博主介绍:资深开发工程师,从事互联网行业多年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在在的写点程序。
🍅文末点击卡片获取联系🍅
技术:python+深度学习+mysql+卷积神经网络
1、绪论
1.1研究背景
当下是一个信息化高速发展的时代,信息的大数据时代为人们带来了丰富多彩的数字化信息内容,多媒体更是在数字化时代的发展下不断的壮大。多媒体通过网络的传递实现更加便捷、迅速、广泛的传递过程,实现很好的文化氛围,也实现了丰富的内容构成。但是面对铺天盖地的信息,信息的过载问题也逐渐的凸显出来。现在人们在信息的消费、信息的生产过程中,面对海量的资源如何进行筛选和加以利用,成了困扰人们的一大难题。面对消费群体,消费者们无法从中获取有效的信息,而面对生产者,生产者希望自己的信息被广泛推广,被广泛阅读,但是由于整个网络的信息体量大,而是生产者的创作容易被石沉大海。针对过载问题日益的严重,搜索引擎的出现大大的缓解了人们寻找所需信息的压力,另外推荐系统的出现也加强了人们对于海量信息搜索的困扰。其中,搜索引擎属于一种相对被动的信息检索,需要用户输入相应内容,根据内容提示来进行相关信息的检索。而推荐系统则是通过对用户的历史行为、大数据逻辑进行分析,从而推荐给用户其可能感兴趣的信息。
目前推荐系统在图书阅读、音乐播放、视频播放等领域有着深入的应用,我国的抖音、头条等都利用了推荐功能来根据用户浏览的历史、页面停留的时长等来进行相应内容分析,从而向用户推荐其感兴趣的相关信息。国外的Netflix以及YouTube也有着相应的推荐功能。在音乐方面,现在的QQ音乐、网易云音乐等也都有着类似的推荐功能,通过用户行为来推荐其偏好的类型、风格的音乐以保持用户的粘性。
1.2研究现状
