
This is a solution to a problem I encountered in one of my projects: how to store incoming API data in an SQLite database without having to write schema manually every time a source changes.
Imagine we have user data as follows:
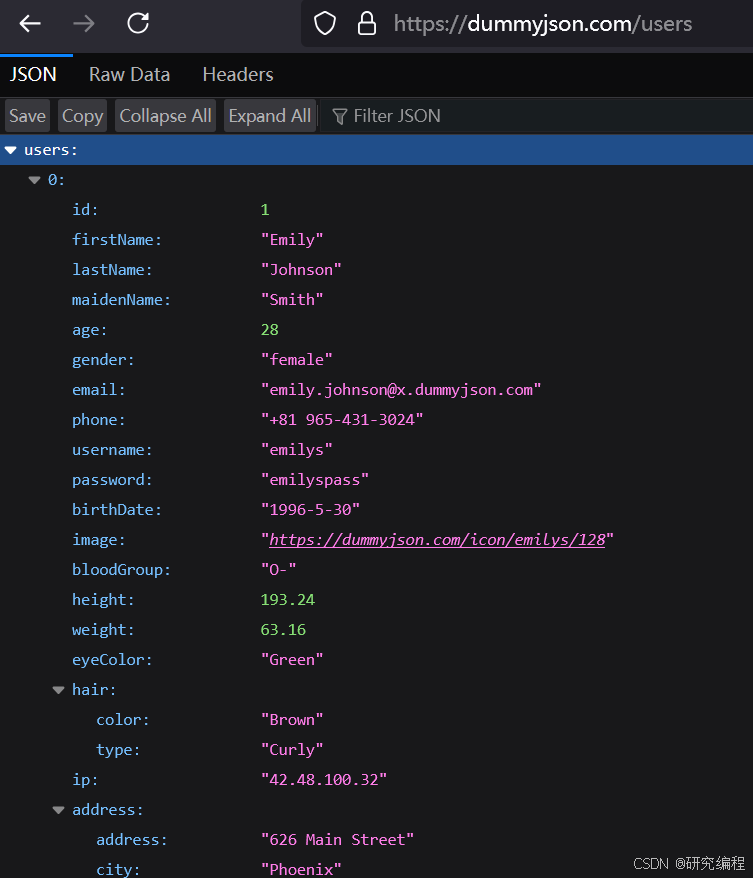
For this tutorial, we use dummy data from dummyjson.com.
This data is a nested structure and has 30 first level columns and a number of second and even third level columns. How do we store this data in an SQL database without manually writing the schema, which is tedious and error-prone?
There are 3 approaches to schema generation:
- keep the first level and store other levels as JSON. Many databases actually allow storing JSON and query it like a regular column:
INSERT INTO products (name, details)
VALUES ('iPhone 13', '{"category": "Electronics", "price": 999, "colors": ["Black", "Blue", "White"]}'),('Samsung Galaxy S21', '{"category": "Electronics", "price": 899, "colors": ["Phantom Black", "Phantom Silver"]}'),('Nike Air Force 1', '{"category": "Shoes", "price": 100, "colors": ["White", "Black"]}'),('Adidas Ultraboost', '{"category": "Shoes", "price": 180, "colors": ["Core Black", "Cloud White"]}'),('MacBook Pro', '{"category": "Electronics", "price": 1299, "colors": ["Silver", "Space Gray"]}'),('Amazon Kindle', '{"category": "Electronics", "price": 79, "colors": ["Black"]}'),('Sony PlayStation 5', '{"category": "Electronics", "price": 499, "colors": ["White"]}'),('Cuisinart Coffee Maker', '{"category": "Home & Kitchen", "price": 99, "colors": ["Stainless Steel", "Black"]}'),('Dyson V11 Vacuum Cleaner', '{"category": "Home & Kitchen", "price": 599, "colors": ["Iron", "Nickel"]}');
SELECTname,json_extract (details, '$.price') AS price
FROMproducts;
Examples are taken from https://www.sqlitetutorial.net/sqlite-json/
- Flatten the data, so that every second and third level nested column becomes the first level column:
{"bank":{'cardExpire': '03/26','cardNumber': '9289760655481815','cardType': 'Elo','currency': 'CNY'}
}
{'bank_cardExpire': '03/26',
'bank_cardNumber': '9289760655481815',
'bank_cardType': 'Elo',
'bank_currency': 'CNY'}
- The third way is to separate nested levels into individual tables and connect them with foreign keys. However, this approach is much more complex and doesn’t apply to every form of data. For example, it doesn’t make sense to store
hairin a separate table like in the dummy data above.

