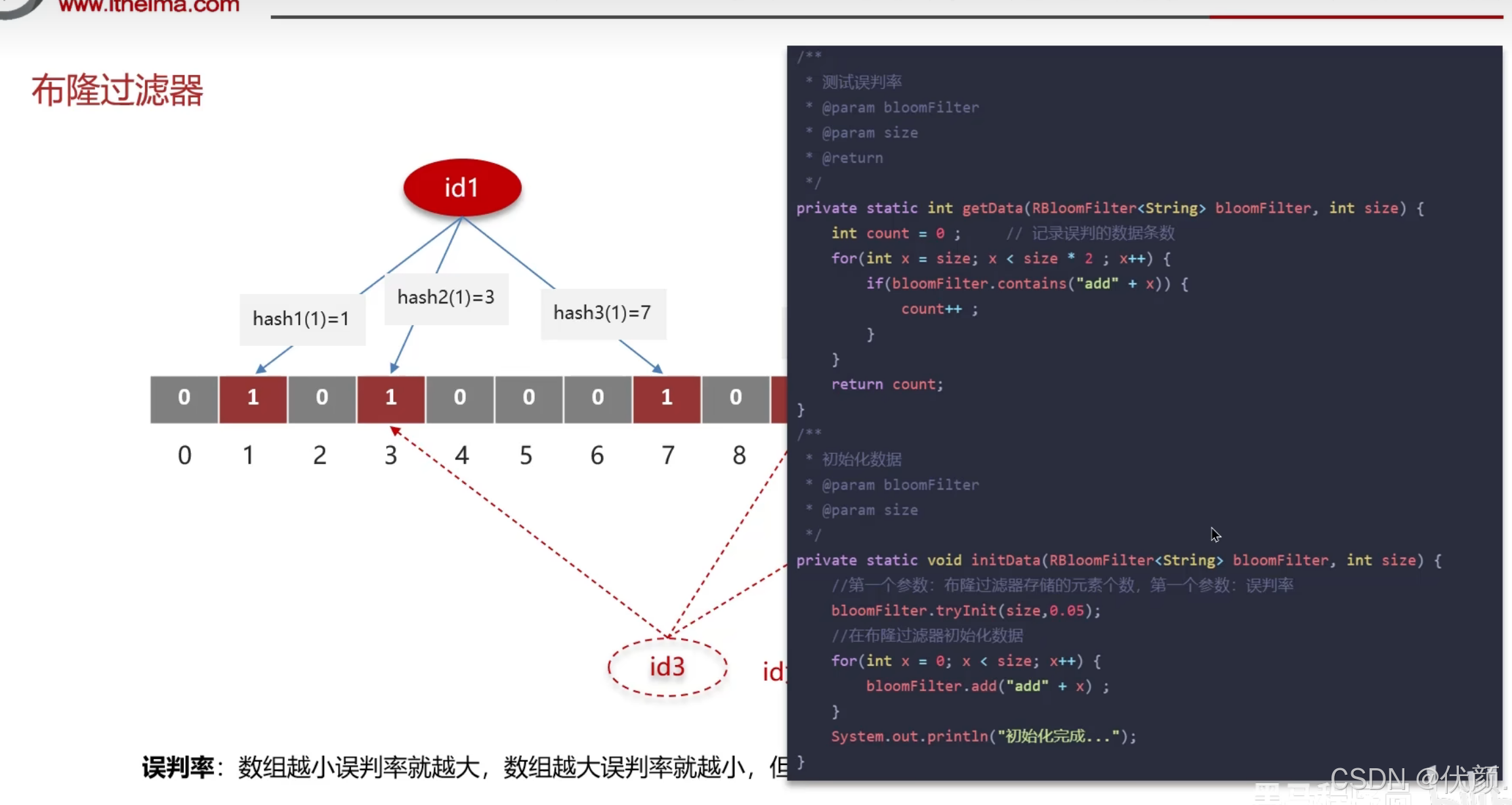
可以使用布隆过滤器解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于Redis前面挡着一个布隆过滤器
当有新的请求时,先到布隆过滤器中查询是否存在
如果布隆过滤器中不存在该条数据就直接返回
如果布隆过滤器中已存在,采取查询缓存Redis,如果Redis里没有查询到再去查询数据库。

三、缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?
-
缓存预热:
-
缓存预热是指在系统正式上线之前,提前将一些热点数据加载到缓存中,以减少首次请求时对数据库的压力。这可以通过批量请求或定时任务来实现。
-
-
缓存雪崩:
-
缓存雪崩是指在某个时间点,大量缓存失效或被清空,造成大量请求直接访问数据库,从而引起数据库的瞬时高负载,可能导致系统崩溃。
-
redis主机挂了,Redis全盘崩溃,偏硬件运维
-
-
缓存穿透:
-
缓存穿透是指请求的数据在缓存和数据库中都不存在(例如,查询一个错误的ID),每次请求都会直接打到数据库,无法利用缓存,从而给数据库带来很大的压力。
-
-
缓存击穿:
-
缓存击穿是指某个热点数据在缓存中失效,同时有大量请求同时访问这个数据,造成请求直接访问数据库。虽然这与缓存雪崩类似,但击穿主要是单个热点数据,而雪崩是多个数据同时失效。
-
遇到过哪几种情况?
在实际生产环境中,遇到过以下几个情况:
-
缓存雪崩:由于没有合理设置缓存的过期时间,导致在特定时刻大量缓存同时失效,数据库瞬间承受了很大压力。
-
缓存穿透:存在大量恶意请求查询不存在的数据,没有有效地过滤,这导致数据库频繁访问。
四、缓存预热你是怎么做到的?
实现缓存预热的方法包括:
-
在系统上线前,通过脚本将热点数据预先加载到缓存中。
-
使用定时任务,在系统的低峰时段定期更新缓存中的热点数据。
-
在发布新版本时,可以在部署过程中,提前访问一遍热点数据以填充缓存。
五、如何避免或者减少缓存雪崩(缓存击穿的升级版)?
为了避免或减少缓存雪崩,可以采取以下措施:
-
设置不同的过期时间:不要让所有缓存数据在同一时间失效,可以采用随机的过期时间。
-
使用互斥锁:在缓存失效后,只有一个请求可以去查询数据库并更新缓存,其他请求则等待。
-
监控和扩容:监控数据库性能,当发现异常流量时及时扩容,以应对突发流量。
六、穿透和击穿有什么区别?它俩一个意思还是截然不同?
穿透和击穿是截然不同的概念:
-
缓存穿透:请求的数据在缓存和数据库中均不存在,不会利用到缓存。
-
缓存击穿:请求的数据在缓存中失效,导致大量请求直接访问数据库。
七、穿透和击穿你有什么解决方案?如何避免?
-
