
接上一回。
Painless Lab 是 Elasticsearch 7.13 引入的实验性功能,是一个交互式代码编辑器,可以实时测试和调试 Painless 脚本。
本文展开解读 Painless Lab 如何应用于企业级实战开发中的脚本调试环节!
1、Painless Lab 是什么?
Painless Lab是一个交互式的测试版代码编辑器,用于实时测试和调试Painless脚本。
咱们可以通过打开主菜单,点击开发工具,然后选择 Painless Lab 来访问它。
如下图所示,左侧是:脚本输入区域。右侧由三部分组成:
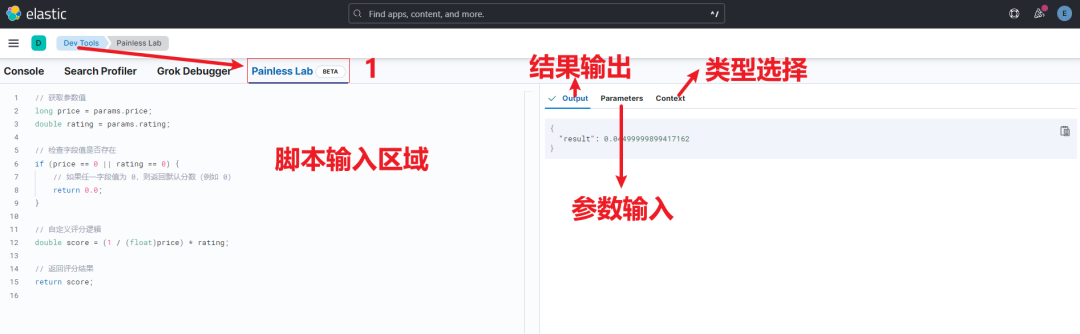
Output:代表结果输出,确切说是调试结果输出。
Parameters:代表参数输入。
Context:代表上下文,确切说是不同脚本类型选型与选择。
2、Painless Lab 能干什么?
一句话:Painless Lab 可以实时测试和调试 Painless 脚本。
Painless Lab 允许我们创建 Kibana 运行时字段(runtime fields)、处理重新索引的数据(reindex)、定义复杂的 Watcher 条件(付费功能),并在其他上下文中处理数据。
下面的 Context 部分展开就是 Painless Lab 的核心功能区域。