Given that flat data is preferred for data analysis, we will use the second approach - flatten the structure so that second and third nested columns become first level columns.
Project imports
import pprint
import sqlite3
from collections import defaultdict
from collections.abc import MutableMappingimport requests # install with `pip install --upgrade requests`Getting the data
First and foremost, we need our data.
r = requests.get("https://dummyjson.com/users")data = r.json()pprint.pprint(data)
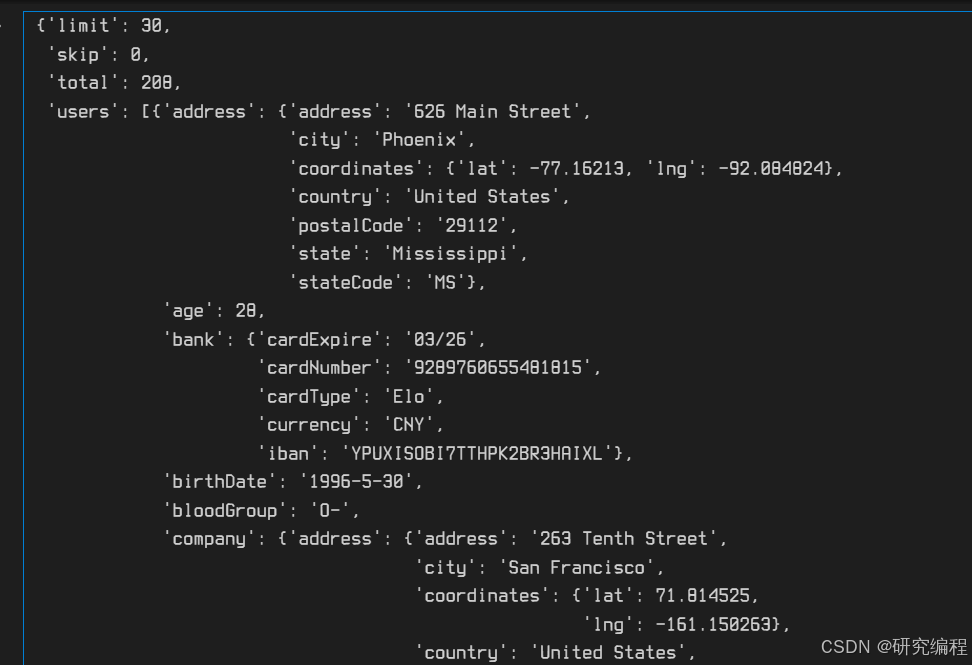
We can see that our data lies within the users object with limit, slip, and total being request related information.