早在1992年,在美国就通过协同过滤的思想为邮件和新闻进行了推荐系统的应用。随后,在1994年实现了自动化的新闻信息协同过滤,1995年实现了支持个性化的信息查找辅助系统的设计实现。从此之后,推荐系统这一种主动信息过滤的系统,关注度持续上升,在学术界已经商业的应用上得到了非常广泛的应用发展。到了2006年,Netflix公司通过以百万美元奖励来促进推荐系统的进一步完善,项目吸引了众多的学者参加,为推荐算法的研究打下了坚实的基础。2007年,明尼苏达大学也成功的举办了全球第一届推荐会议,为推动推荐系统的发展提供了很大的帮助,该会议每年一次一直持续至今。而现如今,很多的新闻、期刊等也都在应用推荐系统,在商业化的领域中,IBM、谷歌等都通过推荐系统实现了广告收益的提升,美国网上零售商overstock也通过推荐方案来为不同的用户推荐产品广告,使得其经营收入也实现了大幅的增长。
随着推荐系统传入我国,我国的电商巨头最先对推荐系统进行了深度的利用,通过针对推荐系统评价的可扩充性、稀疏性等进行了深入的研究,对其未来在我国的发展趋势进行了深入的判断,在个性化服务的核心技术上、在协同规律算法的推荐内容上,通过结合当下的国情,以相似度量的方式来对缺陷进行弥补。通过多种推荐技术结合的方式在国内形成了一股推荐系统开发的热潮。而在数字化产品的不断发展之下,国内的在线音乐商店逐渐的增加,数字音乐成为了当下主流的音乐服务媒介,通过互联网实现了更好的数字音乐的传播发展。而海量的音乐出现,已经超出了人们的接收范围和需求,人们想要在众多的音乐中找到自己想要的、感兴趣的音乐变得极为困难。面对这种情况,国内外对于音乐的推荐系统的开发均有着非常显著的研究成果,通过持续不断的研究,音乐推荐已经成为了现在最为前沿、最为重要的一个多媒体信息检索分支。音乐推荐具有一定的复杂性,通过播放循环、播放次数等来进行偏好隐式的推算,通过结合多种因素实现即时的调整来满足用户的个性化需求。音乐推荐过程中的研究难点主要集中在推荐策略以及算法改进上,整体生对于个性化的问题解决依然需要进行长期的研究和开发。
1.3研究的内容
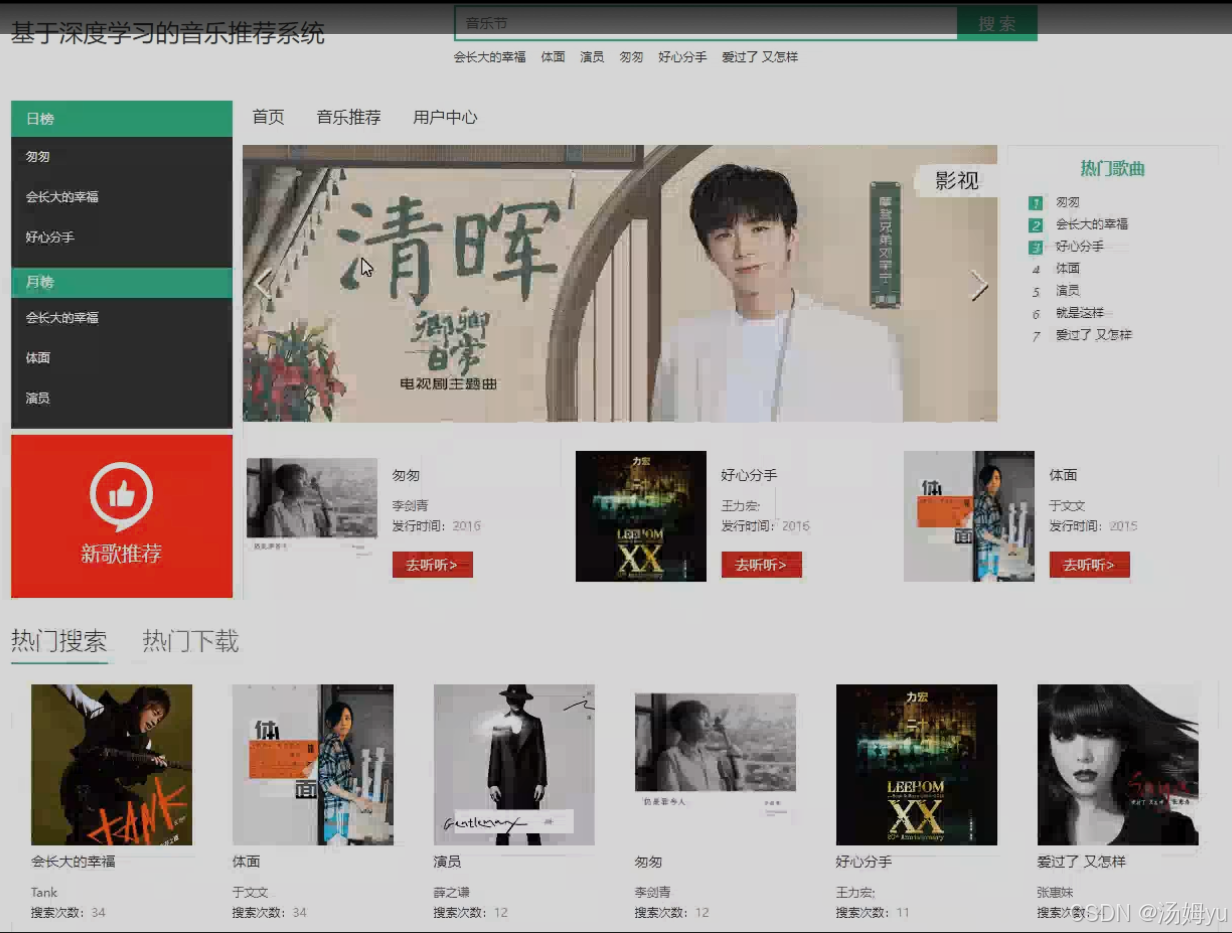