缓存穿透(缓存和数据库中都不存在):
-
使用布隆过滤器:可以快速判断请求的数据是否存在,避免无效请求访问数据库。
-
对于非法请求进行限流和拦截。
-
-
缓存击穿(某个热点数据在缓存中失效):
-
设置互斥锁:确保只有一个请求在缓存失效时去加载数据库数据,其余请求等待。
-
采用“请求合并”技术,将多个同时请求合并为一个请求。
-
八、假如出现了缓存不一致,你有哪些修补方案?
对于缓存不一致的问题,可以考虑以下修补方案:
-
延迟双删:在更新数据库后,先删除缓存,再稍等几秒后再删除一次缓存,以降低缓存和数据库不一致的概率。
-
使用消息队列:在数据写入操作后,将变更信息发送到消息队列,随后由消费者监听该消息并更新缓存。
-
定期刷新缓存:实施定时任务,周期性地从数据库中重新加载数据到缓存,以确保数据的一致性。
九、缓存击穿
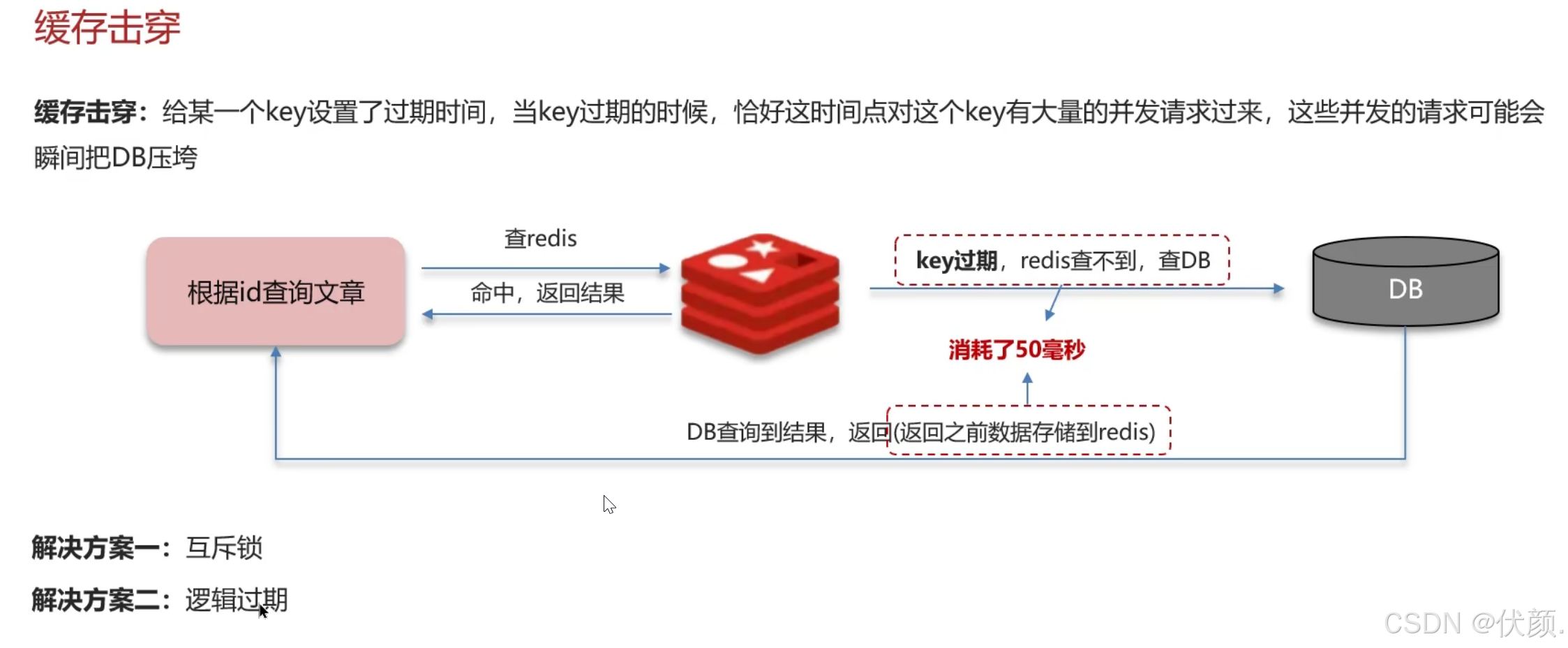
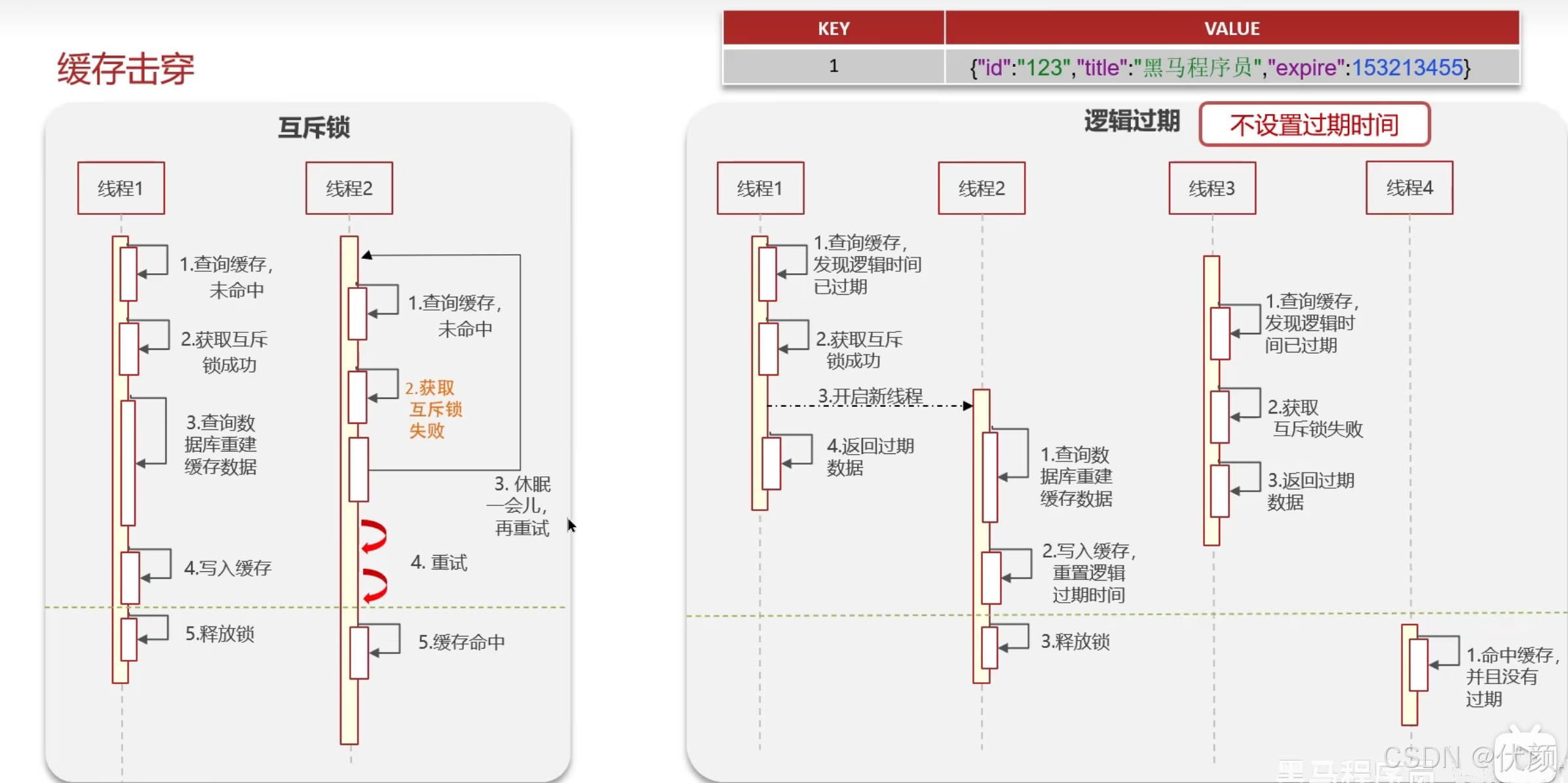

十、缓存雪崩


十一、延迟双删
删除Redis缓存。
更新数据库。
延迟一段时间后再次删除Redis缓存。
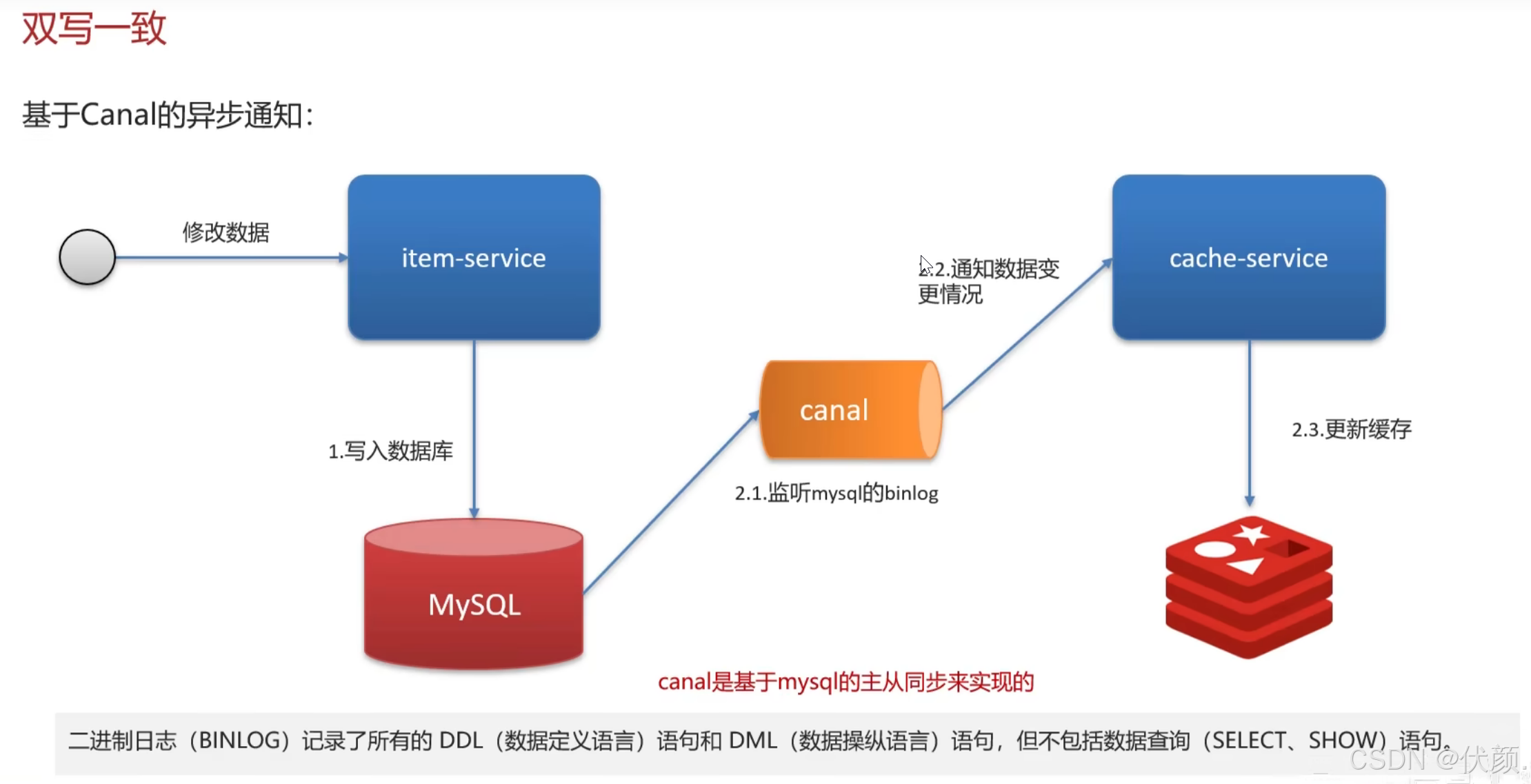
双写一致性,你先动缓存redis还是数据库?为什么?
-
在更新数据库后,如果立即删除Redis缓存,可能会有其他请求查询到旧数据并将其写回Redis。
-
如果先删除Redis缓存,再更新数据库,可能会有请求在缓存删除后查询到数据库的旧数据并将其写回Redis。
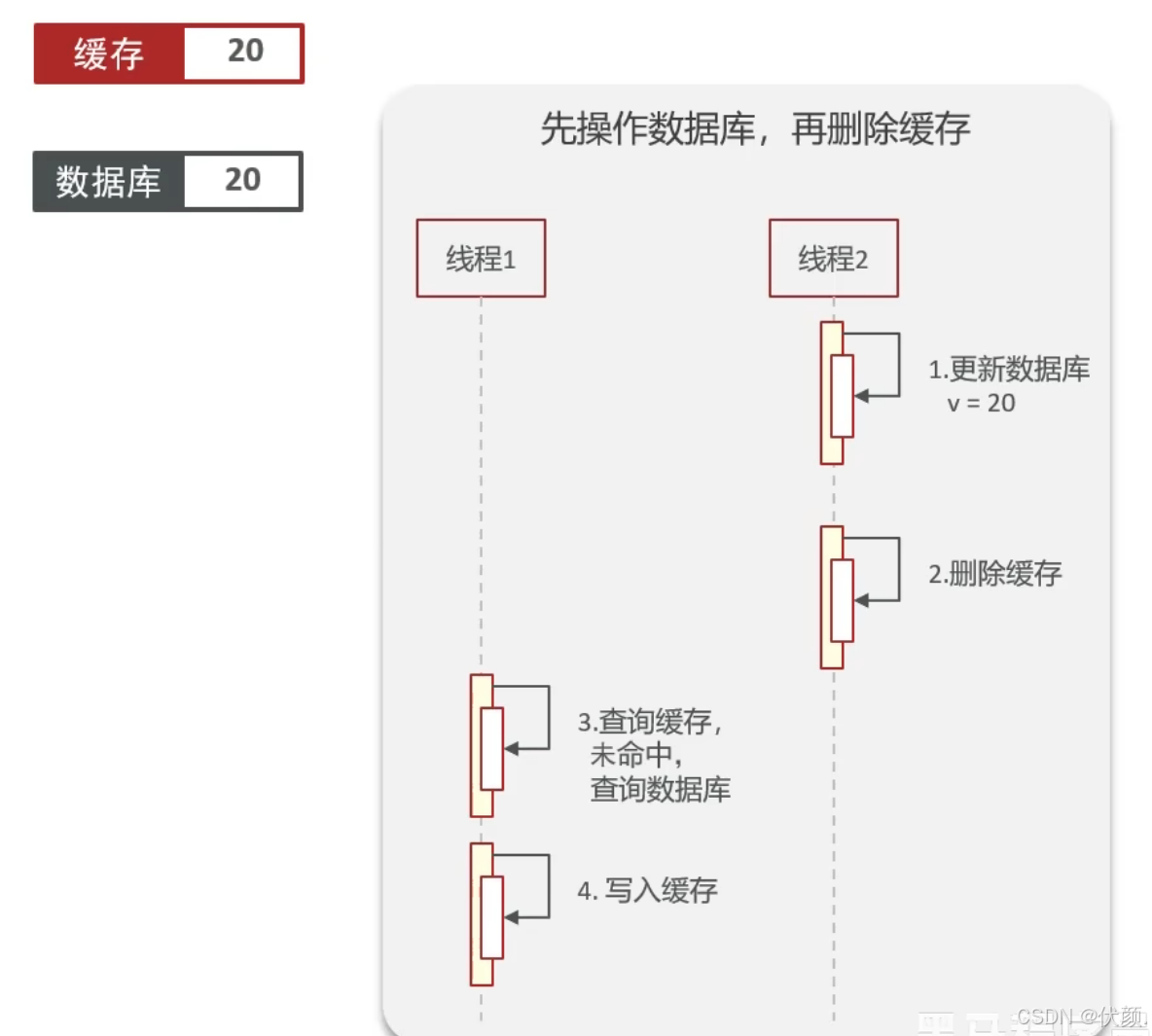
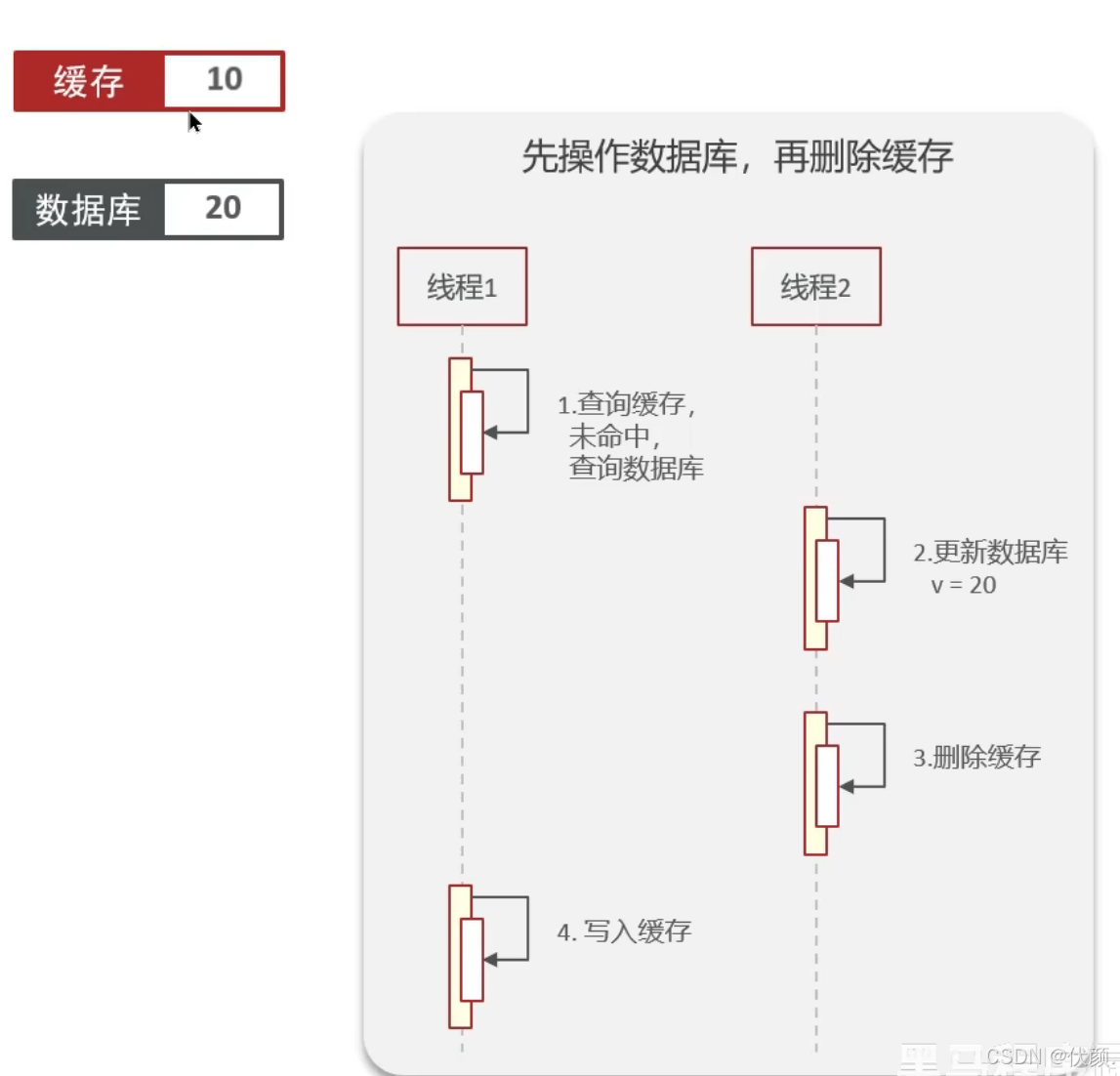
更新数据库 删除缓存 更新缓存
更新数据库,删除缓存
理想情况:
问题:旧数据+数据不一致。线程一去查数据,缓存未命中,查数据库拿到旧数据,回写的时候,此时有线程二去更新数据库为另一个值,又删除了缓存。线程一回写了一个旧值。
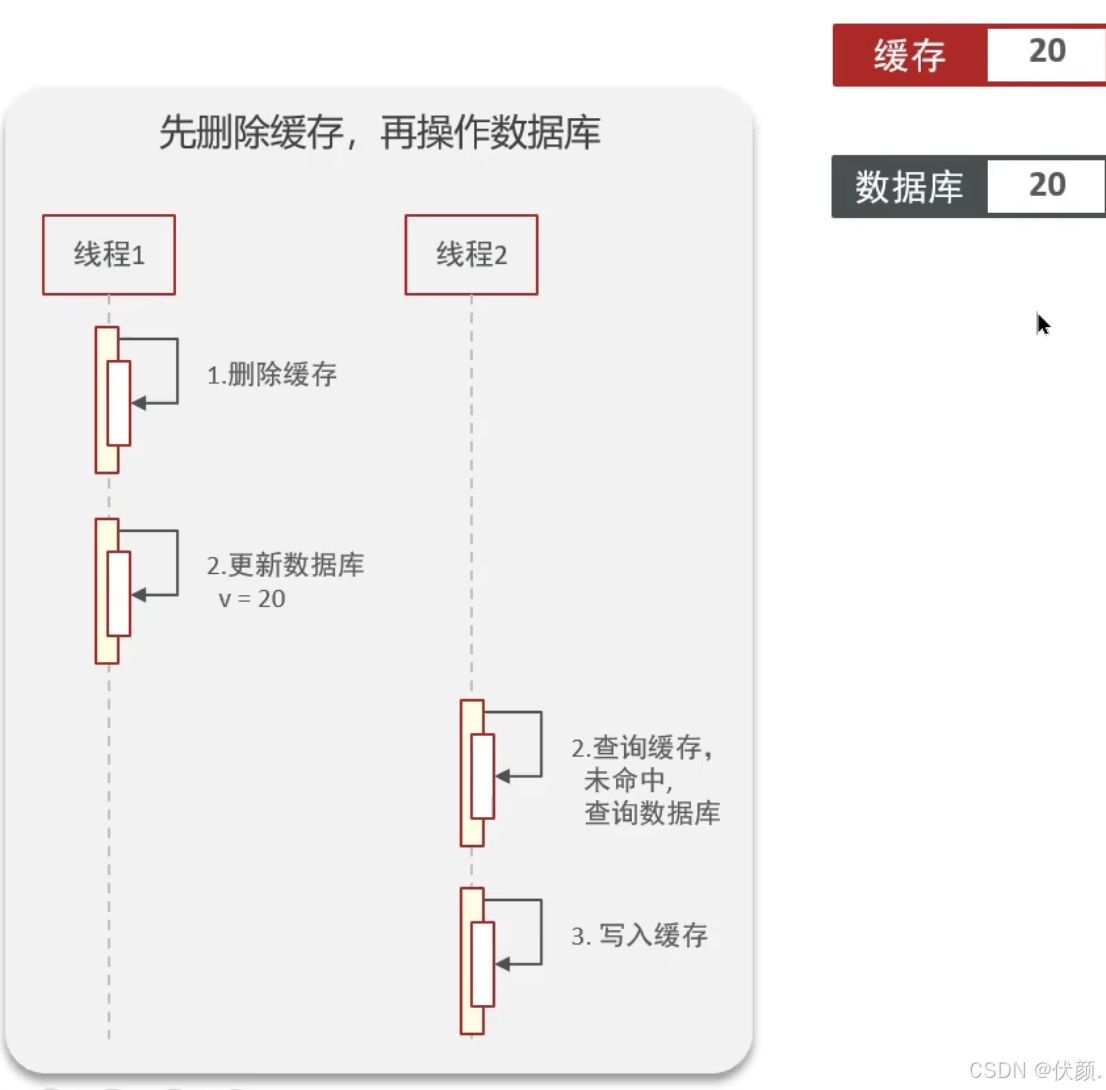
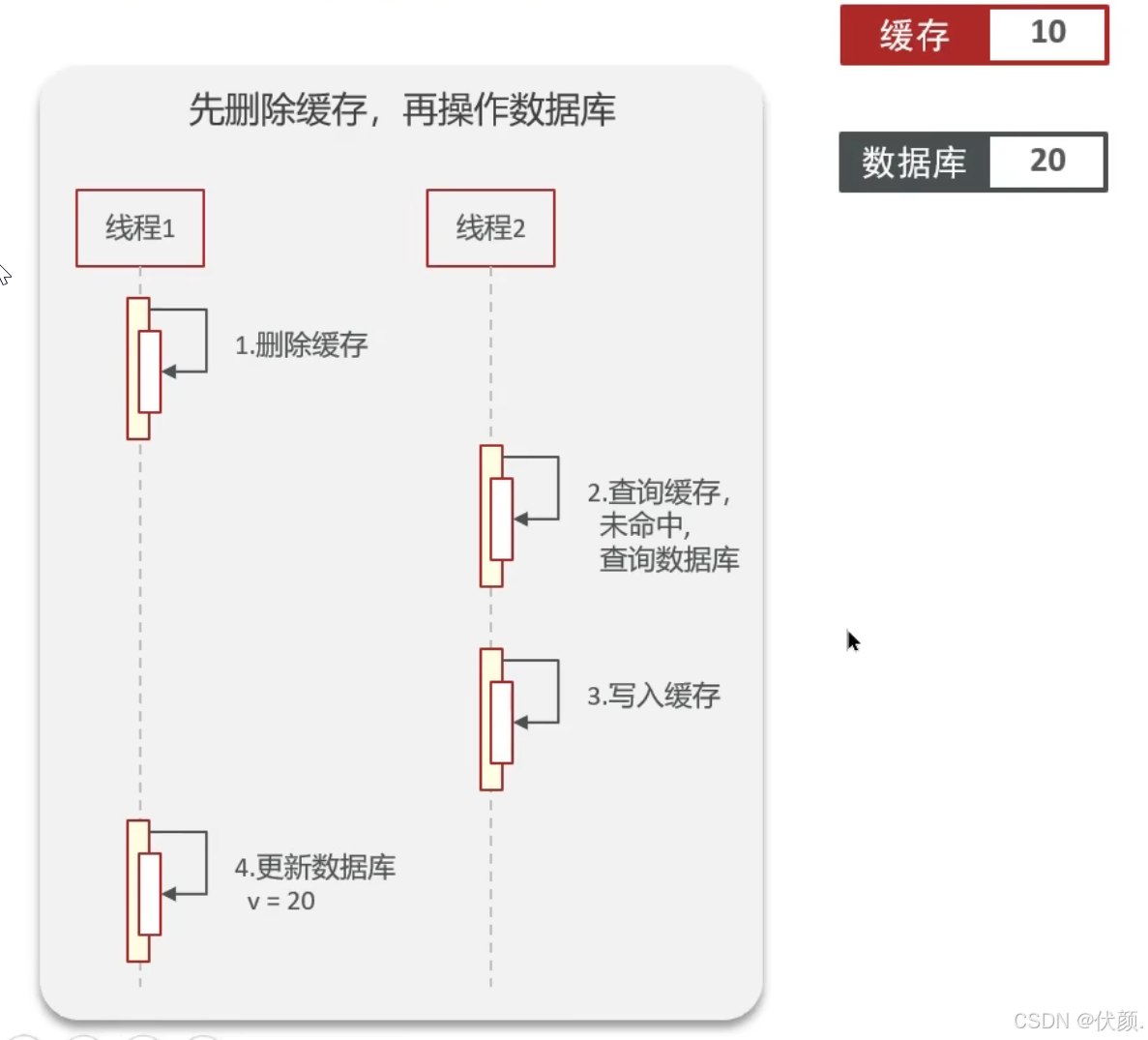
删除缓存,更新数据库
理想情况:
问题:旧数据,数据不一致。缓存删除后,业务直接查数据库,如果此时数据库还没有更新完,会读到旧数据,且会将旧值回写至缓存,就在这时,数据库更新完了,但是实际上跟缓存的数据是不一致的。导致数据不一致,第一步删除缓存白干了。
十二、共享锁与排他锁
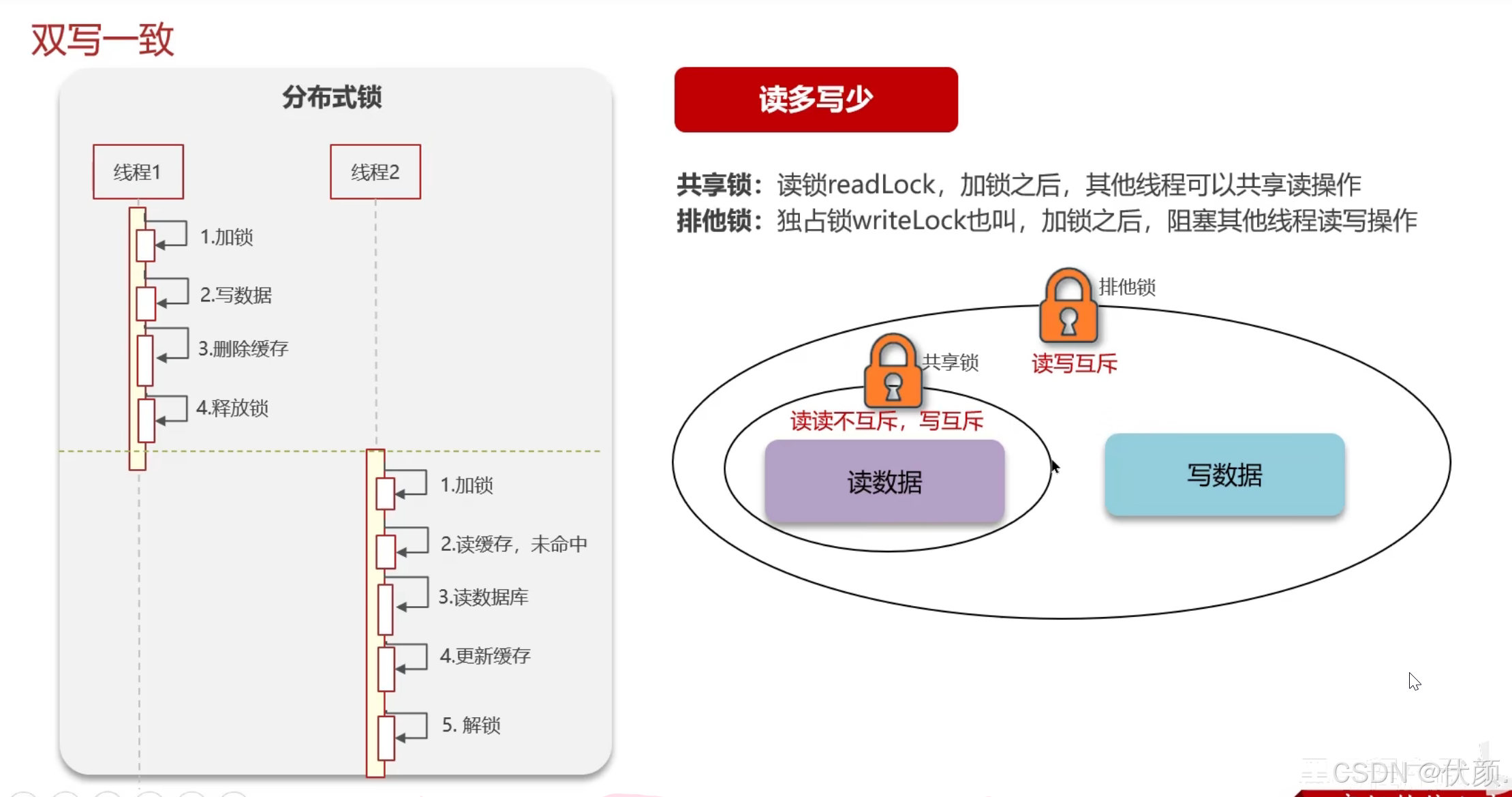
锁与读写操作的直接对应关系
共享锁(S锁) = 读锁 排他锁(X锁) = 写锁
这种命名是因为:
