
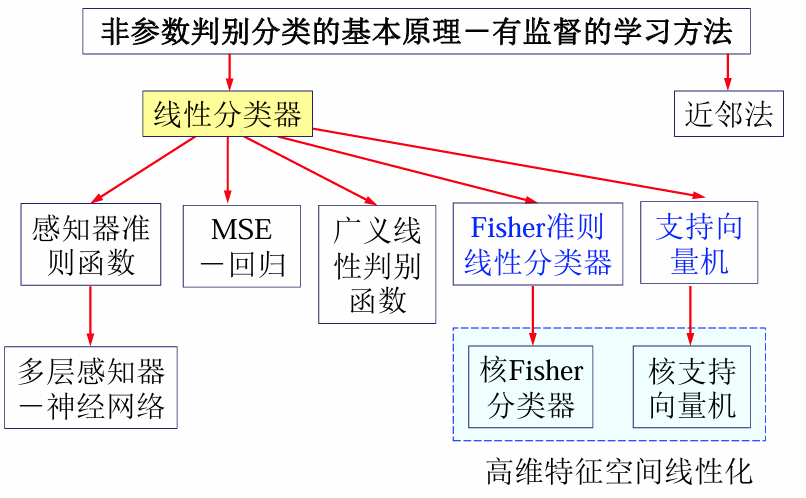
Ch5 线性判别函数
文章目录
- Ch5 线性判别函数
- 引言:生成模型 vs判别模型
- 生成模型 vs 判别模型
- 判别模型分类
- 线性判别函数与决策面
- 线性判别函数
- 两类情况下的决策
- 多类问题下决策
- 多类情形-线性机器
- 线性决策面优缺点
- 广义线性判别函数
- 例:二次判别函数
- 例1: 1-D判别函数
- 感知准则函数
- 概念
- 齐次增广->规范化增广
- 解向量与解区
- 感知准则函数
- 算法收敛性
- 松驰方法
- 学习准则
- 最小平方误差(MSE)准则函数
- 线性判别函数的参数估计
- 可得一个线性方程组: Y a = b Ya = b Ya=b $$ \begin{bmatrix} y_{10} & y_{11} & \cdots & y_{1d}\\ y_{20} & y_{21} & \cdots & y_{2d}\\ \vdots & \vdots & \ddots & \vdots\\ y_{n0} & y_{n1} & \cdots & y_{nd} \end{bmatrix} \begin{bmatrix} a_0\\ a_1\\ \vdots\\ a_d \end{bmatrix}
- 平方误差准则函数
- 梯度下降法
- Ho-Kashyap方法
- 梯度下降
- 伪算法
- 多类线性判别函数
- 方法一:MSE多类扩展
- 回归值的构造:one - hot编码
- 目标函数
引言:生成模型 vs判别模型

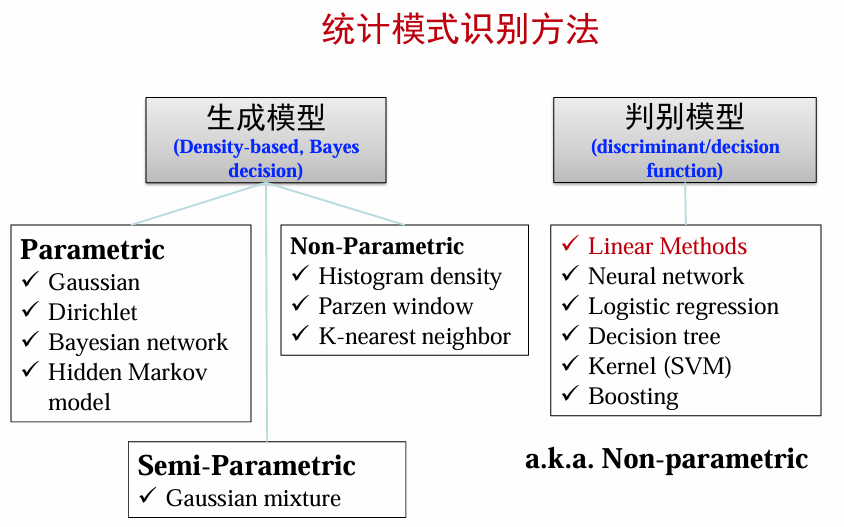
生成模型 vs 判别模型
在分类问题中,生成模型和判别模型是两种不同的建模方法:
| 生成模型 | 判别模型 |
|---|---|
| 直接建模类条件概率或联合分布 | 直接建模后验概率 p ( y ∣ x ) p(y\vert x) p(y∣x) 或决策边界 |
| 通过贝叶斯公式计算后验概率 p ( y ∣ x ) = p ( x , ∣ y ) p ( y ) p ( x ) p(y\vert x) = \frac{p(x,\vert y)p(y)}{p(x)} p(y∣x)=p(x)p(x,∣y)p(y) | 不需要假设数据的分布形式,直接关注分类任务 |
| 示例:朴素贝叶斯、隐马尔可夫模型(HMM) | 示例:支持向量机、线性判别分析、神经网络 |
| 适用于需要生成数据的场景(例如语音识别、自然语言处理) | 适合直接分类任务,通常分类性能较好 |
判别模型分类
判别模型根据复杂性和数据分布特点,可以分为以下几类:
| 线性判别函数 | 广义线性判别函数 | 非线性模型 | 非参数模型 |
|---|---|---|---|
| 假设数据是线性可分的,构造一个超平面来划分不同类别。 | 将数据映射到高维空间,使非线性问题变成线性问题。 | 不依赖数据的线性假设,适合处理复杂分布的数据。 | 不假设数据的分布形式。 |
| 简单、高效,适合高维空间。 | 使用核函数(kernel function)来处理非线性分布。 | 学习能力强,但计算复杂度较高。 | 分类直接依赖于训练样本,适合小样本场景。 |
| 感知器、支持向量机、Fisher线性判别函数 | 核学习机 | 神经网络、决策树 | K近邻分类、高斯过程 |
假设有n个d维空间中的样本,每个样本的类别标签已知,且一共有c个不同的类别。
- 学习问题:假定判别函数的形式已知,采用样本来估计判别函数的参数。
- 推理、预测问题:对于给定的新样本 x ∈ R d x\in\mathbb{R}^d x∈Rd,用判别函数判定 x x x属于 ω 1 , ω 2 , … , ω c \omega_1,\omega_2,\dots,\omega_c ω1,ω2,…,ωc中的哪个类别。
| c>2(one-vs-all) | c=2 | |
|---|---|---|
| 判别函数 | 每个类别对于判别函数 g i ( x ) , i = 1 , 2 , … , c g_i(x),i=1,2,\dots,c gi(x),i=1,2,…,c, g i ( x ) g_i(x) gi(x)用于区分第 ω i \omega_i ωi 类和其他 c − 1 c-1 c−1个类,其数值表示 x x x 属于第 ω i \omega_i ωi 类的概率、置信度、打分等. | g ( x ) = g 1 ( x ) − g 2 ( x ) g(x)=g_1(x)-g_2(x) g(x)=g1(x)−g2(x) |