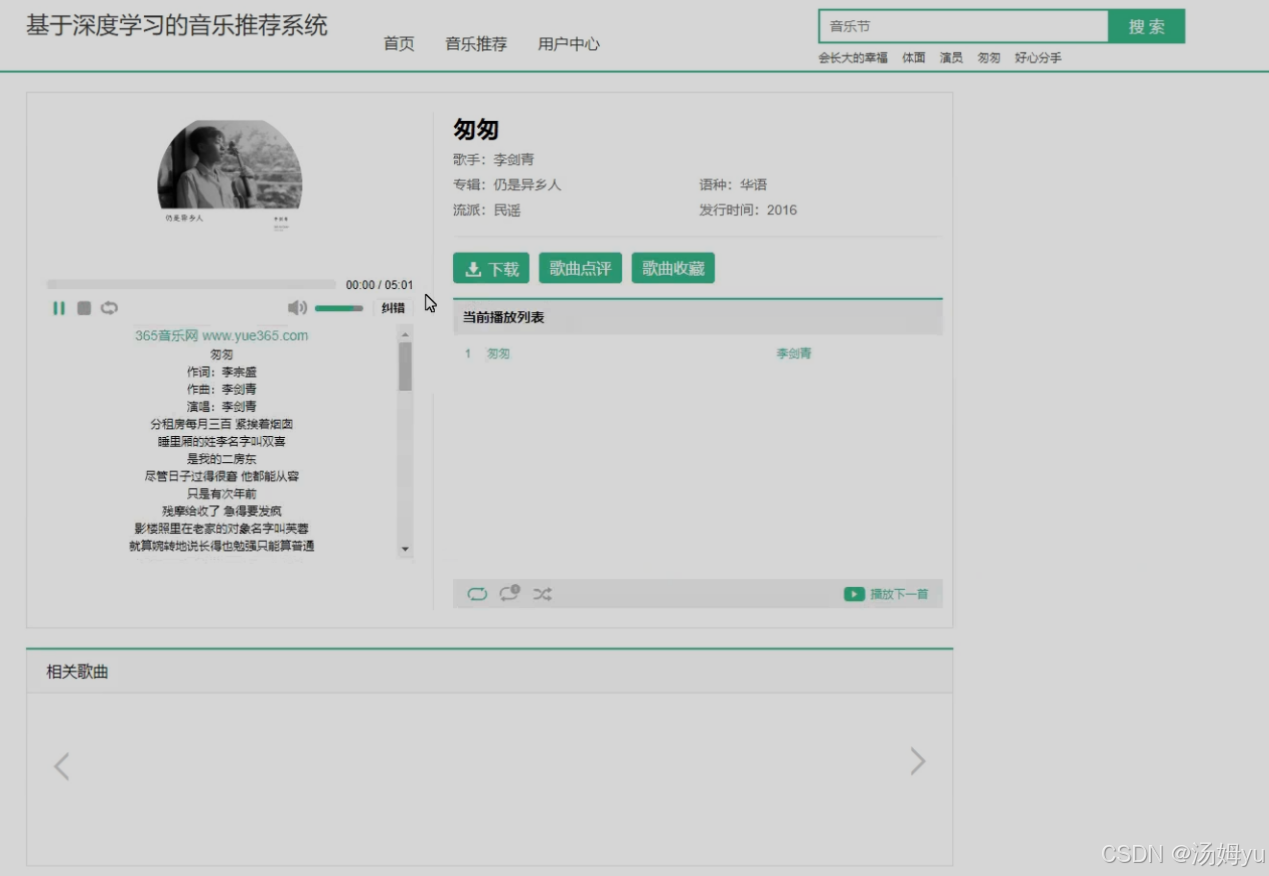
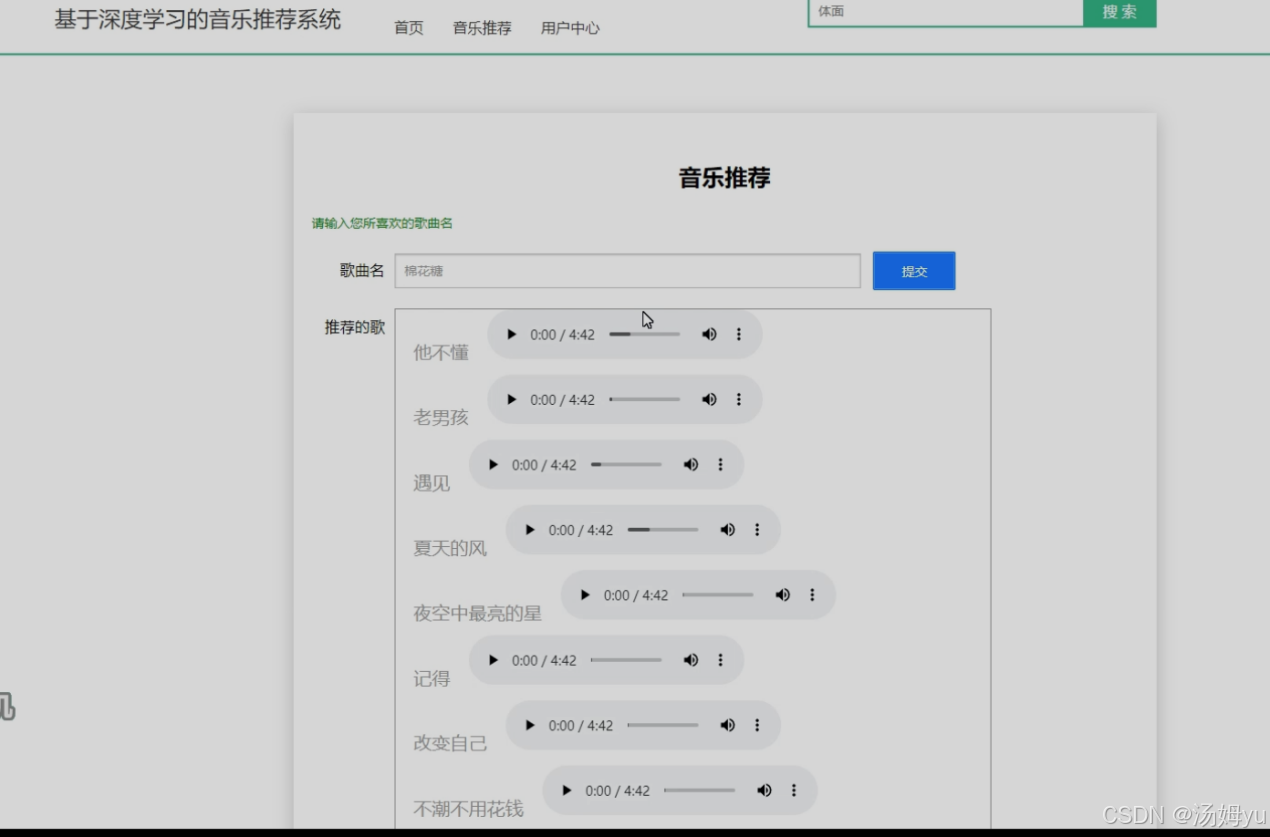
本次通过以卷积神经网络的深度学习为主要的音乐推荐问题解决方法,通过深度学习的算法与传统的算法相结合,以卷积神经网络的回归模型作为最主要的算法理论,来实现一个根据输入文字推荐相关音乐的系统搭建。本次的设计中需要通过以用户的登录,来完成系统的进入;通过以文本框内输入文字的方式来完成推荐音乐的过程实现。可以通过以输入关键词、歌名,由系统来进行类似的歌曲的top10推荐。从而实现深度学习过程下的音乐推荐功能的有效运行。
1.4开发的技术介绍
1.4.1Python技术
本次的系统开发主要是通过利用Python技术来实现对整个web系统的搭建,通过Python技术本次要达成的设计功能是在浏览器端通过B/S结构来开发一款网页,在网页中实现对话框内的文字输入以及搜索的功能运行。之所以选择Python技术是应为该技术在整体的开发过程中有着非常稳定的开发效果,并且语言简单,在开发中能够达到快速的开发效果,对于本次开发时间紧、开发难度大的项目而言,通过Python技术的使用能够很好的完成对系统架构的有效搭建。并且通过Python技术还能够实现有效的与自然语言、卷积神经相结合的功能,从而完整有效的在线音乐推荐的核心功能的开发。
1.4.2MySQL数据库
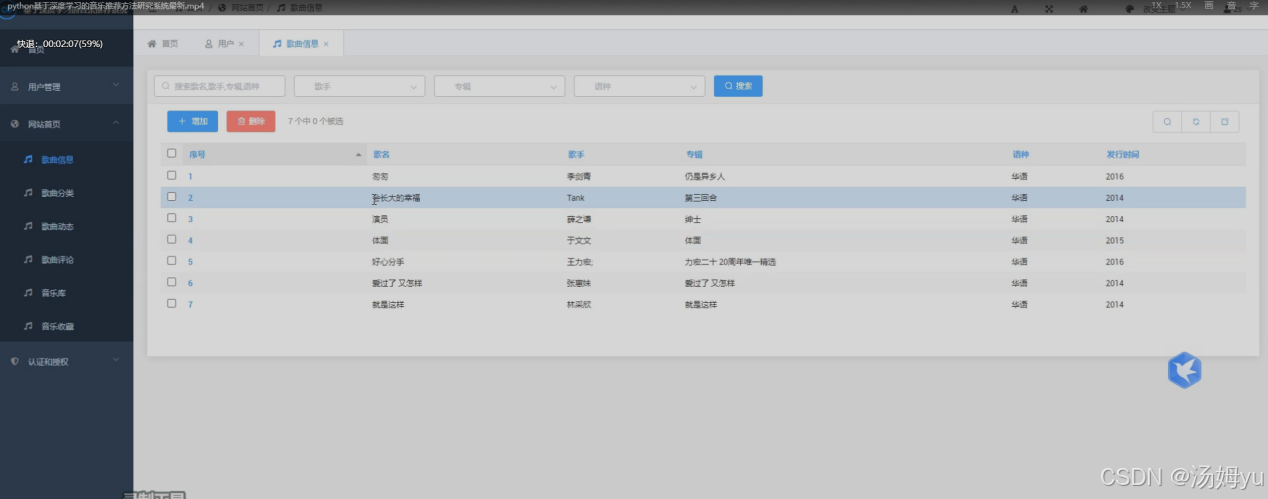
MySQL数据库在本次的开发过程中,是给与数据的存储与调取的功能支持,通过此次利用SQL语言中最为常用的MySQL来进行数据库的搭建,可以起到非常高效的开发效果,通过该数据库的多线程数据处理能力,可以实现有效的提升数据库的多用户同时处理,并且对此次卷积神经所推算出的相关信息也能够在后台的数据库中进行完整的存储。
1.4.3B/S结构