多个"读操作"可以同时进行(共享)
"写操作"必须独占资源(排他)
重新梳理四种情况的互斥关系
1. 读读不互斥 (共享锁之间兼容)
事务A:
SELECT ... LOCK IN SHARE MODE(获取S锁)事务B:可以同时执行相同的S锁查询
✅ 多个事务可以同时读取同一数据
2. 读写互斥 (共享锁与排他锁不兼容)
事务A:持有S锁(读锁)
事务B:尝试
UPDATE...(需要X锁/写锁)❌ 事务B会被阻塞,直到事务A释放S锁
3. 写读互斥 (排他锁与共享锁不兼容)
事务A:
SELECT ... FOR UPDATE(获取X锁/写锁)事务B:尝试
SELECT ... LOCK IN SHARE MODE(需要S锁/读锁)❌ 事务B会被阻塞,直到事务A释放X锁
4. 写写互斥 (排他锁之间不兼容)
事务A:持有X锁(写锁)
事务B:尝试另一个写操作(需要X锁)
❌ 事务B会被阻塞,直到事务A释放X锁
为什么叫"共享"和"排他"?
这种命名是从锁的共享特性角度描述的:
共享锁(S锁):可以被多个事务"共享"持有(对应多个读操作)
排他锁(X锁):必须"排除"其他所有锁(对应写操作需要独占)
-- 事务1获取共享锁(读锁) BEGIN; SELECT * FROM accounts WHERE id = 1 LOCK IN SHARE MODE;
-- 此时事务2可以同时获取共享锁 SELECT * FROM accounts WHERE id = 1 LOCK IN SHARE MODE;
-- 但事务3尝试获取排他锁(写锁)会被阻塞 UPDATE accounts SET balance = 100 WHERE id = 1;
十三、redis分布式锁,是如何实现的?
-
先按照自己简历上的业务进行描述分布式锁使用的场景
-
我们当使用的redisson实现的分布式锁,底层是setnx和lua脚本(保证原子性)
十四、Redisson实现分布式锁如何合理的控制锁的有效时长?
-
在redisson的分布式锁中,提供了一个WatchDog(看门狗),-个线程获取锁成功以后,WatchDog会给持有锁的线程续期(默认是每隔10秒续期一次)
十五、Redisson的这个锁,可以重入吗?
-
可以重入,多个锁重入需要判断是否是当前线程,在redis中进行存储的时候使用的hash结构来存储线程信息和重入的次数
十六、Redisson锁能解决主从数据一致的问题吗
-
不能解决,但是可以使用redisson提供的红锁来解决,但是这样的话,性能就太低了
-
如果业务中非要保证数据的强一致性,建议采用zookeeper实现的分布式锁
十七、Redis集群有哪些方案,知道嘛
在Redis中提供的集群方案总共有三种
-
主从复制
-
哨兵模式
-
分片集群