data["users"]
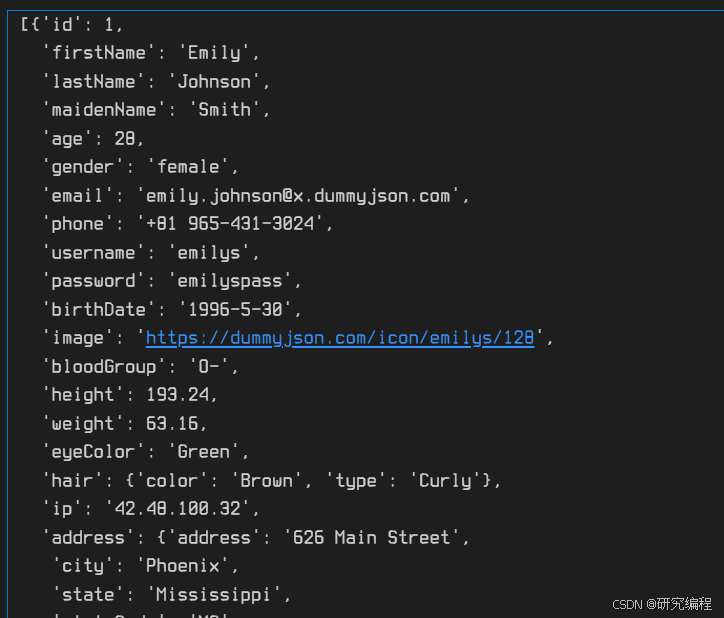
Flattening JSON
def flatten_dict(d: MutableMapping, parent_key: str = "", sep: str = "_"
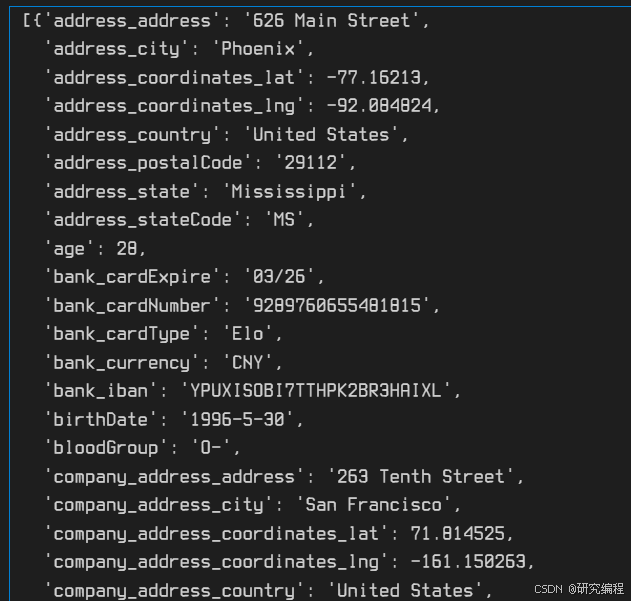
) -> MutableMapping:items = []for k, v in d.items():new_key = parent_key + sep + k if parent_key else kif isinstance(v, MutableMapping):items.extend(flatten_dict(v, new_key, sep=sep).items())else:items.append((new_key, v))return dict(items)flat_data = [flatten_dict(d) for d in data["users"]]pprint.pprint(flat_data)
With the help of a list comprehension and the flatten_dict function, we flatten our data and store it in a new variable. We set _ as a column separator, as SQLite doesn’t accept values such as ..
Creating schema
The first step toward schema generation is to go through our data and look for list types of data. Because SQLite doesn’t know how to handle this type, we represent it as a string. This operation is done in place. Remember that dictionaries are unpacked and flattened in the previous step, which reduces possible values to int, float, str, bool, list, and None types.
# Update the data, repr `lists` as `str`
def repr_data(data):for i in data:for k, v in i.items():if isinstance(v, list):i[k] = repr(v)
Next, we collect all possible keys that may be present in the data. Because data is not always uniform, i.e. a key may be present in one sample but absent in others, we need to know all the possible keys that can occur in the population as well as their types.
def create_schema_dict(data):schema_dict = {}for i in data:for k, v in i.items():schema_dict[k] = type(v)return schema_dict
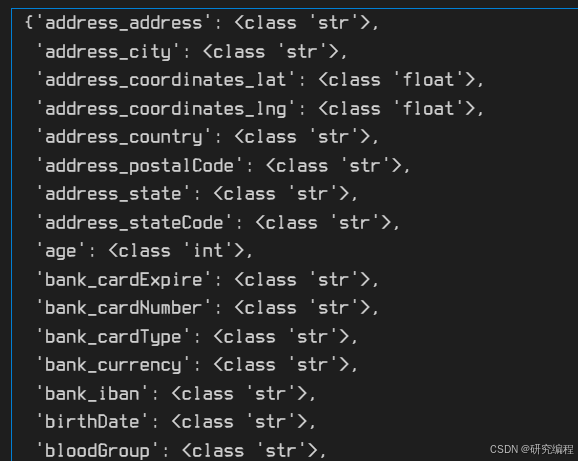
# Update the data, repr `lists` as `str`
def repr_data(data):for i in data:for k, v in i.items():if isinstance(v, list):i[k] = repr(v)def create_schema_dict(data):schema_dict = {}for i in data:for k, v in i.items():schema_dict[k] = type(v)return schema_dictrepr_data(flat_data)schema_dict = create_schema_dict(flat_data)
pprint.pprint(schema_dict)
Now, we can go about creating the schema. We need two pieces: the schema dictionary and a table name. We supply both to the create_schema function.