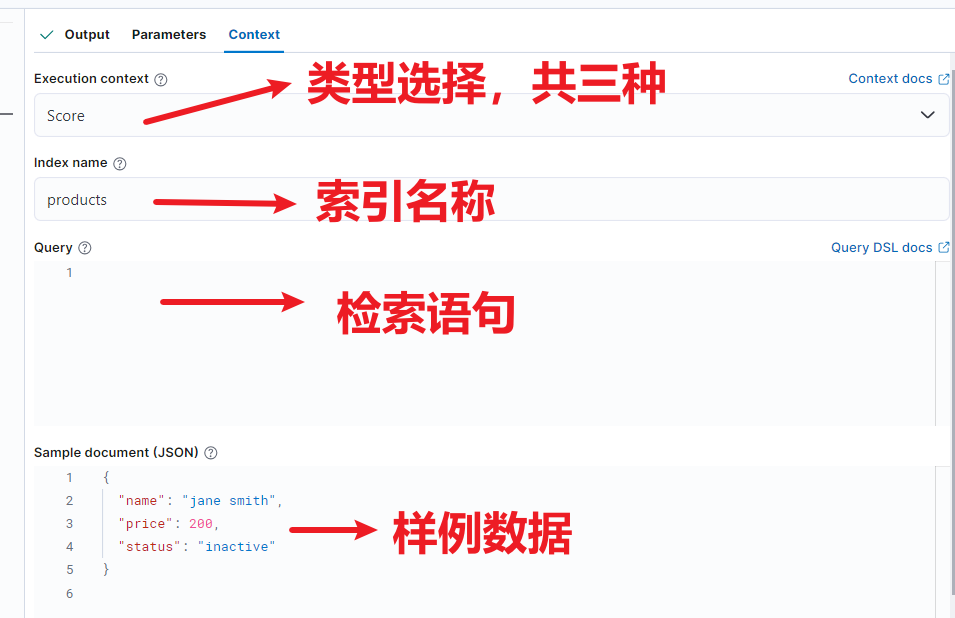
三种类型进一步展开:
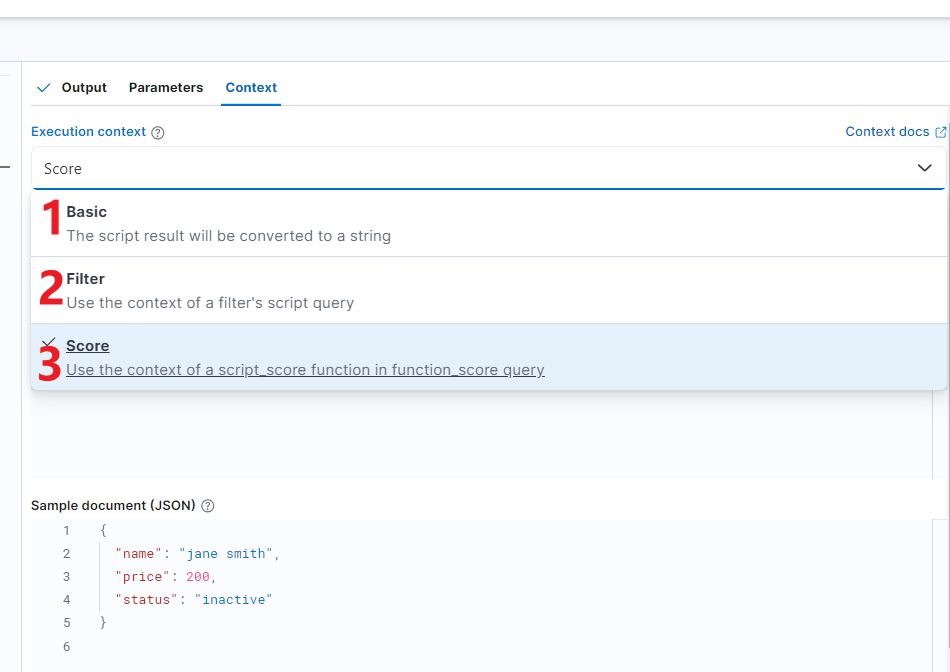
进一步再展开解读。
https://www.elastic.co/guide/en/elasticsearch/painless/8.11/painless-execute-api.html#_contexts
| 上下文 | 描述 |
|---|---|
| painless_test | 默认上下文,如果没有指定其他上下文则使用此上下文。用于通用脚本测试,例如调试和验证脚本逻辑。 |
| filter | 将脚本视为在脚本查询中运行。用于过滤数据。 |
| score | 将脚本视为在 function_score 查询中的 script_score 函数中运行。用于评分数据。 |
2.1 painless_test 类型
默认上下文,如果没有指定其他上下文则使用此上下文。用于通用脚本测试,例如调试和验证脚本逻辑。
2.2 filter 类型
将脚本视为在脚本查询中运行。用于过滤数据。
2.3 score 类型
将脚本视为在 function_score 查询中的 script_score 函数中运行。用于评分数据。
我们逐一详尽展开解读,确保大家跟着过一遍,就能学得会!