| 决策准则 | g i ( x ) > g j ( x ) , ∀ j ≠ i g_i(x)>g_j(x),\forall j\neq i gi(x)>gj(x),∀j=i: x x x被分为 ω i \omega_i ωi类 | g ( x ) > 0 g(x)>0 g(x)>0: 分为第一类 ω 1 \omega_1 ω1 |
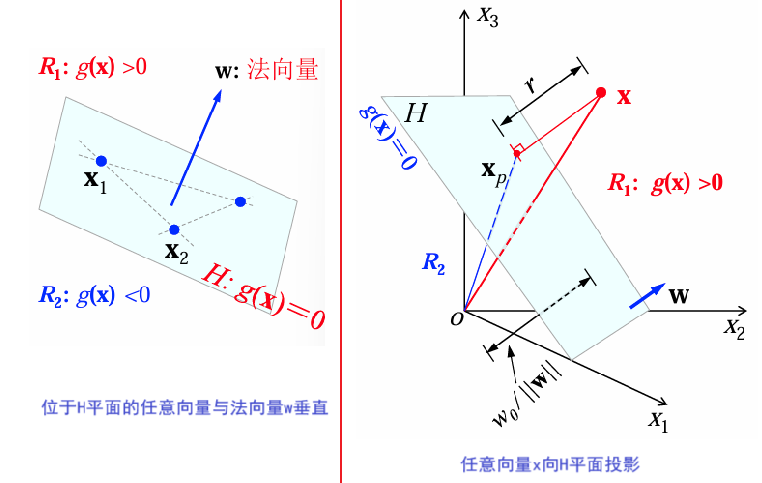
线性判别函数与决策面
线性判别函数
线性判别函数定义为:
g ( x ) = ∑ i = 1 d w i x i + w 0 = w T x + w 0 g(x) = \sum_{i=1}^d w_i x_i + w_0 = w^T x + w_0 g(x)=i=1∑dwixi+w0=wTx+w0
- w w w:权重向量,决定分类超平面的方向。
- w 0 w_0 w0:偏移量(阈值),决定超平面的位置。
两类情况下的决策
决策依据判别函数 g ( x ) g(x) g(x) 的符号:
{ x ∈ ω 1 , if g ( x ) > 0 x ∈ ω 2 , if g ( x ) < 0 uncertain , if g ( x ) = 0 \begin{cases} x \in \omega_1, & \text{if } g(x) > 0 \\ x \in \omega_2, & \text{if } g(x) < 0 \\ \text{uncertain}, & \text{if } g(x) = 0 \end{cases} ⎩ ⎨ ⎧x∈ω1,x∈ω2,uncertain,if g(x)>0if g(x)<0if g(x)=0
两类问题中的决策面:
-
H H H: g ( x ) = 0 g(x)=0 g(x)=0,用于将特征空间分为两类区域:
-
R 1 R_1 R1: g ( x ) > 0 g(x) > 0 g(x)>0
-
R 2 R_2 R2: g ( x ) < 0 g(x) < 0 g(x)<0
超平面 H H H的法向量为 w w w,垂直于决策面。
-
对于位于 H H H 内的任意向量,其法向量满足: w T ( x 1 − x 2 ) = g ( x 1 ) − g ( x 2 ) = 0 w^T (x_1 - x_2) = g(x_1) - g(x_2) = 0 wT(x1−x2)=g(x1)−g(x2)=0
-
对于任意样本/向量 x x x,将其向决策面内投影,并写成两个向量之和:
x = x p + r w ∥ w ∥ x=x_p+r\frac{w}{\|w\|} x=xp+r∥w∥w
x p x_p xp是 x x x在超平面 H H H上的投影, r r r是点 x x x到超平面 H H H的代数距离。若 x ∈ R 1 , r > 0 x\in R_1,r>0 x∈R1,r>0.
多类问题下决策
在多类分类问题中,通常使用多个二分类器来解决问题。常见策略有:
| 一对多(One-vs-All) | 一对一(One-vs-One) | 多对多 |
|---|---|---|
| 每个类别与其余类别分别构造一个二分类器,共需构造 c 个二分类器。 | 每两个类别配对构造一个二分类器,共需构造 c ( c − 1 ) 2 \frac{c(c-1)}{2} 2c(c−1) 个二分类器。 | — |
| 预测时:若只有一个分类器的预测为正,其对应类别即为预测结果;若多个分类器的预测为正,则需要比较判别函数值。 | 预测时, 对测试样本使用投票法,预测得票最多的类别。 | 使用纠错编码(Error Correcting Output Codes, ECOC),实现层次化分类。 |
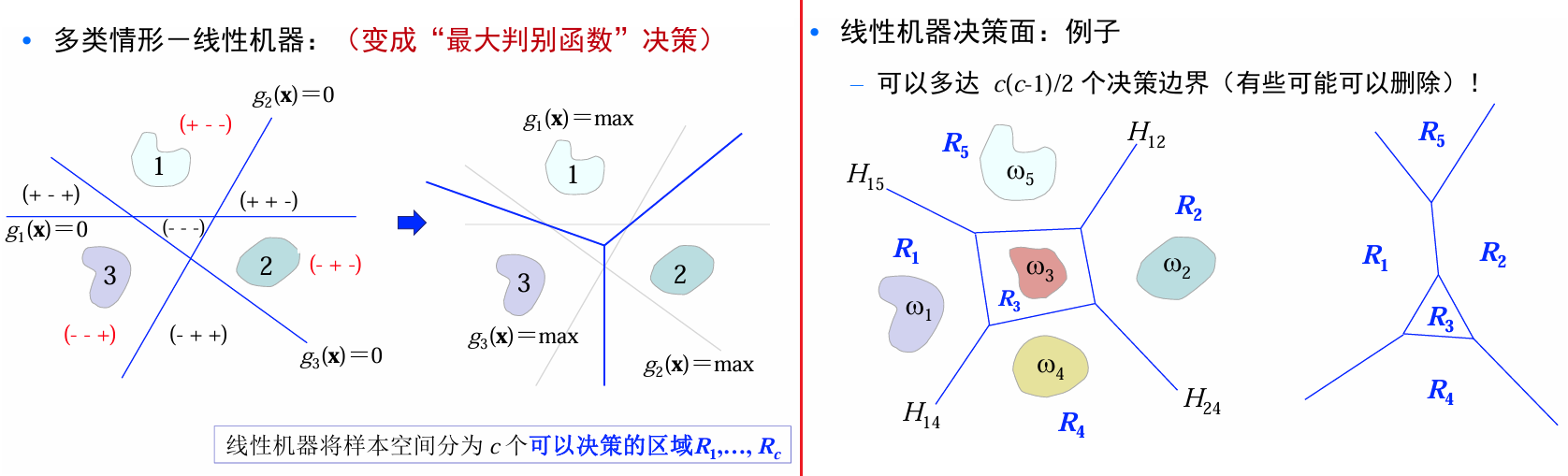
多类情形-线性机器
因为不使用判别函数的函数值、仅仅使用决策面进行分类,one-vs-all\one-vs-one都有可能存在不确定区域。
-
考虑one - vs - all情形,构建 c c c个两类线性分类器:
g i ( x ) = W i T x + w i 0 , i = 1 , 2 , ⋯ , c g_i(x)=W_i^T x + w_{i0},\quad i = 1,2,\cdots,c gi(x)=WiTx+wi0,i=1,2,⋯,c -
对样本 x x x,可以采用如下决策规则(最大判别函数决策):
-
对 ∀ j ≠ i \forall j\neq i ∀j=i,如果 g i ( x ) > g j ( x ) g_i(x)>g_j(x) gi(x)>gj(x), x x x则被分为 ω i \omega_i ωi类;否则不决策
-
