目录
7.1 概述
7.1.1 分布式并行编程
7.1.2 MapReduce模型简介
7.1.3 Map和Reduce函数
7.2 MapReduce体系结构
Client
JobTracker
TaskTracker
Task
7.1 概述
7.1.1 分布式并行编程
“摩尔定律”, CPU性能大约每隔18个月翻一番。从2005年开始摩尔定律逐渐失效 ,需要处理的数据量快速增加,人们开始借助于分布式并行编程来提高程序性能。分布式程序运行在大规模计算机集群上,可以并行执行大规模数据处理任务,从而获得海量的计算能力。谷歌公司最先提出了分布式并行编程模型MapReduce,Hadoop MapReduce是它的开源实现,后者比前者使用门槛低
7.1.2 MapReduce模型简介
| | 传统并行计算框架 | MapReduce |
| 集群架构/容错性 | 共享式(共享内存/共享存储),容错性差 | 非共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN,价格贵,扩展性差 | 普通PC机,便宜,扩展性好 |
| 编程/学习难度 | what-how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 批处理、非实时、数据密集型 |
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架 。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。简单说 MapReduce 是一个框架,一个分布式计算框架,只需用户将业务逻辑放到框架中,就会和框架组成一个分布式运算程序,在 Hadoop 集群上实行分布式计算 。
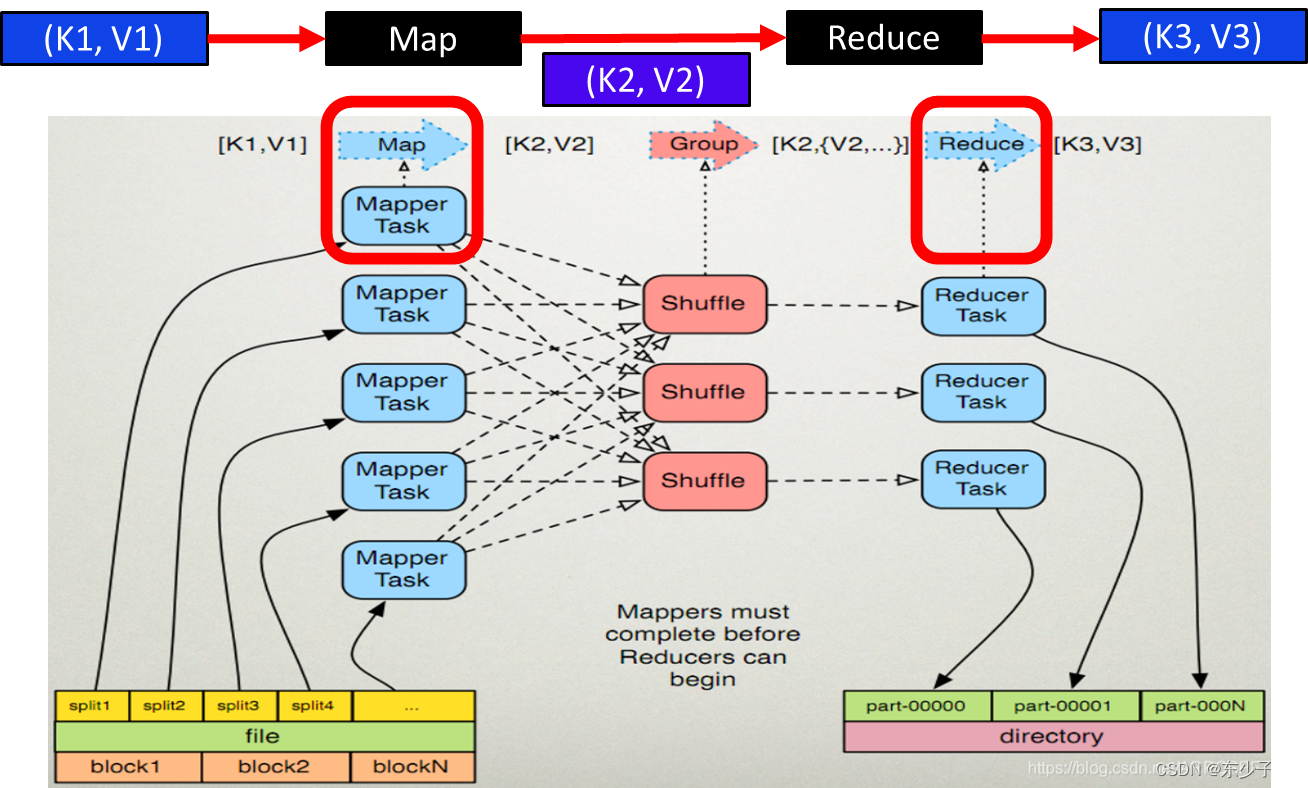
MapReduce 将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数: Map 和 Reduce 。编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算 。
MapReduce 采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分 成许多独立的小数据集,并可以并多个 Map 任务并行处理。 MapReduce 框架会为每个 Map 任务输入一个小数据集(一个切片), Map 任务生成的结果会继续作为 Reduce 任务的输入,最终由 Reduce 任务输出最终结果。
适用MapReduce处理的数据集需要满足:待处理的数据集可以分成许多小的数据集,且每个小数据集都可以完全并行的处理
MapReduce 设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为移动数据需要大量的网络传输开销 。
在一个集群中,MapReduce会尽可能将Map程序就近在HDFS数据所在的节点运行,即将计算节点和数据节点存放在一起运行,减小节点之间数据移动的开销
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker。
Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写 。
7.1.3 Map和Reduce函数