此次的整体设计结构是在B/S的结构下,通过网络来实现一次推荐系统的有效搭建。B/S结构是现在最为常见的一款应用结构,该结构在日常的网络软件开发中有着举足轻重的地位,该结构通过MVC三层架构的方式实现不同层级的快速开发,通过该结构所开发的系统统一都有着简单、稳定、高效的使用效果,并且在开发的成本投入上相对较低,开发后期维护上也能够保持低投入高维护效果。该结构对于本次的开发而言,能够在整体的开发过程中给与很好的支持服务。
1.5论文的结构
本次的论文整体设计架构主要通以下的几个部分来完成:
在第一章的内容中,主要是对深度学习、音乐推荐等内容在当下的互联网大数据环境下的应用背景以及发展现状进行了简要的总结,并且对于此次开发的系统所使用到的编程工具进行了简单的介绍。
在第二章内容中,主要是对深度学习算法、卷积神经以及KNNBaseline算法等进行概念和特性的介绍,通过对这些算法的简单介绍来为本次的推荐系统开发提供必要的技术和理论支持。
在第三章内容中,重点是通过结合深度学习算法以及计算机编程算法来进行系统搭建的整体过程的研究,结合网站搭建的需求进行开发的可行性研究以及其他需求的分析。
在第四章中主要对整个系统的搭建进行整体的设计,在总体的设计中通过结合框架搭建、数据库的设计以及算法的深入研究等来进行整体的系统设计完成。
在第五章中,对于本次搭建的系统中的一些重要的功能进行使用,并且通过截图的方式制作使用说明书。
第六章是对整个系统的整体测试,通过系统的测试来确保整个系统可以稳定的实现有效运行,能够达成设计的需求要求。
最后为总结,通过总结本次的深度学习以及卷积神经网络在音乐推荐中的应用,从而实现提出对系统开发的过程总结以及对未来发展方向的展望。
2深度学习的算法研究
2.1卷积神经网络介绍
卷积神经是一种在图文的推荐上有着深度应用的技术。而在音乐的推荐上实际则是通过以卷积神经的混合土建模型来进行隐含音乐特征的查找。卷积神经是一种多层感知的模型,能够通过从局部的信息中进行扩散从而查找到更为敏感有效的信息内容。
2.1.1卷积神经网络特性