g i ( x ) = max j = 1 , 2 , ⋯ , c g j ( x ) ⇒ x ∈ ω i g_i(x)=\max_{j = 1,2,\cdots,c}g_j(x)\Rightarrow x\in\omega_i gi(x)=j=1,2,⋯,cmaxgj(x)⇒x∈ωi
-
线性机器将样本空间分为 c c c个可以决策的区域 R 1 , ⋯ , R c R_1,\cdots,R_c R1,⋯,Rc。
-
线性决策面优缺点
- 所有的决策区域都是凸的——便于分析
- 所有的决策区域都是单连通的——便于分析
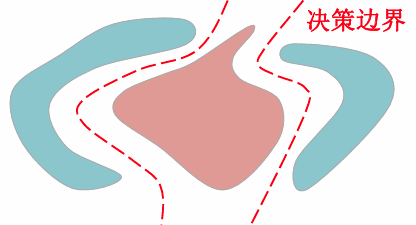
- 凸决策区域:限制分类器的灵活性和精度
- 单连通区域:不利于复杂分布数据的分类(比如:分离的多模式分布)
广义线性判别函数
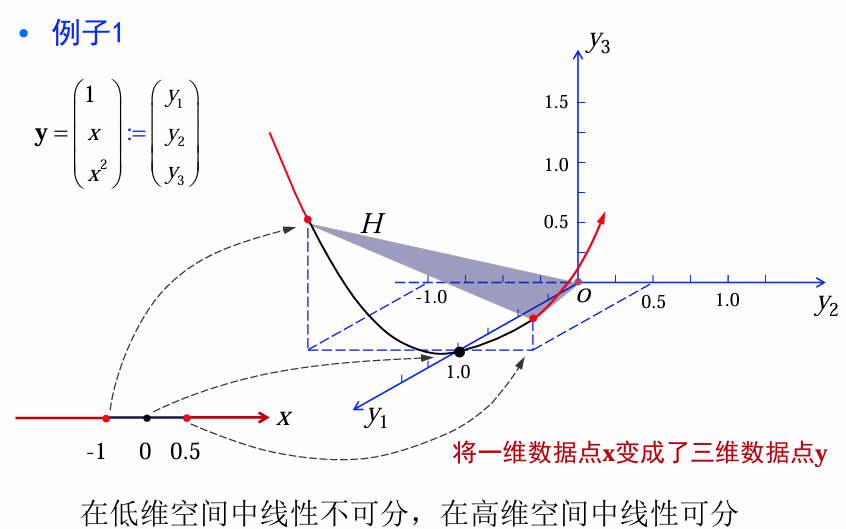
将原来的数据点 x通过一种适当的非线性映射将其映射为新的数据点 y, 从而在新的特征空间内应用线性判别函数方法。
例:二次判别函数
二次判别函数形式:
g ( x ) = w 0 + ∑ i = 1 d w i x i + ∑ i = 1 d ∑ j = 1 d w i j x i x j g(x)=w_0+\sum_{i = 1}^{d}w_i x_i+\sum_{i = 1}^{d}\sum_{j = 1}^{d}w_{ij}x_i x_j g(x)=w0+i=1∑dwixi+i=1∑dj=1∑dwijxixj
其中共有 d ^ = ( d + 1 ) ( d + 2 ) 2 \hat d =\frac{(d + 1)(d + 2)}{2} d^=2(d+1)(d+2)个系数待估计( w i j = w j i w_{ij}=w_{ji} wij=wji),且 g ( x ) = 0 g(x) = 0 g(x)=0为决策面,它是一个二次超曲面。
定义如下非线性变换 y ( x ) y(x) y(x),把 x x x从 d d d维变到 d ^ \hat d d^维:
y 1 ( x ) = 1 y 2 ( x ) = x 1 y 3 ( x ) = x 2 … y d + 1 ( x ) = x d y d + 2 ( x ) = x 1 2 y d + 3 ( x ) = x 1 x 2 … y ( d + 1 ) ( d + 2 ) 2 ( x ) = x d 2 y_1(x)=1\\y_2(x)=x_1\\ y_3(x)=x_2\\\dots\\y_{d + 1}(x)=x_d\\y_{d + 2}(x)=x_1^2\\y_{d + 3}(x)=x_1 x_2\\\dots\\y_{\frac{(d + 1)(d + 2)}{2}}(x)=x_d^2 y1(x)=1y2(x)=x1y3(x)=x2…yd+1(x)=xdyd+2(x)=x12yd+3(x)=x1x2…y2(d+1)(d+2)(x)=xd2
则有:
g ( x ) = w 0 + ∑ i = 1 d w i x i + ∑ i = 1 d ∑ j = 1 d w i j x i x j = ∑ i = 1 d ^ a i y i ( x ) \begin{align}g(x)&=w_0+\sum_{i = 1}^{d}w_i x_i+\sum^d_{i=1}\sum^d_{j=1}w_{ij}x_ix_j\\ &=\sum^{\hat d}_{i=1}a_iy_i(x) \end{align} g(x)=w0+i=1∑dwixi+i=1∑dj=1∑dwijxixj=i=1∑d^aiyi(x)
y i ( x ) y_i(x) yi(x)是变换函数、令 a = [ a 1 , a 2 , ⋯ , a d ^ ] T a = [a_1,a_2,\cdots,a_{\hat{d}}]^T a=[a1,a2,⋯,ad^]T, y = [ y 1 , y 2 , ⋯ , y d ^ ] T y = [y_1,y_2,\cdots,y_{\hat{d}}]^T y=[y1,y2,⋯,yd^]T,可简写为:
g ( x ) = a T y ( x ) g(x)=a^T y(x) g(x)=aTy(x)
其中:
- a a a为广义权重向量, y y y是经由 x x x所变成的新数据点。
- 广义判别函数 g ( x ) g(x) g(x)对 x x x而言是非线性的,对 y y y是线性的。
- g ( x ) g(x) g(x)对 y y y是齐次的,意味着决策面通过新空间的坐标原点。且任意点 y y y到决策面的代数距离为 a T y ∥ a ∥ \frac{a^T y}{\| a\|} ∥a∥aTy。