3、 Basic painless_test 基础调试
Basic 上下文允许我们独立测试脚本逻辑,并将结果转换为字符串输出。
样例数据可以放到 params 中作为输入。
实战举例如下:
对于 Ingest pipeline 脚本,参考官方示例,由于脚本是在 Ingest Pipeline 中处理数据的,并且没有涉及到查询过滤 filter 或评分 score,因此 Basic 上下文是最合适的选择。

https://www.elastic.co/guide/en/elasticsearch/reference/current/script-processor.html
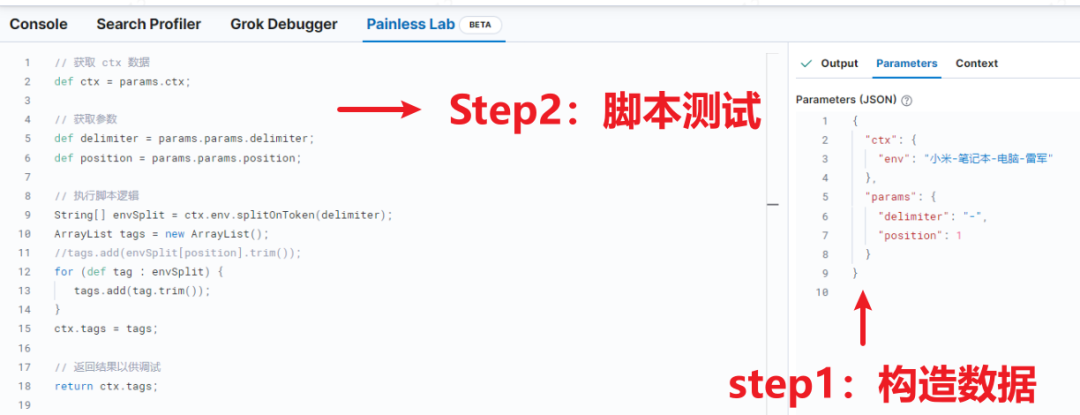
如上图所示,我们在 parameters 中输入如下数据:
{"ctx": {"env": "小米-笔记本-电脑-雷军"},"params": {"delimiter": "-","position": 1}
}我们在左侧输入如下的 painless script 脚本,如下所示:
// 获取 ctx 数据
def ctx = params.ctx;// 获取参数
def delimiter = params.params.delimiter;
def position = params.params.position;// 执行脚本逻辑
String[] envSplit = ctx.env.splitOnToken(delimiter);
ArrayList tags = new ArrayList();
//tags.add(envSplit[position].trim());
for (def tag : envSplit) {tags.add(tag.trim());
}
ctx.tags = tags;// 返回结果以供调试