卷积神经在多层感应的机制中能够通过神经元的每一层来与上一层进行有效的连接,这种连接方式被称之为是全连接方式。卷积神经在参数的设计上都是通过层层卷积后得到的数据信息,在整个卷积的过程中,每一层的参数都是相同的,通过与上一层的神经值相连接来实现连接和共享。
2.1.2卷积的方式
卷积神经的运行方式分为了两层结构,一层是卷积层另外一层是采样层。通过卷积层来进行宽、窄和不变卷积功能的实现。通过长度的变换来实现卷积的操作过程,通过矩阵边缘来对整个矩阵的内容进行整体操作。
2.2基本内容推荐算法
基本内容推荐法作为最常见的一种推荐方法是通过从一件物品汇总的元数据进行提取,从而找到代表物品的特征,通过计算与物品的相关性来进行与之相同、类似的物品推荐。通过以一些历史数据作为参考依据,比如用户的评分、评价、浏览的页面内容等,来进行对用户的偏好判定,从而对用户进行潜在的感兴趣项目推荐,整个基本推荐的过程如下图所示: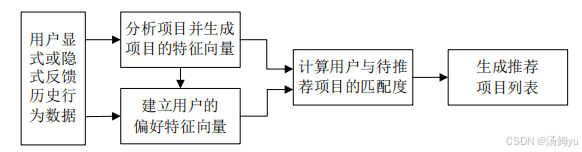
图2.1基本内容推荐流程图
通过使用基本推荐法来进行音乐或者歌手相似度的推荐应用中,假设A喜欢某歌曲名称为a,歌曲的特点是中国风、古典;而B喜欢偏向欧美、摇滚的b歌曲,新歌c 的提取标签为华语、古典,则会将歌曲c 通过基本内容的推荐方式推荐给用户A。
内容推荐法的优点是能够通过直接提取物品的信息内容来避免数据的是属性,能够通过很好的解释性来进行物品的土建展示,准确的找到物品的属性特征,从而提高物品的知名度,加快其在商业市场的推广速度。但该算法也存在一些缺点,基本的内容推荐法对于物品的认知上仍然存在一定的局限性,这种局限性限于仅对物品的表层进行了分析,而不能够在语义上来进行深入的分析,从而实现的推荐类型单一,缺乏新颖性,并且有效推荐的能力相对较差。
2.3基于协同过滤的推荐算法