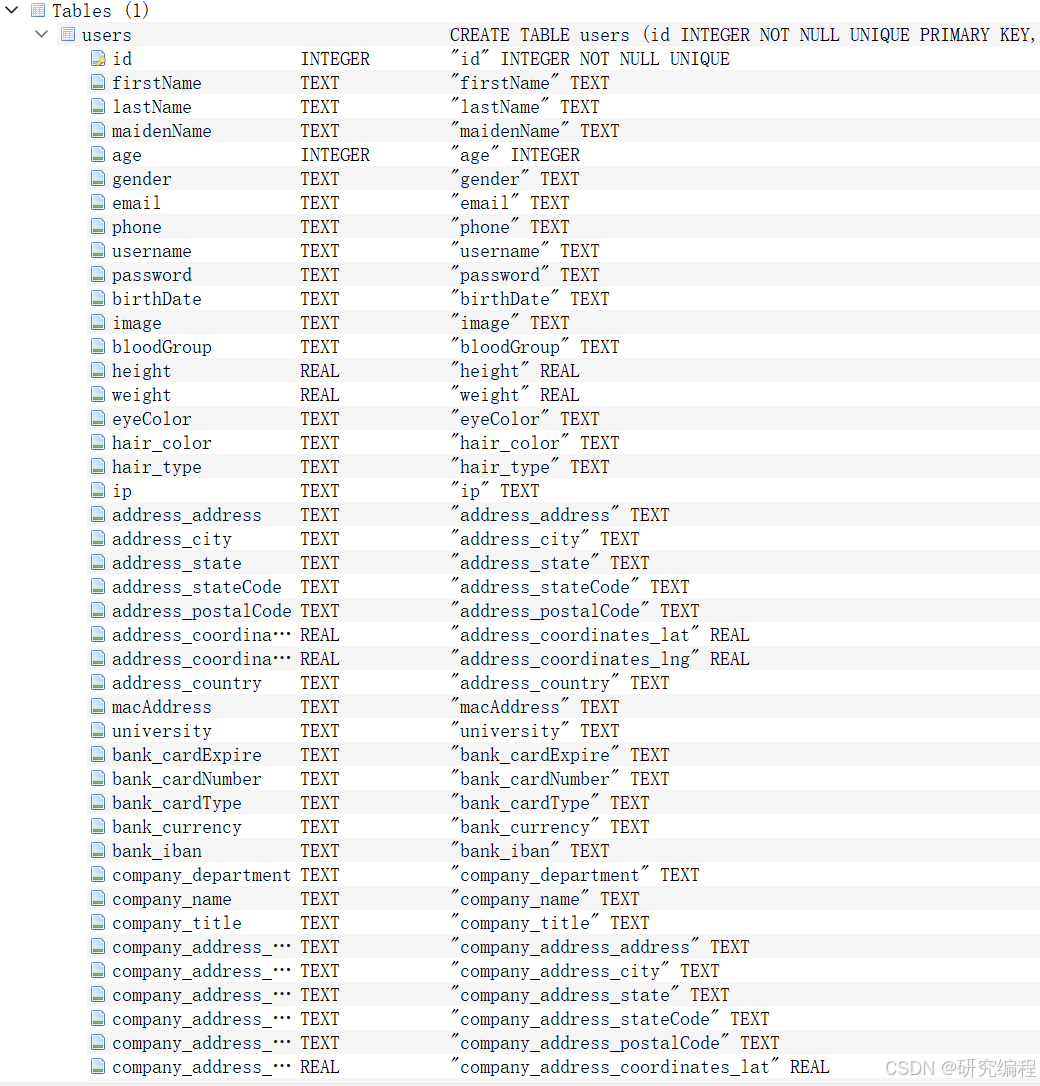
def create_schema(schema_dict: dict, table_name: str) -> str:type_to_type_map = {int: "INTEGER", bool: "INTEGER", float: "REAL", str: "TEXT"}schema = f"CREATE TABLE IF NOT EXISTS {table_name} ("for k, v in schema_dict.items():if k == "id":schema = (schema+ f"{k} {type_to_type_map[schema_dict[k]]} NOT NULL UNIQUE PRIMARY KEY, ")else:schema = schema + f"{k} {type_to_type_map[schema_dict[k]]}, "schema = schema[:-2]schema = schema + ")"return schema
First, we create a type conversion map. Because list values are represented as strings, we only need to handle the following types: int, float, str, bool. In SQLite, boolean values are defined as INTEGER and are internally converted to 1 or 0 for True or False, datetime objects are stored as TEXT, None types are internally converted to NULL, so this map covers all the basic cases.
Second, we define our base schema, which is the CREATE TABLE IF NOT EXISTS statement.
Next, we loop through the schema_dict and use keys as column names and values as column types and append them to the base schema. If our data contains the id key, it is defined as NOT NULL UNIQUE PRIMARY KEY.
schema = schema[:-2]
schema = schema + ")"
Here we remove the leftover ", " from the last definition and add a closing bracket.
# Update the data, repr `lists` as `str`
def repr_data(data):for i in data:for k, v in i.items():if isinstance(v, list):i[k] = repr(v)def create_schema_dict(data):schema_dict = {}for i in data:for k, v in i.items():schema_dict[k] = type(v)return schema_dictrepr_data(flat_data)schema_dict = create_schema_dict(flat_data)