MapReduce的核心是Map和Reduce函数,程序员只需关心如何实现Map和Reduce函数。Map和Reduce函数都是以<key , value>作为输入,按照一定的规则将其转成另一个或另一批<key,value>进行输出。
| 函数 | 输入 | 输出 | 说明 |
| Map | <k1,v1> 如: <行号,”a b c”> | List(<k2,v2>) 如: <“a”,1> <“b”,1> <“c”,1> | 1.将小数据集进一步解析成一批<key,value>对, 输入Map函数中进行处理 2.每一个输入的<k1,v1>会输出一批<k2,v2>。 <k2,v2>是计算的中间结果 |
| Reduce | <k2,List(v2)> 如:<“a”,<1,1,1>> | <k3,v3> 如: <“a”,3> | 输入的中间结果<k2, List(v2)>中的List(v2) 表示是一批属于同一个k2的value |
简单实例
编写一个MapReduce程序来统计一个文本文件中每个单词出现的次数。
(1)<k1,v1>保存的就是<行号,行内容>;
(2)Map函数: <k1,v1>作为输入,实现一系列中间结果<k2,v2>,保存<单词,出现次数>;
(3)Reduce函数:中间结果<k2,v2>作为输入,实现将相同单词的出现次数进行累加,得到每个单词的总次数。

7.2 MapReduce体系结构
在Hadoop中,用于执行MapReduce作业的机器角色有两个:JobTracker和TaskTracker。JobTracker用于调度作业,TaskTracker用于跟踪任务的执行情况。一个Hadoop集群只有一个JobTracker。
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
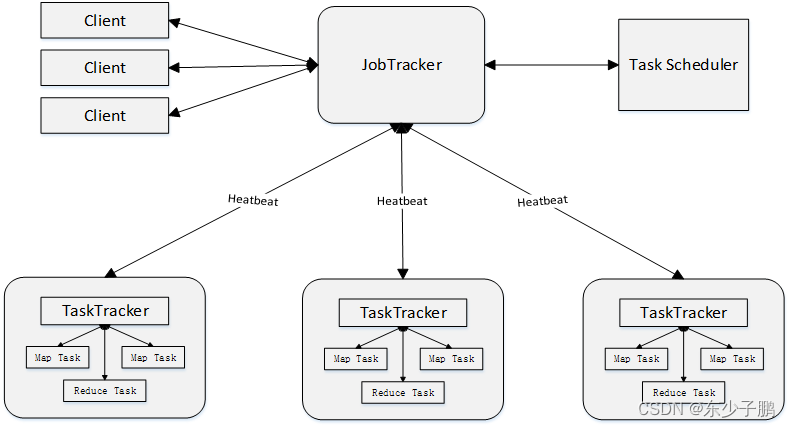
Client
① 用户编写的 MapReduce 程序通过 Client 提交到 JobTracker 端 ;
② 用户可通过 Client 提供的一些接口查看作业运行 状态 ;
JobTracker
① JobTracker 负责资源监控和作业调度
② JobTracker 监控所有 TaskTracker 与 Job 的健康状况,一旦发现失败,就将相应的任务转移到其他节点
③ JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器( TaskScheduler ),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
TaskTracker
① TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给 JobTracker ,同时接收 JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
② TaskTracker 使用“ slot” 等量划分本节点上的资源量( CPU 、内存等)。一个 Task 获取到一个 slot 后才有机会运行,而 Hadoop 调度器的作用就是将各个 TaskTracker 上的空闲 slot 分配给 Task 使用。 slot 分为 Map slot 和 Reduce slot 两种,分别供 MapTask 和 Reduce Task 使用
Task
Task 分为 Map Task 和 Reduce Task 两种,均由 TaskTracker 启动