- 当新空间的维数足够高时, g ( x ) g(x) g(x)可以逼近任意判别函数。
- 但是,新空间的维数远远高于原始空间的维数 d d d时,会造成维数灾难问题。
例1: 1-D判别函数
设有一维样本空间 X X X,我们期望如果 x < − 1 x < - 1 x<−1或者 x > 0.5 x > 0.5 x>0.5,则 x x x属于 ω 1 \omega_1 ω1类;如果 − 1 < x < 0.5 -1 < x < 0.5 −1<x<0.5,则属于 ω 2 \omega_2 ω2类,请设计一个判别函数 g ( x ) g(x) g(x)。
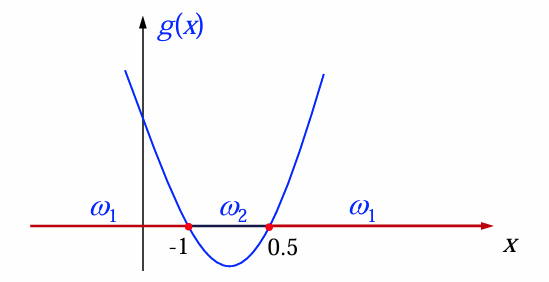
判别函数:
g ( x ) = ( x − 0.5 ) ( x + 1 ) = − 0.5 + 0.5 x + x 2 = a 1 + a 2 x + a 3 x 2 \begin{align} g(x)&=(x - 0.5)(x + 1)\\ &=-0.5+0.5x+x^2 \\ &=a_1+a_2x+a_3x^2 \end{align} g(x)=(x−0.5)(x+1)=−0.5+0.5x+x2=a1+a2x+a3x2
决策规则:
g ( x ) > 0 , x ∈ ω 1 g ( x ) < 0 , x ∈ ω 2 g(x)>0,x\in\omega_1\\g(x)<0,x\in\omega_2 g(x)>0,x∈ω1g(x)<0,x∈ω2
映射关系:
y = ( 1 x x 2 ) : = ( y 1 y 2 y 3 ) y=\begin{pmatrix}1\\x\\x^2\end{pmatrix}:=\begin{pmatrix}y_1\\y_2\\y_3\end{pmatrix} y= 1xx2 := y1y2y3

感知准则函数
概念
线性可分性:来自两个类别的n个样本 y 1 , y 2 , … , y n y_1,y_2,\dots,y_n y1,y2,…,yn(齐次增广表示)。存在一个权向量 a a a,对所有 y ∈ ω 1 y\in \omega_1 y∈ω1,均有 a T y > 0 a^Ty>0 aTy>0;对所有 y ∈ ω 2 y\in \omega_2 y∈ω2,均有 a T y < 0 a^Ty<0 aTy<0。
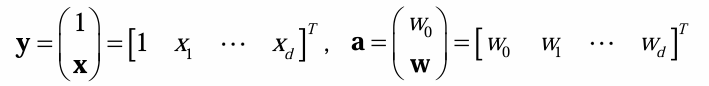
齐次增广->规范化增广
样本规范化:如果样本集是线性可分的,那么将属于 ω 2 \omega_2 ω2的所有样本由 y y y变成 − y -y −y,对所有 n n n样本,将得到 a T y > 0 a^Ty>0 aTy>0。这样训练中就不需要考虑原来的样本类别。
规范化增广样本:1.将所有样本写成齐次增广形式;2.属于 ω 2 \omega_2 ω2的所有样本由 y y y变成 − y -y −y
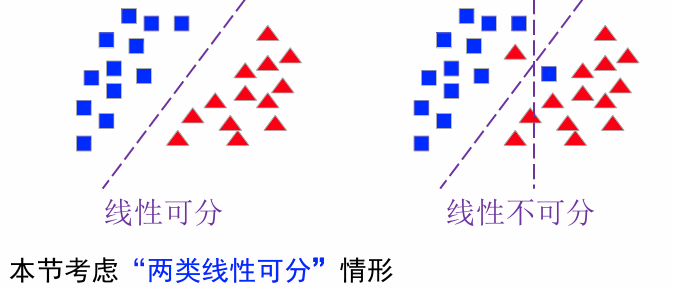
解向量与解区
解向量:线性可分的情况下,满足 a T y i > 0 , i = 1 , 2 , … , n a^Ty_i>0,i=1,2,\dots,n aTyi>0,i=1,2,…,n的权向量 a a a.
解向量 a a a 是我们需要找到的“分类方向”,它保证所有样本点都在它的正确一侧。
**解区:**权向量 a a a属于权空间中的一点,每个样本 y i y_i yi对 a a a的位置均起到限制作用( a T y i > 0 a^Ty_i>0 aTyi>0)
- 任何一个样本点 y i y_i yi均可以确定一个超平面 H i : a T y i = 0 H_i:a^Ty_i=0 Hi:aTyi=0( y i y_i yi是法向量,所有与 y i y_i yi垂直的属于 H i H_i Hi,且 y i y_i yi决定了超平面的方向。)
- 如果解向量存在,那必在每个超平面的正侧( a T y i > 0 a^Ty_i>0 aTyi>0); n n n个样本将产生 n n n个超平面。每个超平面将空间一分为二。解向量存在于所有超平面正面的交集区域,此区域内的任意向量都是解向量。
**限制解区:**解向量存在的话,通常不唯一。根据经验越靠近区域中间的解向量,越能对新的样本正确分类,所以引入附加条件来限制解空间。
-
way1: 寻找单位长度的解向量 a a a,最大化样本到分界面的最小距离。
-
way2: ∀ i \forall i ∀i, 寻找满足 a T y i ≥ b > 0 a^Ty_i\ge b>0 aTyi≥b>0的最小长度的解向量 a a a, b:margin.