介绍一下redis的主从同步 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。-般都是一主多从,主节点负责写数据,从节点负责读数据
十八、redis主从数据同步的流程是什么?
-
全量同步:
-
从节点请求主节点同步数据(replicationid、offset)
-
主节点判断是否是第一次请求,是第一次就与从节点同步版本信息(replication id和offset)
-
主节点执行bgsave,生成rdb文件后,发送给从节点去执行
-
在rdb生成执行期间,主节点会以命令的方式记录到缓冲区(一个日志文件 repl-backlog))
-
把生成之后的命令日志文件发送给从节点进行同步
-
-
增量同步:
-
从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
-
主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
-
十九、主从同步流程(全量+增量)


全量同步(第一次同步)的处理 replid 不一致
当判断需要全量同步时:
主节点执行BGSAVE:
生成RDB快照文件
如果配置了
repl-diskless-sync则直接通过网络发送传输RDB文件:
bash
复制
# 主节点日志示例 Background saving started by pid 2645 Synchronization with replica 127.0.0.1:6380 succeeded从节点加载RDB:
清空自身数据
加载接收到的RDB文件
开始增量同步:
主节点将新写入命令存入复制积压缓冲区
从节点持续接收并执行这些命令
增量同步的处理
当可以进行增量同步时:
主节点发送积压命令:
从积压缓冲区(repl-backlog)中发送从节点缺失的命令
积压缓冲区是环形缓冲区,默认大小1MB
持续同步:
主节点将每个写命令发送给从节点
从节点按顺序执行这些命令
偏移量更新:
主从节点都会持续更新
master_repl_offset用于下次断线重连时判断同步位置
核心概念:Replication ID和offset
Replication ID:
一个伪随机的40字符字符串(如:"fccb3c8c80a6096b9a7b8f1e9a7b8f1e9a7b8f1e9")
标识主节点的复制流历史
offset:
单调递增的64位整数
记录复制流中的字节位置
二十、你们使用redis是单点还是集群,哪种集群?
主从(1主1从)+哨兵就可以了。单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点
二十一、Redis分片集群中数据是怎么存储和读取的?
