

摘要:
简单地重放所有以前的数据可以缓解该问题,但它需要大量内存,并且在现实世界中对过去数据的访问受到限制。提出了深度生成重放(Deep Generative Replay),由深度生成模型(“生成器”)和任务解决模型(“求解器”)。仅使用这两个模型,就可以轻松对先前任务的训练数据进行采样,并将其与新任务的训练数据交错。
在我们的深度生成重放框架中,模型通过生成的伪数据(使用GAN)的重放来保留先前获取的知识。
一些术语:
将要解决的N个任务定义为任务序列 T = ( T 1 , T 2 , ⋅ ⋅ ⋅ , T N ) T = (T_1, T_2, ···, T_N ) T=(T1,T2,⋅⋅⋅,TN)。
定义 1:任务 T i T_i Ti 是针对数据分布 D i D_i Di 的目标优化模型, D i D_i Di中的训练样本表示为 ( x i , y i ) (x_i, y_i) (xi,yi)。
将我们的模型称为scholar,因为它能够学习新任务并将其知识传授给其他网络。“scholar”与集成模型的师生框架的不同,师生框架的网络仅进行教学或学习。
定义2:scholar H H H是一个元组 〈 G , S 〉 〈G, S〉 〈G,S〉,其中生成器 G G G 是产生类真实样本的生成模型,求解器 S S S 是由 θ θ θ 参数化的任务求解模型。
求解器必须执行任务序列 T T T 中的所有任务。完整目标是最小化任务序列中所有任务的无偏损失总和(所有任务的损失总和最小)
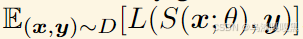
其中 D D D 是整个数据分布, L L L 是损失函数。 在接受任务 T i T_i Ti 的训练时,模型会输入来自 D i D_i Di 的样本。
所提方法:
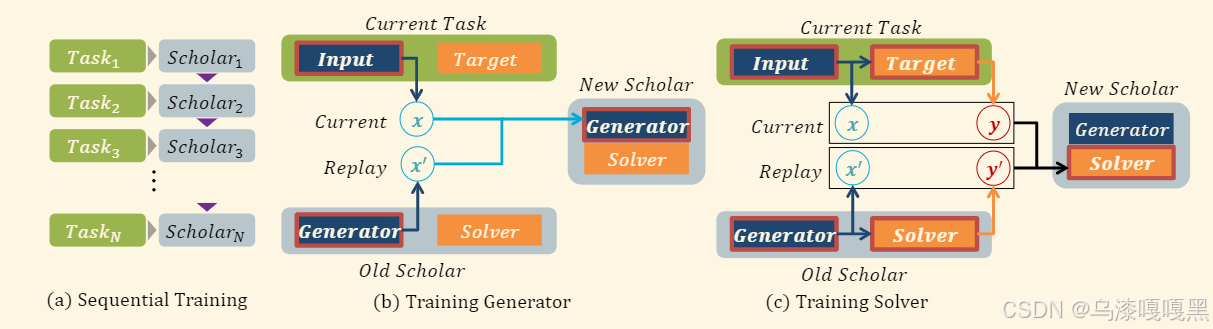
图(a)一个任务对应一个scholar,训练一系列scholar模型相当于连续训练单个scholar,同时参考其最新的先前scholar。
图(b)训练新的生成器,接收当前任务输入 x x x 和先前任务的重放输入 x ′ x' x′,以模拟真实样本 x x x 和来自先前生成器的重放输入 x ′ x' x′ 的混合数据分布。
图(c)新的求解器接收当前任务的输入 ( x , y ) (x,y) (x,y) 以及重放的 ( x ′ , y ′ ) (x',y') (x′,y′),重放的 y ′ y' y′ 是通过将生成的输入 x ′ x' x′ 输入到先前的求解器中获得的。
总结:
每一个新的生成器的输入是最新任务的数据和以前生成器的输出,使得当前生成器能够包含以前任务的全部输入信息,求解器同理。
如有错误,请多包涵!欢迎交流讨论!