协同过滤法是现在被广泛应用的一种推荐方法,这种方法也是在Netflix举办的推荐算法大赛中屡次获得大奖的算法。这种算法的特征是对于物品的表象、内容并不关心,更为重要的是关心用户的历史行为,通过对用户的历史行为分析来找到与物品之间的相关性,通过相关性的评分来进行下一步的推荐工作。最终的实现过程是通过“猜你喜欢”、“购买过该商品的人也喜欢”等方式实现物品的推荐。这种推荐方法又衍生出了两种不同的推荐方式,一种是领域协同、另外一种是模型协同。领域的协同过滤是最为核心的一种推荐方式,是通过启发式的推荐过程来实现有效的推荐。推荐的分类如下图所示:
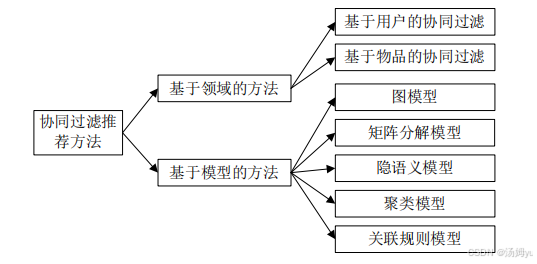
图2.2协同过滤推荐方法分类
在领域的推荐过滤算法中,依然以音乐推荐为例,假设A喜欢歌曲a、b,B喜欢歌曲c,用户C喜欢歌曲a、b、d,通过对用户A、B、C的喜好进行分析,可以看出A和C的喜好类似,通过协同过滤的方式就会将A和C化为相邻的用户集,使得A和C成为了另据用户,由此C喜欢的歌曲也有可能是A所喜欢的,所以会将C所喜欢的歌曲d推荐给用户A。
协同过滤推荐方法的优点在于能够通过分析用户的历史行为,来针对物品特征提取困难的情况进行解决,通过用户行为分析以集体决策智慧的方式来进行评判,在音乐层面,对于音乐风格、音乐的推荐不依靠于音乐本身的特征,而是通过用户与用户之间的共性进行传递。这种算法也存在一定的缺点,主要在于过度的依赖用户和物品的交互数据,从而在评分较少的新物品出现之后,新物品很难被推荐,而且随着用户数、物品数的激增这种情况会越发的明显。
2.4深度学习技术相关概念
自2006年起,计算机领域的深度学习课题被全球所高度重视。在2013年深度学习成为了全球排名第一的计算机突破性技术。而在2016年通过深度学习算法而开发出的AlphaGo,成为了全球瞩目的焦点,并且在围棋领域战胜诸多围棋高手,占据了人工智能领域的制高点。在这种分为的带动下,全球各大互联网公司纷纷加入到深度学习的研究领域中,而深度学习也不断的实现着突破,在当下热门的自动驾驶领域、语音识别领域、图像识别领域以及自然语言的处理领域中均有着深入的应用。在汽车、生物学、医学等方面均有着很好的发展前景。深度学习技术能够让计算机实现根据不同的场景实现不同的学习内容,从而扩宽人工智能的领地。