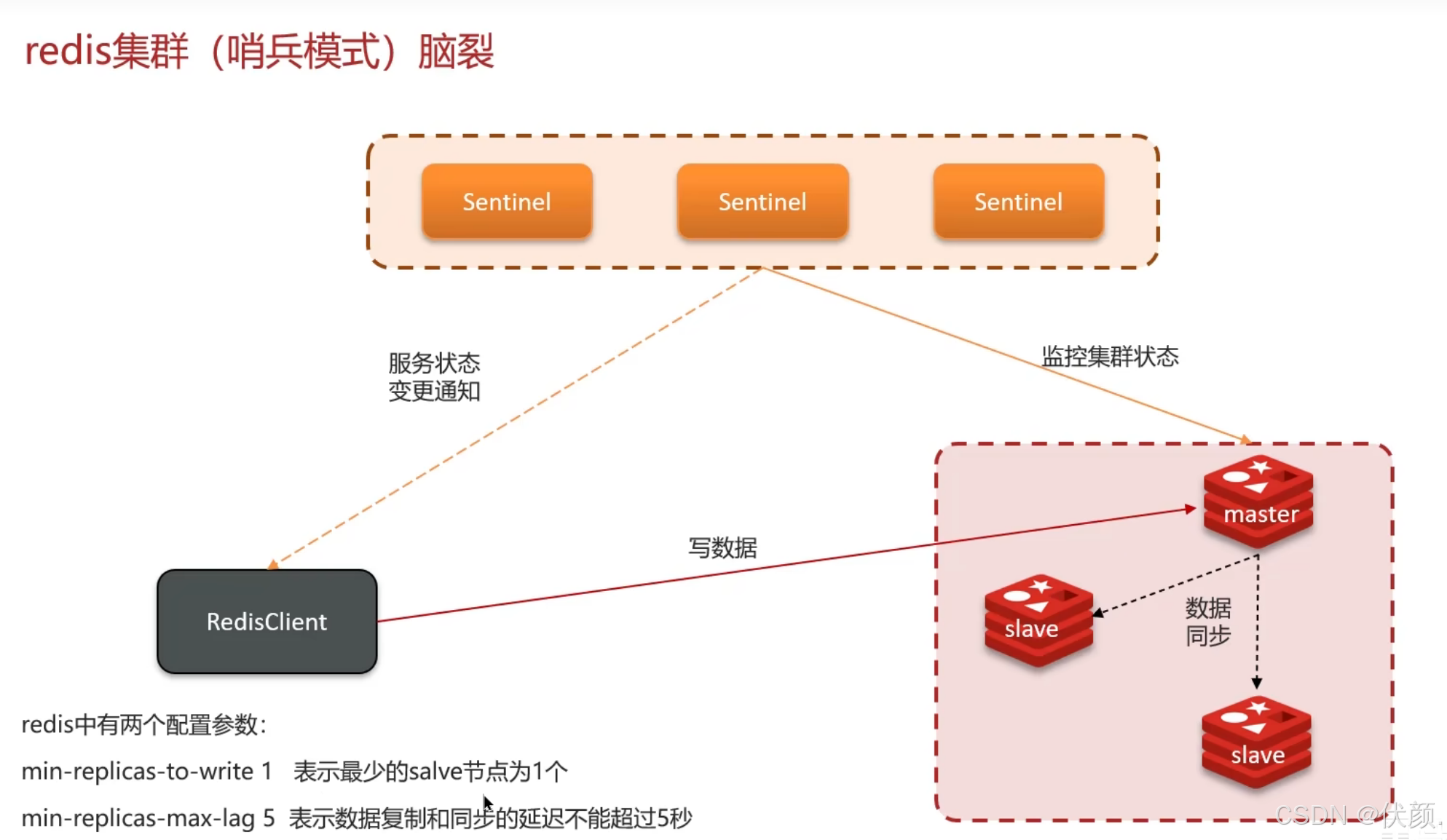
二十二、Redis集群脑裂,该怎么解决呢?
在分布式系统中,两个或多个主节点(Master)同时存在并接受写入,导致数据冲突和不一致
-
主节点(Master)和从节点(Slave)被隔离在不同的网络分区,导致它们无法通信。
-
哨兵(Sentinel)集群也被分割,部分哨兵认为旧主节点仍然存活,而另一部分哨兵选举了新主节点。
-
最终,两个主节点同时接受写入,导致数据冲突。
脑裂的具体过程
假设一个 Redis 集群由 1主(Master)+ 2从(Slave)+ 3哨兵(Sentinel) 组成,网络分区后可能发生:
网络分区1(可访问外网):
主节点(Master)
1个哨兵(Sentinel)
客户端仍然向旧主写入数据
网络分区2(内网隔离):
2个从节点(Slave)
2个哨兵(Sentinel)
哨兵检测到主节点失联,选举新主
客户端向新主写入数据
网络恢复后:
两个主节点数据不一致,Redis 会保留新主的数据,丢弃旧主在隔离期间的写入(取决于配置)
集群脑裂是由于主节点和从节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主,这样就存在了两个master,就像大脑分裂了一样。
解决:修改redis的配置,
1.设置最少的从节点数量(min-replicas-to-write 1 表示最少的salve节点为1个)(至少要有N个从节点同步成功)
-
min-slaves-to-write 1 # 主节点必须至少有一个从节点确认同步,否则停止写入。
-
如果主节点发现无法同步到足够的从节点,会拒绝写入,避免数据丢失。
2.以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求就可以避免大量的数据丢失(min-replicas-max-lag5 表示数据复制和同步的延迟不能超过5秒)(从节点同步延迟不能超过N秒)
-
min-slaves-max-lag 10 # 从节点延迟超过10秒,主节点停止写入
-
防止主节点在高延迟环境下继续写入不可靠数据
3.哨兵(Sentinel)的 quorum(仲裁机制)
-
哨兵必须达到多数派(>N/2)才能执行主节点切换,避免少数派哨兵误判
二十三、Redis集群的最大槽数为什么是16384个?
1.1 问题描述
Redis集群并没有使用一致性hash而是引入了哈希槽的概念。Redis 集群有16384个哈希槽, 每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。但为什么哈希槽的数量是16384(2^14)个呢?
CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。
换句话说值是分布在0~65535之间,有更大的65536不用为什么只用16384就够? 作者在做mod运算的时候,为什么不mod65536,而选择mod16384? HASH_SLOT = CRC16(key) mod 65536为什么没启用
1.2 问题解释
1.2.1 antirez回答
https://github.com/redis/redis/issues/2576
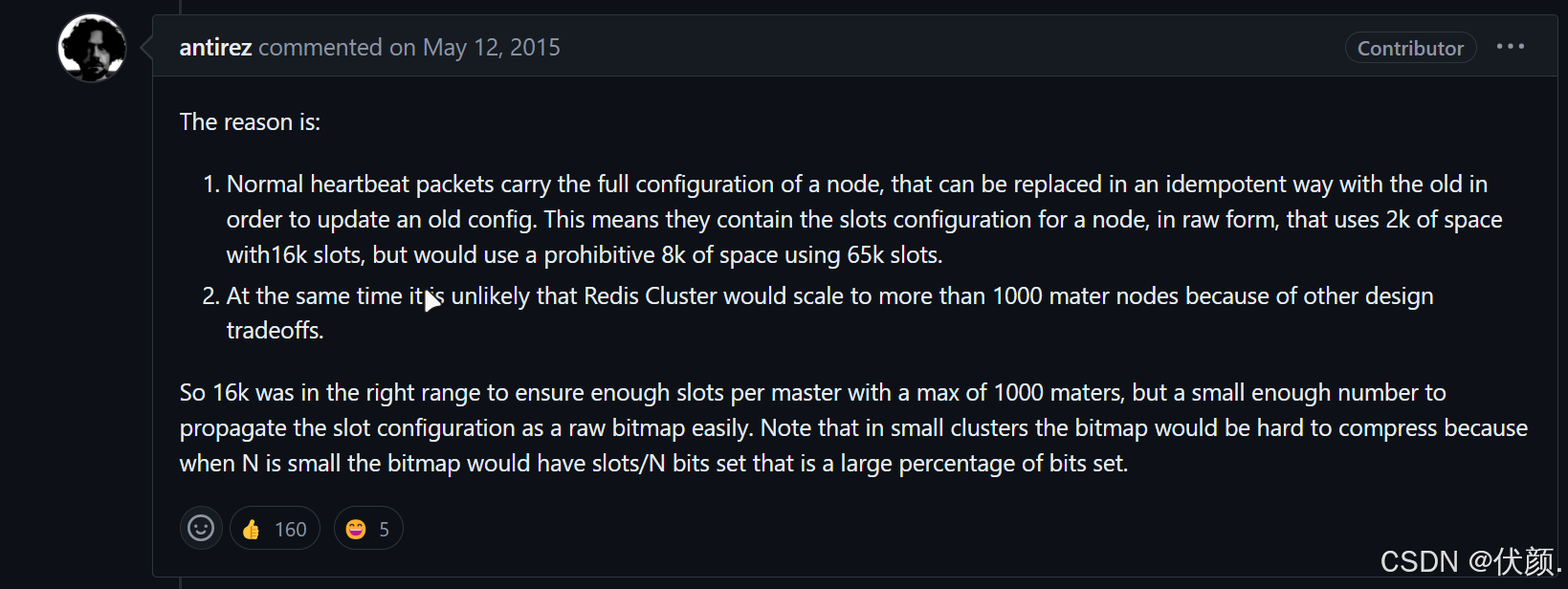
1.2.2 翻译
正常的心跳数据包带有节点的完整配置,可以用幂等方式用旧的节点替换旧节点,以便更新旧的配置。
这意味着它们包含原始节点的插槽配置,该节点使用2k的空间和16k的插槽,但是会使用8k的空间(使用65k的插槽)。
同时,由于其他设计折衷,Redis集群不太可能扩展到1000个以上的主节点。
因此16k处于正确的范围内,以确保每个主机具有足够的插槽,最多可容纳1000个矩阵,但数量足够少,可以轻松地将插槽配置作为原始位图传播。请注意,在小型群集中,位图将难以压缩,因为当N较小时,位图将设置的slot / N位占设置位的很大百分比。
1.2.3 梳理
(1)消息头控制。如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是: 65536÷8÷1024=8kb
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为16384时,这块的大小是: 16384÷8÷1024=2kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
心跳包中包含节点的完整配置,如果哈希槽数为65536,心跳包的消息头大小会达到8KB(计算:65536 / 8 / 1024),而16384个槽时消息头仅为2KB。这有助于减少带宽浪费,因为Redis节点需要频繁发送心跳包。
(2)主节点数量限制。redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
主节点数量限制 Redis集群的主节点数量不建议超过1000个,以防止网络拥堵。如果节点数在1000以内,16384个槽足够满足需求,没有必要扩展到65536个。
(3)高效的位图压缩。槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
哈希槽的配置信息以位图形式保存并进行压缩。在节点少的情况下,较小的槽位数量能够提高位图的压缩率;反之,如果槽位太多而节点较少,填充率高会导致压缩效果差,增加传输负担。
1.2.4 总结
16384个哈希槽的设计兼顾了消息大小、节点管理和数据传输效率,使得Redis集群在保持高性能的同时,避免了带宽浪费和管理复杂性的增加。这一数量恰好符合Redis集群的使用场景,使得集群能够有效支持最多1000个主节点的配置。
二十五、介绍一下redis的主从同步
-
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。-般都是一主多从,主节点负责写数据,从节点负责读数据
二十六、Redis哨兵领导者选举机制?
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法
-
故障发现阶段
-
当主节点被判定为客观下线(ODOWN)时,所有监视该主节点的哨兵都会收到通知。
-
-
选举初始化
-
每个哨兵会随机等待一段时间(减少冲突),然后尝试发起选举。
-
投票规则
-
每个哨兵在每个任期只能投一票
-
哨兵只会投票给:
-
第一个向其拉票的候选者(在相同term内)
-
并且该候选者的配置纪元(configuration epoch)不小于自己
-
-
-
3.成为领导者的条件
-
候选哨兵需要获得多数票(超过半数哨兵节点的同意)
-
当选票数 > N/2 (N是哨兵总数)
-
选举超时
-
如果选举超时(通常300ms * 随机因子)仍未选出领导者,会开始新一轮选举。
哨兵选主规则
-
首先判断主与从节点断开时间长短,如超过指定值就排后该从节点
-
然后判断从节点的slave-priority值,越小优先级越高
-
如果slave-prority一样,则判断slave节点的offset值,越大优先级越高
-
最后是判断slave节点的运行id大小,越小优先级越高。
为什么这样设计?
