

论文网址:01133.pdf
论文代码:GitHub - weihaox/UMBRAE: [ECCV 2024] UMBRAE: Unified Multimodal Brain Decoding | Unveiling the 'Dark Side' of Brain Modality
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
1. 心得
2. 论文逐段精读
2.1. Abstract
2.2. Introduction
2.3. Related Works
2.4. UMBRAE
2.4.1. Architecture
2.4.2. Cross-Subject Alignment
2.4.3. Multimodal Alignment
2.4.4. Brain Prompting Interface
2.5. Experiments
2.5.1. Implementation Details
2.5.2. BrainHub
2.5.3. Brain Captioning
2.5.4. Brain Grounding
2.5.5. Brain Retrieval
2.5.6. Visual Decoding
2.5.7. Weakly-Supervised Adaptation
2.6. Ablation Study
2.6.1. Architectural Improvements
2.6.2. Training Strategies
2.7. Conclusion
1. 心得
(1)额
2. 论文逐段精读
2.1. Abstract
①Challenges: spatial brain-powered information and cross-subject research
granularity n. 间隔尺寸,[岩] 粒度
2.2. Introduction
①The target object of brain signal decoding: people with cognitive or physical disabilities or even locked-in patients
②⭐Challenges: a) single modality decoding will cause loss of brain information, b) text encoding ignores the spatial information
2.3. Related Works
①Mentioned generation models, LLM based models and alignment models
2.4. UMBRAE
①UMBRAE denotes unified multimodal brain decoding
②Overall framework of UMBRAE:
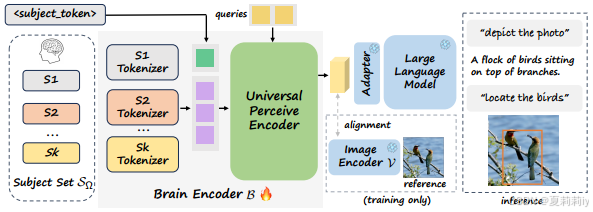
(咦,一眼OneLLM了)
2.4.1. Architecture
①Brain encoder: lightweight Transformer
②Brain signal for each person is from subject set
, where
is with arbitrary length
③Tokenizer transforms to
with
tokens and
dimension(这个是绿色小方块?)
④Brain tokens (这个到底是什么啊哪哪都是brain token但是图上没有啊图上只有subject token,看文本就像是紫色小方块)
⑤Universal Perceive Encoder: cross attention module
prepend v. 预置;前置;预先考虑;预先准备;预追加
2.4.2. Cross-Subject Alignment
①Uniform random sampling in the data of each participant with probability :
就是如果一个batch size的大小是,有
的概率抽到某个被试
,从
中抽
个数据。然后剩下的
个数据从其他受试者中均匀采样
2.4.3. Multimodal Alignment
①Instead of mapping data in all the modalities to the same space, they align brain signal element by element to pretrained image feature
②To align brain response and image
, they minimize the loss between brain encoder
and image encoder
:
2.4.4. Brain Prompting Interface
①Templet of MLLM:
![]()
for brain captioning, they define <instruction> as: ‘Describe this image <image> as simply as possible.’, for brain grounding task, they define <instruction> as: ‘Locate <expr> in <image> and provide its coordinates, please.’, where <expr> is the expression
2.5. Experiments
2.5.1. Implementation Details
①Visual encoder: CLIP ViT-L/14
②LLM: Vicuna-7B/13B
③Image feature: from the second last layer of the transformer encoder, and is converted to
.
for Vicuna-7B and
for Vicuna-13B
④Epoch: 240
⑤Batch size: 256
⑥Training time: 12 hours in one A100 GPU
⑦Optimizer: AdamW with ,
, weight decay of 0.01, learning rate of 3e-4
⑧, meaning that in each batch of 256 samples, 128 come from each of two subjects
2.5.2. BrainHub
①Dataset: NSD
②Tasks: brain captioning, brain grounding, brain retrieval, visual decoding
2.5.3. Brain Captioning
①Brain captioning performance comparison table:
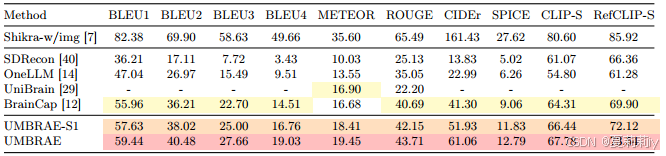
where -S1 denotes training on single subject 01
2.5.4. Brain Grounding
①Example of brain captioning and brain grounding tasks:

②Performance of brain grounding:
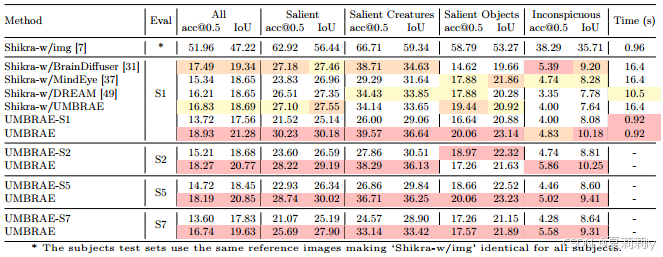
2.5.5. Brain Retrieval
①Forward retrieval, backward retrieval, and exemplar retrieval peroformance:
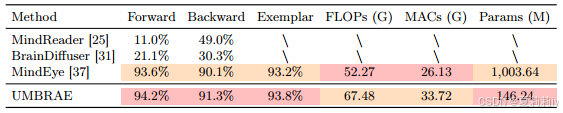
where the model needs to identify brain embedding, image embedding and image
2.5.6. Visual Decoding
①Image reconstruction:
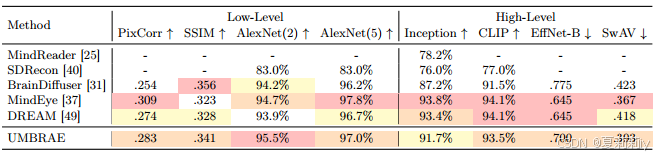
2.5.7. Weakly-Supervised Adaptation
①Performance with different training data on S7:
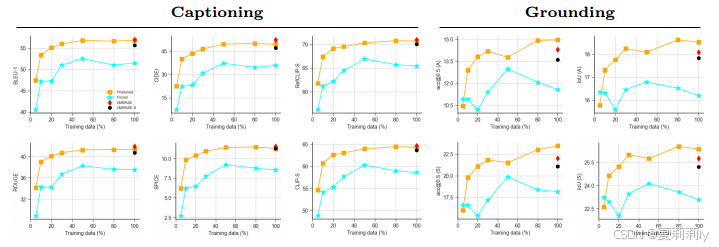
2.6. Ablation Study
2.6.1. Architectural Improvements
①UMBRAE has less parameters
2.6.2. Training Strategies
①Module ablation:
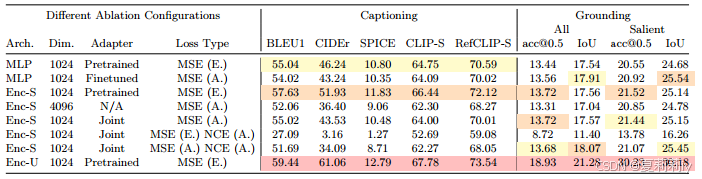
2.7. Conclusion
~










for,forEach,for of,map,filter,reduce,every,some "js【最佳实践】遍历数组的八种方法(含数组遍历 API 的对比)for,forEach,for of,map,filter,reduce,every,some")