return ctx.tags;执行结果如下图右侧 Output 所示。
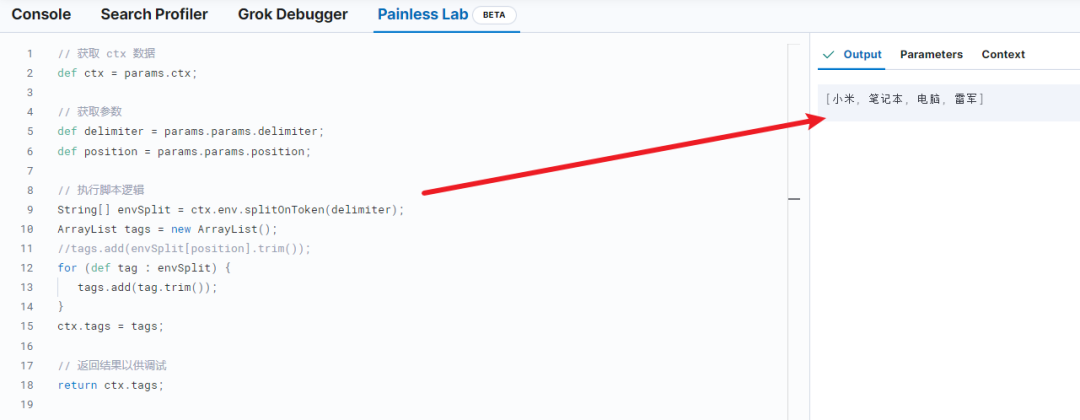
上述脚本实现的核心功能就是:以分隔符截断字符串,形成独立字符串,插入到 tags 集合中。
这样调试过之后,再微调一下就可以应用到 ingest pipeline 中。
4、filter 过滤调试
区别于刚才的逻辑,这里需要我们先创建索引,然后基于我们构造的索引数据进行展开 filter 过滤检索。
POST /hockey/_doc/1
{"first": "johnny","last": "gaudreau","goals": [9, 27, 1],"assists": [17, 46, 0],"gp": [26, 82, 1]
}POST /hockey/_doc/2
{"first": "john","last": "doe","goals": [2, 3, 4],"assists": [1, 2, 3],"gp": [4, 5, 6]
}上述索引必须构建,否则会报错如下图所示。
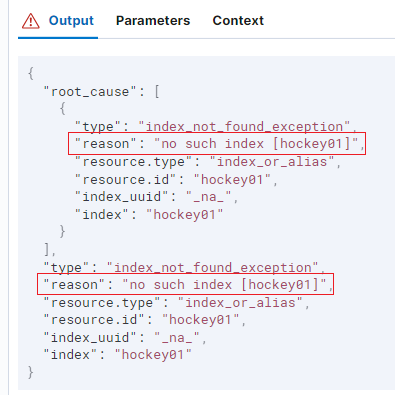
错误原因可能是:索引不存在或者Mapping 不存在。
正确的执行步骤如下所示:
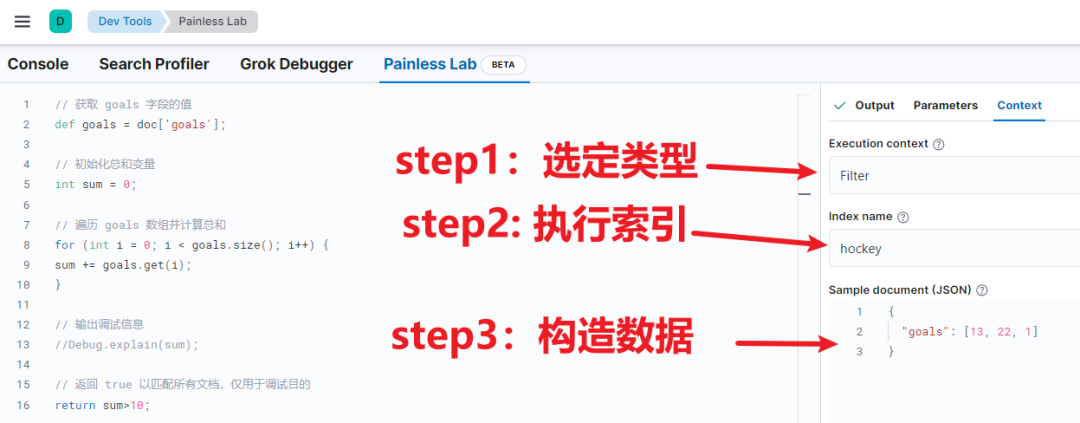
结合上面三个步骤以及左侧的脚本,主要验证左侧脚本正确与否。注意:返回值必须是 Bool 类型。执行结果如下:
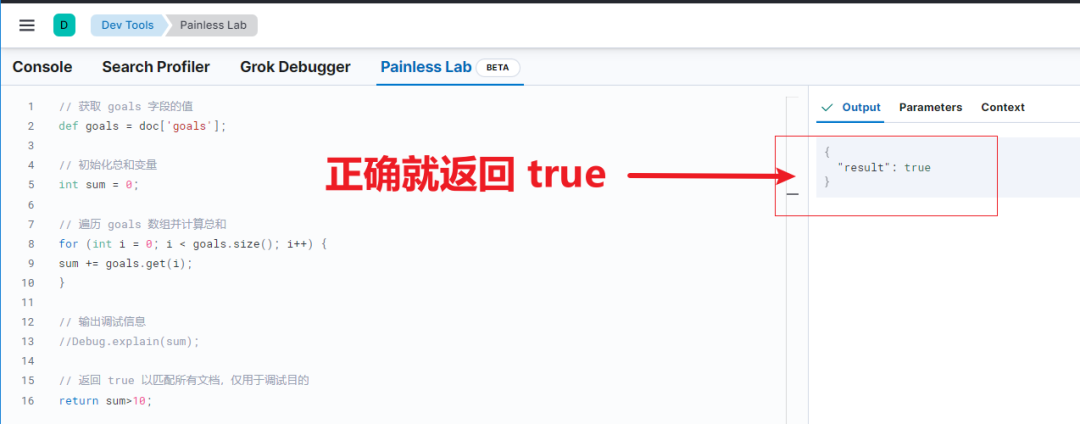
最终结合上述调试成功的脚本,整合到 script query 检索语句中,就能得到满足用户预期的结果数据。
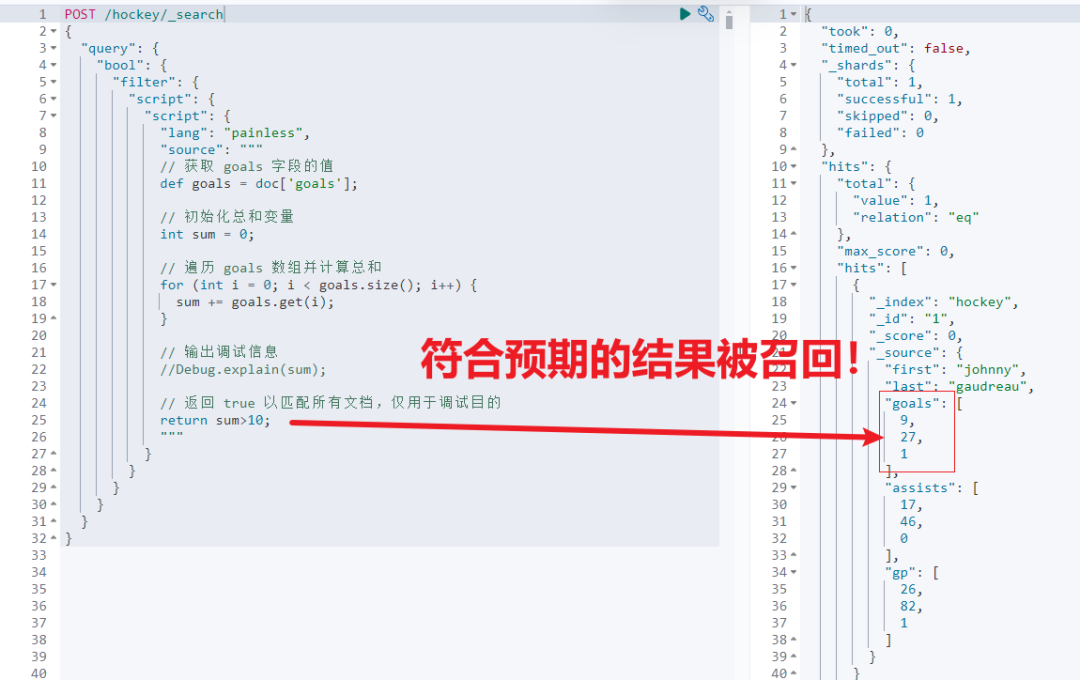
POST /hockey/_search