避免脑裂:多数票确保只有一个领导者
容错性:允许部分节点故障
效率:随机等待减少冲突
一致性:高epoch的哨兵优先
二十七、Redis脑裂
“旧主(原Master)在网络隔离期间仍接受写入,恢复后被降级导致数据丢失”的问题。这是分布式系统中的“旧主隔离写入”问题,但严格来说,这不属于“脑裂”,而是数据一致性问题。下面详细解释:
1. 什么是脑裂(Split-Brain)?
脑裂的定义: 在分布式系统中,两个或多个主节点(Master)同时存在并接受写入,导致数据冲突和不一致。
案例 1:库存超卖(电商场景)
初始库存:
stock = 10。客户端 1 向主节点 A 发送:
DECR stock(A 的stock = 9)。客户端 2 向主节点 B 发送:
DECR stock(B 的stock = 9)。最终合并时:
如果简单相加:
stock = 9 + 9 = 18(显然错误,实际应该stock = 8)。如果取最小值:
stock = 9(仍然错误,因为扣减了两次)。关键特征:
多个主节点同时活跃。
客户端可能向不同的主节点写入,导致数据无法合并。
2. 你的场景分析
假设 3 节点集群(1 Master + 2 Sentinel):
初始状态:
Node1是 Master,Node2和Node3是 Sentinel + Slave。网络分区:
Node1被隔离(无法与Node2和Node3通信)。
Node2和Node3检测到Node1失联,选举Node2为新 Master。问题发生:
分区期间:
客户端仍可能向
Node1写入(如果客户端未感知Node1已失联)。
Node2(新 Master)也接受写入。网络恢复后:
Node1重新加入集群,但发现自己已被降级为 Slave。
Node1的数据会被清空,并从Node2(新 Master)重新同步。结果:分区期间写入
Node1的数据丢失。
3. 这是脑裂吗?
❌ 不是严格意义上的脑裂,因为:
只有
Node2是合法的主节点(由多数派 Sentinel 选举)。
Node1虽然接受了写入,但它已经被集群多数派判定为失效,因此它的写入是“非法”的。恢复后,集群仍然只有一个主节点(
Node2),没有“双主”情况。✅ 更准确的说法:这是“旧主隔离写入”问题(Stale Master Writes),属于数据丢失,而非脑裂。
4. 为什么奇数节点能避免“脑裂”?
奇数节点的核心作用是确保多数派唯一性,从而:
防止“双主”:
在
1:2分区时,只有2节点侧能选举新主,1节点侧无法选举,因此不会有两个主节点同时存在。如果是偶数节点(如 4 节点
2:2),双方都无法达成多数,可能导致无主状态(但也不会脑裂)。避免冲突决策:
奇数节点确保只有一个子集能达成多数,因此决策(如主节点切换)是唯一的。
5. 如何解决“旧主隔离写入”问题?
虽然奇数节点能避免脑裂,但仍需额外措施防止数据丢失:
(1) Redis 的
min-slaves-to-write配置min-slaves-to-write 1 # 主节点必须至少有 1 个从节点在线才能接受写入
作用:
如果主节点(
Node1)发现无法连接任何从节点(因网络分区),会拒绝写入。这样即使客户端仍向
Node1发送写入,也会失败,避免数据不一致。(2) 客户端重试机制
客户端应监控主节点变化,如果写入失败,应查询 Sentinel 获取新主节点。
(3) 数据修复(人工干预)
如果
Node1在隔离期间接受了写入,可以在恢复后:
手动导出
Node1的增量数据。合并到新主节点(
Node2)。
6. 对比脑裂 vs 旧主隔离写入
问题 脑裂(Split-Brain) 旧主隔离写入(Stale Master Writes) 定义 两个或多个主节点同时接受写入 旧主在网络隔离期间仍接受写入,恢复后数据丢失 数据一致性 数据冲突(无法自动合并) 数据丢失(旧主写入未被同步) 原因 多数派决策失败(如偶数节点 2:2)客户端未感知主节点切换 解决方案 使用奇数节点 + 多数派机制 min-slaves-to-write+ 客户端重试
7. 结论
奇数节点的作用:
避免脑裂(确保只有一个多数派能决策)。
但不能完全防止“旧主隔离写入”问题(需额外配置)。
数据一致性保障:
依赖
min-slaves-to-write和客户端重试机制。生产建议:
使用 3/5 个 Sentinel(奇数)。
配置
min-slaves-to-write 1。客户端实现自动故障转移逻辑。
最终答案: 奇数节点能避免脑裂(防止双主),但“旧主隔离写入”问题需额外配置解决。两者是不同的问题,需分别处理。

二十八、哨兵结点的数量应该为奇数,这是为什么?
-
多数票原则(Quorum)
哨兵通过投票决定主节点是否下线或选举新领导者,必须获得超过半数的同意才能生效。奇数数量能明确形成多数派,避免平局:
-
3个哨兵:至少需要
2票(>1.5) -
4个哨兵:同样需要
3票(>2),但容错能力与3节点相同(只能容忍1节点故障),却多消耗资源。
奇数更高效: 3节点和4节点都能容忍1个故障,但3节点更节省资源;5节点可容忍2个故障,优于6节点(同样最多容忍2个故障)。
-
容错能力最大化
奇数数量能在相同节点数下提供最优的容错能力:
-
3节点:允许1个节点故障(剩余2个仍能形成多数)
-
5节点:允许2个节点故障(剩余3个仍能形成多数)
如果是偶数(如4节点),实际容错能力与少1个的奇数相同(4节点也只能容忍1个故障,否则剩余2=2,无法形成多数)。
-
避免脑裂(Split-Brain)
网络分区时,奇数节点能明确划分多数派和少数派。例如:
-
3节点分区为 1 vs 2:只有2节点的一侧能达成共识。
-
4节点分区为 2 vs 2:双方都无法达成多数,导致服务僵局。
-
成本与性能的平衡
奇数节点在资源消耗和可用性之间取得最佳平衡:
-
偶数节点(如4个)不会比3个提供更高的容错,却增加通信开销。
-
5节点比3节点容错更强,但需权衡部署成本。
当有 3 个节点(奇数)时,如果网络分区为
1:2,2的两个节点是否能选举新的主节点?这样会不会导致脑裂?核心结论
✅ 不会脑裂! 在
1:2的网络分区情况下:
2节点的一侧可以选举新主(因为2 > 3/2,满足多数派)。
1节点的一侧无法选举(因为1 ≤ 3/2,不满足多数派)。最终只有一个主节点生效,因此不会脑裂。
二十九、怎么保证Redis的高并发高可用
-
哨兵模式:实现主从集群的自动故障恢复(监控、自动故障恢复、通知)
-
监控:Sentinel会不断检查您的master和slave是否按预期工作
-
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
-
通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
-
-
哨兵选举:
-
首先判断主与从节点断开时间长短,如超过指定值就排除该从节点
-
然后判断从节点的slave-priority值,越小优先级越高
-
如果slave-prority一样,则判断slave节点的offset值,越大优先级越高
-
复制偏移量(offset)表示从节点从主节点复制的数据量(字节数),可以理解为从节点与主节点数据同步的“进度条”。
-
Offset越大,说明该从节点从旧主节点接收到的数据越多,即它的数据状态更接近故障前的旧主节点。
-
-
最后是判断slave节点的运行id大小,越小优先级越高【Run ID】
1. 为什么选 Run ID 较小的节点?而不是较大的?
Redis 并没有规定必须选较小的,它只是选择了一种确定性的比较方式,确保所有哨兵能达成一致。
-
选较小或较大都可以,关键是要有一个统一的规则,避免不同哨兵投票给不同的节点。
-
Redis 选择了字典序较小的 Run ID,可能是出于以下原因:
-
实现简单:按字典序排序后取第一个(类似
MIN()操作),代码实现更直接。 -
历史习惯:许多分布式系统(如 ZooKeeper、Etcd)在选举时也倾向于选择较小的 ID,以减少冲突。
-
避免人为干扰:如果选较大的 Run ID,可能会有人故意配置更大的 ID 来影响选举,而较小的 Run ID 是随机生成的,更难预测。
-
2. Run ID 的大小和 Redis 启动顺序有关系吗?
没有直接关系!
-
Run ID 是 Redis 启动时随机生成的(16字节的十六进制字符串,如
a1b2c3d4...),并不代表启动顺序。 -
先启动的 Redis 实例的 Run ID 不一定比后启动的小,因为它是完全随机的。
-
所以,Run ID 小的节点 ≠ 先启动的节点,它仅仅是用于选举时的一个确定性比较依据。
3. 如果选较大的 Run ID 会怎样?
技术上完全可以,但 Redis 选择了较小的,可能是为了:
-
一致性:许多分布式系统(如 Raft、ZooKeeper)在选举时也倾向于选择较小的 ID,Redis 可能沿用了类似的设计思路。
-
避免人为操控:如果选较大的 Run ID,管理员可能会故意配置更大的 ID 来影响选举,而较小的 Run ID 是随机的,更公平。
4. 极端情况:如果 Run ID 相同怎么办?
-
理论上不可能,因为 Run ID 是随机生成的,碰撞概率极低(16字节的随机数,冲突概率可以忽略)。
-
如果真的相同(比如人为修改配置文件),哨兵可能会依赖其他机制(如哨兵投票的多数决)来决
-
-
三十、Redis分片集群。解决海量数据存储问题以及高并发写的问题。

在 Redis Cluster 中,{aaa} 是哈希标签(Hash Tag),它的作用是让不同的 key 在计算 CRC16 哈希值时,只对 { } 内的内容(即 aaa)进行哈希计算,从而确保这些 key 被分配到同一个 slot(槽位)。
-
set {aaa}name itheima→ CRC16("aaa") = 888888 -
set {aaa}name itheima22→ CRC16("aaa") = 888888
这是正确的! 因为:
-
CRC16 计算的是
{ }里的内容aaa,而不是整个 key。 -
只要
{ }里的字符串相同,计算出的哈希值就相同,因此这两个 key 会被分配到同一个 slot。
三十一、Redis的分片集群有什么作用?
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
分片集群主要解决的是海量数据存储的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,就类似于哨兵模式了。当客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
三十二、Redis分片集群中数据是怎么存储和读取的?
-
Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽
-
将16384个插槽分配到不同的实例
-
读写数据:根据key的有效部分计算哈希值,对16384取余(有效部分,如果key前面有大括号,大括号的内容就是有效部分,如果没有,则以key本身做为有效部分)余数做为插槽,寻找插所在的实例
三十三、Redis是单线程的,但是为什么还那么快?
-
Redis是纯内存操作,执行速度非常快 ,避免磁盘 I/O 瓶颈
-
所有数据存储在内存中,读写操作直接在 RAM 中完成,速度比磁盘数据库(如 MySQL)快几个数量级。
-
虽然支持持久化(RDB/AOF),但通过 异步刷盘 实现,不影响主线程性能。
-
-
采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
-
单线程模型 避免了多线程的锁竞争、线程切换开销,减少了 CPU 资源的浪费。
-
无锁设计:所有操作按顺序执行,无需考虑并发冲突(如 CAS 操作)。
-
-
使用I/O多路复用模型,非阻塞IO
-
通过 非阻塞 I/O + 多路复用 处理海量客户端连接(如 10 万+ QPS)。
-
Linux 下使用
epoll,Mac 下使用kqueue。 -
单线程监听多个 Socket 事件,高效调度网络请求。
-
-
-
高效的数据结构和算法
-
优化过的数据结构:如哈希表、跳表、压缩列表(ziplist)等,在时间和空间上均高度优化。
-
渐进式 Rehash:扩容时不阻塞主线程。
-
-
避免复杂事务和关联查询
-
无 SQL 解析、连接查询 等复杂操作,命令执行路径极短(如
GET key直接访问内存哈希表)。
-
-
补充优化技术
-
管道(Pipeline):客户端批量发送命令,减少网络往返时间。
-
Lua 脚本:将多个操作合并为一个原子操作,减少通信开销。
-
-
为什么单线程反而更快?