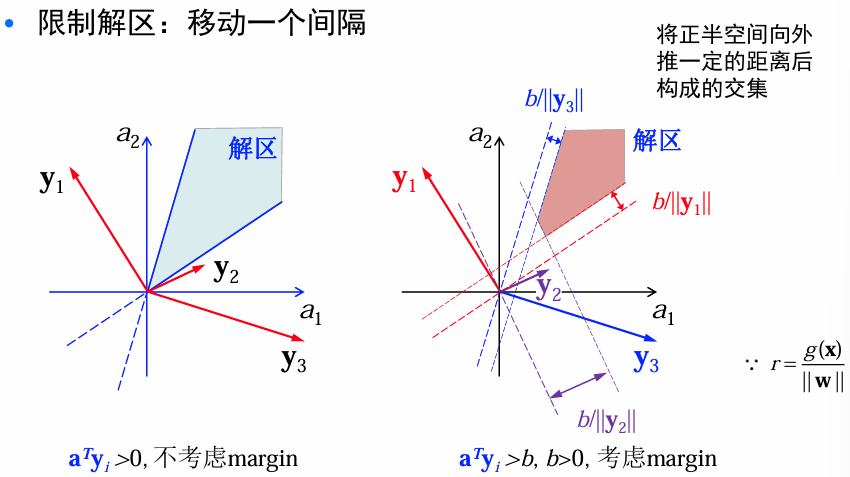
感知准则函数
现在考虑构造解线性不等式 a T y i > 0 a^Ty_i>0 aTyi>0的准则函数问题。令 J ( a ; y 1 , … , y n ) J(a;y_1,\dots,y_n) J(a;y1,…,yn)维被 a a a错分的样本数。但这个函数是分段常数函数,对梯度搜索不友好。因此考虑感知器准则函数:
J p ( a ) = ∑ y ∈ Y ( − a T y ) J_p(a)=\sum_{y\in \mathcal{Y}}(-a^Ty) Jp(a)=y∈Y∑(−aTy)
Y \mathcal{Y} Y是错分样本集合。
当 y i y_i yi被错分: a T y i < 0 ⇒ − a T y i > 0 a^Ty_i<0\Rightarrow -a^Ty_i>0 aTyi<0⇒−aTyi>0,使 J p ( a ) ≥ 0 J_p(a)\ge 0 Jp(a)≥0.
在可分情况下,当且仅当 Y \mathcal{Y} Y是空集时 J p ( a ) J_p(a) Jp(a)将=0,此时不存在错分样本。
目标: min a J p ( a ) \min_a J_p(a) minaJp(a)
梯度下降更新: a k + 1 a_{k+1} ak+1是当前迭代的结果, a k a_k ak是前一次迭代的结果, Y k \mathcal{Y}_k Yk是被 a k a_k ak 错分的样本集合 , η k \eta_k ηk为步长因子(更新动力因子,学习率)。
∂ J p ( a ) ∂ a = − ∑ y ∈ Y y a k + 1 = a k − η k ∂ J p ( a ) ∂ a ∣ a = a k = a k + η k ∑ y ∈ Y k y \frac{\partial J_p(a)}{\partial a}=-\sum_{y\in\mathcal{Y}}y\\ a_{k+1}=a_k-\eta_k\frac{\partial J_p(a)}{\partial a}\vert_{a=a_k}=a_k+\eta_k\sum_{y\in \mathcal{Y}_k}y ∂a∂Jp(a)=−y∈Y∑yak+1=ak−ηk∂a∂Jp(a)∣a=ak=ak+ηky∈Yk∑y


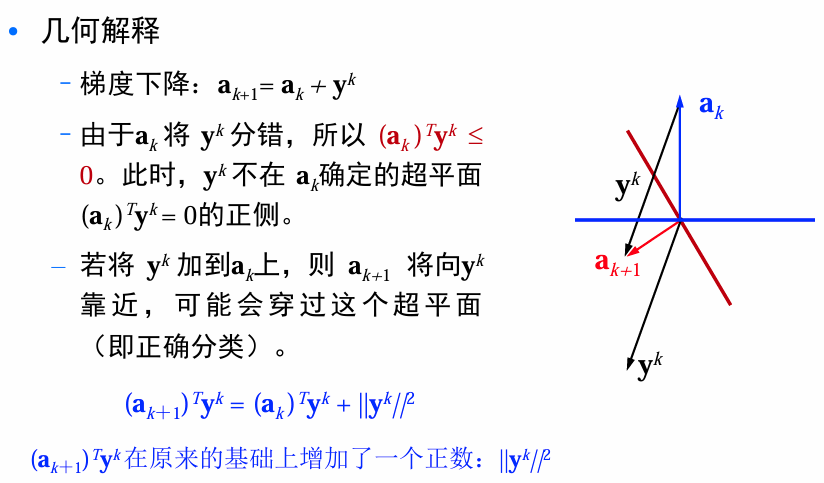
算法收敛性
以固定增量单样本修正方法为例来说明算法的收敛性:
对于权向量 a k a_k ak,如果错分某样本,则将得到一次修正。由于在分错样本时 a k a_k ak才得到修正,不妨假定只考虑由错分样本组成的序列。即每次都只需利用一个分错样本来更正权向量。
记错分样本序列为 y 1 , y 2 , … , y k , … y_1,y_2,\dots, y_k, \dots y1,y2,…,yk,…。考虑此情形的算法收敛性问题。
**收敛性定理:**在样本线性可分的情形下,固定增量单样本权向量修正方法收敛,并可得到一个可行解。
证明思路:设 a a a是一个解向量,只需证明 ∥ a k + 1 − a ∥ < ∥ a k − a ∥ − C \|a_{k+1}-a\|<\|a_k-a\|-C ∥ak+1−a∥<∥ak−a∥−C即可。
- 算法每次迭代都会使权向量到解向量的距离减少1个常数C
- 假设 d s t = ∥ a 1 − a ∥ dst=\|a_1-a\| dst=∥a1−a∥,则dst在经过C次迭代后(计算了足够长的步数),算法收敛。
感觉证明不考,因此略。
松驰方法
学习准则
在感知函数准则中,目标函数中采用了 − a T y −a^Ty −aTy 的形式。实际上有很多其它准则也可以用于感知函数的学习。
| 线性准则 | 平方准则 | 松驰准则 |
|---|---|---|
| J p ( a ) = ∑ y ∈ Y ( − a T y ) J_p(a)=\sum_{y\in\mathcal{Y}}(-a^Ty) Jp(a)=∑y∈Y(−aTy) | J q ( a ) = ∑ y ∈ Y ( a T y ) 2 J_q(a)=\sum_{y\in\mathcal{Y}}(a^Ty)^2 Jq(a)=∑y∈Y(aTy)2 | J r ( a ) = 1 2 ∑ y ∈ Y ( a T y − b ) 2 / ∣ y ∣ 2 J_r(a)=\frac 1 2\sum_{y\in\mathcal{Y}}(a^Ty-b)^2/|y|^2 Jr(a)=21∑y∈Y(aTy−b)2/∣y∣2 |
| Y \mathcal{Y} Y为错分样本集合 | Y \mathcal{Y} Y为错分样本集合 | Y \mathcal{Y} Y是 a T y ≤ b a^Ty\le b aTy≤b的样本集合 |
| 分段线性,梯度不连续 | 梯度连续,但目标函数过于平滑,收敛速度很慢。此外,目标和拿书过于受到最长样本的影响。 | 避免了线性准则和平方准则的缺点。 J r ( a ) = 0 J_r(a)=0 Jr(a)=0时,对所有 y , a T y > b y,a^Ty>b y,aTy>b,意味着 Y \mathcal{Y} Y是空集。 |
松弛准则的梯度下降:
∂ J r ( a ) ∂ a = ∑ y ∈ Y a T y − b ∥ y ∥ 2 y a k + 1 = a k − η k ∑ y ∈ Y a T y − b ∥ y ∥ 2 y \frac{\partial J_r(a)}{\partial a}=\sum_{y\in\mathcal{Y}}\frac{a^Ty-b}{\|y\|^2}y\\ a_{k+1}=a_k-\eta_k\sum_{y\in\mathcal{Y}}\frac{a^Ty-b}{\|y\|^2}y ∂a∂Jr(a)=y∈Y∑∥y∥2aTy−byak+1=ak−ηky∈Y∑∥y∥2aTy−by