{"query": {"bool": {"filter": {"script": {"script": {"lang": "painless","source": """// 获取 goals 字段的值def goals = doc['goals'];// 初始化总和变量int sum = 0;// 遍历 goals 数组并计算总和for (int i = 0; i < goals.size(); i++) {sum += goals.get(i);}// 输出调试信息//Debug.explain(sum);// 返回 true 以匹配所有文档,仅用于调试目的return sum>10;"""}}}}}
}5、评分 score 类型调试
在 Elasticsearch 中,score 类型调试上下文用于在 function_score 查询中的 script_score 函数中运行脚本。
该方式允许用户编写脚本来动态计算文档的评分,从而影响搜索结果的排序。
5.1 真实企业场景再现
假设我们有一个包含产品信息的索引 products,每个文档包含以下字段:
1.name: 产品名称
2.price: 产品价格
3.rating: 产品评分
我们希望根据价格和评分来动态计算每个产品的分数,具体规则如下:
1.价格越低,分数越高
2.评分越高,分数越高
POST /products/_doc/1
{"name": "Product A","price": 100,"rating": 4.5
}POST /products/_doc/2
{"name": "Product B","price": 200,"rating": 4.0
}POST /products/_doc/3
{"name": "Product C","price": 150,"rating": 3.5
}5.2 评分查询脚本调试示例