-
CPU 不是瓶颈:Redis 的性能瓶颈通常是 内存或网络带宽,而非 CPU。
-
多线程的代价:线程切换、锁竞争、缓存一致性等问题会抵消多核优势,而 Redis 的简单操作模型让单线程更高效。
-
适用场景
高吞吐、低延迟:适合缓存、计数器、消息队列等场景。
不适用场景:需要大量 CPU 计算的任务(如复杂数据分析)。
三十四、I/O多路复用模型
Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,I/0多路复用模型主要就是实现了高效的网络请求。
-
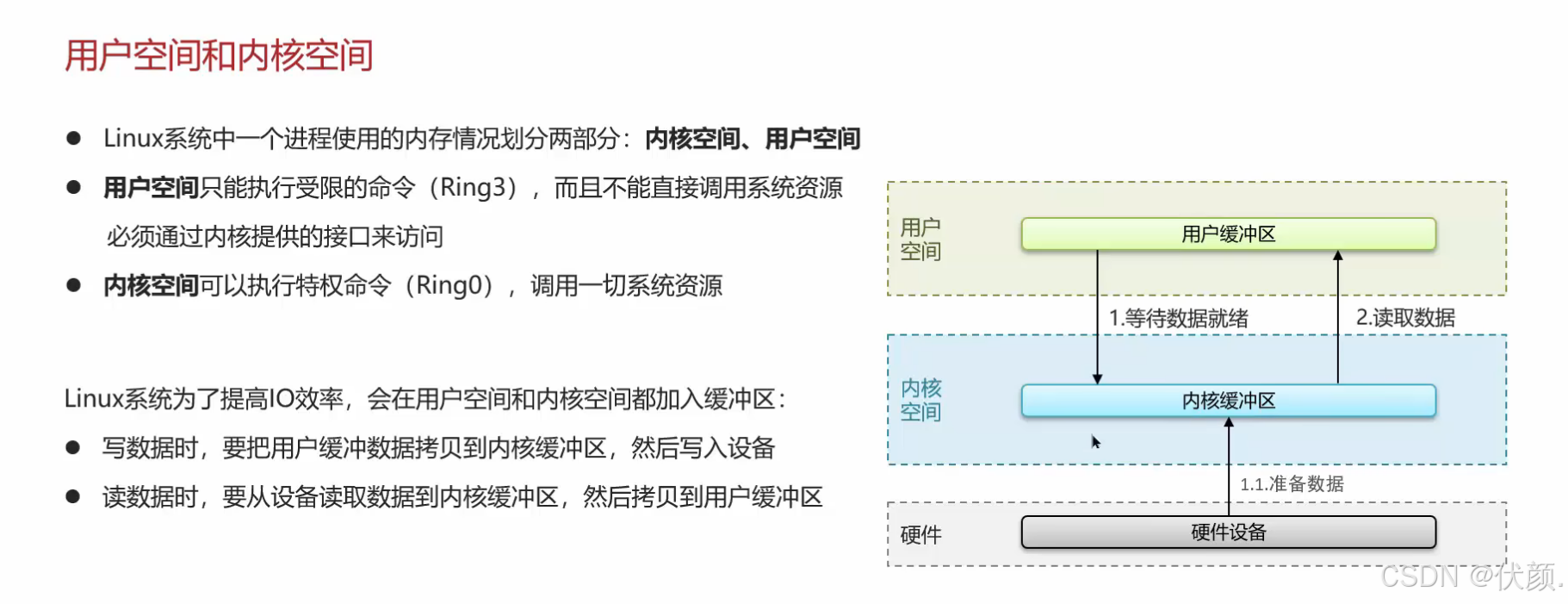
用户空间和内核空间
-
常见的IO模型
-
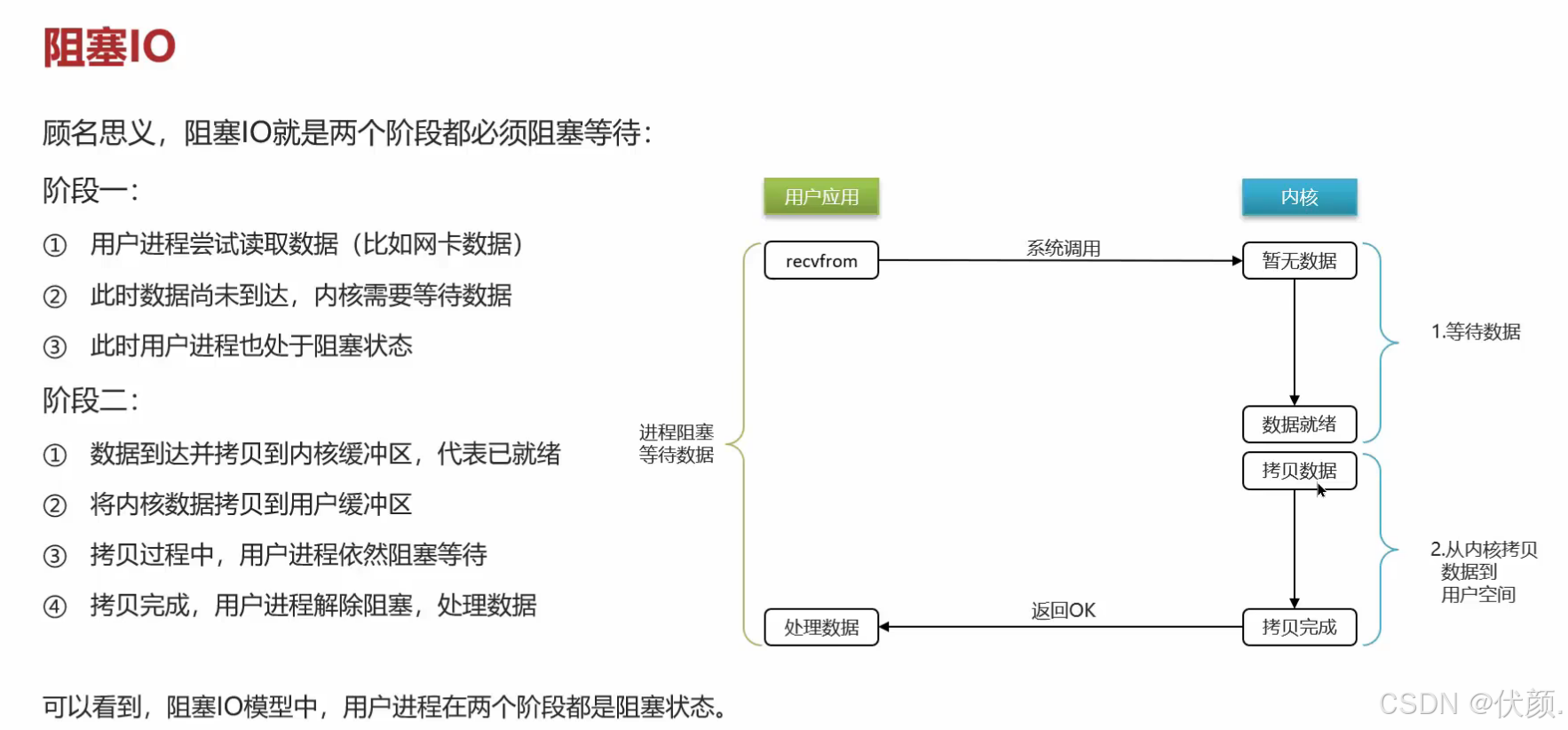
阻塞IO(Blocking lO)
-
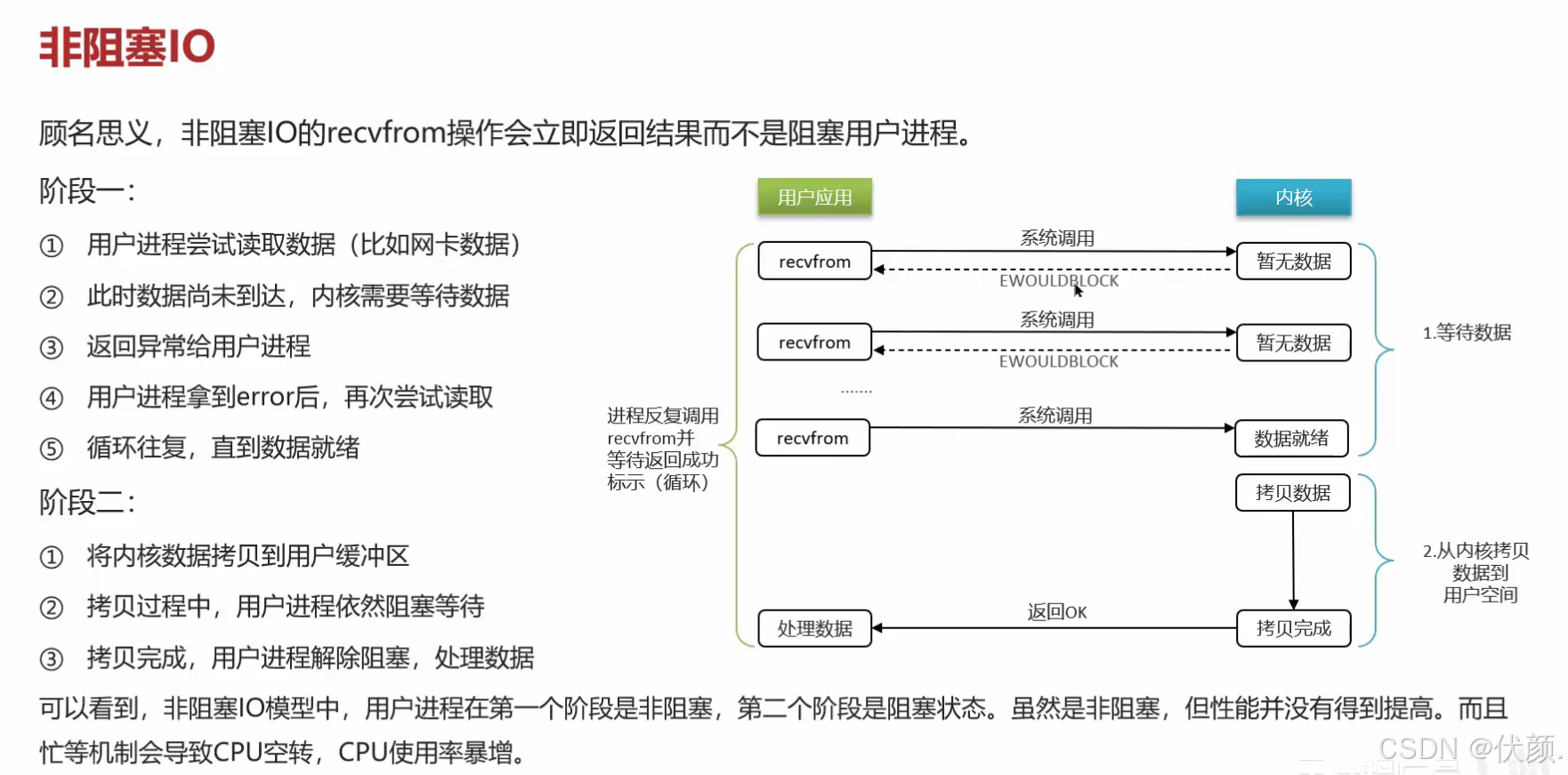
非阻塞IO(Nonblocking lO)
-
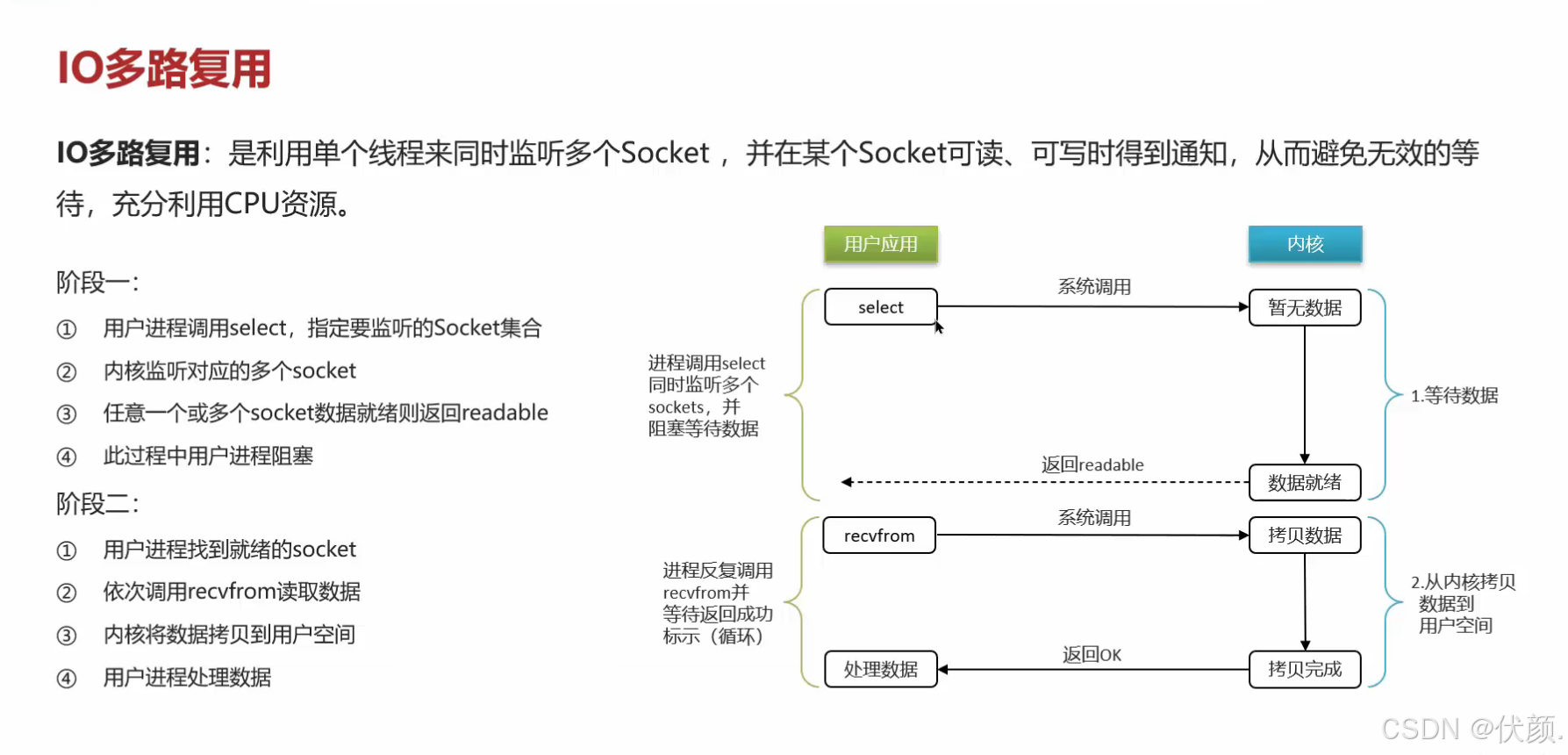
IO多路复用(10 Multiplexing)
-
-
Redis网络模型
1. 阻塞IO(Blocking IO)
场景类比:排队买奶茶
你去奶茶店点单,服务员说:“稍等,奶茶做好后叫你。”(你只能干等,不能做其他事)
你一直站在柜台前等,直到奶茶做好,期间不能玩手机、不能离开。
计算机中的表现
当程序发起一个 读/写操作(比如读取文件、网络请求),如果数据没准备好,线程会一直卡住(阻塞),直到数据就绪。
缺点:浪费 CPU 时间,效率低(一个线程只能处理一个请求)。
2. 非阻塞IO(Non-blocking IO)
场景类比:不断问奶茶做好了没
你去奶茶店点单,服务员说:“你先去逛逛,好了我叫你。”
但你是个急性子,每隔5秒就跑回来问:“奶茶好了吗?”(而不是干等)
如果没好,你就继续去逛;如果好了,你拿走奶茶。
计算机中的表现
程序发起IO请求后,内核立即返回(不管数据是否准备好)。
程序需要 不断轮询(循环检查) 数据是否就绪。
优点:线程不会卡死,可以同时做其他事。
缺点:轮询消耗CPU资源(一直问“好了吗?”很累)。
3. IO多路复用(IO Multiplexing)
