
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀

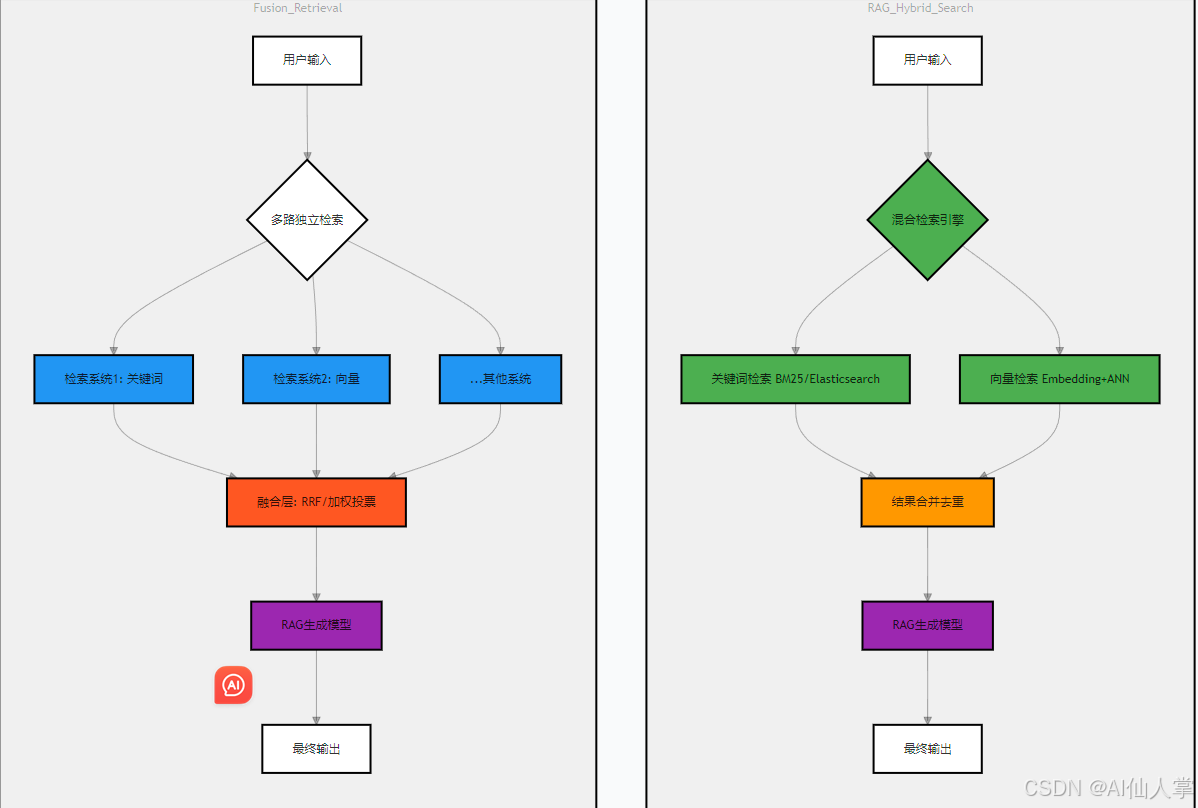
RAG Hybrid Search与Fusion Retrieval的技术对比及工作流程图:
Hybrid Search (混合搜索)
- 定义:结合关键词检索和向量检索的搜索方法
- 特点:同时利用传统BM25算法(精确匹配)和神经网络嵌入(语义匹配)
- 示例:
Elasticsearch + 向量数据库的联合查询
Fusion Retrieval (融合检索)
- 定义:对多种检索结果进行加权融合的算法
- 特点:通过线性加权/学习排序(Rank Fusion)整合不同检索系统的结果
- 示例:
Reciprocal Rank Fusion (RRF)算法
核心区别对比
| 维度 | RAG Hybrid Search | Fusion Retrieval |
|---|---|---|
| 目标 | 通过混合检索策略提升召回率 | 通过多路结果融合提升准确率 |
| 工作阶段 | 检索阶段(预处理层) | 后处理阶段(结果层) |
| 技术实现 | 同时执行关键词+向量检索,合并结果 | 多路独立检索后加权/重排序 |
| 计算开销 | 较高(并行执行两种检索) | 中等(依赖独立检索系统的输出) |
| 典型应用 | 开放域问答、知识密集型任务 | 多模态检索、跨语言检索 |
工作流程图
关键差异解析
-
架构层级差异
- Hybrid Search在检索阶段完成多策略整合(如BM25+向量),降低生成模型噪声
- Fusion Retrieval在检索完成后进行结果融合(如RRF算法),强调异构系统互补性
-
性能权衡
- Hybrid需维护双索引,但减少冗余计算(如ColBERT的混合压缩)
- Fusion支持异步检索(可并行化),但融合算法复杂度高(如RECIPROAL RANK FUSION)
-
适用场景
- Hybrid适合单一数据源下的多角度语义覆盖
- Fusion适合跨系统/跨模态检索(如文本+图像联合检索)
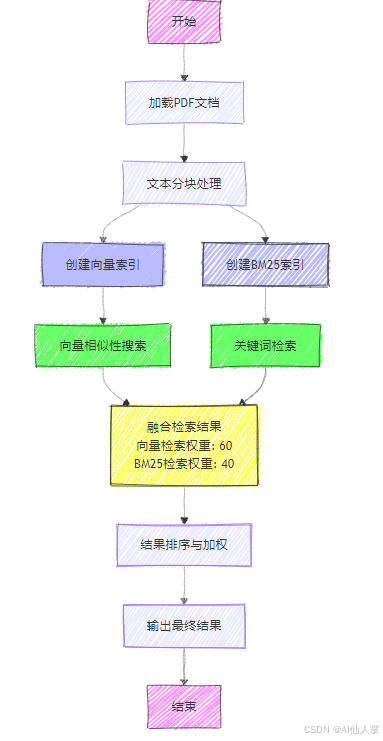
基于LlamaIndex实现RAG融合检索Fusion Retrieval
本代码实现了一个融合检索系统,将基于向量的相似性搜索与基于关键词的BM25检索相结合。该方法旨在综合两种技术的优势,提升文档检索的整体质量和相关性。
动机
传统检索方法通常依赖语义理解(基于向量)或关键词匹配(BM25)。每种方法都有其优缺点。融合检索通过结合这两种方法,构建更强大、更精确的检索系统,能够有效处理更广泛的查询场景。
核心组件
- PDF文档处理与文本分块
- 使用FAISS和OpenAI嵌入创建向量存储
- 构建基于关键词的BM25索引
- 融合BM25和向量搜索结果以优化检索效果
方法细节
文档预处理
- 加载PDF文档并使用SentenceSplitter进行分块
- 通过替换
\t为空格和清理换行符来净化文本块(针对特定格式问题)
向量存储创建
- 使用OpenAI嵌入生成文本块的向量表示
- 基于这些嵌入创建FAISS向量存储,实现高效的相似性搜索
BM25索引创建
- 使用与向量存储相同的文本块创建BM25索引
- 实现与基于向量方法并行的关键词检索
查询混合检索
在创建两种索引后,查询混合检索将它们结合起来,实现混合检索


方法优势
- 提升检索质量:结合语义搜索和关键词匹配,系统能同时捕捉概念相似性和精确关键词匹配
- 灵活调整:通过
retriever_weights参数可调节向量搜索与关键词搜索的权重平衡 - 鲁棒性强:组合方法能有效处理更广泛的查询场景,弥补单一方法的不足
- 高度可定制:系统可轻松适配不同的向量存储或关键词检索方法
结论
融合检索代表了文档搜索的强大方法,结合了语义理解和关键词匹配的优势。通过同时利用基于向量和BM25的检索方法,它为信息检索任务提供了更全面、灵活的解决方案。这种方法在需要兼顾概念相似性和关键词相关性的领域具有广泛应用潜力,如学术研究、法律文档搜索或通用搜索引擎。
导入库
import os
import sys
from dotenv import load_dotenv
from typing import List
from llama_index.core import Settings
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.schema import BaseNode, TransformComponent