我们将编写一个 function_score 查询,使用 Painless 脚本来计算每个文档的分数,并根据计算结果排序。
核心逻辑:
1、获取字段值;
2、脚本重新计算评分;
3、返回自定义评分。
在 Painless Lab 中,可以使用类似的脚本来调试和验证评分逻辑:
构造参数 Parameters 部分
{"price": 100,"rating": 4.5
}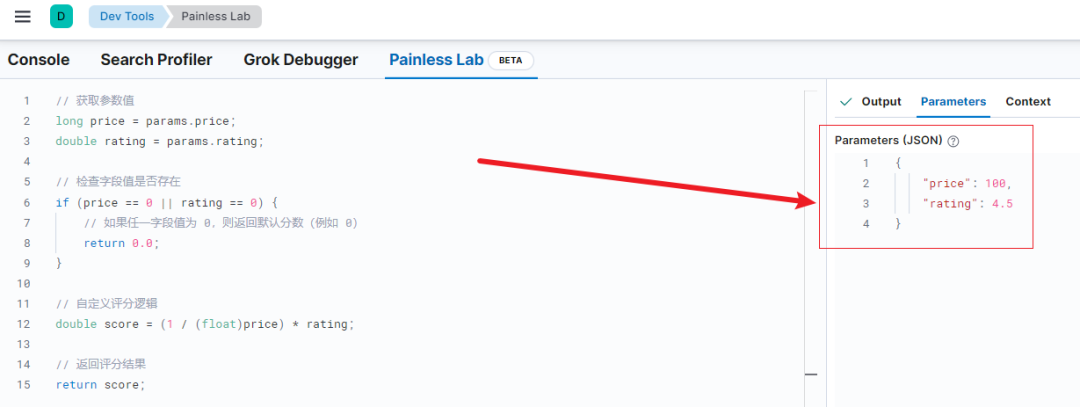
左侧脚本部分
// 获取参数值
long price = params.price;
double rating = params.rating;// 检查字段值是否存在
if (price == 0 || rating == 0) {// 如果任一字段值为 0,则返回默认分数(例如 0)return 0.0;
}// 自定义评分逻辑
double score = (1 / (float)price) * rating;// 返回评分结果
return score;执行结果如下所示:
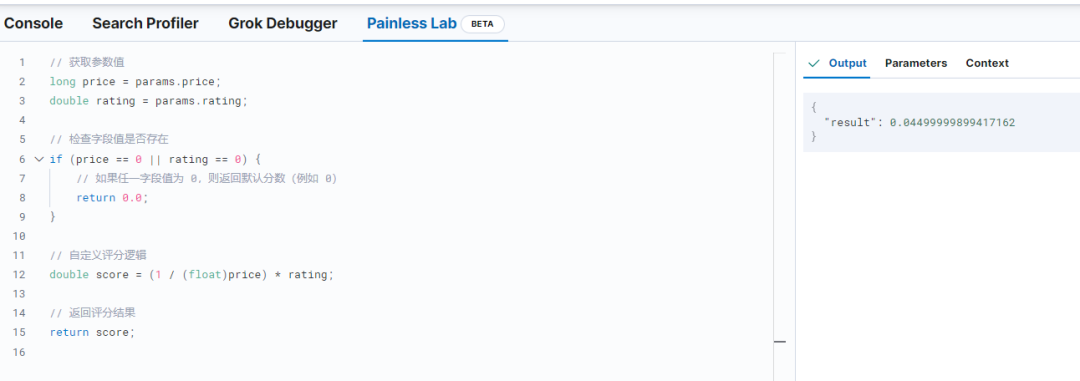
上述脚本通过使用 score 上下文中的 script_score 函数,可以根据自定义逻辑动态计算文档的分数,从而影响搜索结果的排序。
这在需要根据复杂规则排序搜索结果时非常有用。
通过在 Painless Lab 中调试和验证上述脚本,可以确保评分逻辑的正确性和有效性。
进而,可以组合写出如下的评分脚本检索语句。
POST /products/_search
{"query": {"function_score": {"query": {"match_all": {}},"script_score": {"script": {"source": """long price = doc['price'].value;double rating = doc['rating'].value;// 自定义评分逻辑double score = (1 / (float)price) * rating;return score;"""}},"boost_mode": "replace" // 使用脚本计算的分数替换原始分数}}
}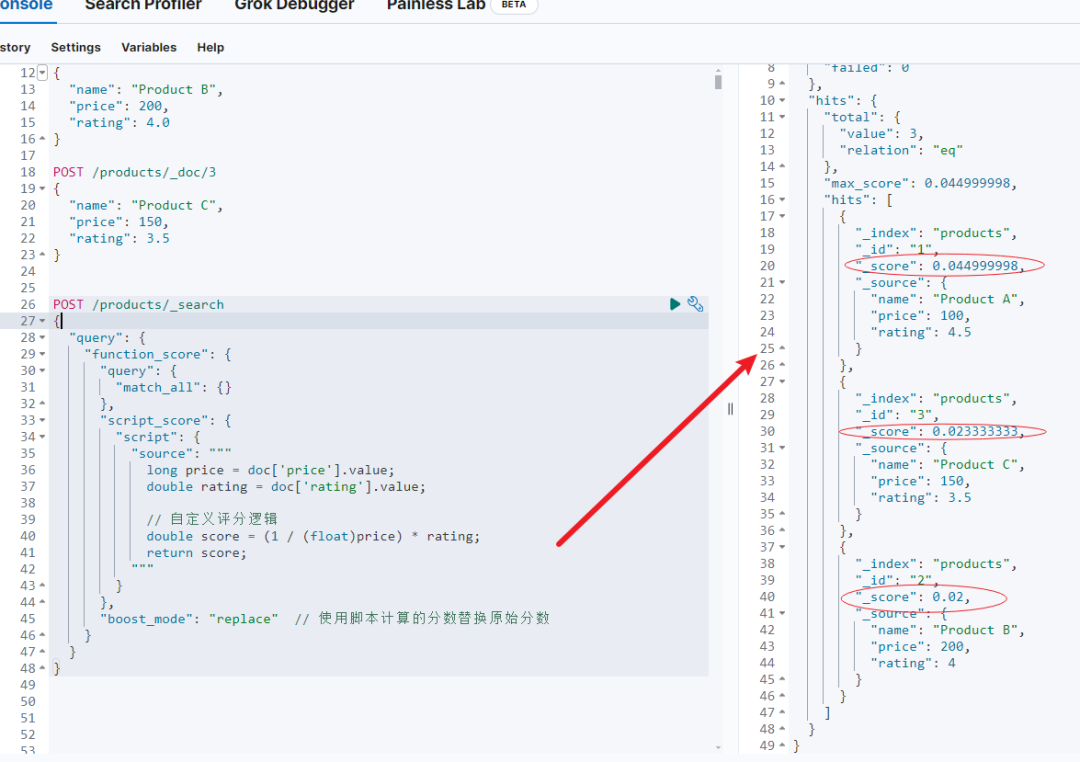
实现核心:根据自定义逻辑计算分数:score = (1 / price) * rating。价格越低,评分越高,分数越高。
boost_mode: 设置为 replace,使用脚本计算的分数替换原始分数。
6、小结
Kibana Painless Lab 是 Elasticsearch 7.13 引入的实验性功能,为开发者提供交互式代码编辑器,用于实时测试和调试 Painless 脚本。
通过 painless_test、filter 和 score 上下文三种测试方式,开发者可以创建和调试 Kibana 运行时字段、处理重新索引的数据、定义复杂的 Watcher 条件,并根据复杂规则动态计算文档分数,提高脚本开发和优化效率。
希望大家真正将两篇文章提到的脚本测试方式应用到企业实战环节。
Elasticsearch 企业级实战 01:Painless 脚本如何调试?
探究 | Elasticsearch Painless 脚本 ctx、doc、_source 的区别是什么?
Elasticsearch 脚本安全使用指南
干货 | Elasticsearch7.X Scripting脚本使用详解
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
http://elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!