从维基百科上来看,深度学习被定义是基于常用复杂结构和非线性变化模型的算法集。是机器学习的一个重要的分支内容。深度学习是通过多层神经网络的方式来实现根据环境学习的过程。其学习的网络模型可以以下图所示:
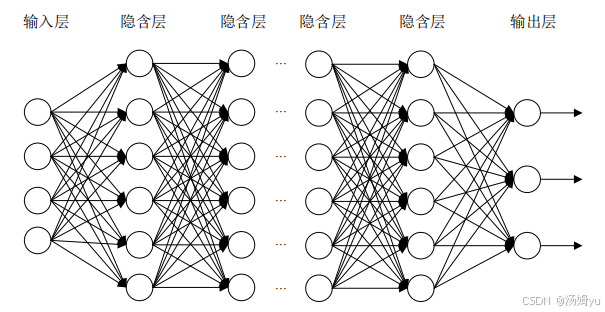
图2.3深度神经网络结构图
2.5深度学习技术推荐算法
在用户和物品之间的维度关系上,传统的浅层的模型分析无法被机器所完全学习,在模型的有效性和判断的准确性以及整个神经网络的可扩展性上均产生了非常大的限制。这种限制在一定的程度上对于传统推荐方式的使用性能影响较大。而深度学习则突破了这种局限性,成为了如今最为热门的人工智能领域的发展标杆。深度学习通过模拟人脑神经网络的感知过程,从为之提供的样本数据集中通过对数据本质的特征学习来客户传统模型的弊端,这一套学习的流程非常的复杂,是通过非线性的网络结构,通过匹配自动学习的特征和捕获数据的能力来构建出一个多源异构的隐空间。在对空间内的数据进行统一的表征,从而整合出一套完整的推荐方法,在遇到数据稀疏以及冷启动等问题上,能够通过深度学习来进行有效的解决。
2.6KNNBaseline算法
KNNbaseline算法是基于KNN算法的一种模型延伸。KNN算法是数据挖掘和分析过程中最为常用的一种算法。这种算法的核心是通过对样本的采集来对样本的特征进行总结,KNN的算法是通过数据训练样本集的收集,将数据与对应的标签进行一一对应,将没有输入标签的数据作为新的数据特征来与样本集中的数据进行对比,根据提取的样本与数据的投资之中找到最为相似的数据来进行新的样本分类。该算法相对更为精确,并且不会过于敏感,不需要太过于详细的了解异常值,从而更容易实现有效的运行。
3系统设计
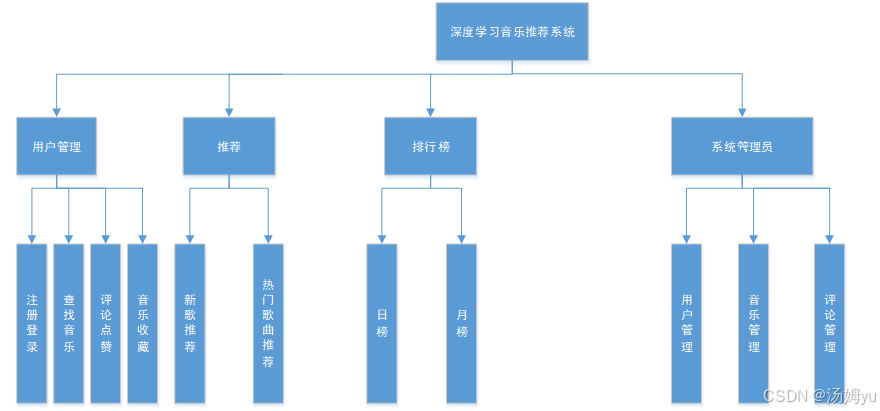
4系统的实现