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.legacy.retrievers.bm25_retriever import BM25Retriever
from llama_index.core.retrievers import QueryFusionRetriever
import faisssys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录添加到路径中(适用于笔记本环境)
# 从.env文件加载环境变量
load_dotenv()# 设置OpenAI API密钥环境变量
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')# Llamaindex全局设置(LLM和嵌入模型)
EMBED_DIMENSION=512
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBED_DIMENSION)
读取文档
path = "../data/"
reader = SimpleDirectoryReader(input_dir=path, required_exts=['.pdf'])
documents = reader.load_data()
print(documents[0])
创建向量存储
# 创建FAISS向量存储用于保存嵌入
fais_index = faiss.IndexFlatL2(EMBED_DIMENSION)
vector_store = FaissVectorStore(faiss_index=fais_index)
文本清理转换
class TextCleaner(TransformComponent):"""在数据摄取管道中使用的转换组件用于清理文本中的杂乱内容"""def __call__(self, nodes, **kwargs) -> List[BaseNode]:for node in nodes:node.text = node.text.replace('\t', ' ') # 将制表符替换为空格node.text = node.text.replace(' \n', ' ') # 将段落分隔符替换为空格return nodes
数据摄取管道
# 管道实例化,包含:
# 节点解析器、自定义转换器、向量存储和文档
pipeline = IngestionPipeline(transformations=[SentenceSplitter(),TextCleaner()],vector_store=vector_store,documents=documents
)# 运行管道获取节点
nodes = pipeline.run()
检索器
BM25检索器
bm25_retriever = BM25Retriever.from_defaults(nodes=nodes,similarity_top_k=2,
)
向量检索器
index = VectorStoreIndex(nodes)
vector_retriever = index.as_retriever(similarity_top_k=2)
融合两种检索器
retriever = QueryFusionRetriever(retrievers=[vector_retriever,bm25_retriever],retriever_weights=[0.6, # 向量检索器权重0.4 # BM25检索器权重],num_queries=1, mode='dist_based_score',use_async=False
)
关于参数:
num_queries:查询混合检索器不仅能组合检索器,还能从给定查询生成多个问题。此参数控制传递给检索器的查询总数。设置为1时禁用查询生成,最终检索器仅使用初始查询。mode:此参数有4种选项:- reciprocal_rerank:应用互逆排序(由于缺乏标准化,不适合此类应用,因为不同检索器返回的分数范围不同)
- relative_score:基于所有节点中的最小和最大分数应用MinMax缩放,将分数缩放到0到1之间,最后根据
retriever_weights进行加权min\_score = min(scores) \\ max\_score = max(scores) - dist_based_score:与
relative_score的唯一区别在于MinMax缩放基于分数的均值和标准差,缩放和加权方式相同min\_score = mean\_score - 3 * std\_dev \\ max\_score = mean\_score + 3 * std\_dev - simple:此方法简单取每个块的最大分数