pprint.pprint(schema_dict)def create_schema(schema_dict: dict, table_name: str) -> str:type_to_type_map = {int: "INTEGER", bool: "INTEGER", float: "REAL", str: "TEXT"}schema = f"CREATE TABLE IF NOT EXISTS {table_name} ("for k, v in schema_dict.items():if k == "id":schema = (schema+ f"{k} {type_to_type_map[schema_dict[k]]} NOT NULL UNIQUE PRIMARY KEY, ")else:schema = schema + f"{k} {type_to_type_map[schema_dict[k]]}, "schema = schema[:-2]schema = schema + ")"return schematable_name = "users"schema = create_schema(schema_dict, table_name)with open(f"{table_name}_schema.sql", "w") as f:f.write(schema)Our generated schema now lives in the schema variable and is also stored to an .sql file.

Creating the database and inserting the data
keys = ", ".join([":" + i for i in list(schema_dict.keys())])
vals = [defaultdict(lambda: None, i) for i in flat_data]
sql = f"INSERT OR IGNORE INTO {table_name} VALUES ({keys})"
First, we collect our keys and convert them to the following format for bulk insertion: :key1, :key2… Next, we collect the values. We convert every dict to a defaultdict. This is done to account for possible data misalignment discussed above. When inserting data into a database, SQLite does so according to the keys we defined above. If a key is not present in the defaultdict, it simply returns None for the value, which will be converted to NULL type by SQLite. This solves the data non-uniformity problem. Finally, we prepare the INSERT SQL statement. We use INSERT OR IGNORE to avoid inserting duplicate data into the database.
Now it is time to execute the queries.
con = sqlite3.connect("data.db")try:cur = con.cursor()cur.execute(schema)con.commit()cur.executemany(sql, vals)con.commit()
finally:con.close()
If everything goes well, we will see data.db in the project folder.
谢谢阅读!












 "【MySQL-16】存储过程-特点介绍&基本语法(创建-调用-查看-删除)")