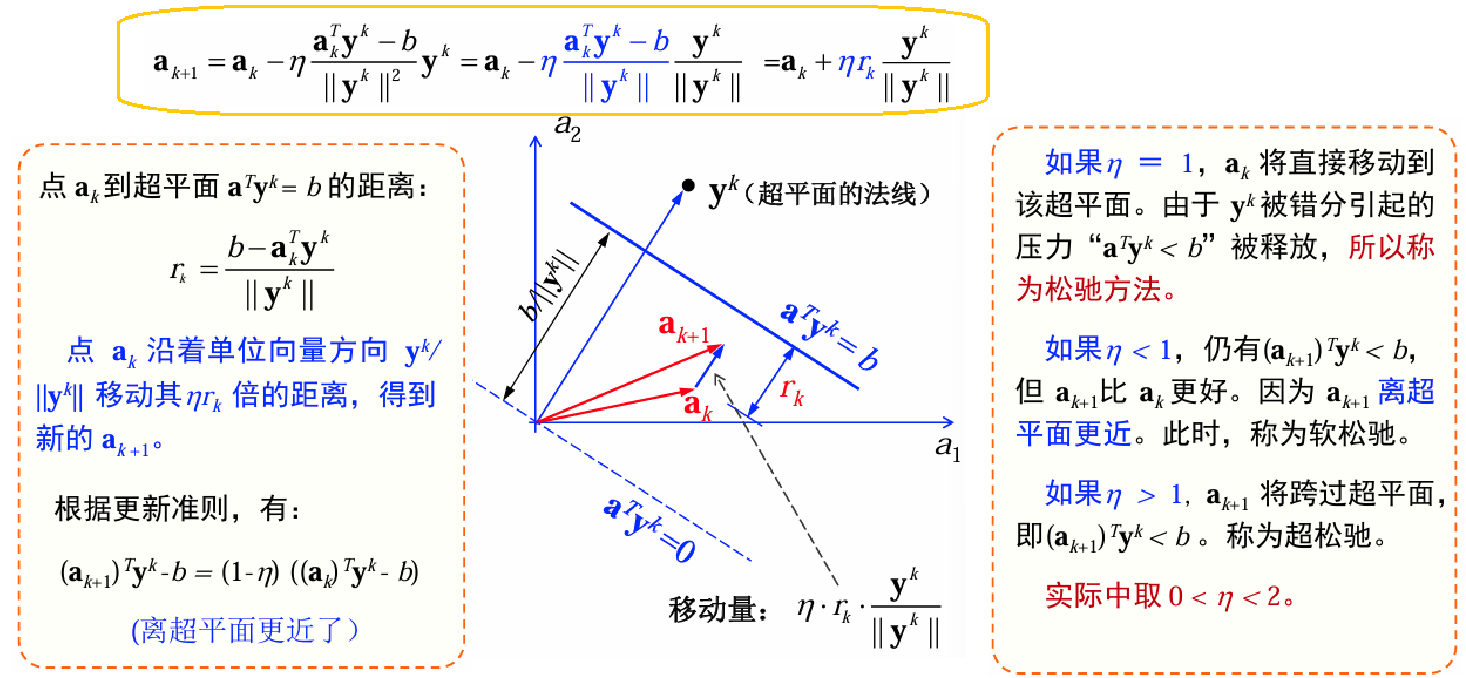
收敛性证明略。
最小平方误差(MSE)准则函数
前面考虑的准则函数都是只考虑被错分的样本。现在考虑一种包含所有样本的准则函数。
**动机:**对两类分问题,感知准则函数是寻找一个解向量 a,对所有样本 y i y_i yi,满足 a T y i > 0 , i = 1 , 2 , … n a^Ty_i>0, i=1,2,…n aTyi>0,i=1,2,…n。或者说,求解一个不等式组,使满足 a T y i > 0 a^Ty_i >0 aTyi>0的数目最大,从而错分样本最少。
a T y i = b i > 0 a^Ty_i=b_i>0 aTyi=bi>0
其中, b i b_i bi是任意给定的正常数,通常取 b i = 1 b_i = 1 bi=1,或者 b i = n i n b_i=\frac{n_i}{n} bi=nni。其中, n i n_i ni( i = 1 i = 1 i=1或 2 2 2)为属于第 i i i类样本的总数,且 n 1 + n 2 = n n_1 + n_2 = n n1+n2=n。
线性判别函数的参数估计
可得一个线性方程组: Y a = b Ya = b Ya=b
$$
\begin{bmatrix}
y_{10} & y_{11} & \cdots & y_{1d}\
y_{20} & y_{21} & \cdots & y_{2d}\
\vdots & \vdots & \ddots & \vdots\
y_{n0} & y_{n1} & \cdots & y_{nd}
\end{bmatrix}
\begin{bmatrix}
a_0\
a_1\
\vdots\
a_d
\end{bmatrix}
\begin{bmatrix}
b_1\
b_2\
\vdots\
b_n
\end{bmatrix}
$$
- 如果 Y Y Y可逆,则 a = Y − 1 b a = Y^{-1}b a=Y−1b。
- 但通常情形下, n ≫ d + 1 n\gg d + 1 n≫d+1,因此,考虑定义一个误差向量: e = Y a − b e = Ya - b e=Ya−b,并使误差向量最小。
平方误差准则函数
J s ( a ) = ∥ e ∥ 2 = ∥ Y a − b ∥ 2 = ∑ i = 1 n ( a T Y i − b i ) 2 J_s(a)=\|e\|^2=\|Ya - b\|^2=\sum_{i = 1}^{n}(a^T Y_i - b_i)^2 Js(a)=∥e∥2=∥Ya−b∥2=i=1∑n(aTYi−bi)2
对其求导:
∂ J s ( a ) ∂ a = ∑ i = 1 n 2 ( a T Y i − b i ) Y i = 2 Y T ( Y a − b ) = 0 Y T Y a = Y T b ⇒ a = ( Y T Y ) − 1 Y T b = Y † b \frac{\partial J_s(a)}{\partial a}=\sum_{i = 1}^{n}2(a^T Y_i - b_i)Y_i = 2Y^T(Ya - b)=0\\ Y^T Ya = Y^T b\Rightarrow a=(Y^T Y)^{-1}Y^T b = Y^\dagger b ∂a∂Js(a)=i=1∑n2(aTYi−bi)Yi=2YT(Ya−b)=0YTYa=YTb⇒a=(YTY)−1YTb=Y†b
其中, Y + Y^+ Y+为 Y Y Y的伪逆。
实际计算(正则化技术):$Y\dagger\approx(YT Y+\varepsilon I){-1}YT (\text{即回归分析方法}) $
梯度下降法
计算伪逆需要矩阵的逆,计算复杂度高。如果原始样本的维数很高,比如 d > 5000 d>5000 d>5000,将十分耗时。
-
批处理梯度下降:
a k + 1 = a k + η k Y T ( b − Y a k ) a_{k + 1}=a_k+\eta_k Y^T(b - Ya_k) ak+1=ak+ηkYT(b−Yak)
梯度下降法得到的 a k + 1 a_{k + 1} ak+1将收敛于一个解,该解满足方程:
Y T ( b − Y a ) = 0 Y^T(b - Ya)=0 YT(b−Ya)=0 -
单样本梯度下降:此方法需要的计算存储量会更小(此时考虑单个样本对误差的贡献)
a k + 1 = a k + η k ( b k − ( a k ) T y k ) y k a_{k + 1}=a_k+\eta_k(b_k-(a_k)^T y^k)y^k ak+1=ak+ηk(bk−(ak)Tyk)yk


Ho-Kashyap方法
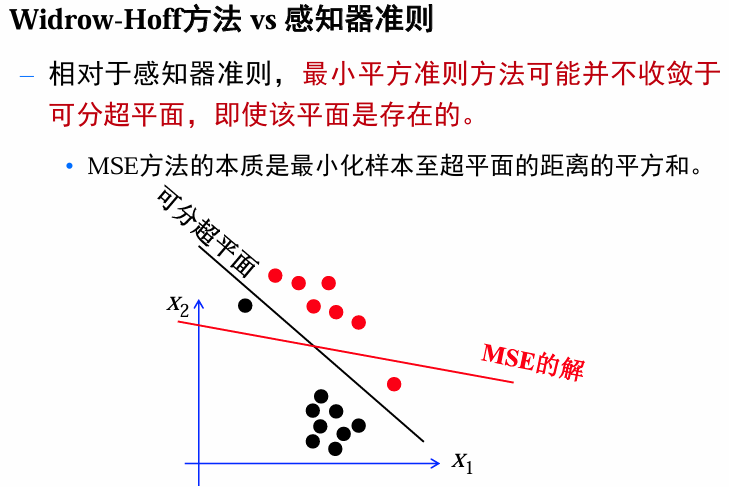
感知器和松弛法对线性可分样本集可找到分离向量,但对于不可分的情况就不收敛了。
MSE算法不管样本是否可分都能得到一个权向量,但并不能保证在可分的情况下这个向量一定是分类向量。
若margin b b b是任意选择的,MSE只是 min ∥ Y a − b ∥ 2 \min \|Ya-b\|^2 min∥Ya−b∥2,所得到的最优解并不需要位于可分超平面上。若训练样本刚好是线性可分的,那么存在 a ^ , b ^ \hat a,\hat b a^,b^满足:
Y a ^ = b ^ > 0 Y\hat a=\hat b>0 Ya^=b^>0
当我们设置 b = b ^ b=\hat b b=b^,利用MSE,就能找到一个分类向量。但是我们没法预知 b ^ \hat b b^。
对MSE准则函数更新为:
J s ( a , b ) = ∥ Y a − b ∥ 2 J_s(a,b)=\|Ya-b\|^2 Js(a,b)=∥Ya−b∥2
ps:直接优化 J s ( a , b ) J_s(a,b) Js(a,b)将导致平凡解,所以需要给 b b b添加约束条件: b > 0 b>0 b>0.
此时 b b b可以解释为margin.
梯度下降
∂ J s ( a , b ) ∂ a = 2 Y T ( Y a − b ) , ∂ J s ( a , b ) ∂ b = − 2 ( Y a − b ) b k + 1 = b k − η k ∂ J s ( a , b ) ∂ b \frac{\partial J_s(a,b)}{\partial a}=2Y^T(Ya-b),\quad \frac{\partial J_s(a,b)}{\partial b}=-2(Ya-b)\\ b_{k+1}=b_k-\eta_k\frac{\partial J_s(a,b)}{\partial b} ∂a∂Js(a,b)=2YT(Ya−b),∂b∂Js(a,b)=−2(Ya−b)bk+1=bk−ηk∂b∂Js(a,b)
约束条件: a = Y † b a=Y^\dagger b a=Y†b, b > 0 b>0 b>0
因为 b k ≥ 0 b_k\ge0 bk≥0,要使 b k + 1 ≥ 0 b_{k+1}\ge0 bk+1≥0,可以要求 ∂ J s ( a , b ) ∂ b ≤ 0 \frac{\partial J_s(a,b)}{\partial b}\le 0 ∂b∂Js(a,b)≤0:
b k + 1 = b k − η k 1 2 ( ∂ J s ( a , b ) ∂ b − ∣ ∂ J s ( a , b ) ∂ b ∣ ) b_{k+1}=b_k-\eta_k\frac12\left(\frac{\partial J_s(a,b)}{\partial b}-\vert \frac{\partial J_s(a,b)}{\partial b}\vert \right) bk+1=bk−ηk21(∂b∂Js(a,b)−∣∂b∂Js(a,b)∣)
更新 a , b a,b a,b:
a k + 1 = Y † b k b 1 > 0 , b k + 1 = b k + 2 η k e k † e k † = 1 2 ( ( Y a k − b k ) + ∣ Y a k − b k ∣ ) ⇐ ∂ J s ( a , b ) ∂ b = − 2 ( Y a − b ) a_{k+1}=Y^{\dagger}b_k\\ b_1>0,\quad b_{k+1}=b_k+2\eta_ke^{\dagger}_k\\ e^{\dagger}_k=\frac 12 \left((Ya_k-b_k)+\vert Ya_k-b_k\vert\right)\Leftarrow\frac{\partial J_s(a,b)}{\partial b}=-2(Ya-b) ak+1=Y†bkb1>0,bk+1=bk+2ηkek†ek†=21((Yak−bk)+∣Yak−bk∣)⇐∂b∂Js(a,b)=−2(Ya−b)
- 为了防止 b b b收敛于 0 0 0,可以让 b b b从一个非负向量( b 1 > 0 b_1>0 b1>0)开始进行更新。
- 由于要求 ∂ J s ( a , b ) ∂ b \frac{\partial J_s(a,b)}{\partial b} ∂b∂Js(a,b)等于 0 0 0,在开始迭代时可令 ∂ J s ( a , b ) ∂ b \frac{\partial J_s(a,b)}{\partial b} ∂b∂Js(a,b)的元素为正的分量等于零,从而加快收敛速度。
伪算法
- 由于权向量序列 { a k } \{a_k\} {ak}完全取决于 { b k } \{b_k\} {bk},因此本质上讲Ho - Kashyap算法是一个生成margin序列 { b k } \{b_k\} {bk}的方法。
- 由于初始 b 1 > 0 b_1>0 b1>0,且更新因子 η > 0 \eta>0 η>0,因此 b k b_k bk总是大于 0 0 0。
- 对于更新因子 0 < η ≤ 1 0<\eta\leq1 0<η≤1,如果问题线性可分,则总能找到元素全为正的 b b b。
- 如果 e k = Y a k − b k e_k = Ya_k - b_k ek=Yak−bk全为 0 0 0,此时, b k b_k bk将不再更新,因此获得一个解。如果 e k e_k ek有一部分元素小于 0 0 0,则可以证明该问题不是线性可分的。(证明略)

多类线性判别函数
决策规则: ∀ j ≠ i , g i ( x ) ≥ g j ( x ) \forall j\neq i,g_i(x)\ge g_j(x) ∀j=i,gi(x)≥gj(x), x x x被分为 ω i \omega_i ωi类。
x x x被分为 ω i \omega_i ωi类的线性判别函数:
∀ j ≠ i , a i T x + b i ≥ a j T x + b j \forall j\neq i,a_i^Tx+b_i\ge a_j^Tx+b_j ∀j=i,aiTx+bi≥ajTx+bj
方法一:MSE多类扩展
可以直接采用 c c c个两类分类器的组合,且这种组合具有与两类分类问题类似的代数描述形式。