使用案例示例
# 查询
query = "气候变化对环境有哪些影响?"# 执行混合检索
response = retriever.retrieve(query)
打印最终检索节点及分数
for node in response:print(f"节点分数:{node.score:.2}")print(f"节点内容:{node.text}")print("-"*100)
基于LlamaIndex实现RAG混合检索
混合检索(Hybrid Search)结合了 关键词检索(如BM25) 和 向量相似度检索(如稠密向量),通过两者的互补性提升召回准确性。
- BM25 处理精确关键词匹配,适合直接相关查询;
- 向量检索 捕捉语义相似性,处理模糊或隐含的语义需求。

2. LlamaIndex实现混合检索的步骤
步骤1:安装依赖与数据准备
pip install llama-index
pip install llama-index[milvus] # 若使用Milvus作为向量数据库
步骤2:构建索引
- BM25索引(关键词检索):基于文本内容的关键词匹配。
- 向量索引(稠密向量检索):将文本编码为向量并存储到数据库(如Weaviate、Milvus)。
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
from llama_index.retrievers import VectorIndexRetriever, BM25Retriever# 加载数据
documents = SimpleDirectoryReader('data/').load_data()# 创建BM25索引(默认)
bm25_index = GPTSimpleVectorIndex(documents) # 实际BM25索引需配置参数# 创建向量索引(需配置向量数据库)
vector_index = GPTSimpleVectorIndex(documents,service_context=service_context # 需配置Embedding模型
)
步骤3:配置混合检索器
LlamaIndex通过 HybridRetriever 或自定义逻辑组合两种检索结果:
from llama_index.retrievers import HybridRetriever# 初始化两个单独的检索器
vector_retriever = VectorIndexRetriever(vector_index)
bm25_retriever = BM25Retriever(bm25_index)# 创建混合检索器(可调整alpha参数权重)
hybrid_retriever = HybridRetriever(vector_retriever=vector_retriever,bm25_retriever=bm25_retriever,alpha=0.5 # 权重参数,调整向量与BM25的贡献比例
)
步骤4:执行混合检索
query = "在发现高血压显著降低的研究中,使用了哪些测量血压的方法?"
results = hybrid_retriever.retrieve(query)
3. 关键参数与调优
**(1) Alpha值调优
- 作用:控制向量检索和BM25检索的权重比例。
- 推荐实践:
- 通过实验确定最优值(如
alpha=0.2或0.6)。 - 使用LlamaIndex的评估模块(如MRR、命中率)进行量化优化。
- 通过实验确定最优值(如
**(2) 索引配置
- BM25优化:调整分块策略(如语义分块提升召回质量)。
- 向量索引优化:
- 选择合适的Embedding模型(如
text-embedding-ada-002); - 确保向量数据库支持混合查询(如Milvus 2.4+版本)。
- 选择合适的Embedding模型(如
4. 实现注意事项
- 数据库兼容性:
- 混合检索需要底层数据库支持联合查询(如Milvus 2.4+)。
- 性能权衡:
- 混合检索可能增加计算开销,需平衡召回率与效率。
- 重排器(Reranker):
- 可添加重排器(如
RerankRetriever)对混合结果进一步排序,提升相关性。
- 可添加重排器(如
5. 参考案例与资源
- BM25+向量的两路召回实现:
参考中LlamaIndex的HybridFusionRetrieverPack或自定义检索器配置。 - Alpha调优实验:
IBM研究指出,混合检索在单/多文档场景中均表现更优,尤其当alpha=0.2/0.6时。