场景类比:一个服务员管理多个顾客
现在奶茶店有 一个智能服务员,你点单后,服务员给你一个号码牌。
你坐在旁边玩手机,服务员会 同时监控多个订单。
当你的奶茶好了,服务员叫你的号码,你再去拿。
计算机中的表现
使用 select/poll/epoll 机制,一个线程可以监听多个IO请求。
内核会主动通知程序哪些IO已经就绪,程序再去处理。
优点:
单线程可处理成千上万的连接(高并发)。
比非阻塞IO更高效(不需要无脑轮询)。
典型应用:Redis、Nginx、Java NIO。
三者的核心区别
类型 工作方式 优点 缺点 适用场景 阻塞IO 一直等,直到数据就绪 简单易用 效率低,线程被卡住 低并发场景 非阻塞IO 不断轮询,检查数据是否就绪 线程不会卡死 轮询消耗CPU 需要实时响应的场景 IO多路复用 一个线程监听多个IO,内核通知 高并发,资源占用少 编程复杂 高并发服务器(Redis)
现实中的例子
阻塞IO → 你去银行柜台办业务,柜员处理时你只能干等。-- 简单但低效,适合低并发。
非阻塞IO → 你在银行取号后,每隔几分钟去问“到我了没?”(浪费体力)。-- 不阻塞线程,但需要轮询,消耗CPU。
IO多路复用 → 银行有大屏幕叫号,你可以坐着玩手机,等叫到你再去。-- 高并发神器,一个线程管多个IO(Redis、Nginx都用它)。
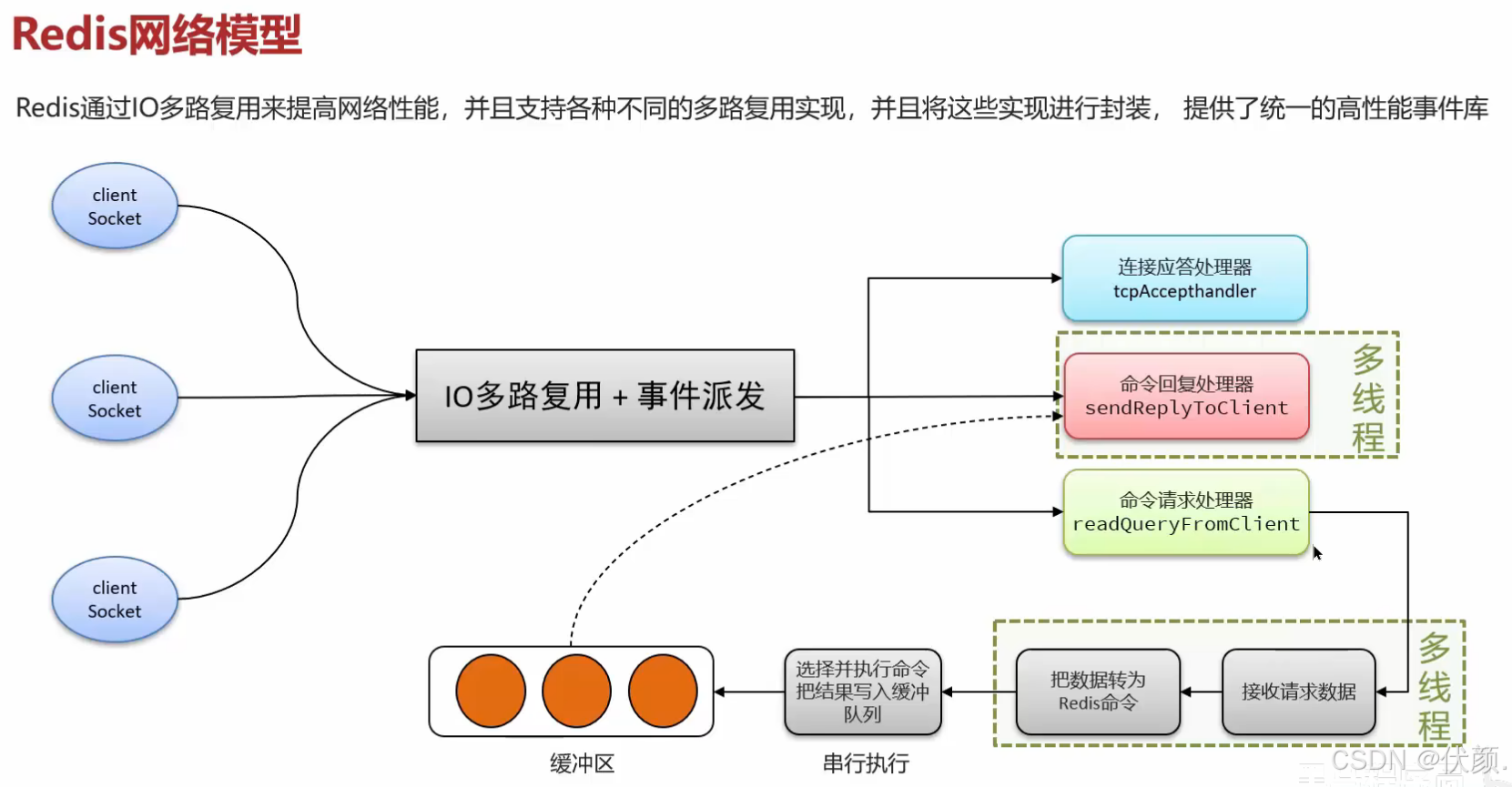
三十五、Redis网络模型
三十六、能解释一下I/O多路复用模型?
1.I/O多路复用
是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/O多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能。
2.Redis网络模型 就是使用 I/O多路复用 结合 事件的处理器 来应对多个Socket请求
-
连接应答处理器
-
命令回复处理器,在Redis6.0之后,为了提升更好的性能,使用了多线程来处理回复事件
-
命令请求处理器,在Redis6.0之后,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程