线性变换(注,此处不采用规范化增广表示):
z = W T x + b , W ∈ R d × c , b ∈ R c z = W^T x + b,\quad W\in R^{d\times c},\quad b\in R^c z=WTx+b,W∈Rd×c,b∈Rc
决策准则: if j = arg max ( W T x + b ) , then x ∈ ω j \text{if}\quad j = \arg \max(W^T x + b),\quad \text{then}\quad x\in\omega_j ifj=argmax(WTx+b),thenx∈ωj
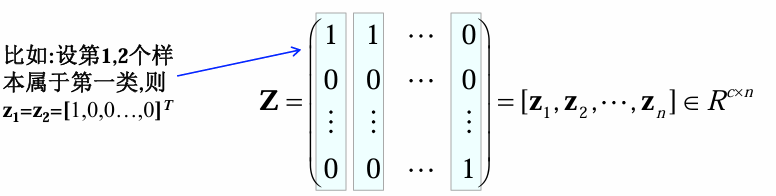
回归值的构造:one - hot编码
x ∈ ω j ⇒ z ∈ R c , z i j = { 1 , if i = j 0 , otherwise x\in\omega_j\Rightarrow z\in R^c,\quad z_{ij}=\begin{cases}1, & \text{if}\quad i = j\\0, & \text{otherwise}\end{cases} x∈ωj⇒z∈Rc,zij={1,0,ifi=jotherwise
若 x x x属于 ω j \omega_j ωj类,则 x x x的类别编码 z z z为一个 c c c维向量,其中第 j j j个元素为 1 1 1,其余为 0 0 0。
目标函数
min W , b ∑ i = 1 n ∥ W T x i + b − z i ∥ 2 2 \min_{W,b}\sum_{i = 1}^{n}\|W^T x_i + b - z_i\|_2^2 W,bmini=1∑n∥WTxi+b−zi∥22
令:
W = [ W T b ] ∈ R ( d + 1 ) × c , x ^ = [ x 1 ] ∈ R d + 1 , X ^ = ( x ^ 1 , x ^ 2 , ⋯ , x ^ n ) ∈ R ( d + 1 ) × n W = \begin{bmatrix}W^T\\b\end{bmatrix}\in R^{(d + 1)\times c},\ \hat{x}=\begin{bmatrix}x\\1\end{bmatrix}\in R^{d + 1},\ \hat{X}=(\hat{x}_1,\hat{x}_2,\cdots,\hat{x}_n)\in R^{(d + 1)\times n} W=[WTb]∈R(d+1)×c, x^=[x1]∈Rd+1, X^=(x^1,x^2,⋯,x^n)∈R(d+1)×n
则有:
∑ i = 1 n ∥ W T x i + b − z i ∥ 2 2 = ∥ W ^ T X ^ − Z ∥ F 2 \sum_{i = 1}^{n}\|W^T x_i + b - z_i\|_2^2=\|\hat{W}^T\hat{X}-Z\|_F^2 i=1∑n∥WTxi+b−zi∥22=∥W^TX^−Z∥F2
∥ ⋅ ∥ F \|\cdot\|_F ∥⋅∥F为Frobenius范数。进而有:
min W ∥ W ^ T X ^ − Z ∥ F 2 W ^ = ( X ^ X ^ T ) − 1 X ^ Z T ∈ R ( d + 1 ) × c \min_{W}\|\hat{W}^T\hat{X}-Z\|_F^2\\ \hat{W}=(\hat{X}\hat{X}^T)^{-1}\hat{X}Z^T\in R^{(d + 1)\times c}\\ Wmin∥W^TX^−Z∥F2W^=(X^X^T)−1X^ZT∈R(d+1)×c
实际中:可能会遇到矩阵奇异或数值不稳定的问题。为此,我们引入正则化项(类似岭回归)
W ^ = ( X ^ X ^ T + λ I ) − 1 X ^ Z T ∈ R ( d + 1 ) × c \hat{W}=(\hat{X}\hat{X}^T+\lambda I)^{-1}\hat{X}Z^T\in R^{(d + 1)\times c} W^=(X^X^T+λI)−1X^ZT∈R(d+1)×c
λ \lambda λ: 正则化参数,通常取一个小正数。防止过拟合以及增强数值计算的稳定性。
R^{d + 1},\ \hat{X}=(\hat{x}_1,\hat{x}_2,\cdots,\hat{x}n)\in R^{(d + 1)\times n}
则有: 则有: 则有:
\sum{i = 1}{n}|WT x_i + b - z_i|_22=|\hat{W}T\hat{X}-Z|F^2
KaTeX parse error: Can't use function '$' in math mode at position 2: $̲\|\cdot\|_F$为Fr…
\min{W}|\hat{W}T\hat{X}-Z|_F2\
\hat{W}=(\hat{X}\hat{X}T){-1}\hat{X}Z^T\in R^{(d + 1)\times c}\
实际中:可能会遇到矩阵奇异或数值不稳定的问题。为此,我们引入正则化项(类似岭回归) 实际中:可能会遇到矩阵奇异或数值不稳定的问题。为此,我们引入正则化项(类似岭回归) 实际中:可能会遇到矩阵奇异或数值不稳定的问题。为此,我们引入正则化项(类似岭回归)
\hat{W}=(\hat{X}\hat{X}^T+\lambda I){-1}\hat{X}ZT\in R^{(d + 1)\times c}
$$
λ \lambda λ: 正则化参数,通常取一个小正数。防止过拟合以及增强数值计算的稳定性。












